
En este artículo, hablaremos sobre los detalles de implementación y el funcionamiento de los diferentes compiladores JIT, así como las estrategias de optimización. Discutiremos con suficiente detalle, pero omitiremos muchos conceptos importantes. Es decir, no habrá suficiente información en este artículo para llegar a conclusiones razonables en cualquier comparación de implementaciones y lenguajes.
Para obtener una comprensión básica de los compiladores JIT, lea este artículo .
Una pequeña nota:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT usa lo que se llama rastreo. Pypy realiza metatracing, es decir, utiliza el sistema para generar trazas e intérpretes JIT. Pypy y LuaJIT no son implementaciones ejemplares de Python y Lua, sino proyectos independientes. Yo caracterizaría a LuaJIT como sorprendentemente rápido, y se describe a sí mismo como una de las implementaciones de lenguaje dinámico más rápidas, y lo creo absolutamente.
Para saber cuándo empezar a rastrear, el bucle del intérprete busca bucles en caliente (¡el concepto de código en caliente es universal para todos los compiladores JIT!). El compilador luego "rastrea" el ciclo, registrando las operaciones ejecutables para compilar un código de máquina bien optimizado. En LuaJIT, la compilación se basa en trazas con una representación intermedia similar a una instrucción que es exclusiva de LuaJIT.
Cómo se implementa el seguimiento en Pypy
Pypy comienza a rastrear la función después de 1619 ejecuciones y compila después de 1039 ejecuciones, es decir, se necesitan aproximadamente 3000 ejecuciones de la función para que comience a funcionar más rápido. Estos valores fueron elegidos cuidadosamente por el equipo de Pypy y, en general, en el mundo de los compiladores, muchas constantes se eligen cuidadosamente.
Los lenguajes dinámicos dificultan la optimización. El siguiente código se puede eliminar estáticamente en un lenguaje más estricto porque
Falsesiempre será falso. Sin embargo, en Python 2, esto no se puede garantizar hasta el tiempo de ejecución.
if False:
print("FALSE")
Para cualquier programa inteligente, esta condición siempre será falsa. Desafortunadamente, el valor
Falsese puede redefinir y la expresión estará en un bucle, se puede redefinir en otro lugar. Por tanto, Pypy puede crear un "protector". Si el defensor falla, el JIT vuelve al ciclo de interpretación. Pypy luego usa otra constante (200) llamada traza ansiosa para decidir si compila el resto de la nueva ruta antes del final del ciclo. Este subtrayecto se llama puente .
Además, Pypy proporciona estas constantes como argumentos que puede personalizar en tiempo de ejecución junto con la configuración de desenrollado, es decir, expansión de bucle y alineación. Y además, proporciona ganchos que podemos ver una vez completada la compilación.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Arriba, escribí un programa Python puro con un gancho de compilación para mostrar el tipo de compilación aplicada. El código también genera datos al final, que muestra el número de defensores. Para este programa, obtuve una compilación de bucles y 66 defensores. Cuando reemplacé la expresión con un
ifsimple pase fuera de circuito for, solo quedaban 59 defensores.
for i in range(10000):
pass # removing the `if False` saved 7 guards!
Al agregar estas dos líneas al bucle
for, obtuve dos compilaciones, ¡una de las cuales era del tipo "puente"!
if random.randint(1, 100) < 20:
False = True
Espera, estabas hablando de metatracing.
La idea del metatrazado se puede describir como "¡escriba un intérprete y obtenga un compilador gratis!" O "¡convierta su intérprete en un compilador JIT!" Escribir un compilador es difícil, y si puede obtenerlo gratis, entonces la idea es genial. Pypy "contiene" un intérprete y un compilador, pero no implementa explícitamente un compilador tradicional.
Pypy tiene una herramienta RPython (construida para Pypy). Es un marco para la escritura de intérpretes. Su lenguaje es una especie de Python y está tipado estáticamente. Es en este idioma que necesita escribir un intérprete. El lenguaje no está diseñado para la programación Python escrita porque no contiene bibliotecas o paquetes estándar. Cualquier programa RPython es un programa Python válido. El código RPython se transpila a C y luego se compila. Por lo tanto, existe un metacompilador en este lenguaje como programa en C compilado.
El prefijo "meta" en metatrace significa que el rastreo se realiza cuando se ejecuta el intérprete, no el programa. Se comporta más o menos como cualquier otro intérprete, pero puede rastrear sus operaciones y está diseñado para optimizar los rastreos actualizando su ruta. Con un seguimiento adicional, la ruta del intérprete se optimiza más. Un intérprete bien optimizado sigue un camino específico. Y el código de máquina utilizado en esta ruta, obtenido compilando RPython, se puede utilizar en la compilación final.
En resumen, el "compilador" en Pypy compila su intérprete, razón por la cual Pypy a veces se llama metacompilador. No compila tanto el programa que estás ejecutando como la ruta de un intérprete optimizado.
El concepto de metatrazado puede parecer confuso, por lo que, con fines ilustrativos, escribí un programa muy pobre que solo comprende
a = 0y a++to.
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Si ejecuto este ciclo caliente:
a = 0
a++
a++
Las pistas pueden verse así:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Pero el compilador no es un módulo separado especial, está integrado en el intérprete. Por lo tanto, el ciclo de interpretación se verá así:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Introducción a la JVM
Pasé cuatro meses escribiendo en el lenguaje TruffleRuby basado en Graal y me enamoré de él.
Hotspot (llamado así porque busca puntos calientes ) es una máquina virtual que viene con instalaciones estándar de Java. Contiene varios compiladores para implementar la compilación multinivel. La base de código de 250.000 líneas de Hotspot está abierta y tiene tres recolectores de basura. El desarrollador hace frente a la compilación JIT, en algunos puntos de referencia, funciona mejor que las implicaciones de C ++ (en esta ocasión, como
Las estrategias utilizadas en Hotspot han inspirado a muchos autores de compiladores JIT posteriores, marcos de máquinas virtuales de lenguaje y especialmente motores Javascript. Hotspot también generó una ola de lenguajes JVM como Scala, Kotlin, JRuby y Jython. JRuby y Jython son implementaciones divertidas de Ruby y Python que compilan el código fuente en el bytecode de JVM, que luego ejecuta Hotspot. Todos estos proyectos son relativamente exitosos en acelerar los lenguajes Python y Ruby (Ruby más que Python) sin implementar todas las herramientas, como es el caso de Pypy. Hotspot también es único en cuanto a que es un JIT para lenguajes menos dinámicos (aunque técnicamente es un JIT para código de bytes JVM, no Java).

GraalVM es un JavaVM con un fragmento de código Java. Puede ejecutar cualquier lenguaje JVM (Java, Scala, Kotlin, etc.). También es compatible con Native Image para trabajar con código compilado AOT a través de Substrate VM. Una proporción significativa de los servicios Scala de Twitter se ejecutan en Graal, lo que habla de la calidad de la máquina virtual, y de alguna manera es mejor que la JVM, aunque está escrito en Java.
¡Y eso no es todo! GraalVM también proporciona Truffle: un marco para implementar lenguajes mediante la creación de intérpretes AST (Abstract Syntax Tree). No hay ningún paso explícito en Truffle cuando el código de bytes de JVM se genera como en un lenguaje JVM normal. Más bien, Truffle simplemente usará el intérprete y hablará con Graal para generar código de máquina directamente con la creación de perfiles y la denominada puntuación parcial. La evaluación parcial está más allá del alcance de este artículo, en pocas palabras: este método se adhiere a la filosofía de "escribir un intérprete, obtener un compilador gratis" del metatracking, pero lo aborda de manera diferente.
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
Las implementaciones JIT a menudo tienen problemas para admitir extensiones C. Los intérpretes estándar como Lua, Python, Ruby y PHP tienen una API para C que permite a los usuarios crear paquetes en ese lenguaje, acelerando significativamente la ejecución. Muchos paquetes están escritos en C, por ejemplo, numerosas funciones de biblioteca estándar como
rand. Todas estas extensiones de C son fundamentales para agilizar los lenguajes interpretados.
Las extensiones C son difíciles de mantener por varias razones. La razón más obvia es que la API está diseñada teniendo en cuenta la implementación interna. Además, es más fácil admitir extensiones C cuando el intérprete está escrito en C, por lo que JRuby no puede admitir extensiones C, pero tiene una API para extensiones Java. Pypy lanzó recientemente una versión beta de soporte para extensiones C, aunque no estoy seguro de si funciona debido a la Ley de Hyrum . LuaJIT admite extensiones C, incluidas funciones adicionales en sus extensiones C (¡LuaJIT es simplemente increíble!)
Graal resuelve este problema con Sulong, un motor que ejecuta el código de bytes LLVM en GraalVM, convirtiéndolo a Truffle. LLVM es una caja de herramientas, y solo necesitamos saber que C se puede compilar en código de bytes LLVM (¡Julia también tiene un backend LLVM!). ¡Es extraño, pero la solución es tomar un buen lenguaje compilado con más de cuarenta años de historia e interpretarlo! Por supuesto, no se ejecuta tan rápido como C compilado correctamente, pero obtiene varios beneficios.
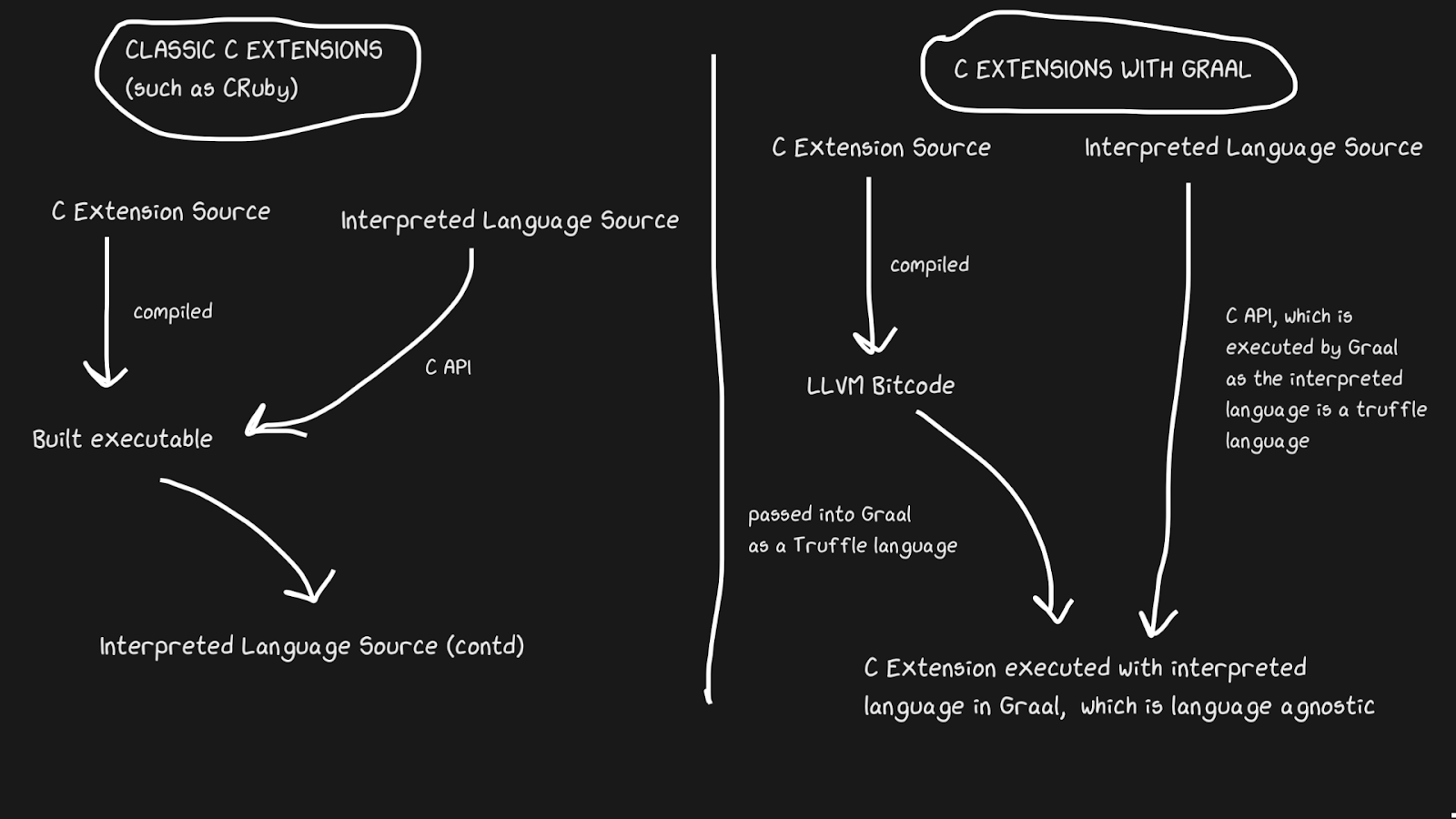
El código de bytes LLVM ya es de nivel bastante bajo, es decir, no es tan ineficiente aplicar JIT a esta representación intermedia como a C.Parte del costo se compensa por el hecho de que el código de bytes se puede optimizar junto con el resto del programa Ruby, pero no podemos optimizar el programa C compilado ... Todas estas tiras de memoria, inlining, bloques muertos y más se pueden aplicar al código C y Ruby, en lugar de llamar al binario C desde el código Ruby. Las extensiones TruffleRuby C son más rápidas que las extensiones CRuby C en algunos aspectos.
Para que este sistema funcione, debe saber que Truffle es completamente independiente del idioma y que la sobrecarga de cambiar entre C, Java o cualquier otro idioma dentro de Graal será mínima.
La capacidad de Graal para trabajar con Sulong es parte de sus capacidades políglotas, lo que permite una alta intercambiabilidad de idiomas. Esto no solo es bueno para el compilador, sino que también demuestra que puede utilizar fácilmente varios idiomas en una "aplicación".
Volviendo al código interpretado, es más rápido
Sabemos que los JIT contienen un intérprete y un compilador, y que se mueven de un intérprete a otro para acelerar las cosas. Pypy crea puentes para la ruta de retorno, aunque desde el punto de vista de Graal y Hotspot, esto es una desoptimización . No estamos hablando de conceptos completamente diferentes, pero por desoptimización entendemos un regreso al intérprete como una optimización consciente, y no una solución a la inevitabilidad de un lenguaje dinámico. Hotspot y Graal hacen un uso intensivo de la desoptimización, especialmente Graal, porque los desarrolladores tienen un control estricto sobre la compilación y necesitan aún más control sobre la compilación por el bien de las optimizaciones (en comparación con, digamos, Pypy). La desoptimización también se usa en motores JS, de los que hablaré mucho, ya que JavaScript en Chrome y Node.js depende de ello.
Para aplicar rápidamente la desoptimización, es importante asegurarse de cambiar entre el compilador y el intérprete lo más rápido posible. Con la implementación más ingenua, el intérprete tendrá que "ponerse al día" con el compilador para realizar la desoptimización. Las complicaciones adicionales están asociadas con la deoptimización de flujos asincrónicos. Graal crea un conjunto de marcos y lo compara con el código generado para regresar al intérprete. Con los puntos de seguridad, puede hacer una pausa en un hilo de Java y decir: "Hola, recolector de basura, ¿tengo que detenerme?" De modo que el procesamiento del hilo no requiera mucha sobrecarga. Resultó ser bastante tosco, pero funciona lo suficientemente rápido como para que la desoptimización sea una buena estrategia.
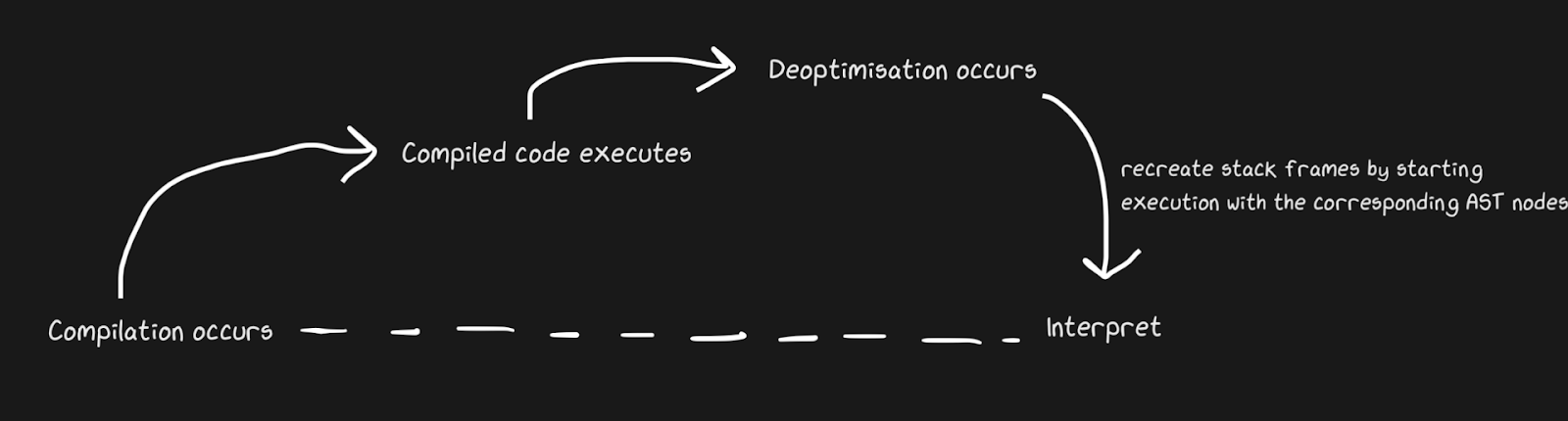
Al igual que en el ejemplo de puente de Pypy, el parche de mono de funciones puede des-optimizarse. Es más elegante porque agregamos código de desoptimización no cuando falla el defensor, sino cuando se aplica el parche de guerrilla.
Un gran ejemplo de desoptimización JIT: el desbordamiento de conversión es un término no oficial. Estamos hablando de una situación en la que un determinado tipo (por ejemplo,
int32) está representado / asignado internamente , pero necesita convertirse a int64. TruffleRuby hace esto con desoptimizaciones, al igual que el V8.
Por ejemplo, si preguntas en Ruby
var = 0, obtienes int32(Ruby lo llama Fixnumy Bignum, pero yo usaré la notación int32y int64). Realizar una operación convar, debe comprobar si se produce un desbordamiento de valores. Pero una cosa es verificar, y compilar código que maneja los desbordamientos es costoso, especialmente dada la frecuencia de las operaciones numéricas.
Sin siquiera mirar las instrucciones compiladas, puede ver cómo esta desoptimización reduce la cantidad de código.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
En TruffleRuby, solo se desoptimiza la primera ejecución de una operación en particular, por lo que no desperdiciamos recursos en ella cada vez que una operación se desborda.
El código WET es un código rápido. Inlining y OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
¡Incluso trivialidades como estos disparadores se desoptimizan en V8! Con opciones como
--trace-deopty, --trace-optpuede recopilar mucha información sobre el JIT y también modificar el comportamiento. Graal tiene algunas herramientas muy útiles, pero usaré V8 porque muchos lo tienen instalado.
La desoptimización se inicia con la última línea (
foo(1, 2)), lo cual es desconcertante, ¡porque esta llamada se realizó en el ciclo! Recibiremos un mensaje "Comentarios de tipo insuficiente para la llamada" (la lista completa de motivos para la deoptimización está aquí , y hay un motivo divertido para "sin motivo"). Esto crea un marco de entrada que muestra los literales 1y 2.
Entonces, ¿por qué des-optimizar? V8 es lo suficientemente inteligente como para encasillar: cuando
ies tipointeger, también se pasan literales integer.
Para entender esto, reemplacemos la última línea con
foo(i, i +1). Pero todavía se aplica la desoptimización, solo que esta vez el mensaje es diferente: "Retroalimentación de tipo insuficiente para operación binaria". ¡¿POR QUÉ?! Después de todo, esta es exactamente la misma operación que se realiza en un ciclo, ¡con las mismas variables!
La respuesta, amigo mío, radica en el reemplazo en la pila (OSR). Inlining es una potente optimización del compilador (no solo JIT) en la que las funciones dejan de ser funciones y el contenido pasa al lugar de las llamadas. Los compiladores JIT pueden incorporarse para aumentar la velocidad cambiando el código en tiempo de ejecución (los lenguajes compilados solo pueden incorporarse estáticamente).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
Por lo tanto, V8 se compilará
foo, determinará que puede estar en línea y en línea con OSR. Sin embargo, el motor hace esto solo para el código dentro del bucle, porque esta es una ruta activa y la última línea aún no está en el intérprete en el momento de la inserción. Por lo tanto, V8 aún no tiene suficientes comentarios sobre el tipo de función foo, porque no se usa en el ciclo, sino en su versión en línea. Si se aplica --no-use-osr, entonces no habrá desoptimización, no importa lo que pasemos, literal o i. Sin embargo, sin la alineación, incluso un pequeño millón de iteraciones se ejecutará notablemente más lento. Los compiladores JIT realmente incorporan el principio de no solución solo de compensación. Las desoptimizaciones son costosas, pero no se comparan con el costo de encontrar métodos y alinear, que se prefiere en este caso.
¡Inlining es increíblemente efectivo! Ejecuté el código anterior con un par de ceros adicionales y se ejecutó cuatro veces más lento con la inserción deshabilitada.

Aunque este artículo trata sobre JIT, la inserción también es eficaz en lenguajes compilados. Todos los lenguajes de LLVM usan activamente la inserción, porque LLVM también lo hará, aunque Julia está en línea sin LLVM, esto está en su naturaleza. Los JIT se pueden integrar mediante heurística en tiempo de ejecución y pueden cambiar entre los modos no integrados y en línea mediante OSR.
Una nota sobre JIT y LLVM
LLVM proporciona un montón de herramientas relacionadas con la compilación. Julia trabaja con LLVM (tenga en cuenta que esta es una gran caja de herramientas y cada idioma la usa de manera diferente), al igual que Rust, Swift y Crystal. Basta decir que este es un proyecto grande y maravilloso que también admite JIT, aunque LLVM no tiene JIT dinámicos incorporados significativos. El cuarto nivel de compilación de JavaScriptCore usó el backend LLVM por un tiempo, pero fue reemplazado hace menos de dos años. Desde entonces, este conjunto de herramientas no ha sido muy adecuado para JIT dinámicos, principalmente porque no está diseñado para funcionar en un entorno dinámico. Pypy lo intentó 5-6 veces, pero se decidió por JSC. Con LLVM, el hundimiento de la asignación y el movimiento del código fueron limitados.También fue imposible utilizar potentes funciones JIT como la inferencia de rango (es como lanzar, pero con un rango de valores conocido). Pero lo que es más importante, con LLVM, se gastan muchos recursos en la compilación.
¿Qué pasa si en lugar de una representación intermedia basada en instrucciones, tenemos un gráfico grande que se modifica a sí mismo?
Hablamos sobre el código de bytes LLVM y el código de bytes Python / Ruby / Java como una representación intermedia. Todos parecen una especie de lenguaje en forma de instrucciones. Hotspot, Graal y V8 utilizan la representación intermedia "Sea of Nodes" (introducida en Hotspot), que es un AST de nivel inferior. Esta es una vista eficaz porque una parte importante de la elaboración de perfiles se basa en la noción de un determinado camino que rara vez se utiliza (o se cruza en el caso de algún patrón). Tenga en cuenta que estos compiladores de AST son diferentes de los analizadores de AST.
Por lo general, me adhiero a la posición de "intentar hacerlo en casa". Por ejemplo, no puedo leer todos los gráficos, no solo por falta de conocimiento, sino también por las capacidades computacionales de mi cerebro (las opciones del compilador pueden ayudar a deshacerme de un comportamiento que no me interesa).
En el caso del V8, usaremos la herramienta D8 con bandera
--print-ast. Para Graal lo será --vm.Dgraal.Dump=Truffle:2. El texto se mostrará en la pantalla (formateado para obtener un gráfico). No sé cómo los desarrolladores de V8 generan gráficos visuales, pero Oracle tiene un "Visualizador de gráficos ideal" que se usa en la ilustración anterior. No tenía la fuerza para reinstalar IGV, así que tomé los gráficos de Chris Seaton, generados con Seafoam, cuya fuente ahora está cerrada.
Bien, ¡echemos un vistazo al AST de JavaScript!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
Ejecuté este código
d8 --print-ast test.js, aunque solo estamos interesados en la función accumulate. Vea que solo lo llamé una vez, es decir, no tengo que esperar a la compilación para obtener el AST.
Así es como se ve el AST (eliminé algunas líneas sin importancia):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
Es difícil analizar esto, pero es similar al AST del analizador (no es cierto para todos los programas). Y el siguiente AST se genera usando Acorn.js.
Una diferencia notable es la definición de variables. En el AST del analizador, no hay una definición explícita de parámetros y la declaración de bucle está oculta en el nodo
ForStatement. En un AST de nivel de compilador, todas las declaraciones se agrupan con direcciones y metadatos.
El compilador AST también usa esta estúpida expresión
VAR PROXY. El AST del analizador no puede determinar la relación entre nombres y variables (por direcciones) debido a la elevación de variables (elevación), evaluación (eval) y otros. Entonces, el AST del compilador usa variables PROXYque luego se asocian con la variable real.
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
¡Y así es como se ve el AST del mismo programa, obtenido usando Graal!
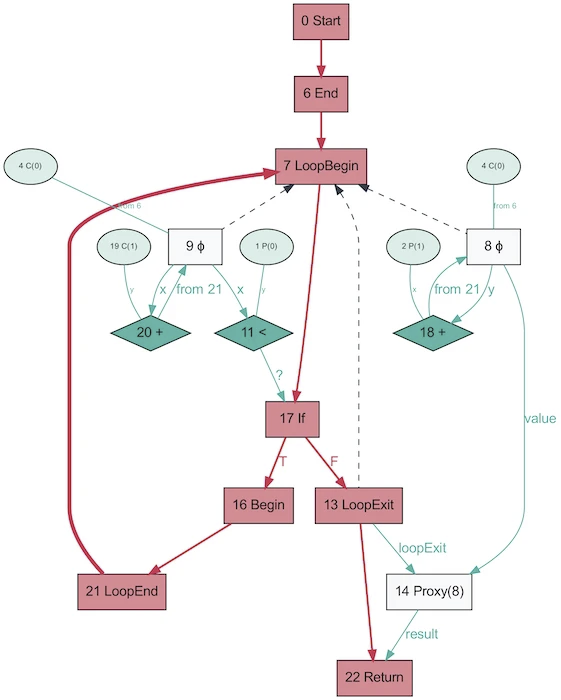
Parece mucho más simple. El rojo indica el flujo de control, el azul indica el flujo de datos, las flechas indican las direcciones. Tenga en cuenta que si bien este gráfico es más simple que el AST de V8, esto no significa que Graal sea mejor para simplificar el programa. Simplemente se genera en base a Java, que es mucho menos dinámico. El mismo gráfico de Graal generado a partir de Ruby estará más cerca de la primera versión.
Es curioso que AST en Graal cambie dependiendo de la ejecución del código. Este gráfico se genera con OSR deshabilitado e insertado, cuando la función se llama repetidamente con parámetros aleatorios para que no esté optimizada. ¡Y el volcado te proporcionará un montón de gráficos! Graal utiliza un AST especializado para optimizar programas (V8 realiza optimizaciones similares, pero no a nivel de AST). Cuando guarda gráficos en Graal, obtiene más de diez esquemas con diferentes niveles de optimización. Al reescribir los nodos, se reemplazan (se especializan) con otros nodos.
El gráfico anterior es un excelente ejemplo de especialización en un lenguaje escrito dinámicamente (imagen tomada de One VM to Rule Them All, 2013). La razón por la que existe este proceso está estrechamente relacionada con el funcionamiento de la evaluación parcial: se trata de especialización.
¡Hurra JIT compiló el código! ¡Compilemos de nuevo! ¡Y otra vez!
Arriba mencioné sobre "multinivel", hablemos de ello. La idea es simple: si aún no estamos listos para crear código totalmente optimizado, pero la interpretación sigue siendo costosa, podemos precompilar y luego compilar finalmente cuando estemos listos para generar un código más optimizado.
Hotspot es un JIT en capas con dos compiladores, C1 y C2. C1 hace una compilación rápida y ejecuta el código, luego hace un perfil completo para compilar el código con C2. Esto puede ayudar a resolver muchos problemas de calentamiento. El código compilado no optimizado es más rápido que la interpretación de todos modos. Además, C1 y C2 no compilan todo el código. Si la función parece lo suficientemente simple, con una alta probabilidad C2 no nos ayudará y ni siquiera se ejecutará (¡también ahorraremos tiempo en la creación de perfiles!). Si C1 está ocupado compilando, la creación de perfiles puede continuar, el trabajo de C1 se interrumpirá y se iniciará la compilación con C2.
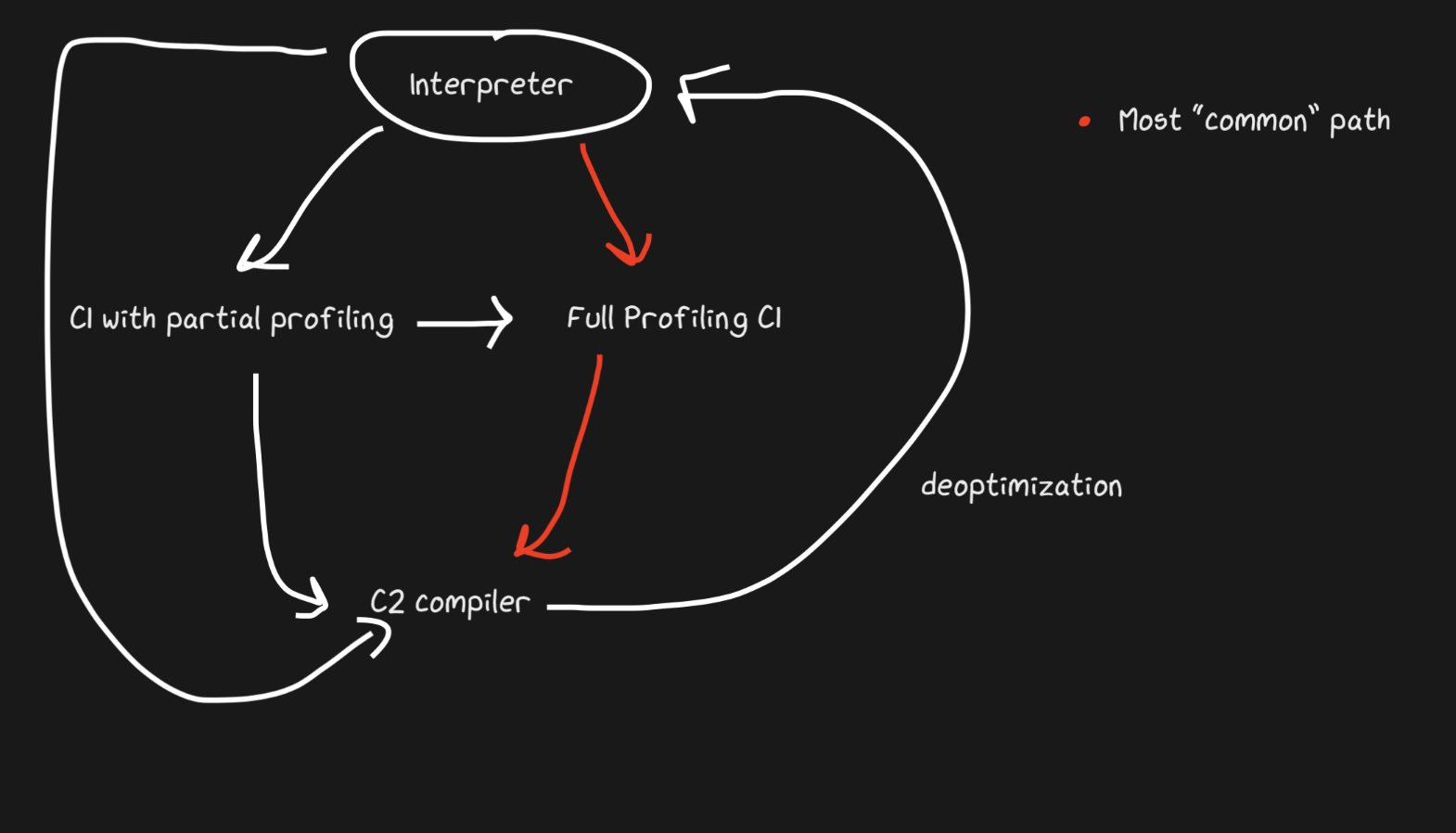
¡JavaScript Core tiene aún más niveles! De hecho, hay tres JIT . El intérprete JSC realiza un perfil ligero, luego pasa a JIT de línea de base, luego a JIT de DFG (gráfico de flujo de datos) y finalmente a JIT de FTL (más rápido que la luz). Con tantos niveles, el significado de la desoptimización ya no se limita a la transición del compilador al intérprete, la desoptimización se puede realizar comenzando con DFG y terminando con Baseline JIT (este no es el caso en el caso de Hotspot C2-> C1). Todas las desoptimizaciones y transiciones al siguiente nivel se realizan mediante OSR (Stack Override).
Baseline JIT se conecta después de aproximadamente 100 ejecuciones y DFG JIT después de aproximadamente 1000 (con algunas excepciones). Esto significa que el JIT obtiene el código compilado mucho más rápido que el mismo Pypy (que toma alrededor de 3000 ejecuciones). La creación de capas permite que el JIT intente correlacionar la duración de la ejecución del código con la duración de su optimización. Hay un montón de trucos sobre qué tipo de optimización (inlining, casting, etc.) realizar en cada uno de los niveles y, por lo tanto, esta estrategia es óptima.
Fuentes útiles
- Cómo funciona el compilador de seguimiento de LuaJIT de Mike Pall
- Impacto del meta-seguimiento en las máquinas virtuales por Laurie Tratt
- Análisis de escape de Pypy
- Por qué los usuarios no están más contentos con las máquinas virtuales por Laurie Tratt
- Acerca de los motores JS:
- Acerca de la desoptimización:
- Graal:
- :
- :