Beneficios de usar TensorFlow.js en un navegador
- interactividad : el navegador tiene muchas herramientas para visualizar procesos en curso (gráficos, animación, etc.);
- sensores : el navegador tiene acceso directo a los sensores del dispositivo (cámara, GPS, acelerómetro, etc.);
- seguridad de los datos del usuario : no es necesario enviar datos procesados al servidor;
- compatibilidad con modelos creados en Python .
Actuación
Uno de los principales problemas es el rendimiento.
Debido al hecho de que el aprendizaje automático está, de hecho, realizando varios tipos de operaciones matemáticas con datos matriciales (tensores), la biblioteca para este tipo de cálculos en el navegador utiliza WebGL. Esto mejora significativamente el rendimiento si se realizan las mismas operaciones en JS puro. Naturalmente, la biblioteca tiene un respaldo en caso de que WebGL no sea compatible con el navegador por alguna razón (en el momento de escribir este artículo, caniuse muestra que el 97,94% de los usuarios tienen soporte WebGL).
Para mejorar el rendimiento, Node.js usa enlaces nativos con TensorFlow. Aquí, CPU, GPU y TPU ( Unidad de procesamiento de tensor ) pueden servir como aceleradores
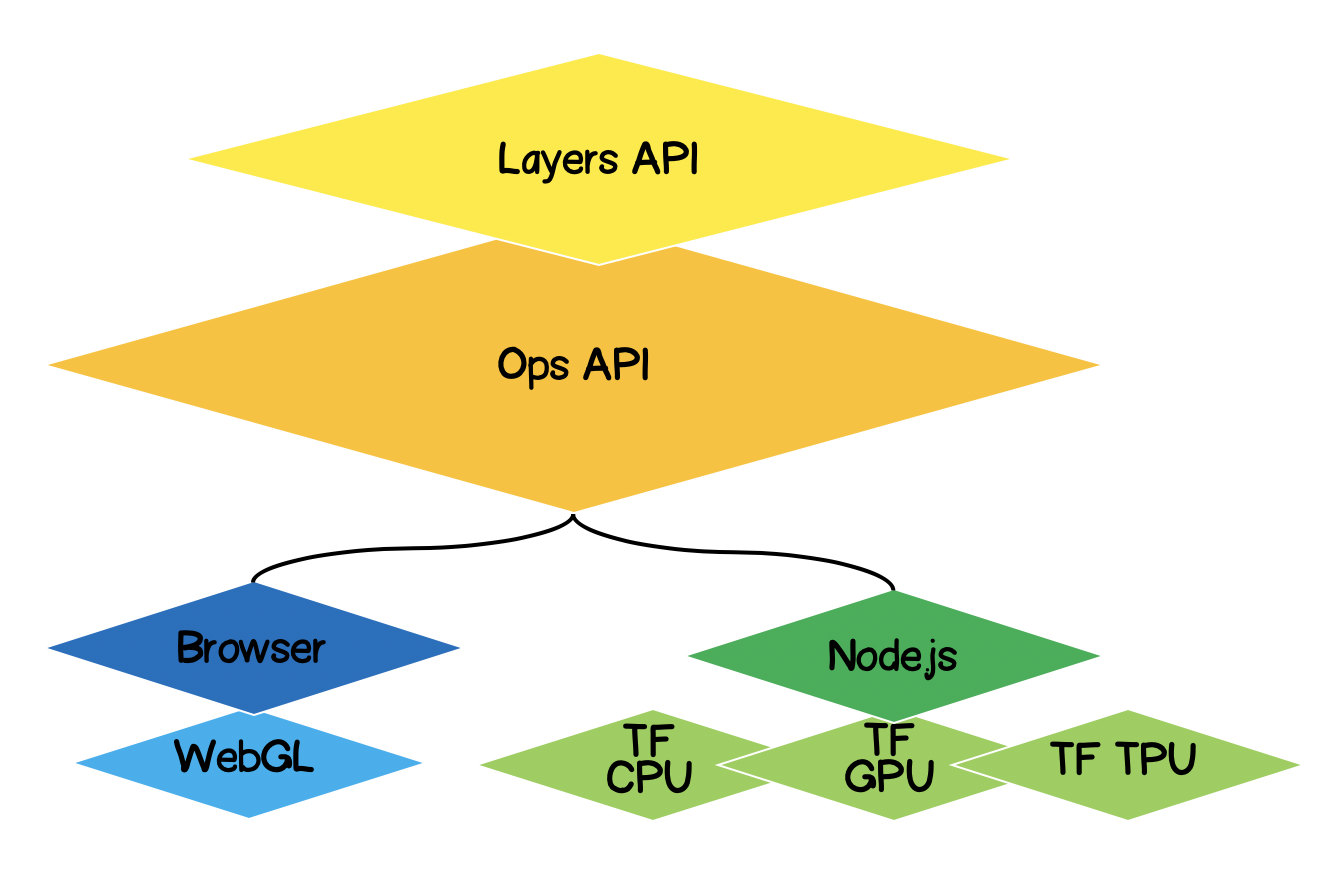
Arquitectura de TensorFlow.js
- Capa más baja : esta capa es responsable de paralelizar los cálculos al realizar operaciones matemáticas en tensores.
- La API de Operaciones - Proporciona API para realizar operaciones matemáticas con tensores.
- API de capas : le permite crear modelos complejos de redes neuronales utilizando diferentes tipos de capas (densas, convolucionales). Esta capa es similar a la API Keras Python y tiene la capacidad de cargar redes basadas en Keras Python previamente entrenadas.
Formulación del problema
Es necesario encontrar la ecuación de la función lineal de aproximación para un conjunto dado de puntos experimentales. En otras palabras, necesitamos encontrar una curva lineal que se encuentre más cerca de los puntos experimentales.

Formalización de la solución
El núcleo de cualquier aprendizaje automático será un modelo, en nuestro caso esta es la ecuación de una función lineal:
Según la condición, también tenemos un conjunto de puntos experimentales:
Supongamos que en ésimo paso de entrenamiento, se calcularon los siguientes coeficientes de la ecuación lineal . Ahora necesitamos expresar matemáticamente qué tan precisos son los coeficientes seleccionados. Para hacer esto, necesitamos calcular el error (pérdida), que se puede determinar, por ejemplo, por la desviación estándar. Tensorflow.js ofrece un conjunto de funciones de pérdida de uso común:tf.metrics.meanAbsoluteError,tf.metrics.meanSquaredError, etc.
El propósito de la aproximación es minimizar la función de error . Usemos el método de descenso de gradiente para esto. Es necesario:
- - encontrar el vector de gradiente calculando las derivadas parciales con respecto a los coeficientes ;
- - corregir los coeficientes de la ecuación en la dirección opuesta a la dirección del vector de gradiente. De esta forma minimizaremos la función de error:
es la tasa de aprendizaje y es uno de los parámetros ajustables del modelo. Para el descenso de gradientes, no cambia durante el proceso de aprendizaje. Un valor pequeño de la tasa de aprendizaje puede conducir a una larga convergencia del proceso de aprendizaje del modelo y un posible acierto en el mínimo local (Figura 2), y un valor muy grande puede conducir a un aumento infinito en el valor del error en cada paso del entrenamiento, Figura 1.
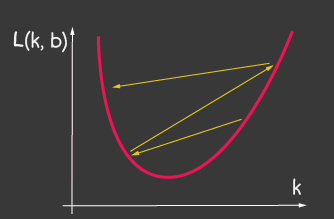
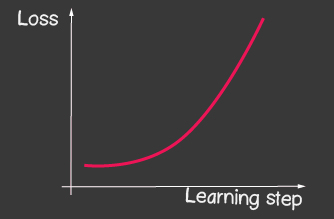
|


|
|---|---|
| Figura 1: El alto valor de la tasa de aprendizaje | Figura 2: Pequeña tasa de aprendizaje |
Cómo implementarlo sin Tensorflow.js
Por ejemplo, calcular el valor de la función de pérdida (desviación estándar) se vería así:
function loss(ysPredicted, ysReal) {
const squaredSum = ysPredicted.reduce(
(sum, yPredicted, i) => sum + (yPredicted - ysReal[i]) ** 2,
0);
return squaredSum / ysPredicted.length;
}
Sin embargo, la cantidad de datos de entrada puede ser grande. Mientras entrenamos el modelo, necesitamos calcular no solo el valor de la función de pérdida en cada iteración, sino también realizar operaciones más serias: calcular el gradiente. Por lo tanto, tiene sentido usar tensorflow, que optimiza los cálculos usando WebGL. Además, el código se vuelve mucho más expresivo, compare:
function loss(ysPredicted, ysReal) => {
const ysPredictedTensor = tf.tensor(ysPredicted);
const ysRealTensor = tf.tensor(ysReal);
const loss = ysPredictedTensor.sub(ysRealTensor).square().mean();
return loss.dataSync()[0];
};
Solución con TensorFlow.js
La buena noticia es que no tendremos que escribir optimizadores para una función de error dada (pérdida), no desarrollaremos métodos numéricos para calcular derivadas parciales, ya hemos implementado el algoritmo de retropropogación para nosotros. Solo debemos seguir estos pasos:
- establecer un modelo (función lineal, en nuestro caso);
- describir la función de error (en nuestro caso, esta es la desviación estándar)
- elija uno de los optimizadores implementados (es posible ampliar la biblioteca con su propia implementación)
Que es tensor
Absolutamente todo el mundo se ha encontrado con tensores en matemáticas - estos son escalares, vectoriales, 2D - matriz, 3D - matriz. Un tensor es un concepto generalizado de todos los anteriores. Es un contenedor de datos que contiene datos de tipo homogéneo (tensorflow admite int32, float32, bool, complex64, string) y tiene una forma específica (el número de ejes (rango) y el número de elementos en cada uno de los ejes). A continuación consideraremos tensores hasta matrices 3D, pero como se trata de una generalización, un tensor puede tener tantos ejes como queramos: 5D, 6D, ... ND.
TensorFlow tiene la siguiente API para la generación de tensor:
tf.tensor (values, shape?, dtype?)donde forma es la forma del tensor y viene dada por una matriz, en la que el número de elementos es el número de ejes, y cada valor de la matriz determina la cantidad de elementos a lo largo de cada uno de los ejes. Por ejemplo, para definir una matriz de 4x2 (4 filas, 2 columnas), el formulario tomará el formato [4, 2].
| Visualización | Descripción |
|---|---|

|
Rango escalar : 0 Forma: [] Estructura JS: API de TensorFlow: |

|
Rango vectorial : 1 Forma: [4] Estructura JS: API de TensorFlow: |
 |
Rango de matriz : 2 Forma: [4,2] Estructura JS: API de TensorFlow: |
 |
Rango de matriz : 3 Forma: [4,2,3] Estructura JS: API de TensorFlow: |
Aproximación lineal con TensorFlow.js
Inicialmente, hablaremos sobre cómo hacer extensible el código. Podemos transformar la aproximación lineal en una aproximación de los puntos experimentales mediante una función de cualquier tipo. La jerarquía de clases se verá así:

Comencemos a implementar los métodos de la clase abstracta, con la excepción de los métodos abstractos que se definirán en las clases secundarias, y aquí solo dejaremos stubs con errores, si por alguna razón el método no está definido en la clase secundaria.
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
}Entonces, en el constructor del modelo, hemos definido el ancho y la altura; estos son el ancho y la altura reales del plano en el que colocaremos los puntos experimentales. Esto es necesario para normalizar los datos de entrada. Aquellos. si tenemos , luego de la normalización tendremos:
OptimizerFunction: hagamos el trabajo del optimizador flexible para que podamos probar otros optimizadores disponibles en la biblioteca, por defecto establecemos el método Stochastic Gradient Descenttf.train.sgd. También recomendaría jugar con otros optimizadores disponibles que pueden modificar la tasa de aprendizaje durante el entrenamiento y el proceso de aprendizaje se mejora considerablemente, por ejemplo, pruebe los siguientes optimizadores:tf.train.momentum, tf.train.adam .
Para asegurar que el proceso de aprendizaje no es infinito, se han definido dos parámetros maxEpochPerTrainSesion y expectedLoss - de esta manera vamos a detener el proceso de aprendizaje, ya sea cuando se alcanza el número máximo de iteraciones de entrenamiento, o cuando el valor de la función de error se hace menor que el error esperado (vamos a tener todo en cuenta en el tren método más adelante).
En el constructor, llamamos al método initModelVariables , pero como se acordó, lo definimos en la clase secundaria más adelante.
initModelVariables() {
throw Error('Model variables should be defined')
}
Ahora implementemos el método principal del modelo de tren:
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert array into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
trainSession es esencialmente un identificador único para la sesión de entrenamiento en caso de que la API externa llame al método train, mientras que la sesión de entrenamiento anterior aún no ha terminado.
En el código puede ver que creamos tensor1d a partir de matrices unidimensionales, mientras que los datos deben normalizarse de antemano, las funciones para la normalización están aquí:
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
En un bucle, para cada paso de entrenamiento, llamamos al optimizador de modelo, al que debemos pasar la función de pérdida. Según lo acordado, la función de pérdida se establecerá mediante la desviación estándar. Luego, usando la API tensorflow.js tenemos:
/**
* Calculate loss function as mean-square deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
// L = sum ((x_pred_i - x_real_i)^2) / N
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
El proceso de aprendizaje continúa mientras
- no se alcanzará el límite en el número de iteraciones
- no se logrará la precisión de error deseada
- no se ha iniciado un nuevo proceso de formación
Observe también cómo se llama a la función de pérdida. Para obtener predictedValue - llamamos a la función f - que, de hecho, establecerá la forma según la cual se realizará la regresión, y en la clase abstracta, según lo acordado, ponemos un stub:
f(x) {
throw Error('Model should be defined')
}
En cada paso del entrenamiento, en la propiedad del objeto del modelo histórico, guardamos la dinámica del cambio de error en cada época de entrenamiento.
Después del proceso de entrenamiento del modelo, necesitamos tener un método que acepte entradas y salidas de los resultados calculados usando el modelo entrenado. Para hacer esto, en la API, hemos definido el método de predicción y se ve así:
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
Preste atención a arraySync , por analogía con node.js, si hay un método arraySync , definitivamente hay un método de matriz asincrónico que devuelve una Promise. Se necesita promesa aquí, porque como dijimos anteriormente, todos los tensores se migran a WebGL para acelerar los cálculos y el proceso se vuelve asíncrono, porque lleva tiempo mover datos de WebGL a una variable JS.
Hemos terminado con una clase abstracta, puedes ver la versión completa del código aquí:
AbstractRegressionModel.js
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
initModelVariables() {
throw Error('Model variables should be defined')
}
f() {
throw Error('Model should be defined')
}
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
/**
* Calculate loss function as mean-squared deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert data into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
stop() {
this.trainSession++;
}
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
}
Para la regresión lineal, definamos una nueva clase que heredará de la clase abstracta, donde solo necesitamos definir dos métodos initModelVariables y f .
Dado que estamos trabajando en una aproximación lineal, debemos especificar dos variables k, b - y serán tensores escalares. Para el optimizador, debemos indicar que son ajustables (variables) y asignar números arbitrarios como valores iniciales.
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}Considere la API para la variable aquí :
tf.variable (initialValue, trainable?, name?, dtype?)Preste atención al segundo argumento de entrenable : una variable booleana y, por defecto, es verdadera . Lo utilizan los optimizadores, lo que les indica si es necesario configurar esta variable al minimizar la función de pérdida. Esto puede ser útil cuando estamos construyendo un nuevo modelo basado en un modelo preentrenado descargado de Keras Python, y estamos seguros de que no hay necesidad de reentrenar algunas capas en este modelo.
A continuación, necesitamos definir la ecuación de la función de aproximación usando la API de tensorflow, eche un vistazo al código y comprenderá intuitivamente cómo usarlo:
f(x) {
// y = kx + b
return x.mul(this.k).add(this.b);
}Por ejemplo, de esta manera puede definir una aproximación cuadrática:
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f(x) {
// y = ax^2 + bx + c
return this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}Puede consultar los modelos de regresión lineal y cuadrática aquí:
LinearRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class LinearRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}
f = x => x.mul(this.k).add(this.b);
}
QuadraticRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class QuadraticRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f = x => this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}
A continuación se muestra un código escrito en React que usa el modelo de regresión lineal escrito y crea la UX para el usuario:
Regression.js
import React, { useState, useEffect } from 'react';
import Canvas from './components/Canvas';
import LossPlot from './components/LossPlot_v3';
import LinearRegressionModel from './model/LinearRegressionModel';
import './RegressionModel.scss';
const WIDTH = 400;
const HEIGHT = 400;
const LINE_POINT_STEP = 5;
const predictedInput = Array.from({ length: WIDTH / LINE_POINT_STEP + 1 })
.map((v, i) => i * LINE_POINT_STEP);
const model = new LinearRegressionModel(WIDTH, HEIGHT);
export default () => {
const [points, changePoints] = useState([]);
const [curvePoints, changeCurvePoints] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
if (points.length > 0) {
const input = points.map(({ x }) => x);
const output = points.map(({ y }) => y);
model.train(input, output, () => {
changeCurvePoints(() => model.predict(predictedInput));
changeLossHistory(() => model.history);
});
}
}, [points]);
return (
<div className="regression-low-level">
<div className="regression-low-level__top">
<div className="regression-low-level__workarea">
<div className="regression-low-level__canvas">
<Canvas
width={WIDTH}
height={HEIGHT}
points={points}
curvePoints={curvePoints}
changePoints={changePoints}
/>
</div>
<div className="regression-low-level__toolbar">
<button
className="btn btn-red"
onClick={() => model.stop()}>Stop
</button>
<button
className="btn btn-yellow"
onClick={() => {
model.stop();
changePoints(() => []);
changeCurvePoints(() => []);
}}>Clear
</button>
</div>
</div>
<div className="regression-low-level__loss">
<LossPlot
loss={lossHistory}/>
</div>
</div>
</div>
)
}Resultado:
Recomiendo encarecidamente realizar las siguientes tareas:
- para implementar la aproximación de la función por la función logarítmica
- para el optimizador tf.train.sgd, intente jugar con learningRate y observe cómo cambia el proceso de aprendizaje. Intente establecer la tasa de aprendizaje muy alta para obtener la imagen que se muestra en la Figura 2.
- configure el optimizador en tf.train.adam. ¿Ha mejorado el proceso de aprendizaje? Si el proceso de aprendizaje depende de cambiar el valor de learningRate en el constructor del modelo.