Primero, nos familiarizaremos brevemente con los métodos de atravesar gráficos, escribiremos la búsqueda de ruta real y luego pasaremos al más delicioso: optimizar el rendimiento y los costos de memoria. Idealmente, debería desarrollar una implementación que no genere basura en absoluto cuando se utiliza.
Me sorprendió cuando una búsqueda superficial no me proporcionó una sola buena implementación del algoritmo A * en C # sin usar bibliotecas de terceros (esto no significa que no haya ninguna). ¡Así que es hora de estirar los dedos!
Estoy esperando un lector que quiera comprender el trabajo de los algoritmos de búsqueda de caminos, así como expertos en algoritmos para familiarizarse con la implementación y los métodos de su optimización.
¡Empecemos!
Una excursión a la historia
Una malla bidimensional se puede representar como un gráfico, donde cada uno de los vértices tiene 8 aristas:
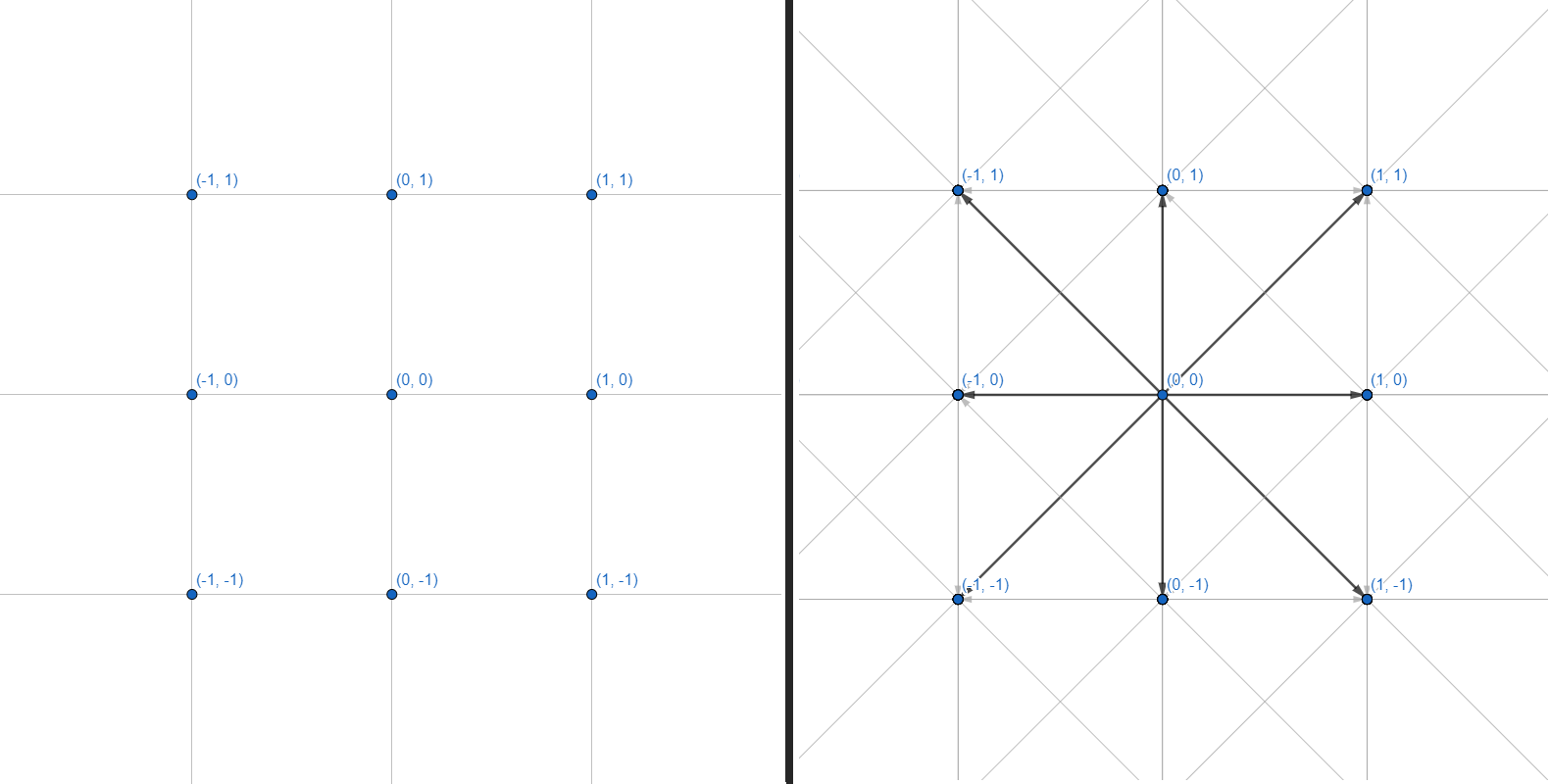
Trabajaremos con gráficos. Cada vértice es una coordenada entera. Cada borde es una transición recta o diagonal entre coordenadas adyacentes. No haremos la cuadrícula de coordenadas y el cálculo de la geometría de los obstáculos, nos restringiremos a una interfaz que acepta varias coordenadas como entrada y devuelve un conjunto de puntos para construir un camino:
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}Para empezar, considere los métodos existentes para atravesar el gráfico.
Búsqueda de profundidad
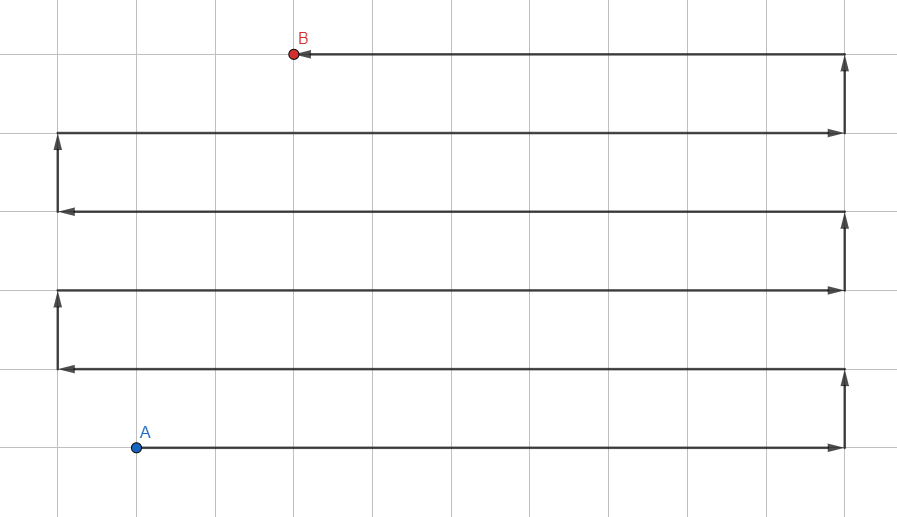
El más simple de los algoritmos:
- Agregue todos los vértices no visitados cerca del actual a la pila.
- Muévase al primer vértice de la pila.
- Si el vértice es el deseado, salga del ciclo. Si llega a un callejón sin salida, regrese.
- GOTO 1.
Se parece a esto:
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
Está organizado en el formato LIFO ( Last in - First out ), donde los vértices recién agregados se analizan primero. Cada transición entre los vértices debe ser monitoreada para luego construir la ruta real a lo largo de las transiciones.
Este enfoque nunca (bueno, casi) devolverá el camino más corto ya que procesa el gráfico en una dirección aleatoria. Es más adecuado para gráficos pequeños para determinar sin dolor de cabeza si hay al menos algún camino hacia el vértice deseado (por ejemplo, si el enlace deseado está presente en el árbol tecnológico).
En el caso de una cuadrícula de navegación y gráficos infinitos, esta búsqueda irá interminablemente en una dirección y desperdiciará recursos informáticos sin llegar al punto deseado. Esto se resuelve limitando el área en la que opera el algoritmo. Hacemos que analice solo los puntos ubicados a no más de N pasos del inicial. Así, cuando el algoritmo alcanza el borde de la región, se despliega y continúa analizando los vértices dentro del radio especificado.
A veces es imposible determinar con precisión el área, pero no desea establecer el borde al azar. Una búsqueda iterativa en profundidad viene al rescate :
- Establezca el área mínima para DFS.
- Iniciar busqueda.
- Si no se encuentra la ruta, aumente el área de búsqueda en 1.
- GOTO 2.
El algoritmo se ejecutará una y otra vez, cada vez cubriendo un área más grande hasta que finalmente encuentre el punto deseado.
Puede parecer una pérdida de energía volver a ejecutar el algoritmo en un radio un poco más grande (de todos modos, la mayor parte del área ya se ha analizado en la última iteración), pero no: el número de transiciones entre vértices crece geométricamente con cada aumento de radio. Será mucho más caro tomar un radio más grande del que necesita que caminar varias veces a lo largo de radios pequeños.
Es fácil para una búsqueda de este tipo ajustar un límite de temporizador: buscará una ruta con un radio en expansión exactamente hasta que finalice el tiempo especificado.
Amplitud primera búsqueda
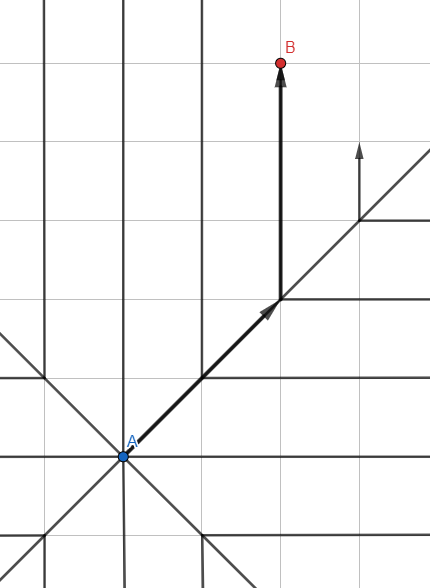
La ilustración puede parecerse a Jump Search , pero este es el algoritmo de onda habitual , y las líneas representan las rutas de propagación de la búsqueda con los puntos intermedios eliminados.
En contraste con la búsqueda en profundidad usando una pila (LIFO), tomemos una cola (FIFO) para procesar los vértices:
- Agregue todos los vecinos no visitados a la cola.
- Ve al primer vértice de la cola.
- Si el vértice es el deseado, salga del ciclo, de lo contrario GOTO 1.
Se parece a esto:
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
Este enfoque proporciona la ruta óptima , pero hay una trampa: dado que el algoritmo procesa vértices en todas las direcciones, funciona muy lentamente en largas distancias y gráficos con fuertes ramificaciones. Este es solo nuestro caso.
Aquí, el área de operación del algoritmo no se puede limitar, porque en cualquier caso no irá más allá del radio hasta el punto deseado. Se necesitan otros métodos de optimización.
UN *
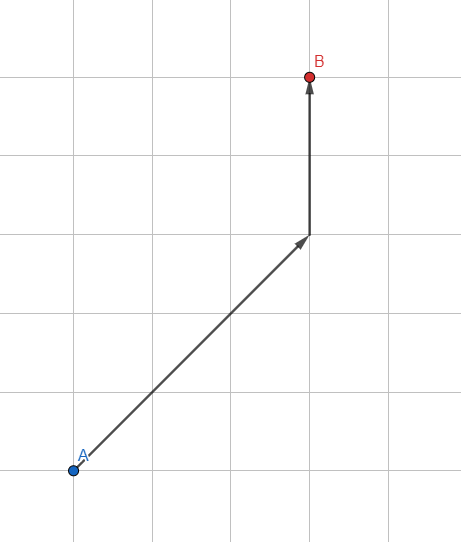
Modifiquemos el estándar Breadth First Search: no usamos una cola normal para almacenar vértices, sino una cola ordenada basada en heurísticas , una estimación aproximada de la ruta esperada.
¿Cómo estimar el camino esperado? El más simple es la longitud del vector desde el vértice procesado hasta el punto deseado. Cuanto más pequeño es el vector, más prometedor es el punto y más cerca del comienzo de la cola se vuelve. El algoritmo dará prioridad a aquellos vértices que se encuentren en la dirección de la meta.
Así, cada iteración dentro del algoritmo tomará un poco más de tiempo debido a cálculos adicionales, pero al reducir el número de vértices para el análisis (solo se procesarán los más prometedores), logramos un tremendo aumento en la velocidad del algoritmo.
Pero todavía hay muchos vértices procesados. Encontrar la longitud de un vector es una operación costosa que implica calcular la raíz cuadrada. Por lo tanto, usaremos un cálculo simplificado para la heurística.
Creemos un vector entero:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}Una estructura estándar para almacenar un par de coordenadas. Aquí vemos el almacenamiento en caché de raíz cuadrada para que se pueda calcular solo una vez. La interfaz IEquatable nos permitirá comparar vectores entre sí sin tener que traducir Vector2Int al objeto y viceversa. Esto acelerará enormemente nuestro algoritmo y eliminará las asignaciones innecesarias.
DistanceEstimate () se utiliza para estimar la distancia aproximada al objetivo calculando el número de transiciones rectas y diagonales. Una forma alternativa es común:
return Math.Max(Math.Abs(X), Math.Abs(Y))Esta opción funcionará aún más rápido, pero esto se compensa con la baja precisión de la estimación de la distancia diagonal.
Ahora que tenemos una herramienta para trabajar con coordenadas, creemos un objeto que represente la parte superior del gráfico:
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}En Padre, registraremos el vértice anterior para cada uno nuevo: esto ayudará a construir la ruta final por puntos. Además de las coordenadas, también almacenamos la distancia recorrida y el costo estimado de la ruta para que luego podamos seleccionar los vértices más prometedores para su procesamiento.
Esta clase pide una mejora, pero volveremos a ella más tarde. Por ahora, desarrollemos un método que genere los vecinos del vértice:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighboursTemplate: una plantilla predefinida para crear vecinos lineales y diagonales del punto deseado. También tiene en cuenta el mayor costo de las transiciones diagonales.
GenerateNeighbors: un generador que atraviesa NeighborsTemplate y devuelve un nuevo vértice para los ocho lados adyacentes.
Sería posible introducir la funcionalidad dentro de PathNode, pero se siente como una ligera violación de SRP. Y tampoco quiero agregar funcionalidad de terceros dentro del algoritmo en sí: mantendremos las clases lo más compactas posible.
¡Es hora de abordar la clase principal de búsqueda de caminos!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodes trabaja con dos colecciones: frontier, que contiene una cola de vértices para análisis, e ignoredPositions, a las que se agregan vértices ya procesados.
Cada iteración del ciclo encuentra el vértice más prometedor, comprueba si hemos alcanzado el punto final y genera nuevos vecinos para este vértice.
Y toda esta belleza encaja en 50 líneas.
Queda por implementar la interfaz:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodes nos devuelve el vértice final, y como escribimos un vecino padre para cada uno de ellos, es suficiente recorrer todos los padres hasta el vértice inicial, y obtenemos el camino más corto. ¡Todo esta bien!
¿O no?
Optimización de algoritmos
1. PathNode
Empecemos de forma sencilla. Simplifiquemos PathNode:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}Este es un contenedor de datos común que también se crea con mucha frecuencia. No hay razón para convertirlo en una clase y cargar memoria cada vez que escribimos algo nuevo . Por lo tanto, usaremos struct.
Pero hay un problema: las estructuras no pueden contener referencias circulares a su propio tipo. Entonces, en lugar de almacenar el Padre dentro del PathNode, necesitamos otra forma de rastrear la construcción de caminos entre vértices. Es fácil: agreguemos una nueva colección a la clase Path:
private readonly Dictionary<Vector2Int, Vector2Int> links;Y modificamos ligeramente la generación de vecinos:
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}En lugar de escribir el padre en el vértice, escribimos la transición al diccionario. Como beneficio adicional, el diccionario puede funcionar directamente con Vector2Int, y no con PathNode, ya que solo necesitamos coordenadas y nada más.
La generación del resultado dentro de Calculate también se simplifica:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
A continuación, hablemos de la generación de vecinos. IEnumerable, a pesar de todos sus beneficios, genera una triste cantidad de basura en muchas situaciones. Vamos a deshacernos de él:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}Ahora nuestro método de extensión no es un generador: solo llena el búfer que se le pasa como argumento. El búfer se almacena como otra colección dentro de la Ruta:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];Y se usa así:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
En lugar de usar List, usemos HashSet:
private readonly HashSet<Vector2Int> ignoredPositions;Es mucho más eficiente cuando se trabaja con colecciones grandes, el método ignoredPositions.Contains () consume muchos recursos debido a la frecuencia de las llamadas. Un simple cambio de tipo de colección aumentará notablemente el rendimiento.
4. BinaryHeap
Hay un lugar en nuestra implementación que ralentiza el algoritmo diez veces:
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);La lista en sí es una mala elección y el uso de Linq empeora las cosas.
Idealmente, queremos una colección con:
- Clasificación automática.
- Bajo crecimiento de complejidad asintótica.
- Operación de inserción rápida.
- Operación de extracción rápida.
- Fácil navegación a través de los elementos.
SortedSet puede parecer una buena opción, pero no sabe cómo contener duplicados. Si escribimos ordenando por EstimatedTotalCost, entonces se eliminarán todos los vértices con el mismo precio (¡pero diferentes coordenadas!). En áreas abiertas con una pequeña cantidad de obstáculos, esto no da miedo, además de que acelerará el algoritmo, pero en laberintos estrechos, el resultado será rutas inexactas y resultados falsos negativos.
Así que estamos implementando nuestra colección: ¡el montón binario ! La implementación clásica satisface 4 de 5 requisitos, y una pequeña modificación hará que esta colección sea ideal para nuestro caso.
La colección es un árbol parcialmente ordenado, con la complejidad de las operaciones de inserción y eliminación igual a log (n) .
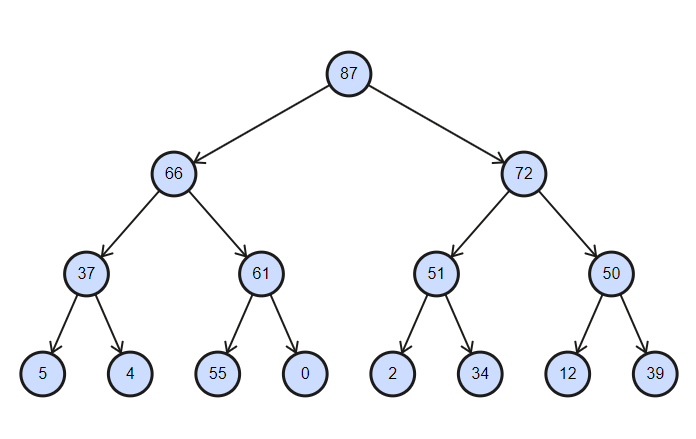
Montón binario ordenado en orden descendente
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}Escribamos la parte fácil:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}Usaremos IComparer para la clasificación personalizada de vértices. IList es en realidad el almacén de vértices con el que trabajaremos. Necesitamos IDictionary para realizar un seguimiento de los índices de los vértices para su eliminación rápida (la implementación estándar del montón binario nos permite trabajar convenientemente solo con el elemento superior).
Agreguemos un elemento:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}Cada nuevo elemento se agrega a la última celda del árbol, después de lo cual se ordena parcialmente de abajo hacia arriba: por nodos desde el nuevo elemento hasta la raíz, hasta que el elemento más pequeño sea lo más alto posible. Dado que no se ordena toda la colección, sino solo los nodos intermedios entre el superior y el último, la operación tiene el registro de complejidad (n) .
Obtener un artículo:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}Por analogía con la suma: se elimina el elemento raíz y se coloca el último en su lugar. Luego, una clasificación parcial de arriba hacia abajo intercambia los elementos para que el más pequeño esté en la parte superior.
Después de eso, implementamos la búsqueda de un elemento y lo cambiamos:
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}Aquí no hay nada complicado: buscamos el índice del elemento a través del diccionario, tras lo cual accedemos directamente.
Versión genérica del montón:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}Ahora nuestro pathfinding tiene una velocidad decente y casi no queda generación de basura. ¡El final está cerca!
5. Colecciones reutilizables
El algoritmo se está desarrollando teniendo en cuenta la capacidad de llamarlo docenas de veces por segundo. La generación de cualquier basura es categóricamente inaceptable: un recolector de basura cargado puede (¡y lo hará!) Causar caídas periódicas en el rendimiento.
Todas las colecciones, excepto la salida, ya se declaran una vez cuando se crea la clase, y la última también se agrega allí:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}El método público toma la siguiente forma:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}¡Y no se trata solo de crear colecciones! Las colecciones cambian dinámicamente su capacidad cuando se llenan, si el camino es largo, el cambio de tamaño ocurrirá decenas de veces. Esto requiere mucha memoria. Cuando limpiamos las colecciones y las reutilizamos sin declarar nuevas, conservan su capacidad. La construcción de la primera ruta creará una gran cantidad de basura al inicializar colecciones y cambiar sus capacidades, pero las llamadas posteriores funcionarán bien sin ninguna asignación (siempre que la longitud de cada ruta calculada sea más o menos igual sin distorsiones agudas). De ahí el siguiente punto:
6. (Bonificación) Anuncio del tamaño de las colecciones
Inmediatamente surgen varias preguntas:
- ¿Es mejor descargar la carga al constructor de la clase Path o dejarla en la primera llamada al buscador de caminos?
- ¿Qué capacidad para alimentar las colecciones?
- ¿Es más barato anunciar una mayor capacidad de inmediato o dejar que la colección se expanda por sí sola?
El tercero se puede responder de inmediato: si tenemos cientos y miles de celdas para encontrar un camino, definitivamente será más barato asignar inmediatamente un cierto tamaño a nuestras colecciones.
Las otras dos preguntas son más difíciles de responder. La respuesta a estos debe determinarse empíricamente para cada caso de uso. Si aún decidimos poner la carga en el constructor, entonces es hora de agregar un límite en la cantidad de pasos a nuestro algoritmo:
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}Dentro de GenerateNodes, corrige el bucle:
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}Por tanto, a las colecciones se les asigna inmediatamente una capacidad igual a la ruta máxima. Algunas colecciones contienen no solo los nodos atravesados, sino también sus vecinos: para tales colecciones, puede usar una capacidad 4-5 veces mayor que la especificada.
Puede parecer demasiado, pero para las rutas cercanas al máximo declarado, la asignación del tamaño de las colecciones gasta la mitad o tres veces menos memoria que la expansión dinámica. Por otro lado, si asigna valores muy grandes al valor de maxSteps y genera rutas cortas, tal innovación solo perjudicará. ¡Ah, y no deberías intentar usar int.MaxValue!
La solución óptima sería crear dos constructores, uno de los cuales establece la capacidad inicial de las colecciones. Entonces nuestra clase se puede usar en ambos casos sin modificarla.
¿Qué más puedes hacer?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- Cambie la firma del método en nuestra interfaz para reflejar mejor su esencia:
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
Por lo tanto, el método muestra claramente la lógica de su funcionamiento, mientras que el método original debería haberse llamado así: CalculateOrReturnEmpty .
La versión final de la clase Path:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}Enlace al código fuente