Recientemente, los colegas de la "tienda" de forma independiente comenzaron a preguntarme: ¿cómo obtener todos los canales Bluetooth de un receptor SDR simultáneamente? El ancho de banda lo permite, hay SDR con un ancho de banda de salida de 80 MHz o más. Por supuesto, puede hacer esto en FPGA, pero el tiempo de desarrollo será bastante largo. Sé desde hace mucho tiempo que es bastante fácil hacer esto en una GPU, ¡pero eso es todo!
El estándar Bluetooth define la capa física en dos versiones: Classic y Low Energy. La especificación está aquí . El documento es terriblemente grande, leerlo en su totalidad es peligroso para el cerebro. Afortunadamente, las grandes empresas de instrumentación tienen los medios para crear documentos visuales sobre un tema. Tektronix y National Instruments , por ejemplo. No tengo absolutamente ninguna posibilidad de competir con ellos en términos de la calidad de la presentación del material. Si está interesado, siga los enlaces.
Todo lo que necesito saber sobre la capa física para crear un filtro multicanal es el paso de la cuadrícula de frecuencia y la tasa de modulación. Están tabulados en uno de los documentos especificados:
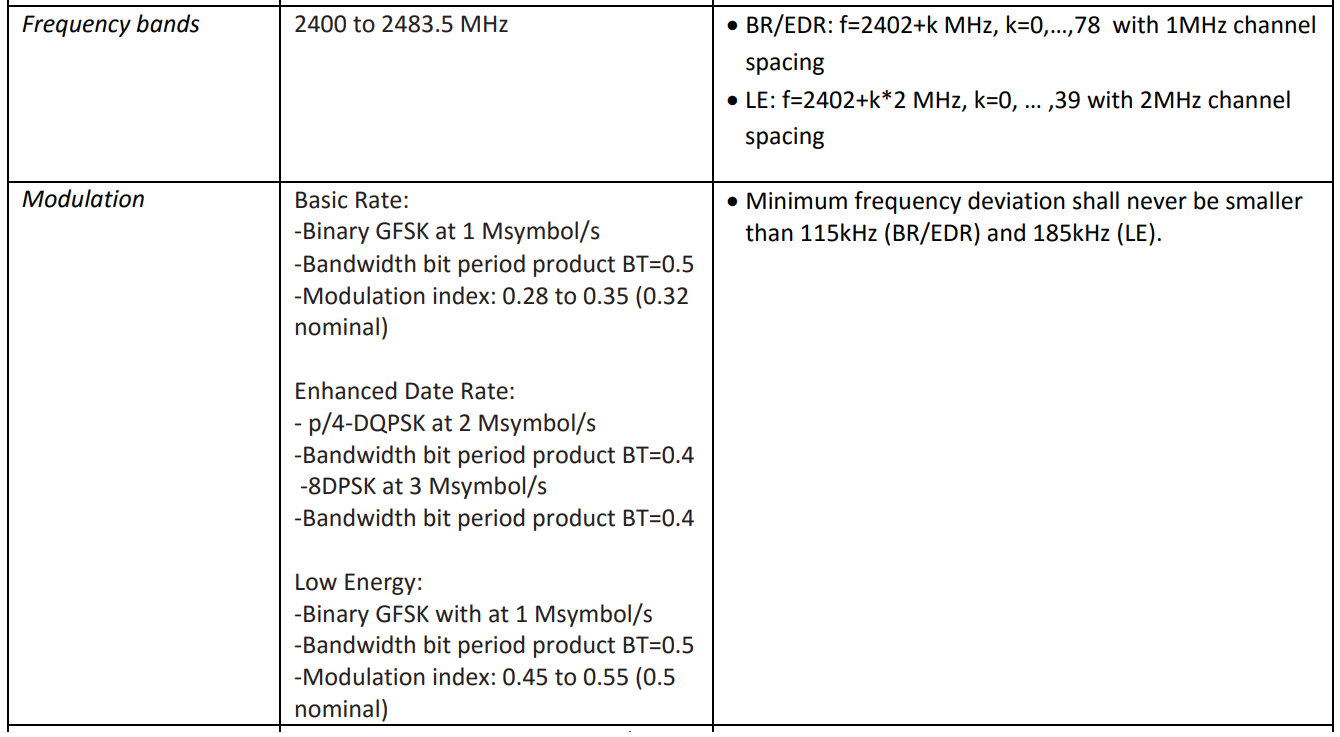
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
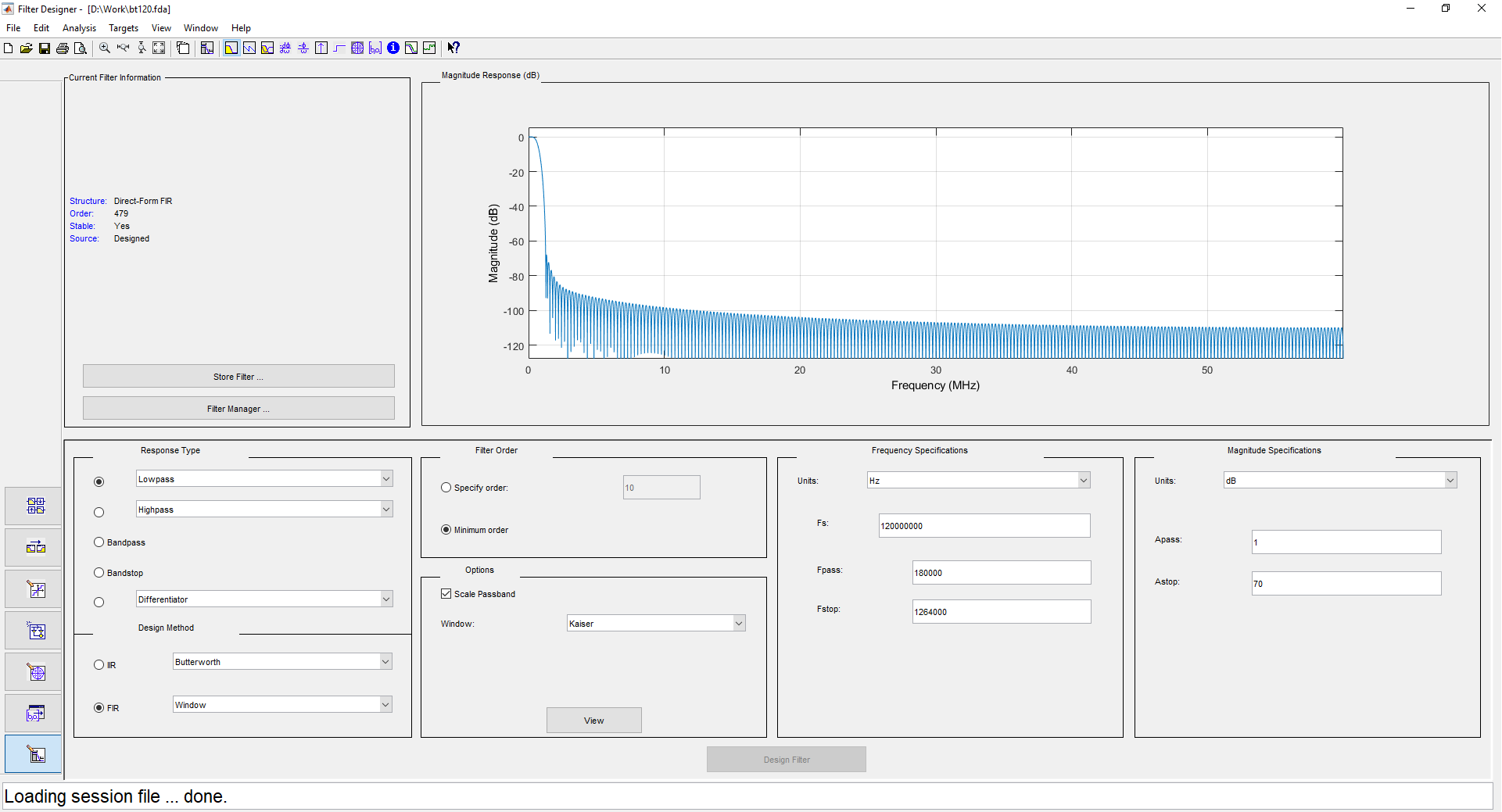
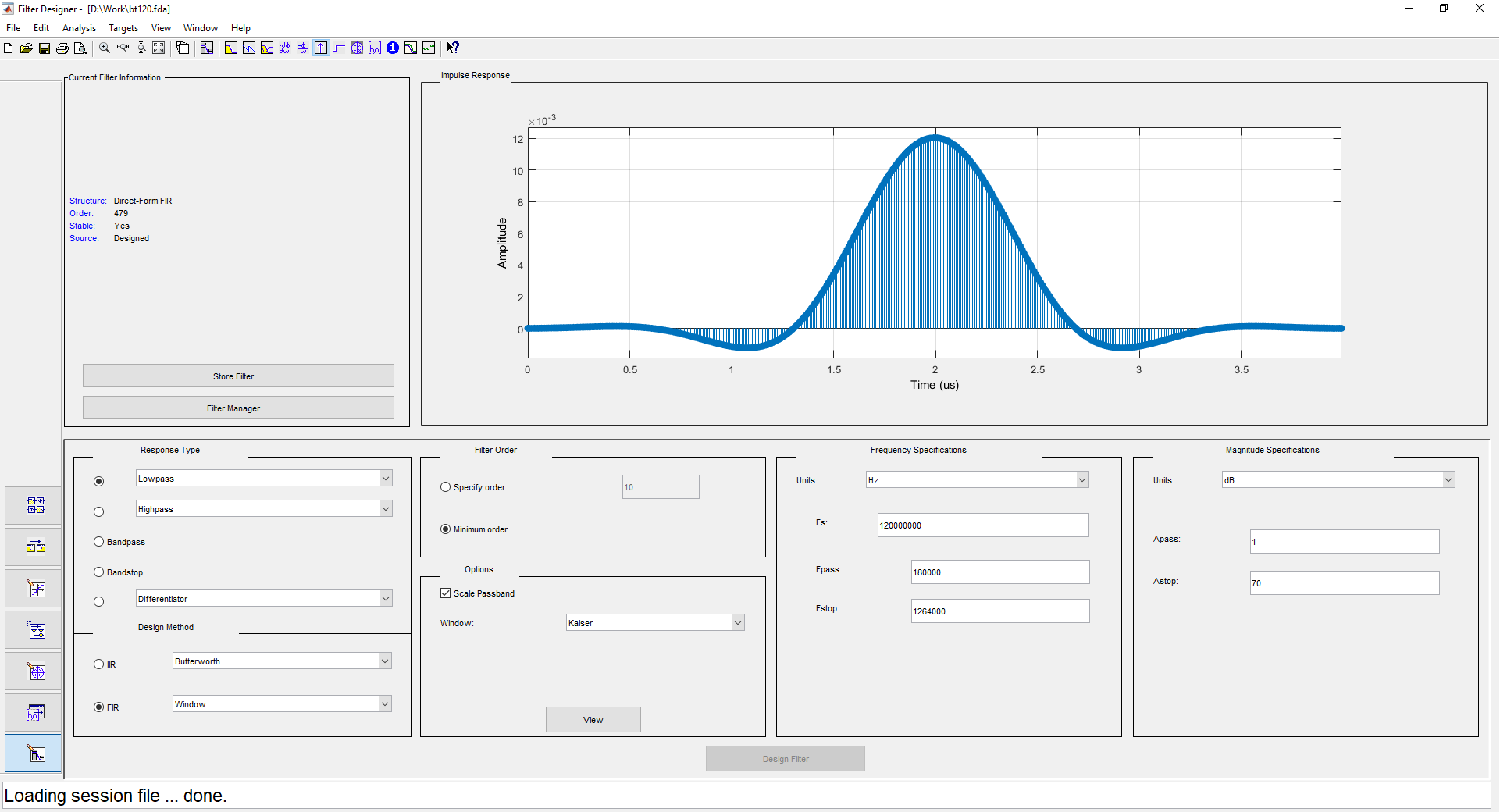
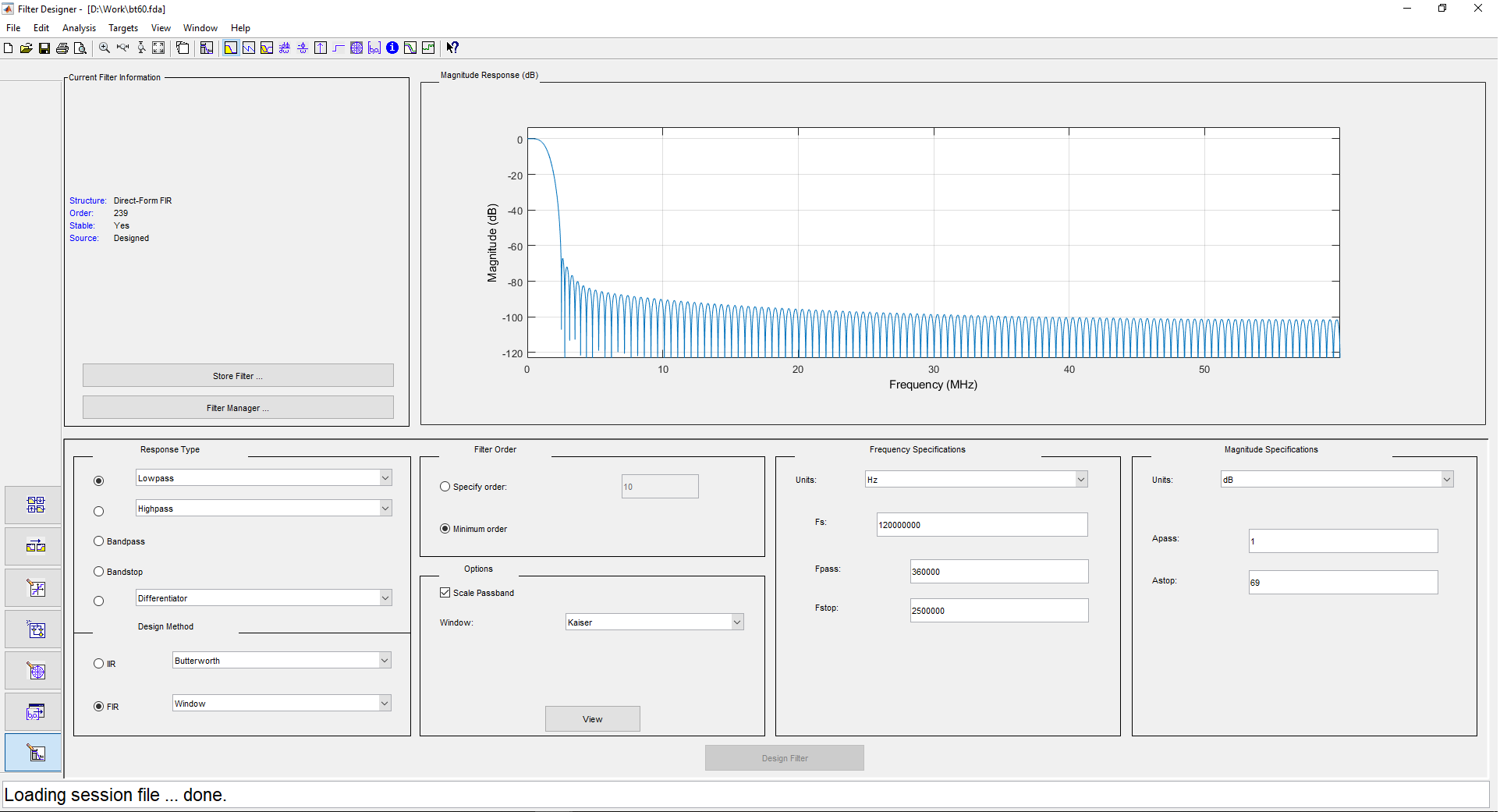
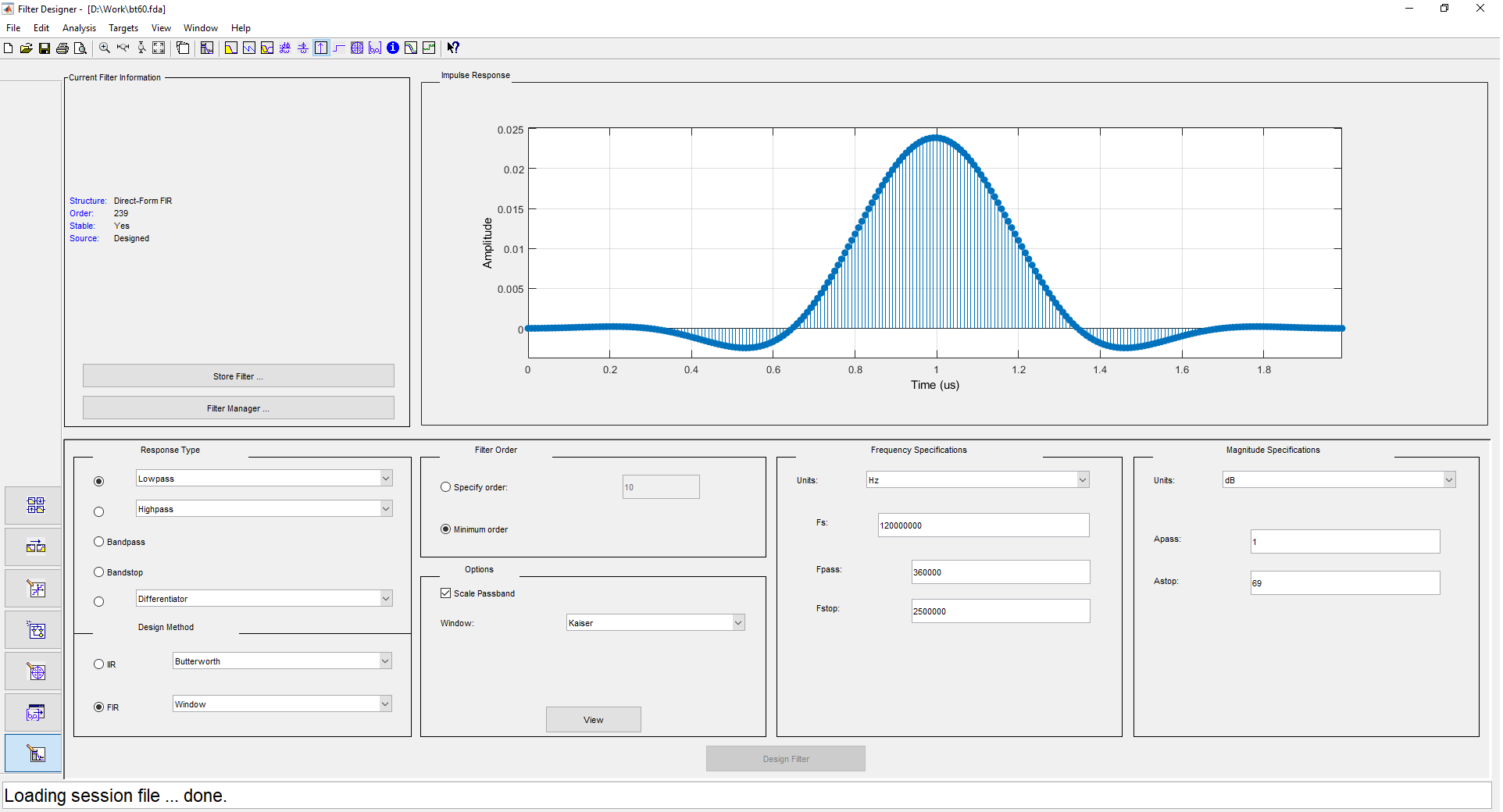
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
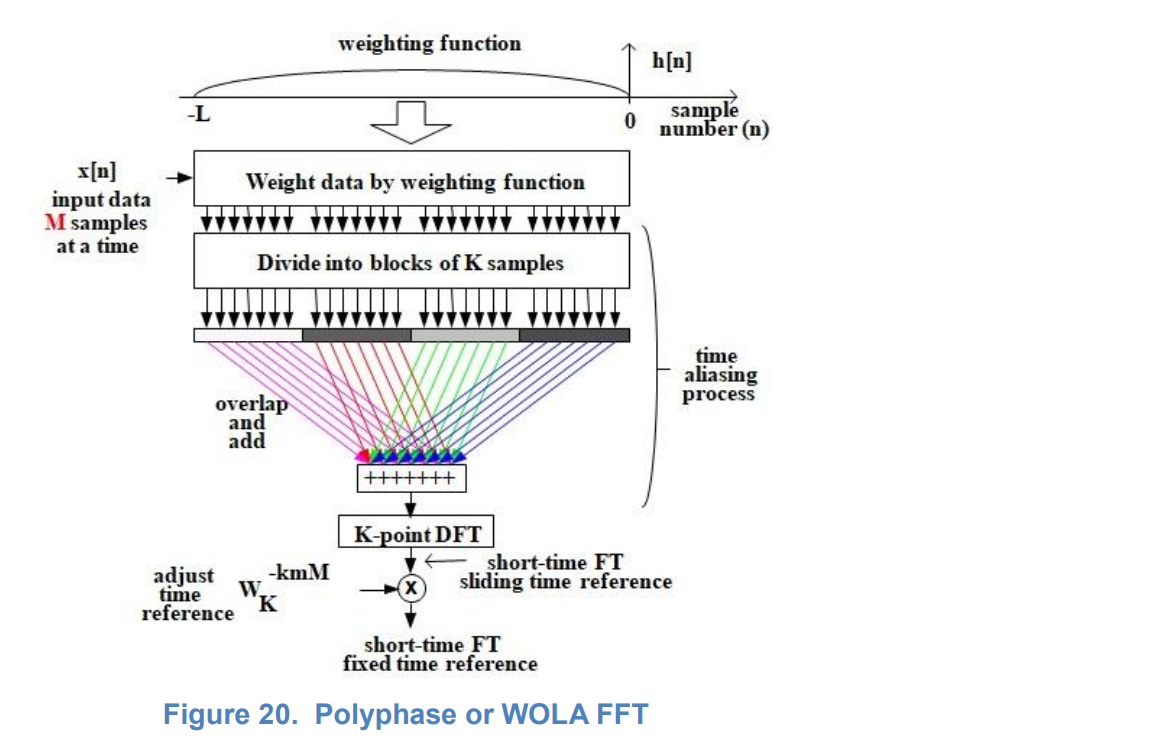
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
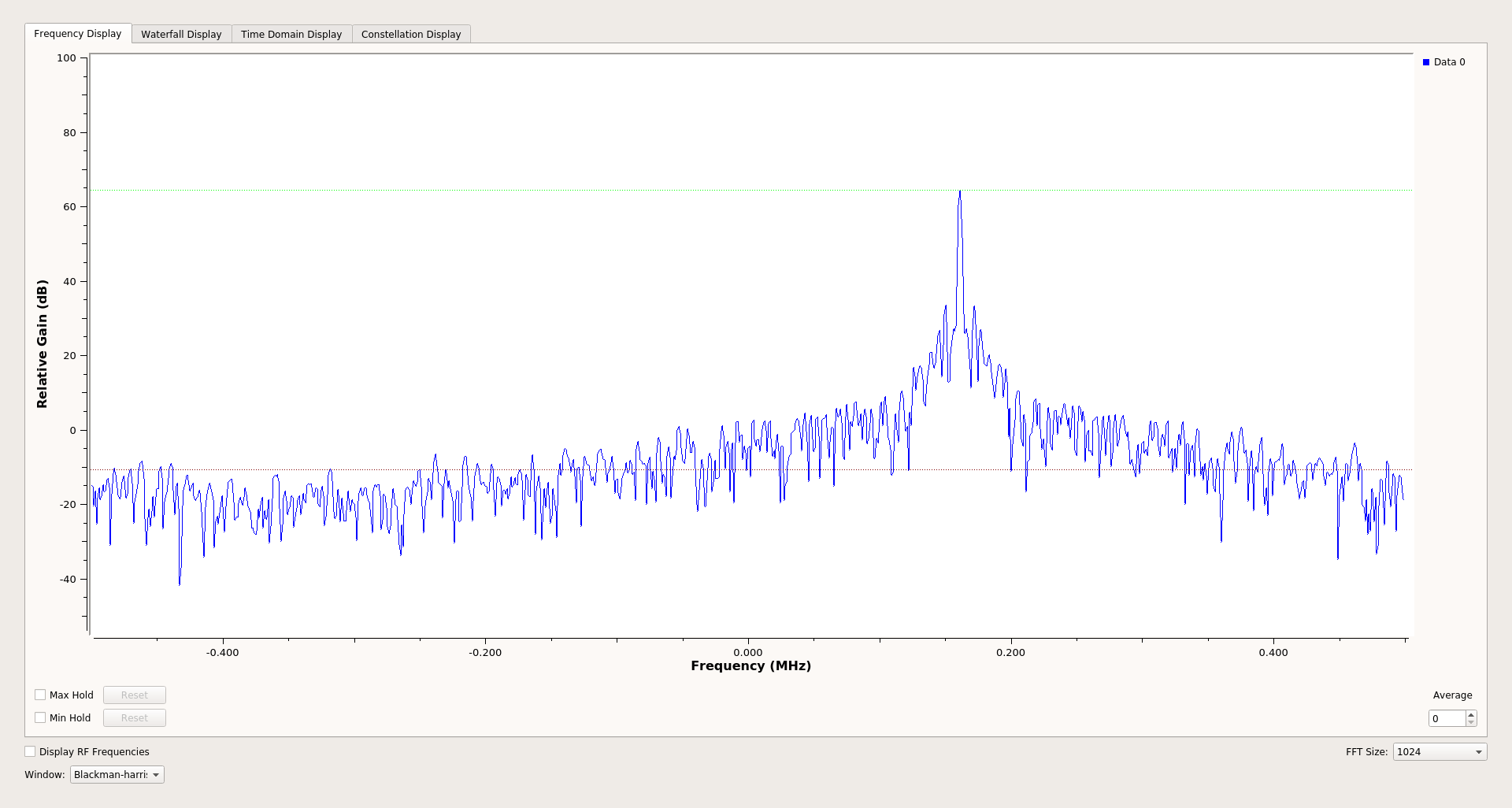
: XRTX , - .
gaudima, !