Ahora debemos aprender a describir la lógica que operará con los datos recibidos y emitir un veredicto sobre si nuestra regla funcionará en una situación determinada. Es esta sección de la regla y sus características a las que está dedicado este artículo. La descripción de la sección lógica de detección es la parte más importante de la sintaxis, cuyo conocimiento es necesario para comprender las reglas existentes y escribir las suyas propias.
En la próxima publicación, nos detendremos en detalle en la descripción de metainformación (atributos que son de naturaleza informativa o de infraestructura, como una descripción o identificador) y colecciones de reglas. ¡Sigue nuestras publicaciones!
Descripción de la lógica de detección (atributo de detección)
Las condiciones de activación de reglas se establecen en el atributo de detección . Sus subcampos describen la parte técnica principal de la regla. Es importante tener en cuenta que una regla solo puede tener una parte descriptiva y varias fuentes de registro y detección. Dado que la sección de detección describe el criterio de activación basado en datos de la sección de fuentes, estas dos secciones tienen un 1 a 1.
En general, el contenido del campo de detección consta de dos partes lógicas:
- una descripción de las suposiciones sobre los campos del evento (ID de búsqueda),
- la relación lógica entre estas descripciones ( período de tiempo y expresión en el campo de condición ).

La descripción de las suposiciones sobre el contenido de los campos del evento se realiza especificando identificadores de búsqueda. Dicho identificador puede ser uno (como aquí ) o puede haber varios de ellos (como aquí ).
La segunda parte puede ser de tres tipos:
- la condición habitual,
- una condición con una expresión agregada (como en el ejemplo anterior),
- condición con la palabra clave cerca .
La sintaxis de los elementos de cada parte se describe en la sección correspondiente de este artículo.
ID de búsqueda
Un identificador de búsqueda es un par clave-valor, donde la clave es el nombre del identificador de búsqueda y el valor es una lista o diccionario (también conocido como matriz asociativa). Por analogía con los lenguajes de programación: lista o mapa. El formato para especificar listas y diccionarios está definido por el estándar YAML, que se puede encontrar aquí . Vale la pena señalar que el formato de la regla Sigma no fija los nombres de los identificadores de búsqueda, pero la mayoría de las veces puede encontrar variaciones con la selección de palabras.
Hay requisitos generales que se aplican tanto a los elementos de la lista como a los elementos de vocabulario:
- Todos los valores se tratan como cadenas que no distinguen entre mayúsculas y minúsculas, es decir, no hay diferencia entre letras mayúsculas y minúsculas.
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
Identificador de búsqueda de lista de valores Las
listas de valores contienen cadenas que se buscan en todo el mensaje del evento. Los elementos de la lista se combinan con un OR lógico.
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

Ejemplos de reglas que contienen identificadores de búsqueda como una lista de valores:
- rules / web / web_apache_segfault.yml (la lista puede contener un elemento)
- reglas / windows / powershell / powershell_clear_powershell_history.yml
- reglas / linux / lnx_shell_susp_log_entries.yml
Identificador de búsqueda de diccionario
Los diccionarios consisten en un conjunto de pares clave-valor, donde la clave es el nombre del campo del evento y el valor puede ser una cadena, un número entero o una lista de uno de estos tipos (las listas de cadenas o números se combinan con un OR lógico). Los conjuntos de diccionarios se combinan mediante un Y lógico
Esquema general:
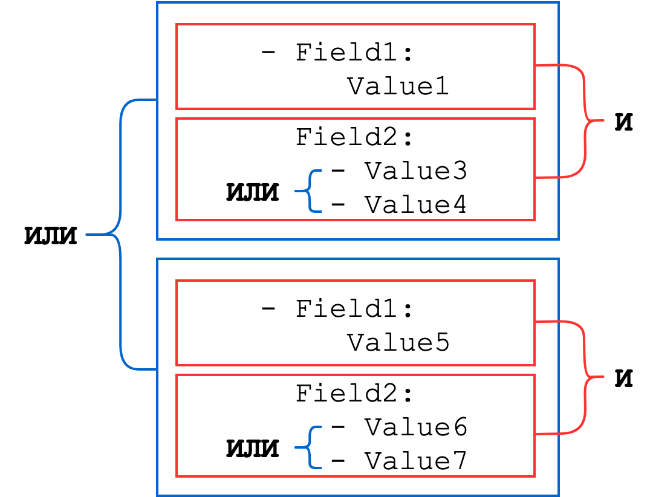
Consideremos varios ejemplos.
Ejemplo 1. Reglas de reglas de detección de limpieza de registros de eventos
/ windows / builtin / win_susp_security_eventlog_cleared.yml
Esta regla se activará si el evento cumple la condición:
EventID = 517 O EventID = 1102
En la regla, se ve así:
detection:
selection:
EventID:
- 517
- 1102
condition: selection Aquí la selección es el nombre del único identificador de búsqueda, y el resto de los subcampos son su valor, y este valor es de tipo "diccionario". En este diccionario, EventID es la clave, y los números 517 y 1102 forman una lista, que es el valor de esta clave de diccionario.
Ejemplo 2. Una solicitud de ticket sospechosa, muy probablemente Kerberoasting
rules / windows / builtin / win_susp_rc4_kerberos.yml
Esta regla se activará si el evento cumple la condición:
EventID = 4679 Y TicketOptions = 0x40810000 Y TicketEncryption = 0x17 Y ServiceName no termina con un signo '$'
En la regla, se ve así:
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction Valores de campo especiales
Hay dos valores de campo especiales que se pueden utilizar:
- Un valor vacío especificado por dos comillas simples ''
- El valor nulo especificado por la palabra clave nula
Nota: no se puede especificar un valor no vacío mediante la construcción no nula
La aplicación de estos valores depende del sistema SIEM de destino. Para describir la condición no nula, debe crear un identificador de búsqueda separado con un valor vacío y quitarle la negación en la condición (el campo de condición, se describe al final del artículo). Considere más ejemplos de reglas que utilizan la descripción de un campo vacío.
Ejemplo 3. Lanzamiento sospechoso de un flujo remoto
rules / windows / sysmon / sysmon_password_dumper_lsass.yml
La regla especificada se activará si el evento cumple la condición:
EventID = 8 AND TargetImage = 'C: \ Windows \ System32 \ lsass.exe' Y StartModule es un campo vacío
En la regla, se ve así:
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection Ejemplo 4. Escritura de un archivo ejecutable en una secuencia de archivos alternativa NTFS
rules / windows / sysmon / sysmon_ads_executable.yml
La regla considerada es un ejemplo de la designación correcta de un valor no vacío. Esta regla se activará si el evento cumple la condición:
EventID = 15 Y I
mphash != '00000000000000000000000000000000' Imphash
En la regla, se ve así:
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter Como se mencionó anteriormente, la negación ahora debe colocarse en la condición (el campo de condición) y no en los identificadores de búsqueda.
Modificadores de valor
La interpretación de los valores de campo en una regla se puede cambiar mediante modificadores. Los modificadores se agregan después del nombre del campo, cada modificador está precedido por una barra vertical (tubería) - "|". Se pueden encadenar para construir cadenas (tuberías) de modificadores:

el valor del campo se modifica de acuerdo con el orden de los modificadores en la cadena. Los modificadores pueden ser de dos tipos: transformadores y modificadores de tipo.
Los modificadores de transformación son aquellos que convierten el valor del campo original en algún otro valor, o transforman la lógica para procesar listas de valores en identificadores de búsqueda. Un ejemplo del primer tipo son los modificadores Base64 y el segundo es el modificador all . Todos los modificadores se discutirán con más detalle más adelante.
Echemos un vistazo a cada uno de los modificadores de transformación. Para mayor claridad, mostraremos esquemáticamente cómo exactamente este o aquel modificador cambia el valor inicial.
comienza con
El modificador startswith se utiliza para hacer coincidir el comienzo de una cadena con el valor deseado.

Ejemplos de uso:
- reglas / windows / builtin / win_ad_replication_non_machine_account.yml
- reglas / windows / process_creation / win_apt_winnti_mal_hk_jan20.yml
- reglas / windows / powershell / powershell_downgrade_attack.yml
termina con
El modificador endswith se usa para hacer coincidir el final de la cadena con el valor de búsqueda.

Ejemplos de uso:
- rules / windows / process_creation / win_local_system_owner_account_discovery.yml
- reglas / windows / sysmon / sysmon_minidumwritedump_lsass.yml
- reglas / windows / process_creation / win_susp_odbcconf.yml
contiene
El modificador contiene comprueba la aparición de una subcadena en el valor del campo. De hecho, este modificador convierte el valor del campo de la siguiente manera:

Es decir, si consideramos los resultados de aplicar los modificadores considerados, puede escribir la siguiente fórmula:
startswith + endswith = contiene
Ejemplos:
- reglas / windows / process_creation / win_hack_bloodhound.yml
- reglas / windows / process_creation / win_mimikatz_command_line.yml
- reglas / windows / sysmon / sysmon_webshell_creation_detect.yml
todos
Por lo general, los elementos de la hoja se combinan con un OR lógico. El modificador all cambia el O lógico por el Y lógico, es decir, todos los elementos de la lista deben estar presentes. Veamos cómo cambiarían las condiciones en el esquema general, que estaba al principio de la sección:
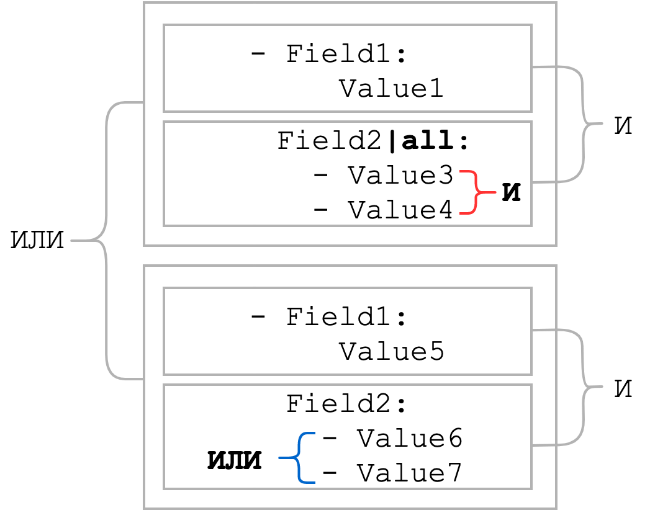
Como puede ver, cuando se aplicó el modificador todo , la conexión lógica entre los elementos de la lista se convirtió en Y. Por lo general, el modificador todo se usa junto con el modificador contiene. Tal grupo puede servir como reemplazo del patrón con metacaracteres comodín si se desconoce el orden de las partes estáticas.
Ejemplos de uso del modificador todo :
- reglas / windows / builtin / win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- reglas / windows / powershell / powershell_suspicious_profile_create.yml
- reglas / windows / powershell / powershell_suspicious_download.yml
base64
Este modificador se aplica cuando el valor del campo está codificado en Base64 y, para mayor claridad, escribimos el texto codificado en la regla y no la cadena de Base64 resultante.

Este modificador asume una coincidencia exacta del campo con la cadena codificada. Por lo general, es más útil identificar signos de actividad sospechosa en los datos originales que buscar una coincidencia exacta con el resultado codificado. Por lo tanto, todavía no hay ejemplos de uso del modificador base64 .
base64offset
Debido a la naturaleza de la codificación Base64, no puede usar una canalización desde base64 y contiene para encontrar una subcadena codificada . El modificador base64offset se crea con este mismo propósito . Se usa cuando una cadena está codificada en Base64 y queremos encontrar una subcadena de la cadena codificada. Además, los caracteres que rodean la subcadena deseada se desconocen de antemano y el desplazamiento de la subcadena con respecto al comienzo de la cadena se desconoce. Puede ver claramente lo que está en juego aquí.
Casi siempre este modificador se usa junto con el modificador contiene :

Ejemplos de uso:
- reglas / windows / process_creation / win_encoded_frombase64string.yml
- reglas / windows / process_creation / win_encoded_iex.yml
¡Importante! Los siguientes tres modificadores de transformación de codificación se utilizan solo junto con los modificadores Base64.
utf16le o ancho
Los modificadores utf16le y wide son sinónimos. Transforman el valor de cadena del campo a codificación UTF-16LE, es decir
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00.

utf16be
El modificador utf16be convierte el valor de cadena del campo a UTF-16BE, es decir
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33.

utf16
El modificador utf16 agrega una marca de orden de bytes (BOM) y codifica una cadena en UTF-16, es decir
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00. Actualmente solo hay un

modificador de tipo : re .
re
Este modificador de tipo interpreta el valor del campo como un patrón de expresión regular. Hasta el momento, solo es compatible con el conversor a una consulta de Elasticsearch, por lo que prácticamente no aparece en las reglas públicas.
Ejemplos de uso:
- reglas / windows / process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- reglas / windows / builtin / win_invoke_obfuscation_obfuscated_iex_services.yml
- reglas / windows / builtin / win_mal_creddumper.yml
Intervalo de tiempo (atributo de marco de tiempo)
Además, la lógica de detección se puede refinar especificando el intervalo de tiempo durante el cual deben aparecer los identificadores de búsqueda. Las abreviaturas estándar se utilizan para denotar unidades de tiempo:
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) Ejemplos de uso:
- reglas / linux / modsecurity / modsec_mulitple_blocks.yml
- rules-unsupported / net_possible_dns_rebinding.yml
- reglas / windows / builtin / win_rare_service_installs.yml
Descripción de las condiciones de activación de la regla (atributo de condición)
Según la documentación oficial de Sigma, la parte de condición de activación de la regla es la más compleja y cambiará con el tiempo. Las siguientes expresiones están disponibles actualmente.
Operaciones lógicas Y, O
Están indicadas por las palabras clave y y o, respectivamente. Estas expresiones son los elementos principales para construir una relación lógica entre identificadores de búsqueda.
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 Ejemplos de uso:
Uno de los valores de ID de búsqueda / todos los valores de ID de búsqueda (1 / todo el identificador de búsqueda)
Lo mismo que para el caso anterior, si el ID de búsqueda
- 1 - OR lógico entre alternativas,
- todo - Y lógico entre alternativas.
Por defecto
condition: keywordssignifica que los valores listados en el identificador de palabras clave son lógicos OR, es decir, esto es lo mismo que escribir condition: 1 of keywords. Si queremos que los valores se combinen con un Y lógico, entonces tenemos que escribir condition: all of keywords.
Ejemplos de uso:
Uno de los ID de búsqueda / todos los ID de búsqueda (1 / todos)
OR lógico (1 de ellos) o AND lógico (todos) entre todos los ID de búsqueda dados. De forma predeterminada, los ID de búsqueda están vinculados mediante un AND lógico si son elementos de un diccionario, o un OR lógico si son elementos de una lista. Para cambiar estas relaciones, se creó esta estructura. Así, la condición, condición: 1 de ellos, significa que al menos uno de los identificadores de búsqueda debe aparecer en el evento.
Ejemplos de uso:
- reglas / windows / process_creation / win_hack_bloodhound.yml
- reglas / windows / powershell / powershell_psattack.yml
- rules / cloud / aws_ec2_download_userdata.yml
Uno de los ID de búsqueda que coinciden con el patrón de nombre / todos los ID de búsqueda que coinciden con el patrón de nombre (1 / todos los patrones de identificación de búsqueda)
Igual que en el párrafo anterior, pero la selección se limita a los identificadores de búsqueda cuyos nombres coincidan con el patrón. Estos patrones se construyen utilizando el comodín * (cualquier número de caracteres) en una posición específica en el patrón de nombre.
La sintaxis es la siguiente:
condition: 1 of selection*
condition: all of selection* Ejemplos de uso:
- reglas / windows / builtin / win_user_added_to_local_administrators.yml
- reglas / windows / process_creation / win_susp_eventlog_clear.yml
- rules / cloud / aws_iam_backdoor_users_keys.yml
Negación lógica
Los negativos lógicos se construyen utilizando la palabra clave not . Como se señaló anteriormente, la expresión "no vacío" debe especificarse en el campo de condición , no en la descripción del identificador de búsqueda. El siguiente ejemplo muestra claramente la versión correcta de la descripción de la expresión "el valor del campo no está vacío".

Ejemplos de uso:
- reglas / windows / sysmon / sysmon_malware_backconnect_ports.yml
- reglas / windows / process_creation / win_apt_gallium.yml
Tubo
La barra vertical (o barra vertical) indica que el resultado de la expresión se pasará a una función agregada, cuyo resultado es probable que se compare con algún valor.
Esquema general:
_ | _
condition: selection | count(category) by dst_ip > 30 Ejemplos de uso:
- reglas / windows / builtin / win_susp_failed_logons_single_source.yml
- reglas / windows / other / win_rare_schtask_creation.yml
- rules / network / net_high_dns_requests_rate.yml
Paréntesis
Los paréntesis se utilizan para especificar una subexpresión. Esto puede resultar útil para especificar el orden en el que se evalúa una expresión lógica o para negar un predicado que contiene varias expresiones. Tienen la máxima prioridad para la operación.
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) Ejemplo de uso:
Expresiones de funciones agregadas
Las expresiones agregadas (o expresiones de función agregada) se utilizan para cuantificar los eventos que han ocurrido.
Esquema de expresión agregada:

todas las funciones agregadas, excepto el recuento, requieren un nombre de campo como parámetro. La función de recuento cuenta todos los eventos coincidentes si no se especifica ningún nombre de campo. Si se especifica un nombre de campo, la función cuenta diferentes valores en este campo. Por ejemplo, la siguiente expresión cuenta la cantidad de puertos diferentes a los que se hicieron conexiones desde una dirección IP, y si este número excede 10, entonces se activa la regla:
condition: selection | count(dst_port) by src_ip > 10 Ejemplos de uso:
- reglas / linux / lnx_susp_failed_logons_single_source.yml
- reglas / windows / other / win_rare_schtask_creation.yml
- rules / network / net_susp_network_scan.yml
Expresión agregada cerca
La palabra clave near se utiliza para generar una solicitud (si esta funcionalidad es compatible con el sistema de destino y el backend) que reconoce la aparición de todos los ID de búsqueda especificados dentro de un intervalo de tiempo especificado después de encontrar el primer ID.
Esquema general:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
ejemplo de sintaxis:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion Las mismas reglas se aplican a la expresión de búsqueda después de la palabra cerca que a la expresión de búsqueda antes de la barra vertical, que hemos detallado anteriormente.
Ejemplos de uso:
- reglas / windows / sysmon / sysmon_mimikatz_inmemory_detection.yml
- reglas / windows / builtin / win_susp_samr_pwset.yml
La prioridad predeterminada de las operaciones es:
- (expresión)
- X del patrón de búsqueda
- No
- Y
- O
- |
Por lo tanto, los paréntesis tienen la prioridad más alta y la tubería tiene la más baja.
Nota: si se especifican varios campos de condición, el valor final se obtiene aplicando OR lógico a todos los valores de expresión.
En este artículo, hemos descrito la lógica de detección. Siga nuestras publicaciones, en el próximo artículo veremos los campos restantes de la regla. La mayoría de ellos son de naturaleza informativa o de infraestructura. Además de los campos con metainformación, detengámonos en esta característica de la composición de reglas, que se llama colecciones de reglas. Para las personas que no están familiarizadas con las complejidades del lenguaje YAML, la consideración de este aspecto de la sintaxis será útil al leer extraños y escribir sus propias reglas.
Autor : Anton Kutepov, especialista del departamento de servicios expertos y desarrollo de Tecnologías Positivas (PT Expert Security Center)