
¡Hola! Nuestra empresa ha estado lidiando con el problema de la protección contra ataques DDoS durante mucho tiempo, y en el proceso de este trabajo pude familiarizarme con áreas relacionadas con suficiente detalle, para estudiar los principios de creación de bots y cómo usarlos. En particular, web scraping, es decir, recopilación masiva de datos públicos de recursos web utilizando bots.
En algún momento, este tema me fascinó con la variedad de problemas aplicados en los que se usa con éxito el raspado. Cabe destacar aquí que me interesa mucho el “lado oscuro” del web scraping, es decir, los escenarios dañinos y malos para su uso y los efectos negativos que puede tener sobre los recursos web y el negocio asociado a ellos.
Al mismo tiempo, debido a los detalles de nuestro trabajo, la mayoría de las veces fue en casos tan (malos) que tuvimos que sumergirnos en los detalles, estudiando detalles interesantes. Y el resultado de estas inmersiones fue que mi entusiasmo se transmitió a mis colegas: implementamos nuestra solución para detectar bots no deseados, pero he acumulado suficientes historias y observaciones que, espero, serán material interesante para ustedes.

Hablaré de lo siguiente:
- ¿Por qué la gente se rasca entre sí?
- ¿Cuáles son los tipos y signos de tal raspado?
- ¿Qué impacto tiene en los sitios web específicos?
- ¿Qué herramientas y capacidades técnicas utilizan los creadores de bots para hacer scraping?
- Cómo se pueden detectar y reconocer diferentes categorías de bots;
- Qué hacer y qué hacer si el raspador llega a visitar su sitio (y si necesita hacer algo).
Comencemos con un escenario hipotético inofensivo: imaginemos que eres un estudiante, mañana por la mañana tienes una defensa de tu trabajo final, no tienes un caballo por ahí basado en materiales, no hay números, extractos ni comillas, y lo entiendes por el resto de la noche. No tiene el tiempo, ni la energía, ni el deseo de empujar a través de toda esta base de conocimientos manualmente.
Por lo tanto, siguiendo el consejo de compañeros mayores, descubres la línea de comandos de Python y escribes un script simple que acepta URL como entrada, va allí, carga la página, analiza el contenido, encuentra palabras clave, bloques o números de interés en él, los agrega a un archivo o en el plato y continúa.
Cargue en este script la cantidad requerida de direcciones de publicaciones científicas, publicaciones en línea, recursos de noticias; repasa rápidamente todo y suma los resultados. Solo tiene que dibujar gráficos y diagramas, tablas sobre ellos, y a la mañana siguiente, con la apariencia de un ganador, obtiene su punto bien merecido.
Pensemos en ello: ¿le hiciste mal a alguien en el proceso? Bueno, a menos que haya analizado HTML con una expresión regular, lo más probable es que no haya dañado a nadie, y más aún a los sitios que visitó de esta manera. Esta es una actividad que se realiza una sola vez, se puede llamar modesta y poco llamativa, y casi nadie sufrió por el hecho de que usted vino, rápidamente y en silencio, tomó la información que necesitaba.
Por otro lado, ¿lo volverás a hacer si todo salió bien la primera vez? Seamos realistas, lo más probable es que lo haga, porque acaba de ahorrar mucho tiempo y recursos, habiendo recibido, muy probablemente, incluso más datos de los que pensaba originalmente. Y esto no se limita a la investigación científica, académica o de educación general.

Porque la información cuesta dinero y la información recopilada a tiempo cuesta incluso más dinero. Por eso, el scraping es una importante fuente de ingresos para un gran número de personas. Este es un tema independiente popular: ingrese y vea un montón de pedidos que le piden que recopile algunos datos o escriba un software de scraping. También existen organizaciones comerciales que hacen scraping por encargo o proporcionan plataformas para esta actividad, el llamado scraping as a service. Tal variedad y propagación es posible, también porque el raspado en sí mismo es algo ilegal, reprobable y no lo es. Desde un punto de vista legal, es muy difícil encontrarle fallas, especialmente en este momento, pronto descubriremos por qué.

Para mí, también es de particular interés el hecho de que, en términos técnicos, nadie puede prohibirle que luche contra el raspado; esto crea una situación interesante en la que los participantes en el proceso a ambos lados de las barricadas tienen la oportunidad en un espacio público para discutir los aspectos técnicos y organizativos de este asunto. Para avanzar, en cierta medida, la ingeniería pensó e involucrar a cada vez más personas en este proceso.

Desde el punto de vista de los aspectos legales, la situación que estamos considerando ahora, con la permisibilidad de raspar, no siempre fue la misma antes. Si miramos un poco la cronología de juicios bastante conocidos relacionados con el scraping, veremos que incluso en los albores de sus albores, el primer reclamo de eBay fue contra un scraper que recopilaba datos de subastas, y el tribunal le prohibió participar en esta actividad. Durante los siguientes 15 años, el statu quo se mantuvo más o menos: las grandes empresas ganaron demandas contra los raspadores cuando descubrieron su impacto. Facebook y Craigslist, así como algunas otras empresas, han informado afirmaciones que terminaron a su favor.
Sin embargo, hace un año, todo cambió de repente. El tribunal determinó que el reclamo de LinkedIn contra la empresa que recopiló perfiles públicos de usuarios y currículums era infundado e ignoró las cartas y amenazas que exigían detener la actividad. El tribunal dictaminó que la recopilación de datos públicos, independientemente de si es un bot o un humano, no puede ser la base para un reclamo de la empresa que muestra estos datos públicos. Este poderoso precedente legal ha cambiado la balanza a favor de los raspadores y ha permitido que más personas muestren, demuestren y prueben su propio interés en el campo.
Sin embargo, al observar todas estas cosas generalmente inofensivas, no se debe olvidar que el raspado tiene muchos usos negativos: cuando los datos se recopilan no solo para su uso posterior, sino que en el proceso se realiza la idea de causar algún daño al sitio o al negocio detrás de él. o intenta enriquecerse de alguna manera a expensas de los usuarios del recurso objetivo.
Veamos algunos ejemplos icónicos.

El primero de los cuales es raspar y copiar anuncios de otras personas de sitios que brindan acceso a dichos anuncios: automóviles, bienes raíces, artículos personales. Elegí un magnífico garaje en California como ejemplo. Imagine que colocamos un bot allí, recopilamos una imagen, recopilamos una descripción, tomamos toda la información de contacto y, después de 5 minutos, el mismo anuncio está colgado en otro sitio con un enfoque similar, y es muy posible que se obtenga un trato rentable a través de él.
Si activamos un poco nuestra imaginación aquí y pensamos en el siguiente lado, ¿qué pasa si no es nuestro competidor quien está involucrado en esto, sino un atacante? Dicha copia del sitio puede ser muy útil para, por ejemplo, solicitar un pago por adelantado al visitante, o simplemente ofrecer ingresar los datos de la tarjeta de pago. Puede imaginarse el desarrollo posterior de los eventos usted mismo.
Otro caso interesante de scraping es la compra de artículos de disponibilidad limitada. Los fabricantes de calzado deportivo como Nike, Puma y Reebok lanzan periódicamente zapatillas de edición limitada, etc. Serie de firmas: son cazados por coleccionistas, están a la venta por tiempo limitado. Antes de los compradores, los bots llegan corriendo a los sitios web de las zapaterías y acumulan toda la circulación, después de lo cual estas zapatillas aparecen en el mercado gris con un precio completamente diferente. En un momento, esto enfureció a los vendedores y minoristas que los distribuían. Desde hace 7 años luchan contra raspadores, etc. bots de zapatillas con éxito variable, tanto técnicos como administrativos.

Probablemente hayas escuchado historias sobre compras en línea para ir personalmente a una tienda de zapatillas, o sobre honeypots con zapatillas por $ 100k, que el bot compró sin mirar, después de lo cual su dueño le agarró la cabeza; todas estas historias están en esta tendencia.
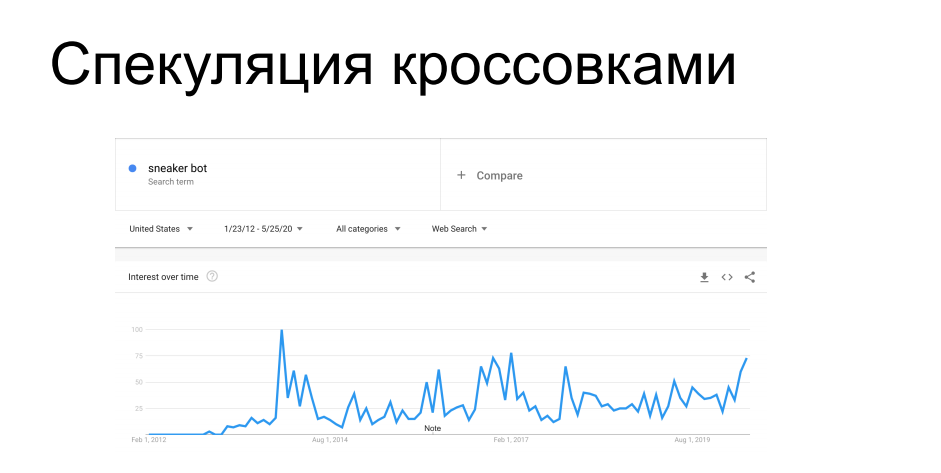
Y otro caso similar es el agotamiento del inventario en las tiendas online. Es similar al anterior, pero en realidad no se realizan compras en él. Hay una tienda en línea y ciertos artículos que los bots entrantes acumulan en la canasta en la cantidad que se muestra como disponible en el almacén. Como resultado, un usuario legítimo que intenta comprar un producto recibe un mensaje de que este artículo está agotado, se rasca la parte posterior de la cabeza con frustración y se va a otra tienda. Luego, los propios robots dejan caer las canastas recolectadas, los productos se devuelven a la piscina, y el que los necesitaba viene y los ordena. O no viene y no ordena, si este es un escenario de picardía y vandalismo. A partir de esto, queda claro que incluso si tales actividades no causan un daño financiero directo a un negocio en línea, al menos pueden alterar seriamente las métricas comerciales.en qué se centrarán los analistas. Parámetros como conversión, asistencia, demanda de productos, verificación promedio del carrito, todos ellos estarán fuertemente manchados por las acciones de los bots en relación con estos elementos. Y antes de poner en funcionamiento estas métricas, deberán limpiarse cuidadosa y minuciosamente de los efectos de los raspadores.
Además de este enfoque empresarial, existen efectos técnicos bastante notables que surgen del trabajo de los raspadores, con mayor frecuencia cuando el raspado se realiza de forma activa e intensiva.
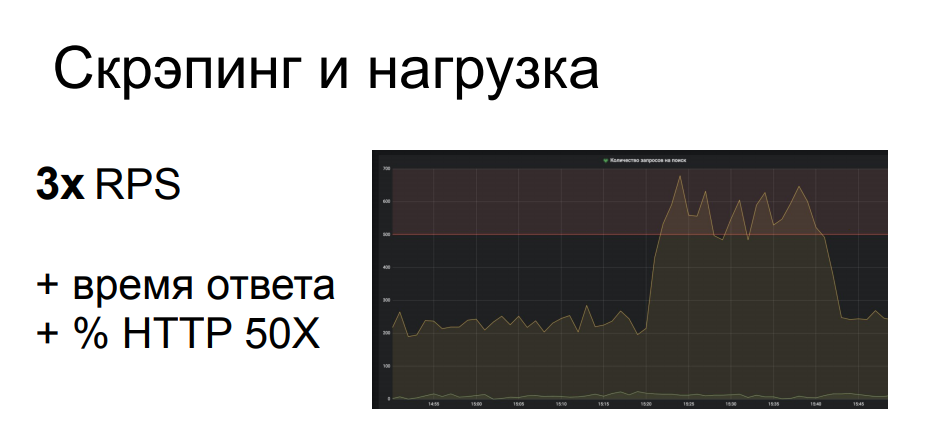
Uno de nuestros ejemplos de uno de nuestros clientes. El raspador llegó a una ubicación con una búsqueda parametrizada, que es una de las operaciones más difíciles en el backend de la estructura en cuestión. El scraper tuvo que pasar por muchas consultas de búsqueda, y de 200 RPS a esta ubicación hizo casi 700. Esto cargó gravemente parte de la infraestructura, lo que provocó una degradación de la calidad del servicio para el resto de usuarios legítimos, el tiempo de respuesta despegó, los 502 y 503 cayeron. y errores. En general, al raspador no le importaba en absoluto y se sentó e hizo su trabajo mientras todos los demás actualizaban frenéticamente la página del navegador.
A partir de esto, queda claro que dicha actividad bien puede clasificarse como un ataque DDoS aplicado, y a menudo lo hace. Especialmente si la tienda en línea no es tan grande, no tiene una infraestructura que se reserve repetidamente en términos de rendimiento y ubicación. Tal actividad bien puede, si no coloca completamente el recurso, no es muy rentable para el raspador, ya que en este caso no recibirá sus datos, entonces todos los demás usuarios se molestan seriamente.
Pero además de DDoS, el scraping también tiene vecinos interesantes del ámbito del ciberdelito. Por ejemplo, los inicios de sesión y contraseñas de fuerza bruta utilizan una base técnica similar, es decir, utilizando los mismos scripts, se puede hacer con énfasis en la velocidad y el rendimiento. Para el relleno de credenciales, se utilizan los datos de usuario eliminados de algún lugar, que se insertan en campos de formulario. Bueno, ese ejemplo de copiar contenido y publicarlo en sitios similares es un trabajo preparatorio serio para deslizar enlaces de phishing y atraer a compradores desprevenidos.

Para comprender cómo las diferentes variantes de raspado pueden, desde un punto de vista técnico, afectar el recurso, intentemos calcular la contribución de los factores individuales a esta tarea. Hagamos algo de aritmética.

Digamos que tenemos un montón de datos a la derecha que necesitamos recopilar. Tenemos una tarea u orden para recuperar 10,000,000 líneas de artículos básicos, por ejemplo, etiquetas de precios o cotizaciones. Y en el lado izquierdo tenemos un presupuesto de tiempo, porque mañana o en una semana el cliente ya no necesitará estos datos, quedarán desactualizados y tendremos que recopilarlos nuevamente. Por lo tanto, debe mantenerse dentro de un cierto período de tiempo y, utilizando sus propios recursos, hacerlo de manera óptima. Disponemos de una serie de servidores - máquinas y direcciones IP detrás de las cuales se ubican, desde los cuales iremos al recurso que nos interese. Tenemos una serie de instancias de usuarios que pretendemos ser: hay una tarea para convencer a una tienda en línea o alguna base pública de que se trata de personas diferentes o computadoras diferentes buscan algunos datos, de modo que esosquien analizará los registros, no había sospechas. Y tenemos algo de rendimiento, tasa de solicitudes, de una de esas instancias.
Está claro que en un caso simple: una máquina host, un estudiante con una computadora portátil, pasando por el Washington Post, se realizarán una gran cantidad de solicitudes con los mismos signos y parámetros. Se notará mucho en los registros si hay muchas de estas solicitudes, lo que significa que es fácil de encontrar y prohibir, en este caso, por la dirección IP.
A medida que la infraestructura de raspado se vuelve más compleja, aparece una mayor cantidad de direcciones IP, se comienzan a utilizar proxies, incluidos los proxies domésticos, más sobre ellos más adelante. Y comenzamos a crear múltiples instancias en cada máquina, para reemplazar los parámetros de consulta, los signos que nos caracterizan, con el fin de hacer que todo se borre en los registros y no sea tan conspicuo.
Si continuamos en la misma dirección, entonces tenemos la oportunidad, dentro del marco de la misma ecuación, de reducir la intensidad de las solicitudes de cada una de esas instancias, haciéndolas más raras, rotándolas de manera más eficiente para que las solicitudes de los mismos usuarios no terminen en los registros cercanos. sin despertar sospechas y siendo similar a los usuarios finales (legítimos).
Bueno, hay un caso límite: una vez tuvimos un caso así en la práctica, cuando un raspador llegó a un cliente desde una gran cantidad de direcciones IP con atributos de usuario completamente diferentes detrás de estas direcciones, y cada instancia hizo exactamente una solicitud de contenido. Hice un GET a la página del producto deseado, lo analicé y me fui, y nunca volví a aparecer. Estos casos son bastante raros, ya que requieren más recursos (que cuestan dinero) para usarse en la misma cantidad de tiempo. Pero al mismo tiempo, se vuelve mucho más difícil rastrearlos y comprender que alguien incluso vino aquí y los raspó. Las herramientas de investigación del tráfico, como el análisis del comportamiento, que construye un patrón de comportamiento de un usuario en particular, se vuelven muy complicadas. Después de todo, ¿cómo se puede hacer un análisis del comportamiento si no hay comportamiento? No hay historial de acciones del usuario,nunca había aparecido antes y, curiosamente, nunca ha vuelto desde entonces. En tales condiciones, si no intentamos hacer algo en la primera solicitud, recibirá sus datos y se irá, y nos quedaremos sin nada; no hemos resuelto el problema de contrarrestar el raspado aquí. Por lo tanto, la única oportunidad es adivinar en la primera solicitud que ha llegado la persona equivocada, a quien queremos ver en el sitio, y darle un error o asegurarnos de que no reciba sus datos.a quién queremos ver en el sitio, y darle un error o asegurarnos de que no reciba sus datos.a quién queremos ver en el sitio, y darle un error o asegurarnos de que no reciba sus datos.
Para comprender cómo puede moverse a lo largo de esta escala de complejidad en la construcción de un raspador, echemos un vistazo al arsenal que tienen los creadores de bots que se utilizan con más frecuencia, y en qué categorías se pueden dividir.

La categoría principal y más simple con la que la mayoría de los lectores están familiarizados es el raspado de guiones, el uso de guiones lo suficientemente simples como para resolver problemas relativamente complejos.

Y esta categoría es quizás la más popular y mejor documentada. Incluso es difícil recomendar qué leer exactamente, porque, en realidad, hay mucho material. Se escribieron muchos libros con este método, hay muchos artículos y publicaciones; en principio, es suficiente dedicar 5/4/3/2 minutos (dependiendo de la insolencia del autor del material) para analizar su primer sitio. Este es un primer paso lógico para muchos que se inician en el web scraping. El "paquete de inicio" de una actividad de este tipo suele ser Python, más una biblioteca que puede realizar solicitudes de manera flexible y cambiar sus parámetros, como solicitudes o urllib2. Y algún tipo de analizador HTML, generalmente Beautiful Soup. También hay una opción para usar bibliotecas que están diseñadas específicamente para raspar, como scrapy, que incluye todas estas funciones con una interfaz fácil de usar.
Con la ayuda de simples trucos, puede pretender ser diferentes dispositivos, diferentes usuarios, incluso sin poder escalar de alguna manera sus actividades por máquinas, por direcciones IP y por diferentes plataformas de hardware.

Para eliminar el olor de quien inspecciona los registros en el lado del servidor del que se recopilan los datos, es suficiente reemplazar los parámetros de interés, y esto no es difícil ni por mucho tiempo. Veamos un ejemplo de un formato de registro personalizado para nginx: registramos una dirección IP, información TLS, encabezados que nos interesan. Aquí, por supuesto, no todo lo que normalmente se recopila, pero necesitamos esta restricción como ejemplo: para ver un subconjunto, simplemente porque todo lo demás es aún más fácil de "lanzar".
Para no ser prohibidos por direcciones, usaremos proxies residenciales, como se les llama en el extranjero, es decir, proxies de máquinas alquiladas (o pirateadas) en las redes domésticas de los proveedores. Está claro que al prohibir una dirección IP de este tipo, existe la posibilidad de prohibir una cierta cantidad de usuarios que viven en estas casas, y es posible que haya visitantes en su sitio, por lo que a veces es más costoso para usted hacerlo.
La información de TLS tampoco es difícil de reemplazar: tome los conjuntos de cifrado de los navegadores populares y elija el que le guste, el más común, o rótelos periódicamente para presentarse como dispositivos diferentes.
En cuanto a los encabezados, con la ayuda de un pequeño estudio, puede configurar el referente a lo que le guste al sitio raspado, y tomamos el agente de usuario de Chrome o Firefox, para que no difiera de ninguna manera de decenas de miles de otros usuarios.
Luego, haciendo malabarismos con estos parámetros, puede fingir ser dispositivos diferentes y seguir raspando sin tener miedo de ser notado de alguna manera por el simple hecho de caminar por los registros. Para el ojo armado, esto es todavía algo más difícil, porque trucos tan simples son neutralizados por las mismas, bastante simples, contramedidas.

Comparar parámetros de solicitud, encabezados, direcciones IP entre sí y con los conocidos públicamente le permite atrapar a los raspadores más arrogantes. Un ejemplo simple: nos llegó un robot de búsqueda, pero por alguna razón su IP no es de la red del motor de búsqueda, sino de algún proveedor de la nube. Incluso el propio Google en la página que describe el robot de Google recomienda realizar una búsqueda inversa de los registros DNS para asegurarse de que este bot realmente provenga de google.com u otros recursos válidos de Google.
Hay muchos controles de este tipo, la mayoría de las veces están diseñados para aquellos raspadores que no se molestan con el borrado, algún tipo de sustitución. Para casos más complejos, existen métodos más confiables y engorrosos, por ejemplo, insertar Javascript en este bot. Está claro que en tales condiciones la lucha ya es desigual: su script Python no podrá ejecutar e interpretar el código JS. Pero puede hacerlo el autor del script, si el autor del bot tiene suficiente tiempo, deseo, recursos y habilidad para ir y ver qué está haciendo su Javascript en el navegador.
La esencia de las comprobaciones es que integre el script en su página, y es importante para usted no solo que se ejecute, sino que también demuestre algún tipo de resultado, que generalmente se envía POST al servidor antes de que el cliente duerma lo suficiente. contenido y se cargará la página. Por lo tanto, si el autor del bot resolvió su acertijo y codifica las respuestas correctas en su secuencia de comandos de Python, o, por ejemplo, entiende dónde necesita analizar las líneas de secuencia de comandos en sí mismas en busca de los parámetros necesarios y los métodos llamados, y calculará la respuesta por su cuenta, podrá rodearlo con un círculo. alrededor de tu dedo. He aquí un ejemplo.

Creo que algunos oyentes reconocerán este fragmento de javascript: este es un cheque que solía tener uno de los proveedores de nube más grandes del mundo antes de acceder a la página solicitada, compacto y muy simple, y al mismo tiempo, sin aprenderlo, es tan fácil el sitio no se abre paso. Al mismo tiempo, habiendo aplicado un poco de esfuerzo, podemos preguntar a la página en busca de los métodos JS que nos interesan que serán llamados, a partir de ellos, contando, encontrar los valores que nos interesan que deban calcularse, y pegar los cálculos en el código. Después de eso, no te olvides de dormir unos segundos debido al retraso, y listo.

Llegamos a la página y luego podemos analizar lo que necesitamos, sin gastar más recursos que crear nuestro propio raspador. Es decir, desde el punto de vista del uso de recursos, no necesitamos nada adicional para solucionar este tipo de problemas. Está claro que la carrera armamentista en este sentido (escribir desafíos JS y analizarlos y eludirlos con herramientas de terceros) está limitada solo por el tiempo, el deseo y las habilidades del autor de los bots y el autor de los controles. Esta carrera puede durar bastante tiempo, pero en algún momento la mayoría de los raspadores dejan de ser interesantes, porque hay opciones más interesantes para afrontarla. ¿Por qué sentarse y analizar el código JS en Python cuando puede simplemente tomar y ejecutar un navegador?

Sí, estoy hablando principalmente de navegadores sin cabeza, porque esta herramienta, creada originalmente para pruebas y preguntas y respuestas, ha resultado ser ideal para tareas de raspado web en este momento.
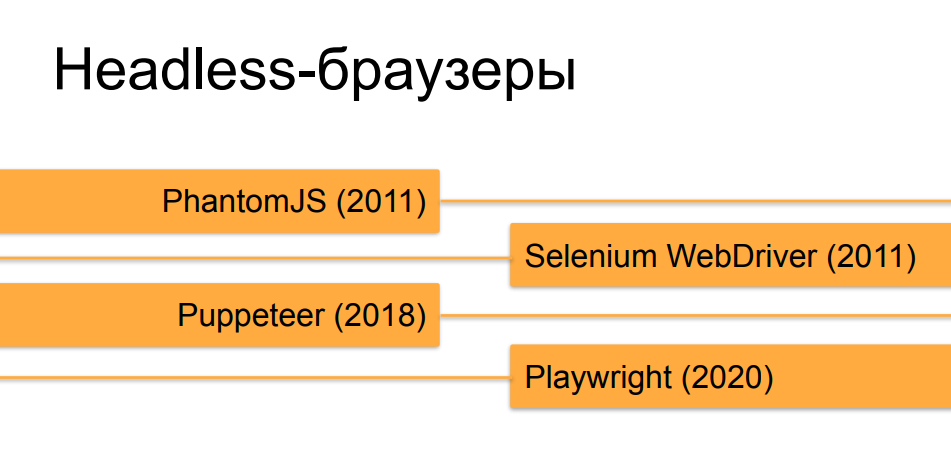
No entraremos en detalles sobre los navegadores sin cabeza, creo que la mayoría de los oyentes ya los conocen. Los orquestadores, que automatizan los navegadores sin cabeza, han experimentado una evolución bastante rápida en los últimos 10 años. Al principio, en el momento de PhantomJS y las primeras versiones de Selenium 2.0 y Selenium WebDriver, un navegador sin cabeza que se ejecutaba bajo un autómata no era en absoluto difícil de distinguir de un usuario en vivo. Pero, con el tiempo y la aparición de herramientas como Puppeteer para Chrome sin cabeza y, ahora, la creación de caballeros de Microsoft - Playwright, que hace lo mismo que Puppeteer, pero no solo para Chrome, sino para todas las versiones de navegadores populares, son cada vez más y acercar los navegadores sin cabeza a los reales en términos decómo se pueden hacer con la ayuda de una orquestación similar en comportamiento y en diferentes signos y propiedades al navegador de una persona sana.

Para lidiar con el reconocimiento sin cabeza en el contexto de los navegadores comunes en los que la gente se sienta, por regla general, se utilizan las mismas comprobaciones de JavaScript, pero más profundas, detalladas, recopilando una nube de parámetros. El resultado de esta recopilación se envía de vuelta a la herramienta de protección o al sitio desde el que el raspador quería recopilar los datos. Esta tecnología se llama huella digital, porque recopila una huella digital real del navegador y del dispositivo en el que se ejecuta.
Hay bastantes cosas que JS comprueba cuando se toman las huellas dactilares: se pueden dividir en algunos bloques condicionales, en cada uno de los cuales la excavación puede seguir y seguir. Realmente hay muchas propiedades, algunas son fáciles de ocultar, otras son menos fáciles. Y aquí, como en el ejemplo anterior, mucho depende de cuán meticulosamente el raspador se acercó a la tarea de ocultar las "colas" que sobresalen de la decapitación. Hay propiedades de los objetos en el navegador, que el orquestador reemplaza de forma predeterminada, existe la propiedad misma (navigator.webdriver), que está configurada en headless, pero al mismo tiempo no está presente en los navegadores normales. Se puede ocultar, se puede detectar un intento de ocultar mediante la verificación de ciertos métodos; qué verificaciones estas verificaciones también se pueden ocultar y la salida falsa se puede deslizar a funciones que imprimen métodos, por ejemplo,y puede durar indefinidamente.
Otro bloque de comprobaciones, por regla general, se encarga de estudiar los parámetros de ventana y pantalla, que por definición no tienen en los navegadores sin cabeza: comprobación de coordenadas, comprobación de tamaños, cuál es el tamaño de una imagen rota que no se ha dibujado. Hay muchos matices que una persona que conoce bien el dispositivo de los navegadores puede prever y sacar una conclusión plausible (pero no real) sobre cada uno de ellos, que volará en verificaciones de huellas dactilares al servidor que lo analizará. Por ejemplo, en el caso de renderizar algunas imágenes, 2D y 3D, por medio de WebGL y Canvas, puede tener listo todo el resultado, falsificarlo, emitirlo en un método y hacer creer a alguien que algo está realmente dibujado.
Hay comprobaciones más complicadas que no ocurren simultáneamente, pero digamos que el código JS girará durante un cierto número de segundos en la página, o se colgará constantemente y transferirá cierta información al servidor desde el navegador. Por ejemplo, rastreando la posición y la velocidad del movimiento del cursor: si el bot hace clic solo en los lugares que necesita y sigue los enlaces a la velocidad de la luz, entonces esto se puede rastrear por el movimiento del cursor, si el autor del bot no piensa en escribir algún tipo de lenguaje suave, similar , compensar.
Y hay una gran jungla: estos son parámetros y propiedades específicos de la versión del modelo de objetos, que son específicos de un navegador a otro, de una versión a otra. Y para que estas comprobaciones funcionen correctamente y no se falsifiquen, por ejemplo, en usuarios en vivo con algunos navegadores antiguos, debe tener en cuenta un montón de cosas. Primero, debe mantenerse al día con el lanzamiento de nuevas versiones, modificar sus controles para que tengan en cuenta el estado de las cosas en los frentes. Es necesario mantener la compatibilidad con versiones anteriores para que alguien pueda ingresar a un sitio protegido por tales controles en un navegador atípico y al mismo tiempo no ser atrapado como un bot, y muchos otros.
Este es un trabajo laborioso y bastante complicado; estas cosas generalmente las realizan empresas que brindan detección de bots como un servicio, y hacerlo por su cuenta con sus propios recursos no es una inversión muy rentable de tiempo y dinero.
Pero qué hacer: realmente necesitamos raspar el sitio, colgarnos con una nube de tales controles sin cabeza y calcular nuestro cromo sin cabeza con titiritero, a pesar de todo, sin importar cuánto lo intentemos.
Una pequeña digresión lírica: para aquellos que estén interesados en leer con más detalle sobre la historia y la evolución de los controles, por ejemplo, para la decapitación de Chrome, hay un divertido duelo epistolar entre dos autores. No sé mucho sobre un autor, y el otro se llama Antoine Vastel, un joven de Francia que mantiene un blog sobre bots y su detección, ofuscación de cheques y muchas otras cosas interesantes. Y así, ellos y su contraparte han estado discutiendo durante dos años sobre si es posible detectar Chrome sin cabeza.
Y seguiremos adelante y entenderemos qué hacer si no podemos pasar los controles con un decapitado.

Esto significa que no usaremos headless, sino que usaremos grandes navegadores reales que nos dibujen ventanas y todo tipo de elementos visuales. Herramientas como Puppeteer y Playwright permiten, en lugar de sin cabeza, iniciar navegadores con una pantalla renderizada, leer la entrada del usuario desde allí, tomar capturas de pantalla y mucho más que no está disponible para navegadores sin un componente visual.

Además de pasar por alto las comprobaciones de decapitación, en este caso, también puede hacer frente al siguiente problema: cuando tenemos algunos creadores de sitios astutos, esconderse del texto en las imágenes, hacerlos invisibles sin hacer clics adicionales o algunas otras acciones y movimientos. Ocultan algunos elementos que deberían estar ocultos, y con los que se encuentran los decapitados: no saben que este elemento no debería mostrarse ahora en la pantalla, y lo encuentran. Simplemente podemos dibujar esta imagen en el navegador, enviar la captura de pantalla al OCR, obtener el texto en la salida y usarlo. Sí, es más difícil, más caro en términos de desarrollo, lleva más tiempo y consume más recursos. Pero hay raspadores que funcionan de esta manera y, a expensas de la velocidad y el rendimiento, recopilan datos de esta manera.

"¿Qué pasa con el CAPTCHA?" - usted pregunta. Después de todo, el captcha OCR (avanzado) no se puede resolver sin algunas cosas más complejas. Hay una respuesta simple a esto: si no podemos resolver el captcha automáticamente, ¿por qué no utilizar mano de obra humana? ¿Por qué separar un bot y un humano cuando puedes combinar su trabajo para lograr un objetivo?
Existen servicios que te permiten enviarles un captcha, donde se resuelve de la mano de personas sentadas frente a las pantallas, y a través de la API puedes obtener una respuesta a tu captcha, insertar una cookie en la solicitud, por ejemplo, la cual se emitirá, y luego procesar automáticamente la información de este sitio. ... Cada vez que aparece un captcha, sacamos el apishka, obtenemos una respuesta al captcha, lo deslizamos en la siguiente pregunta y seguimos adelante.
Está claro que esto también cuesta un centavo: la solución CAPTCHA se compra al por mayor. Pero si nuestros datos son más caros que el costo de todos estos trucos, entonces, después de todo, ¿por qué no?
Ahora que hemos visto la evolución hacia la complejidad de todas estas herramientas, pensemos en qué hacer si se produce un scraping en nuestro recurso en línea: una tienda en línea, una base de conocimiento público o lo que sea.

Lo primero que debe hacer es encontrar el raspador. Les diré esto: no todos los casos de reuniones públicas generalmente tienen efectos negativos, como ya lo hemos considerado al comienzo del informe. Como regla general, los métodos más primitivos, los mismos scripts sin limitación de velocidad, sin limitar la velocidad de la solicitud, pueden hacer mucho más daño (si no se previenen mediante protección) que cualquier raspado de navegador complejo, sofisticado y con una sola solicitud. en la hora, que al principio todavía debe encontrarse de alguna manera en los registros.

Por lo tanto, primero debe comprender que estamos siendo raspados, para ver los significados que generalmente se ven afectados por esta actividad. Ahora estamos hablando de parámetros técnicos y métricas comerciales. Esas cosas que puedes ver en tu Grafana, con el tiempo mirando la carga y el tráfico, todo tipo de ráfagas y anomalías. Esto se puede hacer manualmente si no se usa una herramienta de seguridad, pero lo hacen de manera más confiable quienes saben cómo filtrar el tráfico, detectar todo tipo de incidentes y relacionarlos con algunos eventos. Porque además de analizar logs a posteriori y además de analizar cada solicitud individual, aquí puede funcionar el uso de algunos medios acumulados de protección de la base de conocimiento, que ya ha visto las acciones de scrapers sobre este recurso o sobre recursos similares, y de alguna manera se puede comparar uno con el otro - discurso sobre el análisis de correlación.
En cuanto a las métricas comerciales, ya hemos recordado el uso del ejemplo de scripts que causan daños económicos directos o indirectos. Si es posible rastrear rápidamente la dinámica de estos parámetros, entonces nuevamente se puede notar el raspado, y luego, si resuelve este problema usted mismo, bienvenido a los registros de su backend.
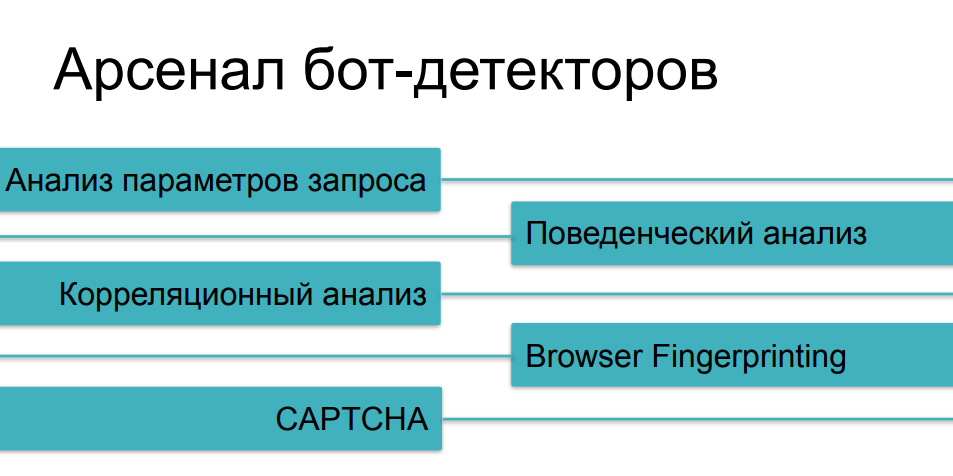
En cuanto a los medios de protección que se utilizan contra el raspado agresivo, ya hemos considerado la mayoría de los métodos, hablando de diferentes categorías de bots. El análisis de tráfico nos ayudará desde los casos más simples, el análisis de comportamiento nos ayudará a rastrear cosas como fuzzing (sustitución de identidad) y scripts de instancias múltiples. Frente a cosas más complejas, recopilaremos impresiones digitales. Y, por supuesto, tenemos un CAPTCHA como último argumento de los reyes: si de alguna manera no pudiéramos atrapar a un robot astuto en las preguntas anteriores, entonces, probablemente, tropezará con un CAPTCHA, ¿verdad?
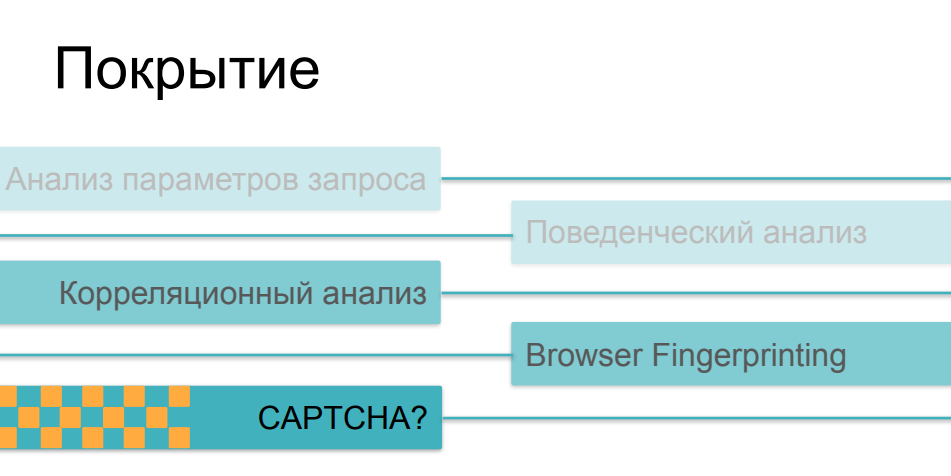
Bueno, aquí es un poco más complicado. El hecho es que a medida que aumenta la complejidad y la astucia de los cheques, se vuelven cada vez más caros, principalmente para el cliente. Si el análisis de tráfico y la comparación posterior de parámetros con algunos valores históricos se pueden realizar de forma absolutamente no invasiva, sin afectar el tiempo de carga de la página y la velocidad del recurso en línea en principio, entonces la toma de huellas digitales, si es lo suficientemente masiva y hace cientos de verificaciones diferentes en el lado del navegador, puede afectar seriamente la velocidad de descarga. Y a pocas personas les gusta ver páginas con cheques en el proceso de seguir enlaces.
Cuando se trata de CAPTCHA, este es el método más crudo e invasivo. Esto es algo que realmente puede asustar a los usuarios o compradores del recurso. A nadie le gusta el captcha y no lo utiliza por una buena vida; lo utiliza cuando todas las demás opciones no han funcionado. Aquí hay una paradoja más divertida, algún problema con la aplicación de estos métodos. El hecho es que la mayoría de los medios de protección en una u otra superposición utilizan todas estas posibilidades, dependiendo de cuán complejo sea el escenario de actividad del bot que encontraron. Si nuestro usuario logró pasar analizadores de tráfico, si su comportamiento no difiere del comportamiento de los usuarios, si su huella dactilar parece un navegador válido, superó todas estas comprobaciones, y luego al final le mostramos el captcha - y resulta ser una persona ... puede ser muy triste ...Como resultado, el captcha comienza a mostrarse no a los bots malvados que queremos cortar, sino a una parte bastante seria de usuarios: personas que pueden enojarse con esto y pueden no venir la próxima vez, no comprar algo en el recurso, no participar en su desarrollo posterior.

Teniendo en cuenta todos estos factores, ¿qué deberíamos hacer al final si nos llegara el raspado, lo analizamos y pudimos evaluar de alguna manera su impacto en nuestros indicadores comerciales y técnicos? Por un lado, no tiene sentido luchar contra el scraping por definición como con la recopilación de datos públicos, máquinas o personas; usted mismo acordó que estos datos están disponibles para cualquier usuario que provenga de Internet. Y para resolver el problema de limitar el raspado "fuera de principio", es decir, debido al hecho de que los bots bots avanzados y talentosos vienen a ti, intentas prohibirlos a todos, significa gastar una gran cantidad de recursos en protección, ya sea la tuya propia o usando una solución costosa y muy compleja , autohospedado o basado en la nube en "modo de máxima seguridad" y en la búsqueda de cada bot individual se corre el riesgo de asustar a la parte de usuarios válidos con tales cosas,como comprobaciones pesadas de javascript, como captcha que aparece en cada tercera transición. Todo esto puede cambiar su sitio más allá del reconocimiento a favor de sus visitantes.
Si desea utilizar una herramienta de protección, debe buscar aquellas que le permitan cambiar y de alguna manera encontrar un equilibrio entre la proporción de raspadores (de simples a complejos) que tratará de cortar en el uso de su recurso y, de hecho, la velocidad de su web. -recurso. Porque, como ya hemos visto, algunos controles se realizan de forma sencilla y rápida, mientras que algunos controles son difíciles y requieren mucho tiempo y, al mismo tiempo, son muy notorios para los propios visitantes. Por lo tanto, las soluciones que sean capaces de aplicar y variar estas contramedidas dentro de una plataforma común le permitirán lograr este equilibrio más rápido y mejor.
Bueno, también es muy importante utilizar lo que se llama la "mentalidad correcta" en el estudio de todos estos problemas por su cuenta o por los ejemplos de otros. Debe recordarse que los datos públicos en sí mismos no necesitan protección: tarde o temprano serán vistos por todas las personas que los deseen. La experiencia de usuario necesita protección: la UX de tus clientes, clientes y usuarios, que, a diferencia de los scrapers, te generan ingresos. Puede mantenerlo y aumentarlo si está mejor versado en esta área tan interesante.
¡Muchas gracias por su atención!
