
Varias opciones de visualización nos ayudarán con esto :
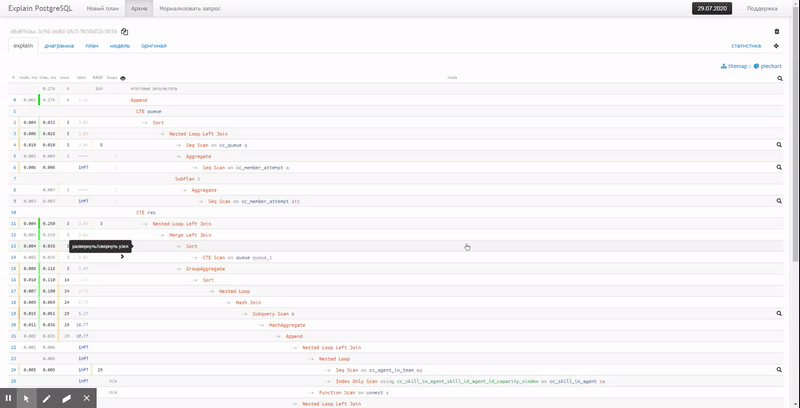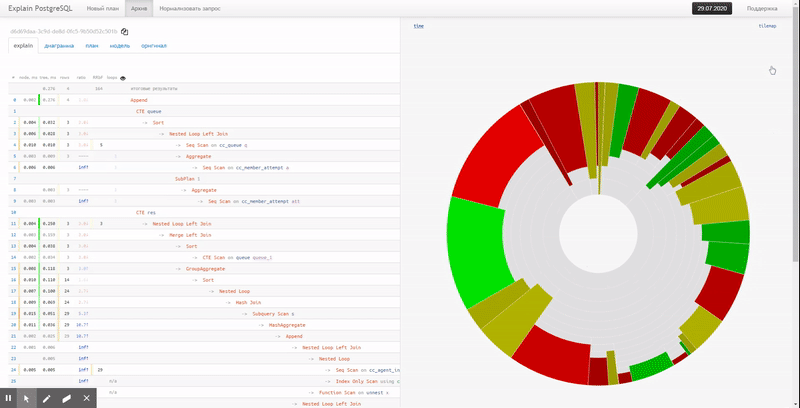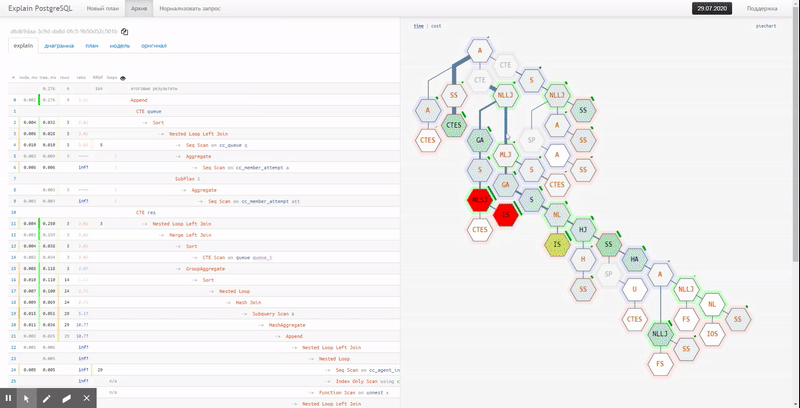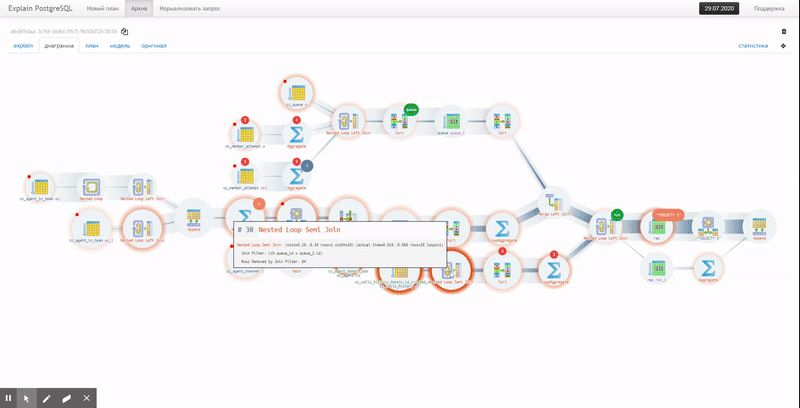
Vista de texto reducida
El texto original de un plan bastante simple ya causa problemas en el análisis:
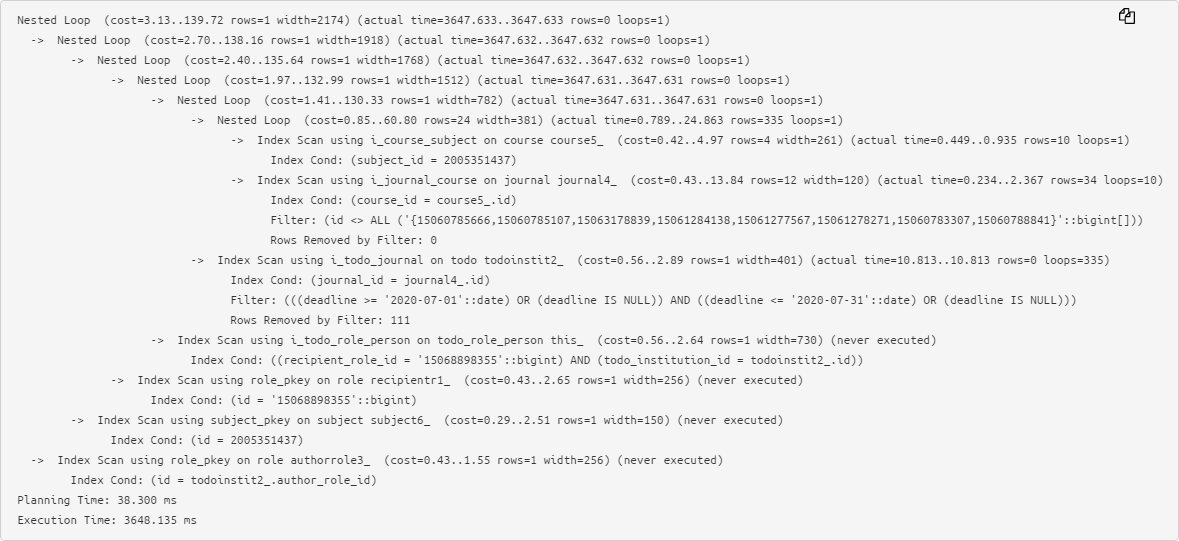
Por lo tanto, preferimos la forma abreviada, cuando la información clave sobre el tiempo de ejecución y los búferes usados de cada nodo se saca a la izquierda y a la derecha , y es muy fácil notar los máximos:
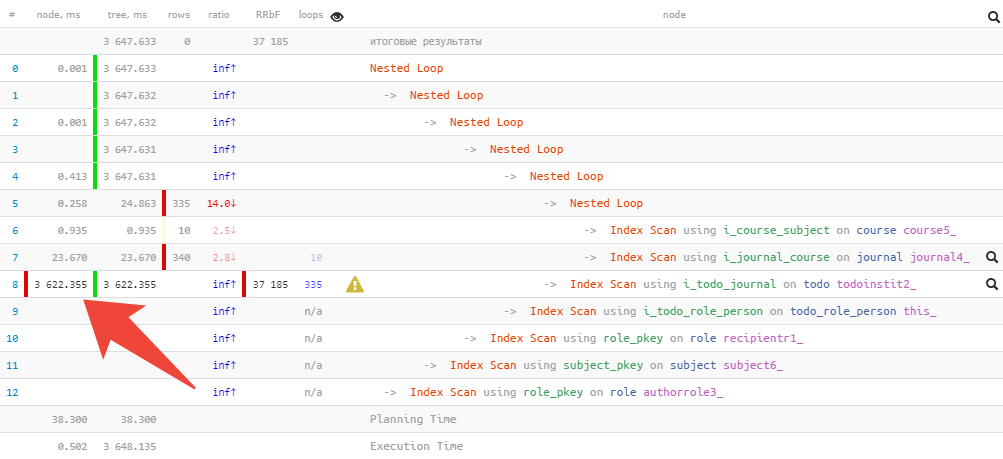
Gráfico circular
Pero a veces, incluso solo entender "dónde duele más" no es fácil, especialmente si contiene varias decenas de nodos e incluso la forma abreviada del plan toma 2-3 pantallas.

En este caso, el gráfico circular habitual vendrá al rescate:
Inmediatamente, de repente, puede ver la participación aproximada del consumo de recursos por cada uno de los nodos. Cuando pasamos el cursor sobre él, a la izquierda en la vista de texto, veremos un icono para el nodo seleccionado.
Loseta
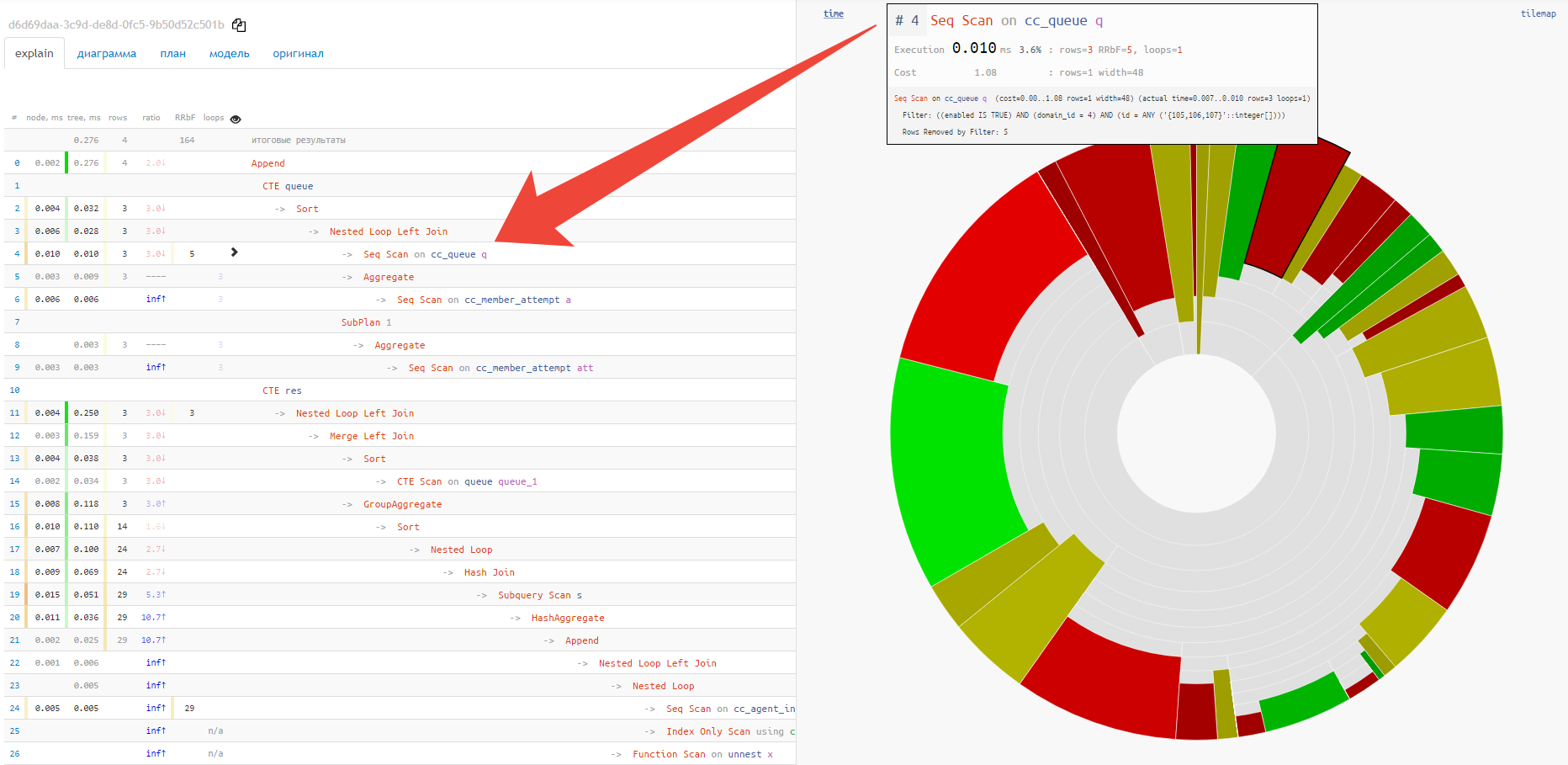
Por desgracia, el gráfico circular no muestra la relación entre los diferentes nodos y los puntos "más calientes". Para esto, la opción "mosaico" es mucho más adecuada:
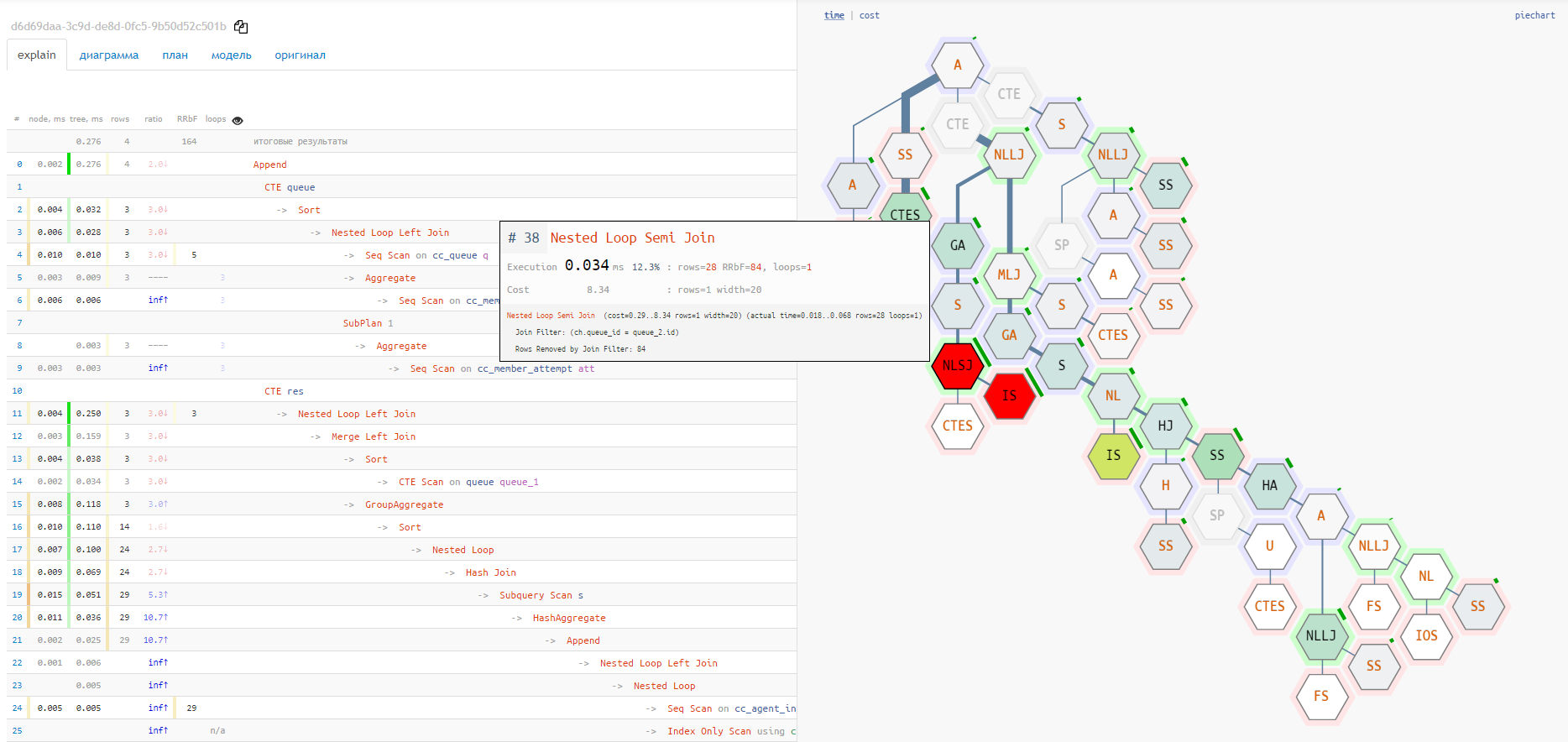
Diagrama de ejecución
Pero ambas opciones no muestran la cadena completa de adjuntos de nodos de servicio
CTE/InitPlain/SubPlan; solo se puede ver en el diagrama de ejecución real:

¡Se necesitan más métricas!
Si dispara el plan de la ejecución real de la consulta como
EXPLAIN (ANALYZE), verá solo el tiempo transcurrido allí . ¡Pero muy a menudo esto no es suficiente para sacar conclusiones correctas!
Por ejemplo, al ejecutar una consulta en un caché "frío", recibirá (¡pero no verá!) El tiempo de recepción de datos de los medios, y no el trabajo de la consulta en sí.
Por tanto, un par de recomendaciones:
- Utilice para ver el volumen de páginas de datos que se restan. Este valor prácticamente no está sujeto a fluctuaciones de la carga del propio servidor y se puede utilizar como métrica para la optimización.
EXPLAIN (ANALYZE, BUFFERS) - Úselo
track_io_timingpara comprender exactamente cuánto tiempo tardó en trabajar con el transportista .
Y si su plan contiene no solo tiempo , sino también
bufferso i/o timings, entonces en cada una de las opciones del diagrama puede cambiar al modo de análisis para estas métricas. A veces puede ver de inmediato, por ejemplo, que más de la mitad de todas las lecturas recayeron en un solo nodo problemático:

Artículos anteriores sobre el tema: