 Mucha gente sabe que ABBYY procesa y extrae datos de varios documentos. Pero nuestros productos también tienen otras posibilidades interesantes. En particular, con la solución ABBYY Intelligent Search, puede buscar rápida y cómodamente información significativa en documentos electrónicos de sistemas corporativos. Esto ya está siendo utilizado por grandes empresas rusas, por ejemplo, NPO Energomash , un fabricante de motores de cohetes .
Mucha gente sabe que ABBYY procesa y extrae datos de varios documentos. Pero nuestros productos también tienen otras posibilidades interesantes. En particular, con la solución ABBYY Intelligent Search, puede buscar rápida y cómodamente información significativa en documentos electrónicos de sistemas corporativos. Esto ya está siendo utilizado por grandes empresas rusas, por ejemplo, NPO Energomash , un fabricante de motores de cohetes .
La práctica a largo plazo muestra que el tiempo que lleva llevar los motores espaciales al mercado desde el inicio del trabajo es de 5 a 7 años. Al mismo tiempo, para mantener una posición de liderazgo, es necesario reducir el tiempo de desarrollo y fabricación a 3 - 4 años. Además, la intensificación de la competencia ha llevado a la necesidad de reducir significativamente el costo de los motores fabricados en un 30-50%.
Estos indicadores no se pueden lograr sin la introducción de tecnologías digitales modernas. Las empresas más avanzadas utilizan enfoques innovadores no solo en todas las etapas de producción, sino también en todas las etapas del ciclo de vida de sus productos. Cuantas más empresas se vuelvan digitales, más aguda se vuelve la pregunta: ¿cómo utilizar Big Data para obtener el máximo beneficio para ellas?
Más de 90 años de trabajo NPO Energomash ha acumulado un volumen centenario de documentos (tanto en papel como electrónicos) con información valiosa sobre los desarrollos de probadores y diseñadores. La mayoría de los documentos ya están almacenados en los sistemas de información de la empresa (SI). Según la investigación de IDC, en promedio, los empleados de las grandes organizaciones utilizan 5-6 SI internos. En promedio, aproximadamente el 36% del tiempo se dedica a la búsqueda de información; en una gran empresa, esto equivale a miles de horas de trabajo al día.
Hoy le contaremos cómo ayudamos a NPO Energomash a crear un sistema corporativo de recuperación de información inteligente (KIIPS) basado en ABBYY Intelligent Search , tan conveniente y rápido como los motores de búsqueda populares.
¿Qué hace Energomash y qué tiene que ver Gagarin con él?
 Desde el día de su fundación, el 15 de mayo de 1929, Energomash ha fabricado más de 12 mil motores para vehículos de lanzamiento no solo en Rusia, sino también en el extranjero. Estos "motores" se utilizaron para lanzar el primer satélite artificial de la Tierra, fueron al espacio "Vostok-1" con el primer cosmonauta Yuri Gagarin a bordo, voló el avión espacial "Buran" y los vehículos de lanzamiento estadounidenses Atlas y Antares aún se están lanzando. Por ejemplo, el cohete Atlas V del 26 de marzo de 2020, equipado con motores rusos, puso en órbita un sistema de comunicaciones por satélite estratégico militar estadounidense. En el primer semestre de 2020, los motores desarrollados por Energomash funcionaron con éxito en 11 lanzamientos espaciales, lo que representa el 24,4% de todos los lanzamientos en el mundo.
Desde el día de su fundación, el 15 de mayo de 1929, Energomash ha fabricado más de 12 mil motores para vehículos de lanzamiento no solo en Rusia, sino también en el extranjero. Estos "motores" se utilizaron para lanzar el primer satélite artificial de la Tierra, fueron al espacio "Vostok-1" con el primer cosmonauta Yuri Gagarin a bordo, voló el avión espacial "Buran" y los vehículos de lanzamiento estadounidenses Atlas y Antares aún se están lanzando. Por ejemplo, el cohete Atlas V del 26 de marzo de 2020, equipado con motores rusos, puso en órbita un sistema de comunicaciones por satélite estratégico militar estadounidense. En el primer semestre de 2020, los motores desarrollados por Energomash funcionaron con éxito en 11 lanzamientos espaciales, lo que representa el 24,4% de todos los lanzamientos en el mundo.
Hoy Energomash es parte de la corporación estatal Roscosmos y encabeza la estructura integrada de propulsión de cohetes, que incluye a las empresas líderes en esta industria.
En los últimos años, la compañía ha estado introduciendo activamente soluciones de TI a gran escala que hacen un uso extensivo del análisis de datos, el aprendizaje automático y todas las capacidades de las tecnologías de procesamiento del lenguaje natural. La compañía se ha fijado un objetivo estratégico de fabricación totalmente digital para 2021.
Por ejemplo, en el marco del proyecto " Tecnologías de diseño y producción digitales»Una de las tareas clave fue la implementación de un sistema PLM (sistema automatizado de gestión del ciclo de vida del producto). Su objetivo es garantizar la creación de documentación de diseño electrónico (ECD) y modelar sobre su base el funcionamiento del motor y otros procesos de trabajo en las unidades tecnológicas y de producción de NPO Energomash y la preparación para el intercambio de ECD entre las empresas de la industria.
¿Por qué fue necesario buscar en el universo de Energomash?
Para lograr el objetivo estratégico de crear producción digital, la empresa está llevando a cabo una amplia gama de proyectos basados en el trabajo con grandes cantidades de datos. Uno de ellos es un proyecto para crear un sistema corporativo de recuperación de información inteligente.
El objetivo del proyecto es preservar, incrementar y servir la producción digital con el conocimiento y la competencia de la empresa acumulados durante décadas de trabajo.
En el marco del proyecto se resolvieron dos tareas:
1). Facilite a los diseñadores e ingenieros la búsqueda de información útil en documentos de años anteriores.
Se crearon muchos desarrollos en la URSS, pero no todos se implementaron, porque no siempre se asignaron inversiones para ellos o el nivel de desarrollo tecnológico no permitió completar el plan. En nuestro tiempo, tales desarrollos pueden encontrar una segunda vida. Para ello, la empresa pide a diseñadores experimentados que compartan sus trabajos de investigación y dibujos, que todavía están en papel. Esto ayudará a digitalizar datos valiosos, preservarlos durante muchos años y transferir conocimientos a la generación más joven de científicos e ingenieros.
Por supuesto, la búsqueda de documentos en sistemas electrónicos existía antes en Energomash, pero no era fácil para los empleados encontrar la información que necesitaban para trabajar.
Debajo del spoiler, le contaremos con más detalle cómo se organizó este proceso anteriormente.
7 . , - , , - – , , . , , :
, , , , . , , : . , .
:
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
- ;
- ;
- , , .
, , , , . , , : . , .
:
- . , , ;
- , , .
. « » () , . , « », , , , , , . , , . - , «».
, , , , , .
2). Simplifique y agilice la búsqueda de datos para los departamentos de servicios: contables, abogados y otros especialistas que redactan, editan, coordinan documentos en sistemas contables e intercambian información.
La empresa quería que los empleados pudieran recopilar y analizar la información financiera, de fabricación y otra información relevante que necesitan para realizar su trabajo desde sistemas corporativos dispares, simplemente ingresando consultas en una sola cadena de búsqueda. Era necesario crear un único punto de acceso a los datos almacenados en los sistemas de información de la empresa, con la provisión de acceso delimitado a la información, en función de la autoridad del usuario en cada sistema.
¿Por qué es importante? En 7 años, más de la mitad de todos los datos del mundo se almacenarán en sistemas corporativos, se desprende deInforme de antigüedad de datos de Seagate e IDC . Para tener siempre a mano la información necesaria, es necesario encontrarla rápidamente. Así, según un estudio de IDC y ABBYY "El mercado de la inteligencia artificial en Rusia", los representantes de TI (48%) y las unidades de negocio (33%) ven grandes oportunidades en el uso de la IA para la búsqueda corporativa y la clasificación de documentos en los próximos dos años.
Para hacer frente a estas tareas, la empresa necesitaba una búsqueda conveniente de un extremo a otro en numerosas direcciones IP. Energomash consideró varios motores de búsqueda, pero al final decidió probar ABBYY Intelligent Search. La elección estuvo influenciada, en primer lugar, por la disponibilidad de tecnologías de procesamiento del lenguaje natural que permiten encontrar documentos relevantes para las consultas de búsqueda por significado y no solo por palabras clave. En segundo lugar, la capacidad de diferenciar los derechos de acceso de los usuarios a los resultados de búsqueda. Te contaremos más sobre esto un poco más tarde, pero ahora, sobre cómo comenzamos.
La primera "salida" a la búsqueda
Energomash decidió verificar el trabajo de búsqueda inteligente en 3 mil documentos de la base de datos de información (BID) de trabajos de investigación, diseño y cálculo.
Para ello, ABBYY ha desarrollado un prototipo de conector para el BID, que vincula ABBYY Intelligent Search a la base de datos de documentos. Un conector es un programa java que se utiliza para cargar documentos en un índice. ¿Cómo funciona?
1). Primero construimos un índice de búsqueda de texto completo
Un índice de texto completo es, en términos generales, una lista de todas las palabras de un documento y sus metadatos (número de documento, título, fecha de creación). El índice de texto completo se crea con bastante rapidez y le permite buscar la información necesaria por palabras clave, las que aparecen en el texto.


Para crear un índice de texto completo, necesita un conector. Conecta la solución de búsqueda a un sistema de información específico y recopila (“indexa”) las características de cada documento, por ejemplo:
- el nombre de la IP donde se almacena el archivo,
- la fecha de la última modificación del documento,
- la versión del documento en la fuente,
- formato de documento,
- los códigos de los idiomas en los que está redactado el documento,
- ruta al documento en el IS,
- fecha de la última indexación del documento
- y etc.
Estas características en el futuro ayudarán no solo a acelerar la búsqueda de un documento, sino también a simplificar la lógica de trabajar con ellos para el conector. En particular, el conector analiza diferentes versiones del mismo documento para incluir solo la última en el índice. El conector también recibe información sobre los documentos que se han eliminado de la fuente.
Un rastreador (robot de búsqueda) integrado en ABBYY Intelligent Search ayuda a crear un índice de búsqueda. Sondea los conectores a intervalos regulares, comprueba si han aparecido nuevos documentos en el SI, qué documentos se han eliminado, cómo han cambiado los derechos de acceso a los documentos. En consecuencia, el índice se actualiza con una frecuencia determinada.
No solo se indexan documentos de texto, sino también archivos gráficos. Por ejemplo, se pueden escanear copias de dibujos en JPEG o PDF sin capa de texto. Al trabajar con imágenes, la solución de búsqueda primero reconoce automáticamente el texto y lo agrega al índice de búsqueda.
Además, el sistema puede manejar archivos ZIP, RAR, TAR, siempre que no estén protegidos por contraseña. Los archivos se descomprimen, las imágenes de ellos se reconocen y el texto se indexa.
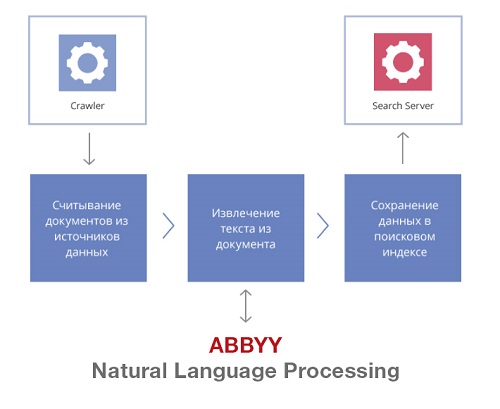

El índice de búsqueda contiene un conjunto arbitrario de campos, que también se pueden utilizar para filtrar los resultados de la búsqueda (autor del documento, fecha de creación, número de producto, etc.).
2). Luego aplicamos tecnologías de procesamiento del lenguaje natural
En segundo plano, el índice de búsqueda se enriquece con información semántica . Para esto, usamos la ontología semántico-lingüística que ya tenemos, en otras palabras, descripciones de objetos y fenómenos del mundo real. Ya hemos hablado de cómo creamos este modelo en Habré aquí y aquí .
Mediante el uso de tecnologías de procesamiento de lenguaje natural y aprendizaje automático, cada documento analiza la sintaxis de las oraciones, la morfología y los significados semánticos de literalmente cada palabra del texto. Esta información complementa el índice de búsqueda y permite buscar no por palabras clave, sino por sinónimos, hipónimos.y otros constructos que transmiten el mismo significado pero en diferentes expresiones. De esta forma, el motor de búsqueda busca con mayor precisión información en fuentes corporativas.


Esto es muy conveniente si uno de nuestros pares ha formulado una consulta de búsqueda con sus propias palabras y quiere encontrar documentos hace 40 años, donde, quizás, el tema que necesitaba fue llamado por otros términos. Por ejemplo, para la consulta "defecto de trama", el sistema seleccionará todas las posibles expresiones semánticas asociadas con este término. Los resultados pueden incluir " deflexión ", " agujero ", " torcedura " o "el hecho de violación de la documentación tecnológica de diseño ".
Aquí hay otro ejemplo:

los resultados de búsqueda de " fluctuaciones de empuje " también mostrarán textos que contienen la frase " variación de empuje ".
Las tecnologías de procesamiento del lenguaje natural también ayudan al motor de búsqueda a corregir automáticamente los errores ortográficos en el texto de la consulta. Por ejemplo, el sistema comprenderá que hay errores en la palabra "cojinete" e inmediatamente buscará documentos que mencionen "cojinete".
Resultados del primer lanzamiento
Para evaluar el trabajo de un motor de búsqueda inteligente, los especialistas de Energomash completaron alrededor de 30 consultas de documentos del BID utilizando el motor de búsqueda integrado en el BID y utilizando ABBYY Intelligent Search . Luego compararon los resultados de la búsqueda: qué documentos fueron encontrados por ambos sistemas, qué frases se destacaron en fragmentos. Como resultado, la búsqueda integrada en el BID no arrojó resultados para algunas consultas, ya que solo puede detectar palabras clave, no palabras relacionadas. ABBYY Intelligent Search ha devuelto documentos relevantes para todas las consultas.
En cuanto a la velocidad, cumpliendo con los requisitos de la plataforma de hardwarela respuesta de búsqueda no superó una fracción de segundo, como en los motores de búsqueda populares. Las consultas más complejas tardaron un máximo de 3 segundos.
Después de un proyecto piloto exitoso, Energomash decidió utilizar la solución ABBYY Intelligent Search en el corazón del Sistema de búsqueda de información inteligente corporativa.
Vamos mas lejos
Energomash conectó 7 fuentes corporativas a la búsqueda: sistema de gestión de documentos electrónicos LanDocs, almacenamiento de archivos, IDB, sistema de soporte del ciclo de vida del producto TeamCenter, sistema de gestión de recursos Galaktika ERP y AMM y sistema de información de gestión de proyectos. Se ha creado un índice separado para cada sistema de información. Esto hace que el motor de búsqueda sea flexible en la administración y hace posible reconstruir el índice para cada sistema por separado, estableciendo nuevas condiciones. El acceso al Sistema de Búsqueda Corporativa se organiza a través del portal interno de la empresa en la página principal. El proyecto se implementó conjuntamente con un socio, LANIT , el grupo diversificado más grande de empresas de TI de Rusia.
Los principales módulos del sistema de búsqueda corporativa:
- página principal de consultas de búsqueda y resultados de búsqueda;
- panel de administración (configuración de índices, filtros, metadatos para cada sistema de información);
- estadísticas del número de documentos (muestra el número de documentos en el índice para cada sistema de información para el período).
El sistema de búsqueda corporativa se encuentra en operación comercial desde el 1 de julio de 2020. En el momento del lanzamiento, se indexaron 500 mil documentos. Se espera que para fin de año, con el uso activo del sistema y la conexión de nuevas fuentes de información, el número de documentos en el índice supere el millón.
Cómo garantizar la seguridad
Como cualquier gran empresa, NPO Energomash tiene documentos que no están destinados al acceso de todos los empleados. El requisito de seguridad clave al lanzar el proyecto fue proporcionar acceso a los documentos de acuerdo con el modelo a seguir de cada sistema de información. Para esto se hizo:
1). Almacenamiento local de información
La solución de búsqueda de ABBYY se implementa en un servidor separado en el circuito interno de NPO Energomash. Todos los índices de búsqueda y sus copias de seguridad en caso de pérdida y su configuración se almacenan allí.
2). Modelo a seguir del sistema de información
Por seguridad, se organiza la diferenciación de los derechos de acceso de los usuarios a los resultados de búsqueda para cada sistema de información. Todos los sistemas corporativos conectados a ABBYY Intelligent Search admiten la autorización de dominio. El usuario inicia sesión en el sistema con una cuenta de dominio, ejecuta una solicitud y ve el documento en los resultados de la búsqueda, teniendo en cuenta la configuración de vista previa del documento para cada sistema de información y el nivel de acceso realizado directamente en el propio sistema de búsqueda corporativo, y teniendo en cuenta el acceso al documento en el propio sistema de información fuente. ... Si el usuario tiene derechos para trabajar con el documento en el sistema de origen, la transición al documento original se puede realizar directamente desde el sistema de búsqueda corporativo haciendo clic en el enlace.
Planes para el futuro
Según la idea de Energomash, la recuperación de información inteligente ayudará a simplificar y acelerar los procesos comerciales en la empresa, por ejemplo, acelerar indirectamente la entrada de nuevos productos al mercado, mejorar su calidad y reducir el costo. Las ideas y proyectos que se han conservado en documentos antiguos se pueden utilizar en desarrollos modernos de la empresa. Por ejemplo, cree algo completamente nuevo sobre la base de los desarrollos y manténgase por delante de los competidores en el mercado mundial.
Mencionemos también nuestros planes para el futuro:
- En el futuro, está previsto conectar fuentes de información de otras empresas que forman parte de la estructura de Energomash al sistema de búsqueda corporativa. En este caso, el índice de búsqueda puede expandirse a 2 millones de documentos.
- , , – . , - . , , : , - , . , , . , , .
- Energomash también planea explorar la posibilidad de construir informes analíticos complejos usando la función de búsqueda.
En su opinión, ¿qué otras tareas puede resolver mediante la búsqueda corporativa?