
Continuando con el ciclo de notas sobre problemas reales en Data Science, hoy trataremos un problema vivo y veremos qué problemas nos esperan en el camino.
Por ejemplo, además de la ciencia de datos, me gusta el atletismo durante mucho tiempo y uno de los objetivos de correr para mí, por supuesto, es un maratón. Y dónde está el maratón y la pregunta es: ¿cuánto correr? A menudo, la respuesta a esta pregunta se da a simple vista: "bueno, en promedio, están corriendo" o "¡este es un buen momento!"
Y hoy abordaremos un asunto importante: aplicaremos la ciencia de datos en la vida real y responderemos la pregunta:
¿Qué nos dicen los datos sobre el maratón de Moscú?
Más precisamente, como ya está claro en la tabla al principio, recopilaremos datos, averiguaremos quién corrió y cómo. ¡Y al mismo tiempo nos ayudará a comprender si debemos entrometernos y permitirnos evaluar con sensatez nuestras fortalezas!
TL; DR: Recopilé datos sobre las carreras de maratón de Moscú para 2018/2019, analicé el tiempo y el rendimiento de los participantes y puse el código y los datos a disposición del público.
Recopilación de datos
A través de una búsqueda rápida en Google, encontramos los resultados de los últimos años, 2019 y 2018 .
Miré detenidamente la página web, y quedó claro que los datos son bastante fáciles de obtener; solo necesita averiguar qué clases son responsables de qué, por ejemplo, la clase "results-table__col-result", por supuesto, del resultado, etc.
Queda por entender cómo obtener todos los datos de allí.
Y resulta que esto no es difícil, porque hay paginación directa y en realidad iteramos sobre todo el segmento de números. Bingo, publico los datos recopilados para 2019 y 2018 aquí, si alguien está interesado en un análisis más detallado, entonces los datos en sí se pueden descargar aquí: aquí y aquí .
¿Con qué tenía que jugar?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- Tipos de datos: el tiempo aquí es un tiempo delta, pero debido a los reinicios y los valores no válidos, tenemos que trabajar con filtros y borrar los valores de tiempo para que podamos operar con resultados de tiempo puro para calcular promedios; todos los resultados aquí son promedios sobre aquellos que terminaron y que tiene un tiempo válido.
Y aquí está el código de spoiler en caso de que alguien decida continuar recopilando datos de ejecución interesantes.
Código analizador
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Análisis de tiempos y resultados
Pasemos a analizar los datos y los resultados reales de la carrera.
Usado pandas, numpy, matplotlib y seaborn, todo en los clásicos.
Además de los valores promedio para todas las matrices, consideraremos por separado los siguientes grupos:
- Hombres: como pertenezco a este grupo, estos resultados me interesan.
- Las mujeres están a favor de la simetría.
- 35 — «» , — .
- 2018 2019 — ?.
Primero, echemos un vistazo rápido a la tabla a continuación, aquí nuevamente, para no desplazarse: hay más participantes, el 95% en promedio llega a la línea de meta y la mayoría de los participantes son hombres. Bien, esto significa que en promedio estoy en el grupo principal y los datos en promedio deberían representar bien el tiempo promedio para mí. Continuemos.
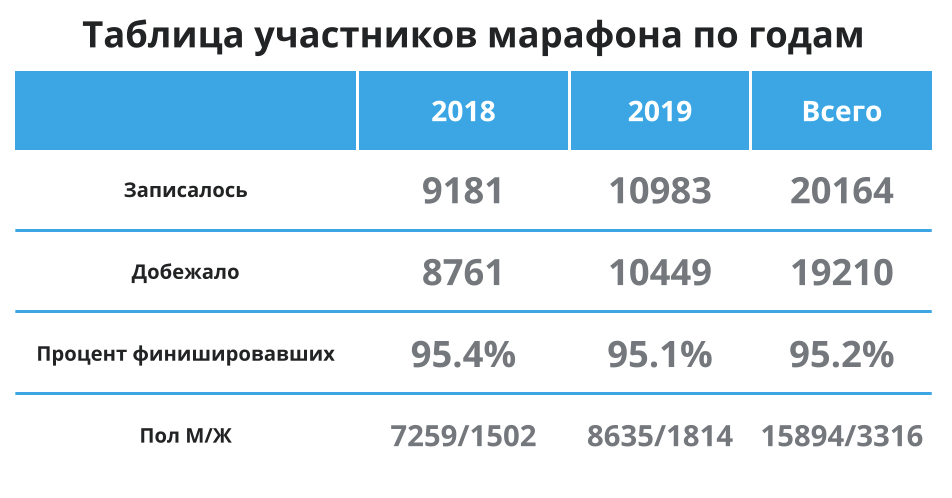

Como podemos ver, los promedios para 2018 y 2019 prácticamente no cambiaron: aproximadamente 1,5 minutos fueron más rápidos para los corredores en 2019. La diferencia entre los grupos que me interesan es insignificante.
Pasemos a las distribuciones en su conjunto. Y primero al tiempo total de la carrera.
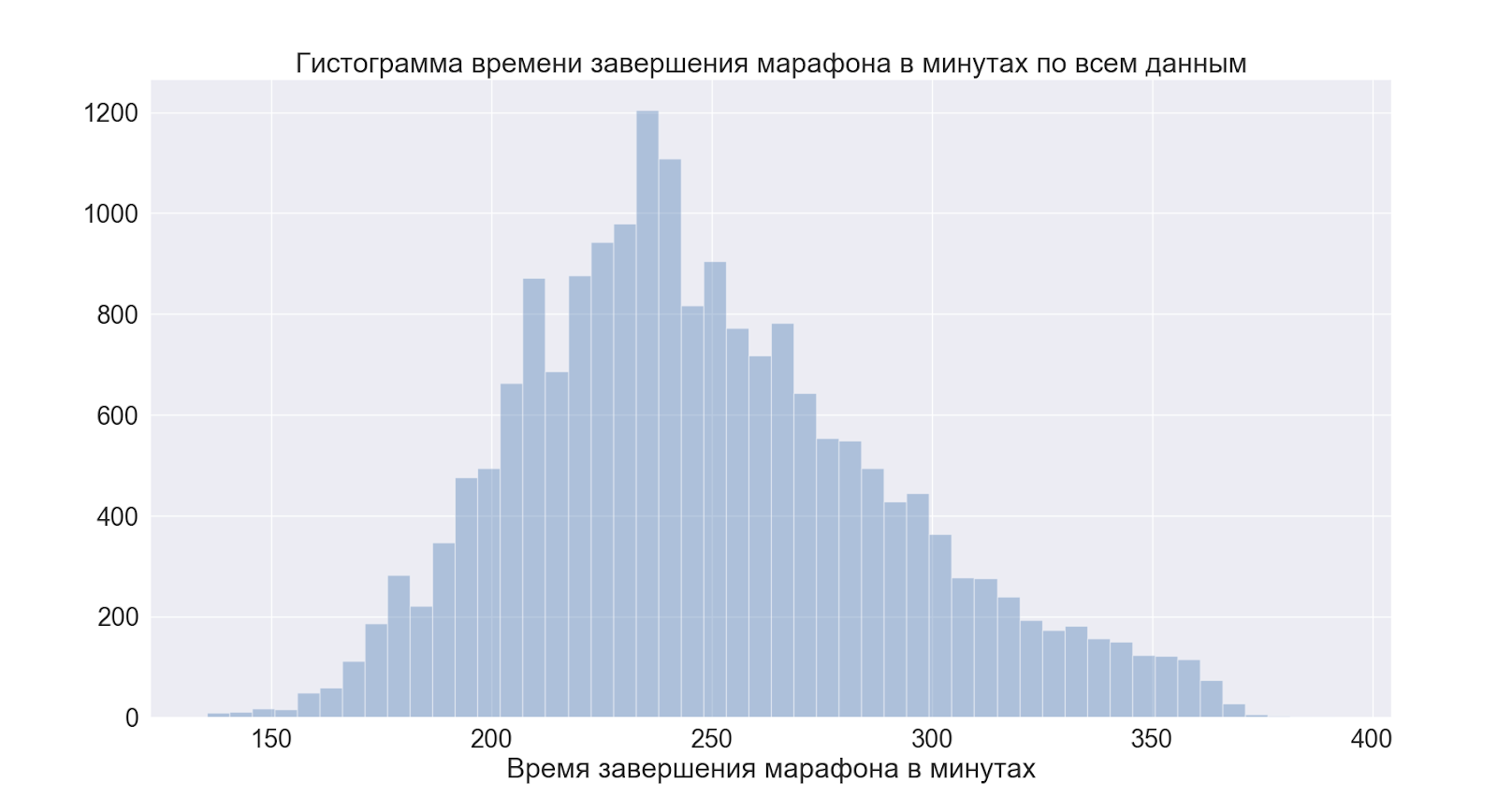
Como podemos ver el pico justo antes de las 4 en punto, esta es una marca condicional para aquellos a quienes les gusta “correr bien” = “agotar las 4 horas”, los datos confirman el rumor popular.
A continuación, veamos cómo ha cambiado la situación en promedio durante el año.
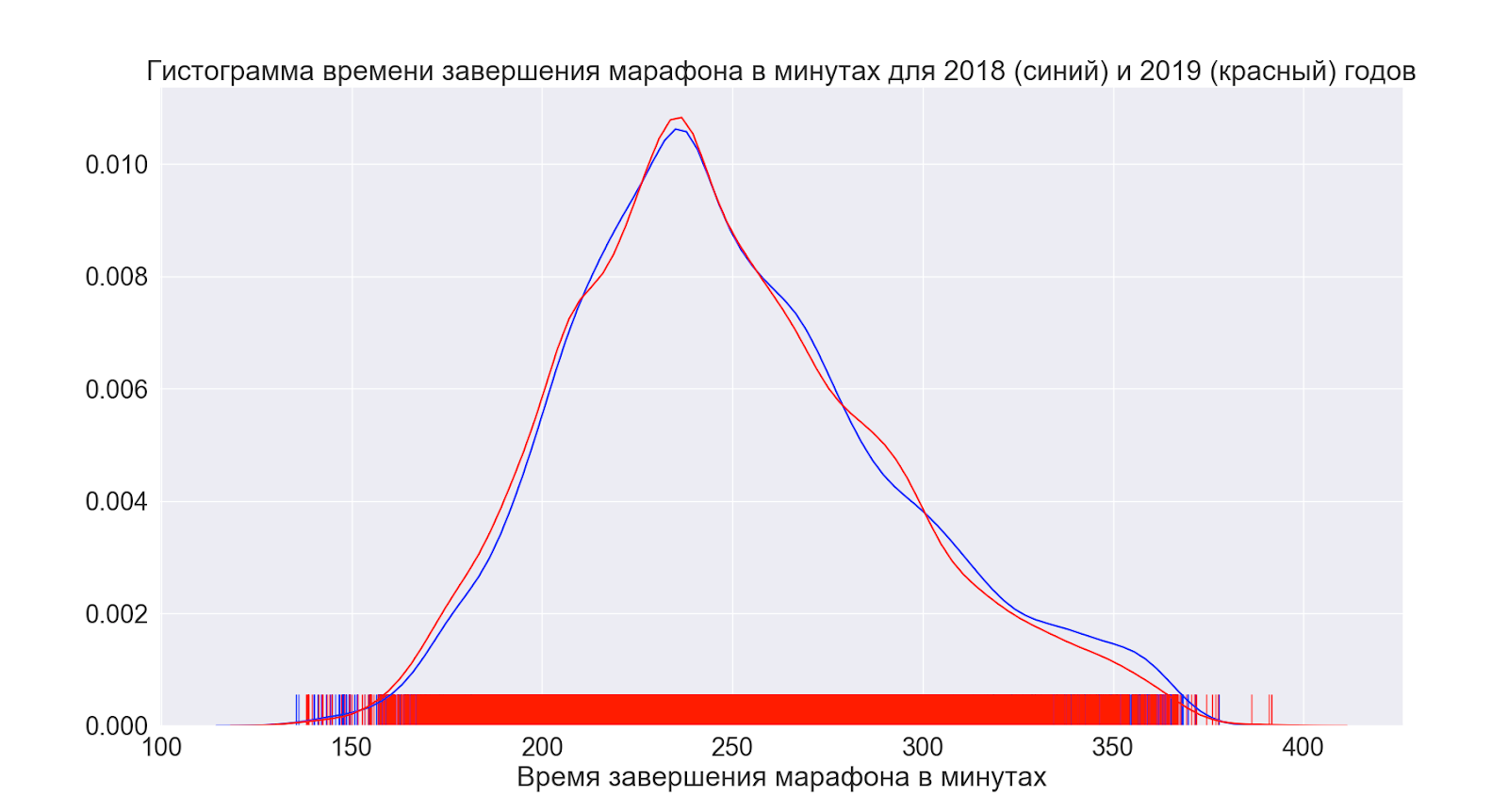
Como podemos ver, de hecho, nada ha cambiado en absoluto: las distribuciones parecen prácticamente idénticas.
A continuación, considere las distribuciones por género:

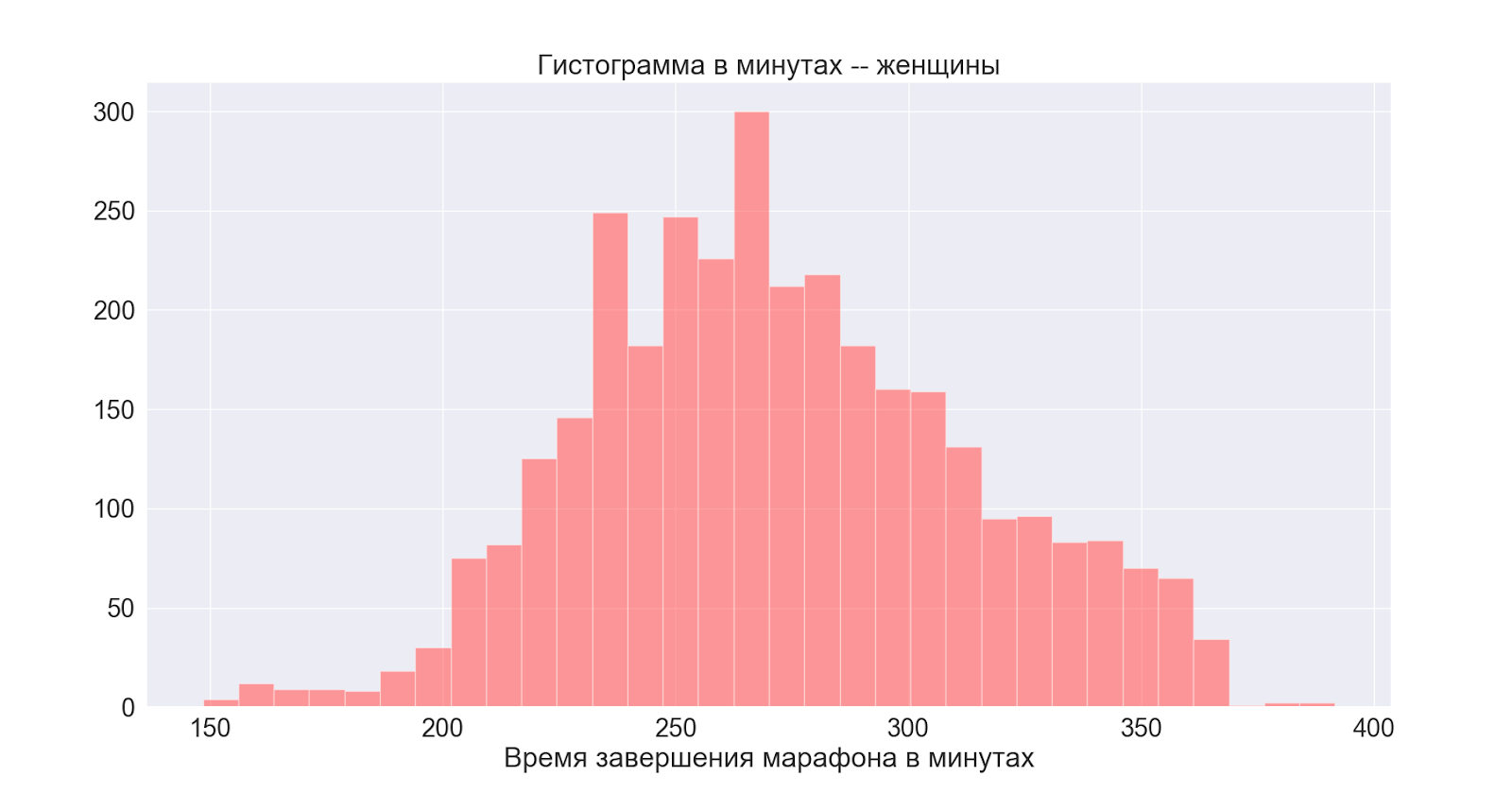
en general, ambas distribuciones son normales con centros ligeramente diferentes; vemos que el pico en el hombre también se manifiesta en la distribución principal (general).
Por separado, pasemos al grupo que es más interesante para mí:
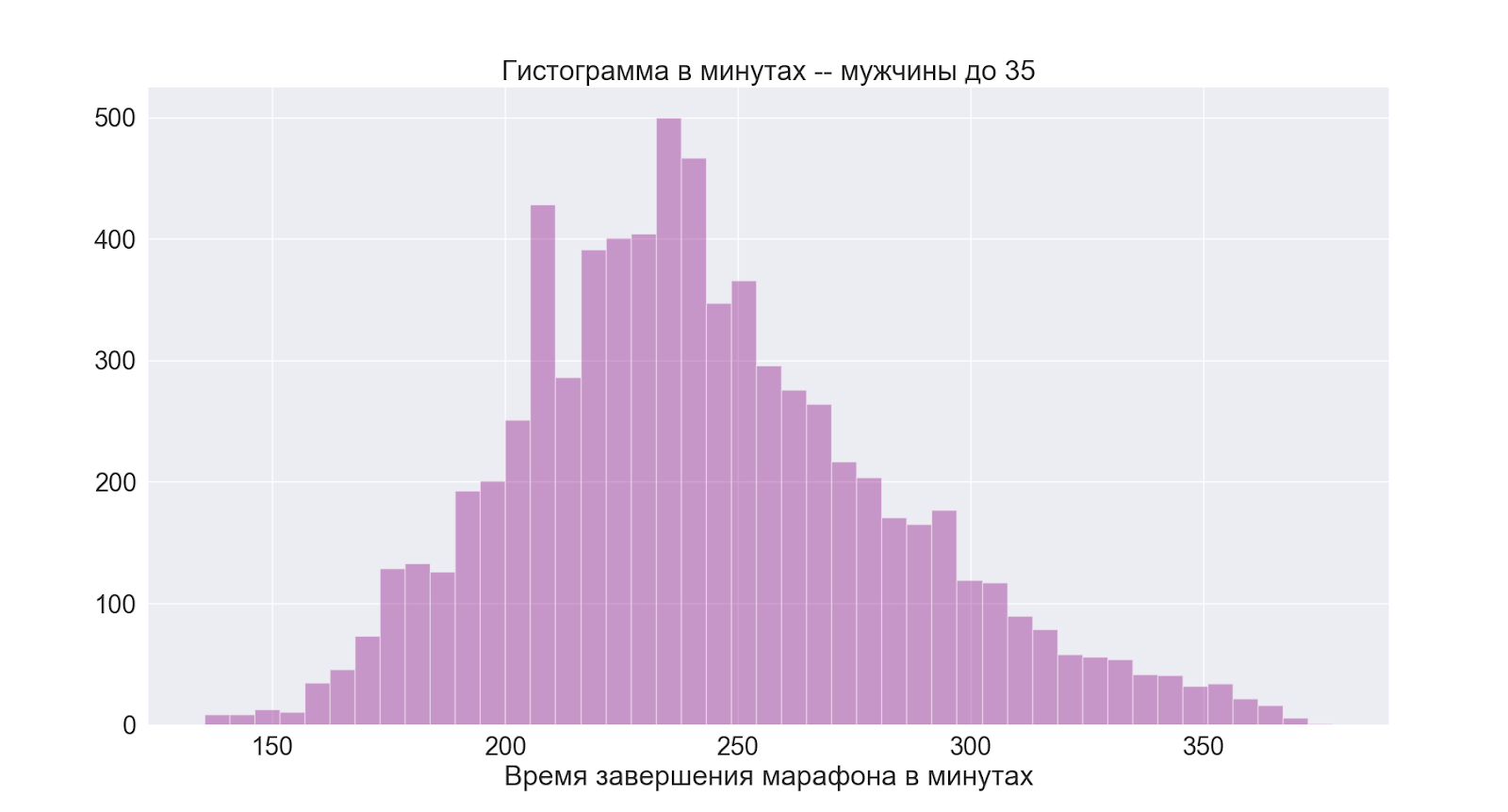
como podemos ver, la imagen es básicamente la misma que en el grupo de hombres en su conjunto.
De esto concluimos que 4 horas también es un buen tiempo promedio para mí.
Estudiando las mejoras de los participantes 2018 → 2019
De interés: por alguna razón pensé que ahora recopilaría datos rápidamente y podría profundizar en el análisis, buscar patrones allí durante horas, etc. Resultó ser al revés, la recopilación de datos resultó ser más difícil que el análisis en sí: según los clásicos, trabajar con la red, datos sin procesar, limpiar, formatear, emitir, etc., tomó mucho más tiempo que el análisis y la visualización. No olvides que las pequeñas cosas toman un poco de tiempo, pero hay bastantes de ellas [pequeñas cosas], y al final acabarán consumiendo toda la noche.
Por separado, quería ver cómo las personas que participaron en ambas ocasiones mejoraron sus resultados, al comparar los datos entre los años, pude establecer lo siguiente:
- 14 personas participaron ambos años y nunca terminaron
- 89 personas corrieron a 18 m, pero fallaron a los 19
- 124 viceversa
- Aquellos que pudieron correr ambas veces mejoraron su resultado en 4 minutos en promedio
Pero aquí todo resultó ser bastante interesante:
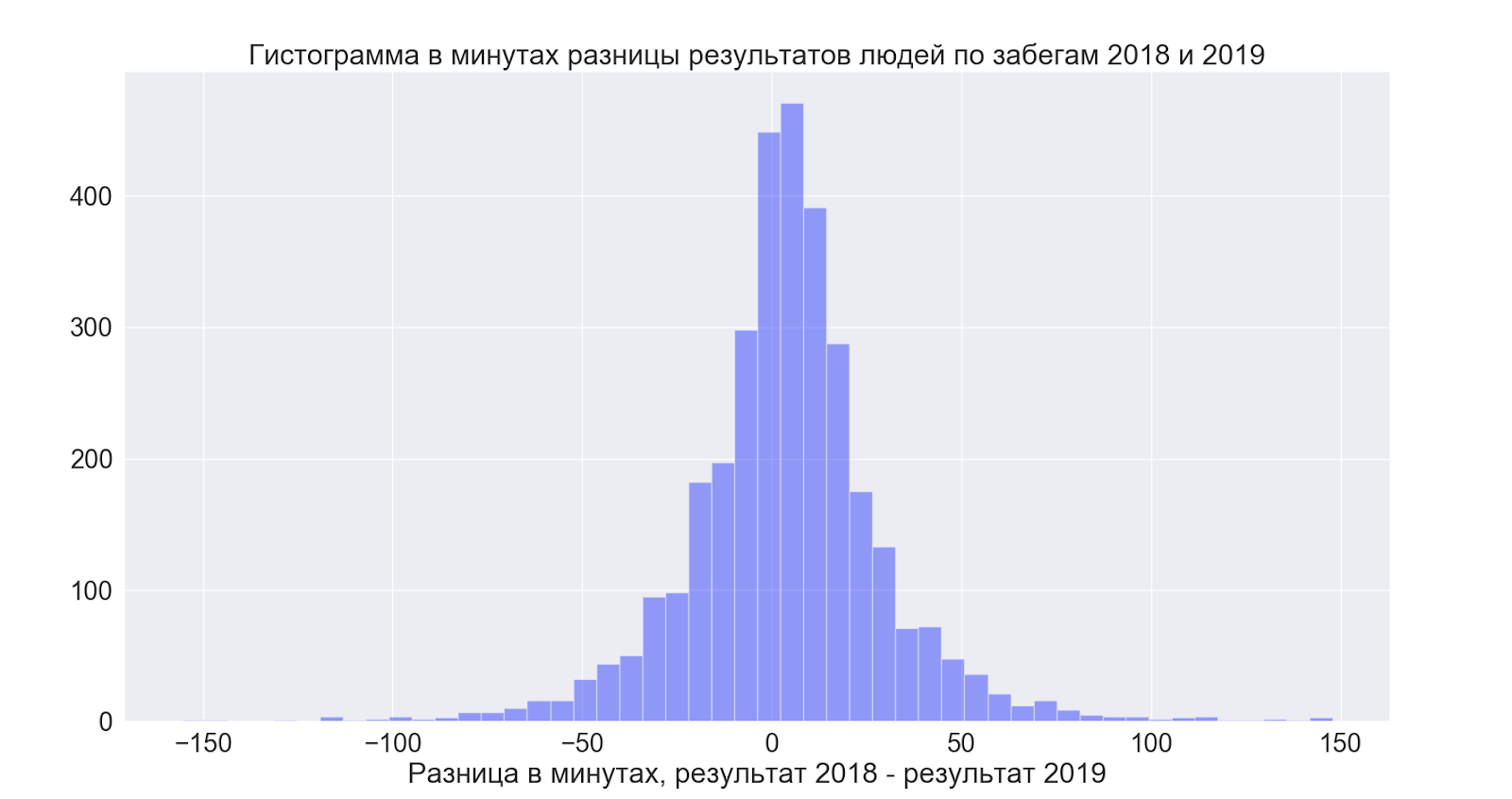
es decir, en promedio, la gente mejora ligeramente los resultados, pero en general la propagación es increíble y en ambas direcciones, es decir, es bueno esperar que sea mejor, pero a juzgar por los datos, ¡resulta en general lo que te gusta!
conclusiones
Hice las siguientes conclusiones por mí mismo a partir de los datos analizados.
- En general, 4 horas es un buen objetivo promedio.
- El grupo principal de corredores ya está en una edad muy competitiva (y en el mismo grupo que yo).
- En promedio, las personas mejoran levemente sus resultados, pero en general, a juzgar por los datos, cómo llegan allí.
- Los resultados promedio de toda la carrera son aproximadamente los mismos para ambos años.
- Es muy cómodo hablar del maratón desde el sofá.
