
Durante los últimos tres años, Nvidia ha estado creando chips gráficos en los que, además de los núcleos habituales utilizados para los sombreadores, se instalan otros adicionales. Estos núcleos, llamados núcleos tensoriales, ya se encuentran en miles de computadoras de escritorio, portátiles, estaciones de trabajo y centros de datos en todo el mundo. Pero, ¿para qué sirven y para qué sirven? ¿Son incluso necesarios en tarjetas gráficas?
Hoy explicaremos qué es un tensor y cómo se utilizan los núcleos tensoriales en el mundo de los gráficos y el aprendizaje profundo.
Una breve lección de matemáticas
Para comprender qué están haciendo los núcleos tensoriales y para qué se pueden usar, primero averiguamos qué son los tensores. Todos los microprocesadores, independientemente de la tarea que realicen, realizan operaciones matemáticas con números (suma, multiplicación, etc.).
A veces, estos números deben agruparse porque tienen un cierto significado entre sí. Por ejemplo, cuando el chip procesa datos para representar gráficos, puede tratar con valores enteros simples (digamos, +2 o +115) como un factor de escala, o un grupo de flotantes (+0.1, -0.5, +0.6) como un coordenadas de un punto en el espacio 3D. En el segundo caso, los tres elementos de datos son necesarios para la posición del punto.
TensorEs un objeto matemático que describe las relaciones entre otros objetos matemáticos relacionados entre sí. Por lo general, se muestran como una matriz de números, cuyas dimensiones se muestran a continuación.

El tipo de tensor más simple tiene dimensión cero y consta de un solo valor; de lo contrario, se llama escalar . A medida que aumenta el número de dimensiones, encontramos otras estructuras matemáticas comunes:
- 1 dimensión = vector
- 2 dimensiones = matriz
Estrictamente hablando, un escalar es un tensor 0 x 0, un vector es 1 x 0 y una matriz es 1 x 1, pero por simplicidad y referencia a los núcleos tensoriales de la GPU, consideraremos los tensores solo en forma de matrices.
Una de las operaciones matemáticas más importantes que se realizan con matrices es la multiplicación (o producto). Echemos un vistazo a cómo se multiplican entre sí dos matrices con cuatro filas y columnas de datos:
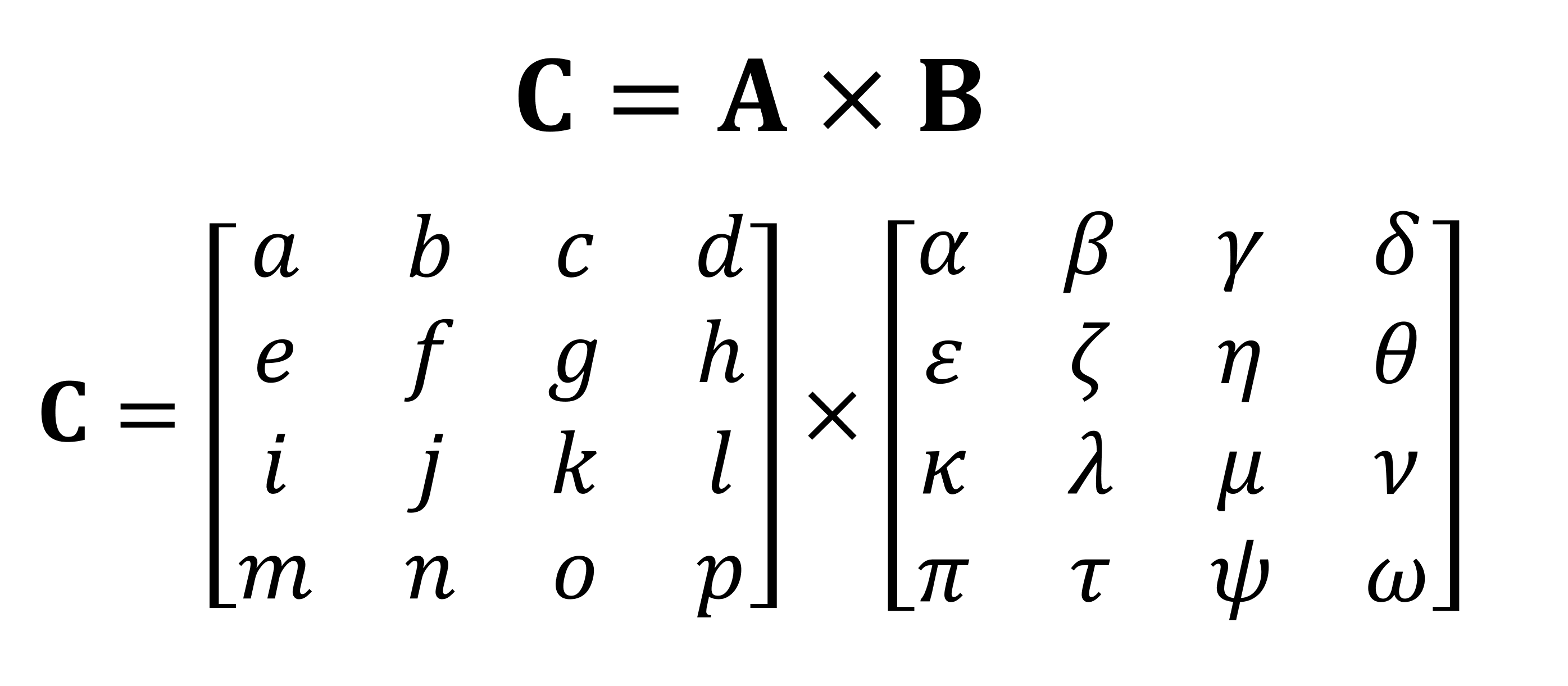
El resultado final de la multiplicación será siempre el mismo número de filas que en la primera matriz y el mismo número de columnas que en la segunda. ¿Cómo se multiplican estas dos matrices? Me gusta esto:
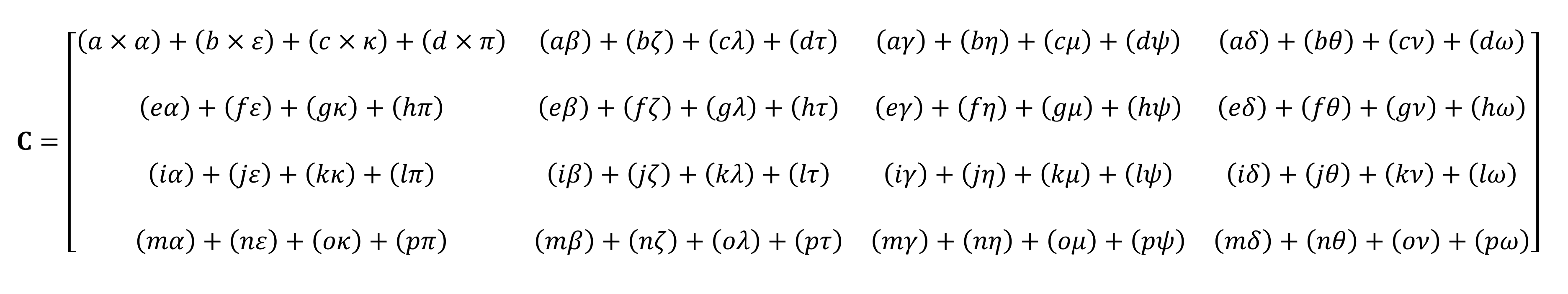
No será posible calcularlo con los dedos.
Como puede ver, el cálculo del producto "simple" de matrices consiste en un montón de pequeñas multiplicaciones y adiciones. Dado que cualquier unidad central de procesamiento moderna puede realizar ambas operaciones, cualquier computadora de escritorio, computadora portátil o tableta puede realizar los tensores más simples.
Sin embargo, el ejemplo que se muestra arriba contiene 64 multiplicaciones y 48 sumas; cada producto pequeño da un valor que debe almacenarse en algún lugar antes de que pueda agregarse a los otros tres productos pequeños para que el valor tensorial final pueda almacenarse más tarde. Por lo tanto, a pesar de la simplicidad matemática de las multiplicaciones de matrices, son computacionalmente costosas. - Es necesario utilizar muchos registros y la caché debe poder hacer frente a un montón de operaciones de lectura y escritura.

Arquitectura Intel Sandy Bridge, que introdujo por primera vez las extensiones AVX
A lo largo de los años, los procesadores AMD e Intel han tenido varias extensiones (MMX, SSE y ahora AVX, todas las cuales son SIMD, datos múltiples de una sola instrucción ), lo que permite que el procesador procese simultáneamente muchos números punto flotante; esto es exactamente lo que se requiere para la multiplicación de matrices.
Pero hay un tipo especial de procesador que está diseñado específicamente para manejar operaciones SIMD: la unidad de procesamiento de gráficos (GPU).
¿Más inteligente que una calculadora normal?
En el mundo de los gráficos, es necesario transmitir y procesar simultáneamente grandes cantidades de información en forma de vectores. Debido a su capacidad de procesamiento paralelo, las GPU son ideales para el procesamiento tensorial; todas las GPU modernas admiten una funcionalidad llamada GEMM ( Multiplicación de matriz general ).
Se trata de una operación "pegada" en la que se multiplican dos matrices y el resultado se acumula con otra matriz. Existen restricciones importantes sobre el formato de las matrices y todas están relacionadas con el número de filas y columnas de cada matriz.

Requisitos de filas y columnas de GEMM: matriz A (mxk), matriz B (kxn), matriz C (mxn)
Los algoritmos utilizados para realizar operaciones en matrices suelen funcionar mejor cuando las matrices son cuadradas (por ejemplo, una matriz de 10 x 10 funcionará mejor que 50 x 2) y de tamaño bastante pequeño. Pero seguirán funcionando mejor si se procesan en equipos que están diseñados exclusivamente para tales operaciones.
En diciembre de 2017, Nvidia lanzó una tarjeta gráfica con una GPU con la nueva arquitectura Volta . Estaba dirigido a mercados profesionales, por lo que este chip no se utilizó en los modelos GeForce. Fue único porque fue la primera GPU con núcleos solo para cálculos de tensores.

Tarjeta gráfica Nvidia Titan V con chip GV100 Volta. Sí, puede ejecutar Crysis en él. Los
núcleos tensores de Nvidia fueron diseñados para ejecutar 64 GEMM por ciclo de reloj con matrices 4 x 4 que contienen valores FP16 (números de coma flotante de 16 bits) o multiplicación FP16 con suma FP32. Dichos tensores son de tamaño muy pequeño, por lo que al procesar conjuntos de datos reales, los núcleos procesan pequeñas partes de matrices grandes, creando la respuesta final.
Menos de un año después, Nvidia lanzó la arquitectura Turing . Esta vez, los núcleos tensoriales también se instalaron en el modelo GeForce.nivel de consumidor. El sistema se mejoró para admitir otros formatos de datos, como INT8 (valor entero de 8 bits), pero por lo demás funcionaba igual que en Volta.

A principios de este año, la arquitectura Ampere debutó en la GPU del centro de datos A100 , y esta vez Nvidia aumentó el rendimiento (256 GEMM por ciclo en lugar de 64), agregó nuevos formatos de datos y la capacidad de procesamiento muy rápido de tensores dispersos (matrices con muchos ceros).
Los programadores pueden acceder a los núcleos tensoriales de los chips Volta, Turing y Ampere muy fácilmente: el código solo necesita usar una bandera que le indique a la API y los controladores que usen núcleos tensoriales, el tipo de datos debe ser compatible con los núcleos y las dimensiones de la matriz deben ser múltiplos de 8. Cuando se ejecuta Todas estas condiciones serán atendidas por el equipo.
Todo eso es genial, pero ¿cuánto mejores son los núcleos Tensor en el procesamiento de GEMM que los núcleos GPU normales?
Cuando salió el Volta, Anandtech realizó pruebas de matemáticas en tres tarjetas de Nvidia: la nueva Volta, la más poderosa de la alineación de Pascal, y la vieja tarjeta de Maxwell.
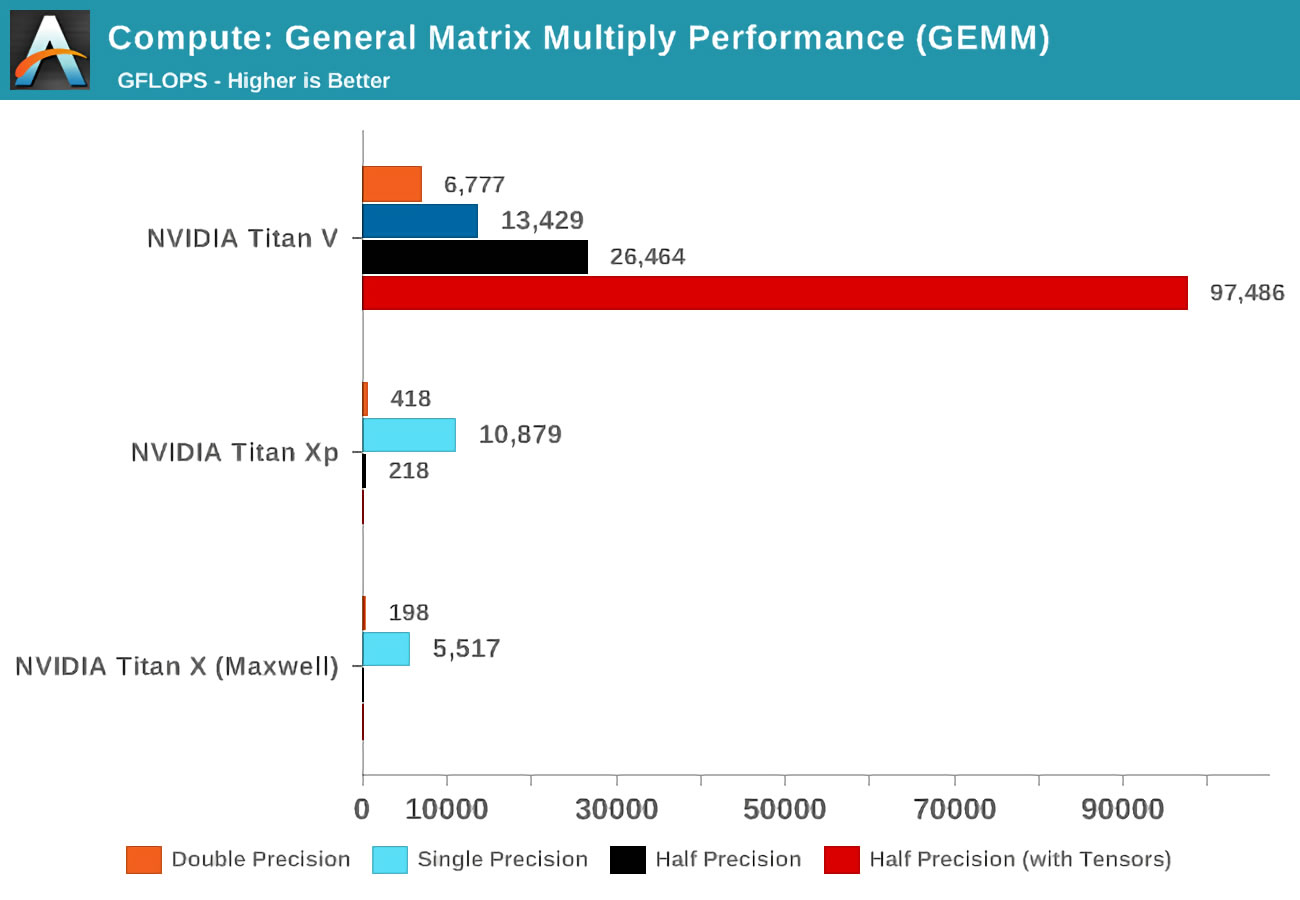
El concepto de exactitud (precisión) se refiere al número de bits usados para números de coma flotante en las matrices: doble (doble) denota 64, un simple (simple) - 32, y así sucesivamente. El eje horizontal es el número máximo de operaciones de coma flotante realizadas por segundo, o FLOP para abreviar (recuerde que un GEMM son 3 FLOP).
¡Solo eche un vistazo a los resultados cuando use núcleos tensoriales en lugar de los llamados núcleos CUDA! Obviamente, son increíbles en este trabajo, pero ¿qué podemos hacer con los núcleos tensoriales?
Las matemáticas que hacen que todo sea mejor
La computación tensorial es extremadamente útil en física e ingeniería, se usa para resolver todo tipo de problemas complejos en mecánica de fluidos , electromagnetismo y astrofísica , sin embargo, las computadoras que se usaron para procesar tales números generalmente realizaban operaciones en matrices en grandes grupos de unidades centrales de procesamiento.
Otra área en la que los tensores son populares es el aprendizaje automático , especialmente su subsección "aprendizaje profundo". Su significado se reduce a procesar enormes conjuntos de datos en matrices gigantes llamadas redes neuronales . A las conexiones entre diferentes valores de datos se les asigna un cierto peso, un número que expresa la importancia de una conexión en particular.
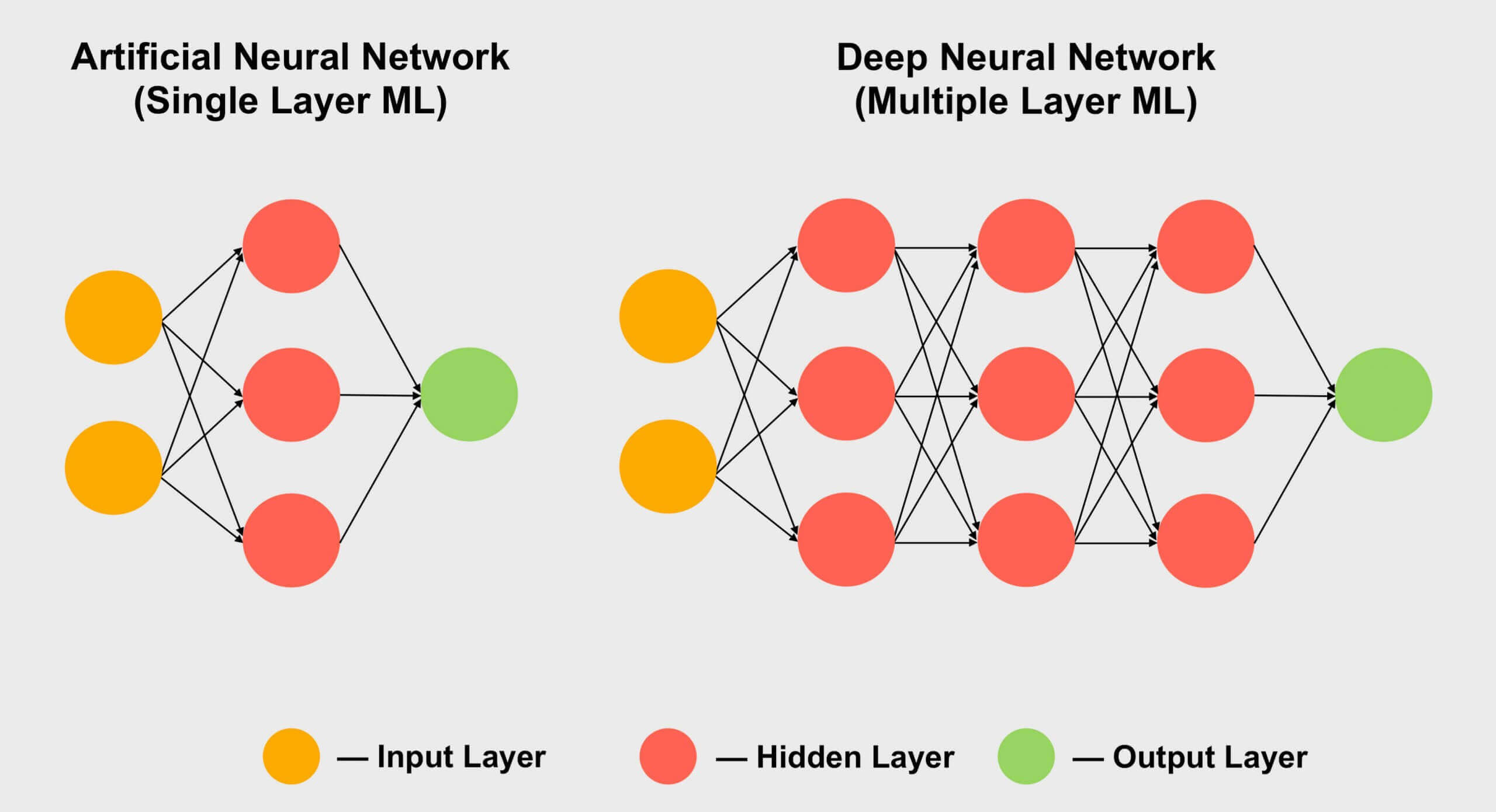
Entonces, cuando necesitamos averiguar cómo interactúan todos estos cientos, si no miles, de conexiones, debemos multiplicar cada pieza de datos en la red por todos los pesos de conexión posibles. En otras palabras, multiplique dos matrices, ¡que es la matemática tensorial clásica!

Los chips de Google TPU 3.0 están cubiertos por un sistema de refrigeración por agua.
Es por eso que todas las supercomputadoras de aprendizaje profundo usan GPU, y casi siempre es Nvidia. Sin embargo, algunas empresas incluso han desarrollado sus propios procesadores a partir de núcleos tensores. Google, por ejemplo, anunció el desarrollo de su primera TPU ( unidad de procesamiento de tensor ) en 2016 , pero estos chips son tan especializados que no pueden hacer nada más que operaciones con matrices.
Núcleos de tensor en GPU de consumo (GeForce RTX)
Pero, ¿qué pasa si compro una tarjeta gráfica Nvidia GeForce RTX, sin ser un astrofísico que resuelve problemas múltiples de Riemann o un experto que experimenta con profundidades de redes neuronales convolucionales ...? ¿Cómo puedo usar núcleos tensoriales?
La mayoría de las veces, no se aplican a la reproducción, codificación o decodificación de video normal, por lo que puede parecer que ha gastado dinero en una función inútil. Sin embargo, Nvidia ha incorporado núcleos tensores en sus productos de consumo en 2018 (Turing GeForce RTX) mientras implementaba DLSS - Deep Learning Super Sampling .

El principio es simple: renderice el fotograma a una resolución bastante baja y, una vez finalizado, aumente la resolución del resultado final para que coincida con las dimensiones de la pantalla "nativa" del monitor (por ejemplo, renderice a 1080p y luego cambie el tamaño a 1400p). Esto mejora el rendimiento porque se procesan menos píxeles y aún se produce una imagen hermosa en la pantalla.
Las consolas han tenido esta función durante años, y muchos juegos de PC modernos también ofrecen esta función. En Assassin's Creed: Odyssey de Ubisoft, puedes reducir la resolución de renderizado a tan solo el 50% de la resolución del monitor. Desafortunadamente, los resultados no se ven tan bien. Así es como se ve el juego en 4K con la configuración de gráficos máxima:

Las texturas se ven mejor en altas resoluciones porque retienen más detalles. Sin embargo, se requiere mucho procesamiento para mostrar estos píxeles en la pantalla. Ahora eche un vistazo a lo que sucede cuando el renderizado se establece en 1080p (25% del número anterior de píxeles), usando los sombreadores al final para estirar la imagen a 4K.

Debido a la compresión jpeg, es posible que la diferencia no se note de inmediato, pero puede ver que la armadura del personaje y la roca en la distancia se ven borrosas. Acerquemos una parte de la imagen para verla más de cerca:

La imagen de la izquierda está renderizada en 4K; la imagen de la derecha es 1080p ampliada a 4K. La diferencia es mucho más notable en el movimiento, porque el suavizado de todos los detalles se convierte rápidamente en un desorden borroso. Parte de la nitidez se puede restaurar gracias al efecto de nitidez de los controladores de la tarjeta gráfica, pero sería mejor si no tuviéramos que hacer esto en absoluto.
Aquí es donde entra en juego DLSS, en la primera versiónesta tecnología Nvidia analizó varios juegos seleccionados; se ejecutaron a alta resolución, baja resolución, con y sin suavizado. En todos estos modos, se generó un conjunto de imágenes y luego se cargó en las supercomputadoras de la compañía, que utilizaron una red neuronal para determinar la mejor manera de convertir una imagen de 1080p en una imagen ideal de mayor resolución.

Debo decir que DLSS 1.0 no era perfecto : a menudo se perdían detalles y aparecían parpadeos extraños en algunos lugares. Además, no usó los núcleos tensores de la tarjeta gráfica en sí (se ejecutó en la red Nvidia) y cada juego habilitado para DLSS requirió una investigación de Nvidia separada para generar el algoritmo de ampliación.

Cuando se lanzó la versión 2.0 a principios de 2020, se le realizaron importantes mejoras. Lo más importante es que las supercomputadoras de Nvidia ahora solo se usaban para crear un algoritmo de escalado general: la nueva versión de DLSS usa datos de un marco renderizado para procesar píxeles usando un modelo neuronal (núcleos tensores de GPU).

Estamos impresionados con las capacidades de DLSS 2.0 , pero hasta ahora muy pocos juegos lo admiten; en el momento de escribir este artículo, solo había 12. Cada vez más desarrolladores quieren implementarlo en sus juegos futuros, y por una buena razón.
Cualquier aumento en la escala puede lograr ganancias de productividad significativas, por lo que puede estar seguro de que DLSS seguirá evolucionando.
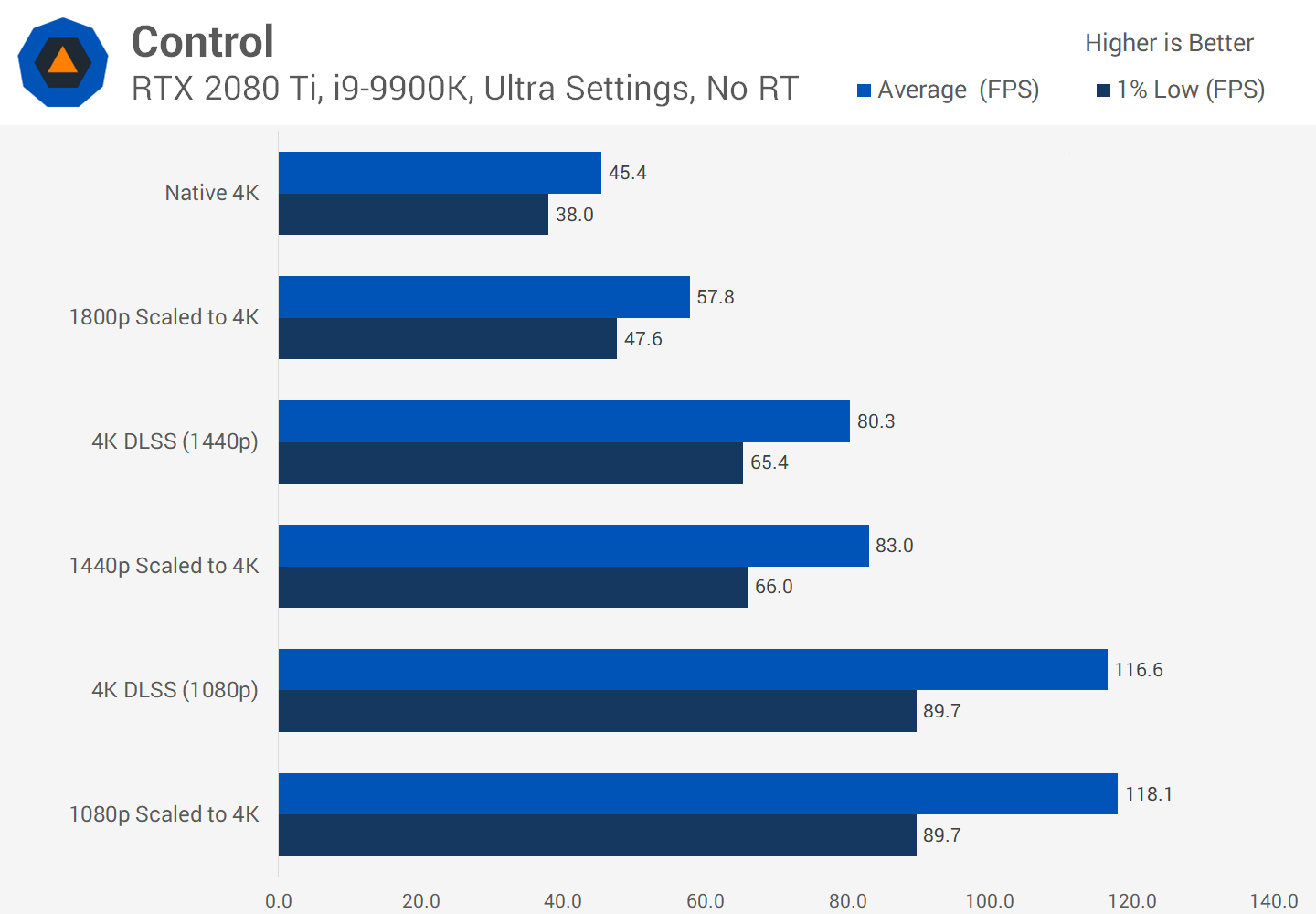
Si bien los resultados visuales de DLSS no siempre son perfectos, al liberar recursos de renderizado, los desarrolladores pueden agregar más efectos visuales o proporcionar un nivel de gráficos en una gama más amplia de plataformas.
Por ejemplo, DLSS a menudo se anuncia junto con el trazado de rayos en juegos "habilitados para RTX". Las tarjetas GeForce RTX contienen bloques computacionales adicionales llamados núcleos RT, que son bloques lógicos especializados para acelerar las intersecciones de rayos y triángulos y el recorrido de la jerarquía del volumen delimitador (BVH). Estos dos procesos son procedimientos que requieren mucho tiempo y determinan cómo la luz interactúa con otros objetos en la escena.
Como descubrimos, el trazado de rayosEs un proceso que consume mucho tiempo, por lo que para garantizar un nivel aceptable de velocidad de fotogramas en los juegos, los desarrolladores deben limitar la cantidad de rayos y reflejos realizados en la escena. Este proceso puede crear imágenes granuladas, por lo que se debe aplicar un algoritmo de reducción de ruido, lo que aumenta la complejidad del procesamiento. Se espera que los núcleos tensoriales mejoren el rendimiento de este proceso al eliminar el ruido mediante la IA, pero esto aún no se ha realizado: la mayoría de las aplicaciones modernas todavía usan núcleos CUDA para esta tarea. Por otro lado, dado que DLSS 2.0 se está convirtiendo en una técnica de ampliación muy práctica, los núcleos tensores se pueden utilizar eficazmente para aumentar la velocidad de fotogramas después del trazado de rayos en una escena.
Hay otros planes para aprovechar los núcleos tensores de las tarjetas GeForce RTX, como mejorar las animaciones de los personajes o la simulación de tejidos . Pero al igual que con DLSS 1.0, pasará mucho tiempo antes de que haya cientos de juegos que utilicen computación matricial especializada en la GPU.
Un comienzo prometedor
Entonces, la situación es así: núcleos tensores, excelentes unidades de hardware, que, sin embargo, solo se encuentran en algunas tarjetas de consumo. ¿Cambiará algo en el futuro? Dado que Nvidia ya ha mejorado drásticamente el rendimiento de cada Tensor Core en su arquitectura Ampere, existe una gran probabilidad de que se instalen en los modelos de gama baja y media.
Aunque tales núcleos aún no están en las GPU de AMD e Intel, quizás en el futuro los veamos. AMD tiene un sistema para afilar o mejorar detalles en los marcos terminados a costa de una leve disminución en el rendimiento, por lo que la empresa puede apegarse a este sistema, especialmente porque no necesita ser integrado por los desarrolladores, es suficiente habilitarlo en los controladores.
También existe la percepción de que el espacio en los cristales en los chips gráficos se gastaría mejor en núcleos de sombreado adicionales; esto es lo que hizo Nvidia al crear versiones económicas de sus chips Turing. En productos como la GeForce GTX 1650 , la compañía ha abandonado por completo los núcleos tensores y los ha reemplazado con sombreadores FP16 adicionales.
Pero por ahora, si desea proporcionar un procesamiento GEMM ultrarrápido y aprovecharlo al máximo, tiene dos opciones: comprar un montón de CPU multinúcleo enormes o solo una GPU con núcleos tensores.
Ver también: