 ¡Hola habitantes! Hemos publicado una guía práctica para procesar y generar textos en lenguaje natural. El libro está equipado con todas las herramientas y técnicas necesarias para crear sistemas de PNL aplicados con el fin de garantizar el funcionamiento de un asistente virtual (chatbot), un filtro de correo no deseado, un programa de moderador de foros, un analizador de sentimientos, un programa de creación de bases de conocimientos, un analizador inteligente de textos en lenguaje natural o casi cualquier otra aplicación de PNL imaginable.
¡Hola habitantes! Hemos publicado una guía práctica para procesar y generar textos en lenguaje natural. El libro está equipado con todas las herramientas y técnicas necesarias para crear sistemas de PNL aplicados con el fin de garantizar el funcionamiento de un asistente virtual (chatbot), un filtro de correo no deseado, un programa de moderador de foros, un analizador de sentimientos, un programa de creación de bases de conocimientos, un analizador inteligente de textos en lenguaje natural o casi cualquier otra aplicación de PNL imaginable.
El libro está dirigido a desarrolladores de Python de nivel intermedio a avanzado. Una parte importante del libro será de utilidad para aquellos lectores que ya sepan diseñar y desarrollar sistemas complejos, ya que contiene numerosos ejemplos de soluciones recomendadas y revela las capacidades de los algoritmos de PNL más modernos. Si bien el conocimiento de la programación orientada a objetos en Python puede ayudarlo a construir mejores sistemas, no es necesario utilizar la información de este libro.
¿Qué encontrarás en el libro?
I . , . , , , , , . -, , 2–4, . , 90%- 1990- — .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
Redes neuronales de retroalimentación: redes neuronales recurrentes
El Capítulo 7 demuestra las posibilidades de analizar un fragmento o una oración completa usando una red neuronal convolucional, rastreando palabras adyacentes en una oración aplicando un filtro de pesos compartidos (realizando convolución) en ellas. Las palabras que aparecen en grupos también se pueden encontrar en un paquete. La web también es resistente a pequeños cambios en las posiciones de estas palabras. Al mismo tiempo, los conceptos adyacentes pueden afectar significativamente la red. Pero si necesita echar un vistazo al panorama general de lo que está sucediendo, tenga en cuenta las relaciones durante un período de tiempo más largo, ¿una ventana que cubre más de 3-4 tokens del suministro? ¿Cómo introducir el concepto de eventos pasados en la red? ¿Memoria?
Para cada ejemplo de entrenamiento (o lote de ejemplos desordenados) y salida (o lote de salidas) de la red neuronal de retroalimentación, los pesos de la red neuronal deben ajustarse para neuronas individuales según el método de retropropagación. Ya lo hemos demostrado. Pero los resultados de la fase de entrenamiento para el siguiente ejemplo son en su mayoría independientes del orden de los datos de entrada. Las redes neuronales convolucionales intentan capturar estas relaciones de orden capturando las relaciones locales, pero hay otra forma.
En una red neuronal convolucional, cada ejemplo de entrenamiento se pasa a la red como un conjunto agrupado de tokens de palabras. Los vectores de palabras se agrupan en una matriz en la forma (longitud del vector de palabras × número de palabras en el ejemplo), como se muestra en la Fig. 8.1.

Pero esta secuencia de vectores de palabras se puede transmitir con la misma facilidad a la red neuronal feedforward normal del Capítulo 5 (Figura 8.2), ¿verdad?
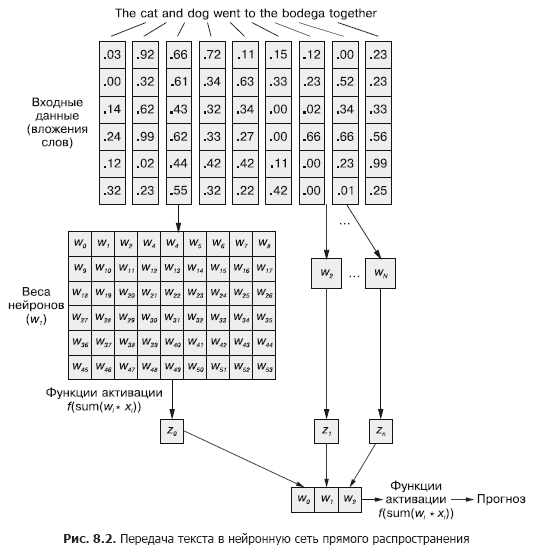
Por supuesto, este es un modelo perfectamente viable. Con este método de transferencia de datos de entrada, la red neuronal feedforward podrá responder a las ocurrencias conjuntas de tokens, que es lo que necesitamos. Pero al mismo tiempo, reaccionará a todas las ocurrencias conjuntas de la misma manera, independientemente de si están separadas por un texto largo o están juntas. Además, las redes neuronales de alimentación directa, como las CNN, son deficientes en el manejo de documentos de longitud variable. No pueden procesar el texto al final del documento si supera el ancho de la web.
Las redes neuronales de retroalimentación funcionan mejor en el modelado de la relación de una muestra de datos en su conjunto con su etiqueta correspondiente. Las palabras al principio y al final de una oración tienen el mismo efecto en la señal de salida que en el medio, aunque es poco probable que estén relacionadas semánticamente entre sí.
Esta uniformidad (uniformidad de influencia) claramente puede causar problemas en el caso de, por ejemplo, fichas de negación severas y modificadores (adjetivos y adverbios) como "no" o "bueno". En una red neuronal de retroalimentación, las palabras de negación afectan el significado de todas las palabras en una oración, incluso si están muy alejadas del lugar en el que realmente deberían influir.
Las convoluciones unidimensionales son una forma de resolver estas relaciones entre tokens analizando varias palabras en las ventanas. Las capas de reducción de resolución discutidas en el Capítulo 7 están diseñadas específicamente para adaptarse a pequeños cambios en el orden de las palabras. En este capítulo, veremos un enfoque diferente que nos ayudará a dar el primer paso hacia el concepto de memoria de red neuronal. En lugar de desensamblar un lenguaje como una gran cantidad de datos, comenzaremos a ver su formación secuencial, token por token, a lo largo del tiempo.
8.1. Memorización en redes neuronales
Por supuesto, las palabras de una oración rara vez son completamente independientes unas de otras; sus ocurrencias están influenciadas o influenciadas por ocurrencias de otras palabras en el documento. Por ejemplo: el coche robado entró a toda velocidad en la arena y el coche del payaso entró a toda velocidad en la arena.
Es posible que tenga impresiones completamente diferentes de las dos oraciones a medida que lee hasta el final. La construcción de la frase en ellos es la misma: adjetivo, sustantivo, verbo y frase preposicional. Pero reemplazar el adjetivo en ellos cambia radicalmente la esencia de lo que está sucediendo desde el punto de vista del lector.
¿Cómo modelar tal relación? ¿Cómo entiendes que arena e incluso speed pueden tener connotaciones ligeramente diferentes si hay un adjetivo delante de ellos en la oración que no es una definición directa de ninguno de ellos?
Si hubiera una manera de recordar lo que sucedió un momento antes (especialmente recordar en el paso t + 1 lo que sucedió en el paso t), sería posible identificar patrones que surgen cuando ciertas fichas aparecen en una secuencia de patrones asociados con otras fichas. Las redes neuronales recurrentes (RNN) hacen posible que una red neuronal memorice las palabras pasadas de una secuencia.
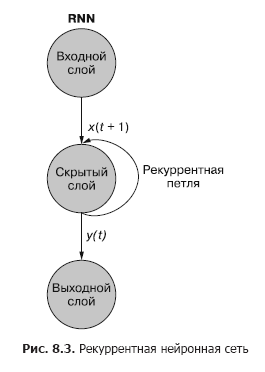
Como puede ver en la fig. 8.3, una neurona recurrente separada de la capa oculta agrega un bucle recurrente a la red para "reutilizar" la salida de la capa oculta en el tiempo t. La salida en el tiempo t se agrega a la siguiente entrada en el tiempo t + 1. La red procesa esta nueva entrada en el paso de tiempo t + 1 para producir una salida de capa oculta en el tiempo t + 1. Esta salida en el tiempo t + 1 luego es reutilizado por la red e incluido en la señal de entrada en un paso de tiempo t + 2, etc.
Si bien la idea de influir en un estado a través del tiempo parece un poco confusa, el concepto básico es simple. Los resultados de cada señal en la entrada de una red neuronal de retroalimentación convencional en un paso de tiempo t se utilizan como una señal de entrada adicional junto con el siguiente dato alimentado a la entrada de la red en un paso de tiempo t + 1. La red recibe información no solo sobre lo que está sucediendo ahora, sino también sobre lo que sucedió antes. ...
. , . , . , . , . , , . . , .
t . , t = 0 — , t + 1 — . () . , . — .
t, — t + 1.
Se puede visualizar una red neuronal recurrente como se muestra en la Fig. 8.3: Los círculos corresponden a capas completas de una red neuronal feedforward, que consta de una o más neuronas. La salida de la capa oculta la proporciona la red como de costumbre, pero luego vuelve como su propia entrada (capa oculta) junto con los datos de entrada habituales del siguiente paso de tiempo. El diagrama muestra este bucle de retroalimentación como un arco que va desde la salida de la capa hasta la entrada.
Una forma más fácil (y más utilizada) de ilustrar este proceso es mediante la implementación de redes. La figura 8.4 muestra una red invertida con dos barridos de la variable de tiempo (t) - capas para los pasos t + 1 y t + 2.
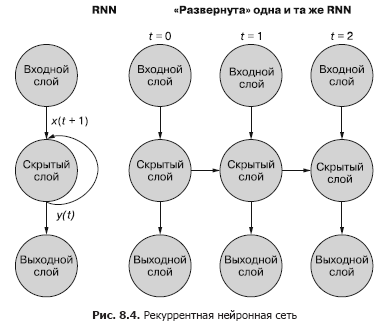
Cada uno de los pasos de tiempo corresponde a una versión expandida de la misma red neuronal en forma de columna de neuronas. Es como ver un guión o cuadros de video individuales de una red neuronal en un momento dado. La red de la derecha representa una versión futura de la red de la izquierda. La salida de la capa oculta en el tiempo (t) se retroalimenta a la entrada de la capa oculta junto con la entrada para el siguiente paso de tiempo (t + 1) a la derecha. Una vez más. El diagrama muestra dos iteraciones de este despliegue, un total de tres columnas de neuronas para t = 0, t = 1 y t = 2.
Todas las rutas verticales en este diagrama son completamente análogas, muestran las mismas neuronas. Reflejan la misma red neuronal en diferentes momentos. Esta representación visual es útil para demostrar el movimiento hacia adelante y hacia atrás de la información a través de la red durante la propagación hacia atrás de un error. Pero recuerde cuando observe estas tres redes implementadas: son instantáneas diferentes de la misma red con el mismo conjunto de pesos.
Echemos un vistazo más de cerca a la representación original de la red neuronal recurrente antes de implementarla y mostremos la relación entre las señales de entrada y los pesos. Las capas individuales de este RNN se ven como se muestra en la Fig. 8.5 y 8.6.

Todas las neuronas en estado latente tienen un conjunto de pesos aplicados a cada uno de los elementos de cada uno de los vectores de entrada, como en una red de alimentación convencional. Pero en este esquema, apareció un conjunto adicional de pesos entrenables, que se aplican a las señales de salida de neuronas ocultas del paso de tiempo anterior. La red, mediante el entrenamiento, selecciona los pesos apropiados (importancia) de los eventos anteriores al ingresar la secuencia token por token.
«», t = 0 t – 1. «» , , . t = 0 . , .
Volviendo a los datos, imagina que tienes un conjunto de documentos, cada uno de los cuales es un ejemplo etiquetado. Y en lugar de pasar el conjunto completo de vectores de palabras a la red neuronal convolucional para cada muestra, como en el capítulo anterior (Figura 8.7), transferimos los datos de muestra al RNN, un token a la vez (Figura 8.8).

Pasamos un vector de palabras para el primer token y obtenemos la salida de nuestra red neuronal recurrente. Luego transferimos el segundo token, ¡y con él la señal de salida del primero! Después de eso, transferimos el tercer token junto con la señal de salida del segundo. Etc. Ahora bien, en nuestra red neuronal hay conceptos de "antes" y "después", causa y efecto, alguna noción, aunque vaga, de tiempo (véase la figura 8.8).
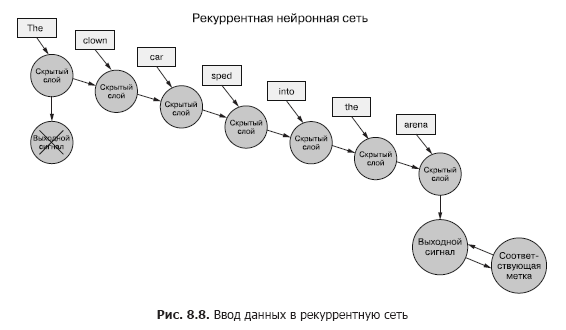
¡Ahora nuestra red ya está recordando algo! Bueno, hasta cierto punto. Todavía quedan algunas cosas por resolver. Primero, ¿cómo puede ocurrir la propagación hacia atrás de un error en tal estructura?
8.1.1. Retropropagación de un error en el tiempo
En todas las redes discutidas anteriormente, había una etiqueta de destino (variable de destino), y RNN no es una excepción. Pero no tenemos el concepto de una etiqueta para cada token, y solo hay una etiqueta para todos los tokens de cada texto de muestra. Solo tenemos etiquetas para documentos de muestra.
Estamos hablando de tokens como entrada a la red en cada paso de tiempo, pero las redes neuronales recurrentes también pueden funcionar con cualquier dato de serie temporal. Los tokens pueden ser cualquiera, discretos o continuos: lecturas de la estación meteorológica, notas, símbolos en una oración, etc.
Aquí, primero comparamos la salida de la red en el último paso de tiempo con la señal. Esto es lo que llamaremos (por ahora) un error, es decir, nuestra red está tratando de minimizarlo. Pero hay una ligera diferencia con los capítulos anteriores. Una muestra determinada de datos se divide en partes más pequeñas que se introducen en la red neuronal de forma secuencial. Sin embargo, en lugar de utilizar directamente la salida de cada uno de estos subejemplos, la enviamos de vuelta a la red.
Hasta ahora, solo nos interesa la señal de salida final. Cada uno de los tokens de la secuencia se alimenta a la red y las pérdidas se calculan en función de la salida del último paso de tiempo (token) (Figura 8.9).
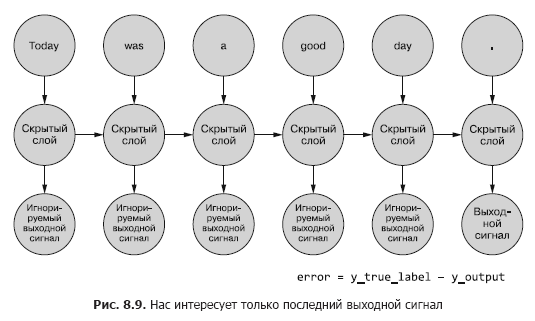
Es necesario determinar, si hay un error para un ejemplo dado, qué pesos actualizar y cuánto. En el Capítulo 5, le mostramos cómo propagar hacia atrás un error en una red normal. Y sabemos que la cantidad de corrección de peso depende de su contribución (este peso) al error. Podemos alimentar el token de la secuencia de muestra a la entrada de la red, calculando el error del paso de tiempo anterior en función de su señal de salida. Aquí es donde la idea de retropropagar un error en el tiempo parece confundirlo todo.
Sin embargo, uno puede simplemente pensar en ello como un proceso de duración determinada. En cada paso de tiempo, los tokens, comenzando desde el primero en t = 0, se alimentan uno a la vez a la entrada de la neurona oculta ubicada al frente, la siguiente columna en la Fig. 8,9. Al mismo tiempo, la red se expande, revelando la siguiente columna de la red, que ya está lista para recibir el siguiente token de la secuencia. Las neuronas latentes se despliegan una a la vez, como una caja de música o un piano mecánico. Al final, cuando todos los elementos de los ejemplos se introduzcan en la red, no habrá nada más que implementar y obtendremos la etiqueta final para la variable objetivo que nos interesa, que se puede utilizar para calcular el error y ajustar los pesos. Acabamos de recorrer todo el camino hacia abajo en el gráfico de cálculo para esta red desenrollada.
Por ahora, consideramos que los datos de entrada son generalmente estáticos. Puede rastrear a lo largo de todo el gráfico qué señal de entrada ingresa a qué neurona. Y como sabemos cómo funciona qué neurona, podemos propagar el error a lo largo de la cadena, por el mismo camino, de la misma manera que en el caso de una red neuronal de alimentación directa convencional.
Para propagar el error a la capa anterior, usaremos la regla de la cadena. En lugar de la capa anterior, propagaremos el error a la misma capa en el pasado, como si todas las variantes de red implementadas fueran diferentes (Figura 8.10). Esto no cambia las matemáticas de cálculo.

El error se propaga desde el último paso. Se calcula el gradiente de un paso de tiempo anterior con respecto a uno más nuevo. Después de calcular todos los gradientes individuales basados en tokens hasta el paso t = 0 para este ejemplo, los cambios se agregan y se aplican a un conjunto de pesos.
8.1.2. Cuándo actualizar qué
Hemos convertido nuestro extraño RNN en algo así como una red neuronal de avance regular, por lo que actualizar los pesos debería ser sencillo. Sin embargo, hay una salvedad. El truco es que los pesos no se actualizan en ninguna otra rama de la red neuronal. Cada rama representa la misma red en diferentes momentos. Los pesos para cada paso de tiempo son los mismos (consulte la Figura 8.10).
Una solución simple a este problema es calcular correcciones para los pesos en cada uno de los pasos de tiempo con un retraso en la actualización. En una red de retroalimentación, todas las actualizaciones de los pesos se calculan inmediatamente después del cálculo de todos los gradientes para una señal de entrada particular. Y aquí es exactamente lo mismo, pero las actualizaciones se aplazan hasta que lleguemos al paso de tiempo inicial (cero) para una muestra de datos de entrada específica.
El cálculo del gradiente debe basarse en los valores de los pesos a los que hicieron esta contribución al error. Aquí está la parte más abrumadora: el peso en el paso de tiempo t contribuyó de alguna manera al error. Y el mismo peso recibe otra señal de entrada en el paso de tiempo t + 1, lo que significa que hace una contribución diferente al error.
Puede calcular los diversos cambios en los pesos en cada paso de tiempo, resumirlos y luego aplicar los cambios agrupados a los pesos de la capa oculta como último paso de la fase de entrenamiento.
, . , , . , , . , .
Magia real. En el caso de la propagación hacia atrás del error en el tiempo, un peso individual se puede corregir en una dirección en un paso de tiempo t (dependiendo de su respuesta a la señal de entrada en un paso de tiempo t), y luego en la otra dirección en un paso de tiempo t - 1 (de acuerdo con cómo reaccionó a la señal de entrada en el paso de tiempo t - 1) para una muestra de datos. Recuerde que las redes neuronales en general se basan en minimizar la función de pérdida independientemente de la complejidad de los pasos intermedios. En conjunto, la red optimiza esta compleja función. Dado que la actualización del peso se aplica solo una vez para los datos de muestra, la red (si es que converge, por supuesto) finalmente se detiene en el peso más óptimo en este sentido para una señal de entrada específica y una neurona específica.
Los resultados de los pasos anteriores siguen siendo importantes
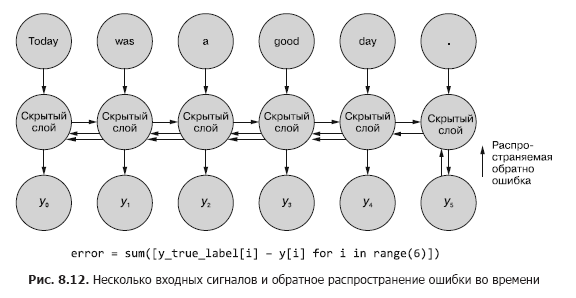
A veces, la secuencia completa de valores generados en todos los pasos de tiempo intermedios es importante. En el capítulo 9, daremos ejemplos de situaciones en las que la salida de un paso de tiempo t en particular es tan importante como la salida del último paso de tiempo. En la Fig. 8.11 muestra un método para recopilar datos de error para cualquier paso de tiempo y propagarlos para corregir todos los pesos de la red.

Este proceso se asemeja a la propagación hacia atrás habitual de un error en el tiempo durante n pasos de tiempo. En este caso, propagamos el error desde varias fuentes al mismo tiempo. Pero, como en el primer ejemplo, los ajustes a los pesos son aditivos. El error se propaga desde el último paso de tiempo al principio hasta el primero con la suma de los cambios en cada uno de los pesos. Entonces ocurre lo mismo con el error calculado en el penúltimo paso de tiempo, sumando todos los cambios hasta t = 0. Este proceso se repite hasta que llegamos al paso de tiempo cero con retropropagación del error como si fuera el único. Luego, los cambios acumulativos se aplican todos a la vez a la capa oculta correspondiente.
En la Fig. La figura 8.12 muestra cómo se propaga el error desde cada señal de salida hasta t = 0, luego se agrega antes de la corrección final de los pesos. Esta es la idea principal de esta sección. Como en el caso de una red neuronal de retroalimentación convencional, los pesos se actualizan solo después de calcular el cambio propuesto en los pesos para todo el paso de retropropagación para una señal de entrada dada (o conjunto de señales de entrada). En el caso de RNN, la retropropagación del error incluye actualizaciones hasta el tiempo t = 0.
Actualizar los pesos antes distorsionaría los cálculos de gradiente con propagación de errores hacia atrás en puntos anteriores en el tiempo. Recuerde, los gradientes se calculan en relación con un peso específico. Si este peso se actualiza demasiado pronto, digamos en el paso de tiempo t, entonces al calcular el gradiente en el paso de tiempo t - 1, el valor del peso (recuerde que esta es la misma posición del peso en la red) cambiará. Y al calcular el gradiente basado en la señal de entrada del paso de tiempo t - 1, los cálculos se distorsionarán. De hecho, en este caso, el peso será multado (o recompensado) por lo que "no tiene la culpa".
Sobre los autores
Hobson Lane(Hobson Lane) tiene 20 años de experiencia en la creación de sistemas autónomos que toman decisiones críticas en beneficio de las personas. En Talentpair, Hobson enseñó a las máquinas a leer y comprender los currículums de una manera menos sesgada que la mayoría de los gerentes de contratación. En Aira, ayudó a construir su primer chatbot diseñado para interpretar el mundo para ciegos. Hobson es un apasionado admirador de la apertura y la orientación comunitaria de la IA. Realiza contribuciones activas a proyectos de código abierto como Keras, scikit-learn, PyBrain, PUGNLP y ChatterBot. Actualmente está involucrado en proyectos educativos y de investigación abiertos para Total Good, incluida la creación de un asistente virtual de código abierto. Ha publicado numerosos artículos, ha dado conferencias en AIAA, PyCon,PAIS e IEEE y ha obtenido varias patentes en el campo de la robótica y la automatización.
Hannes Max Hapke es un ingeniero eléctrico convertido en ingeniero de aprendizaje automático. En la escuela secundaria, se interesó por las redes neuronales cuando estudió formas de calcular redes neuronales en microcontroladores. Más tarde en la universidad, aplicó los principios de las redes neuronales a la gestión eficiente de plantas de energía renovable. Hannes es un apasionado de la automatización de procesos de desarrollo de software y aprendizaje automático. Es coautor de modelos de aprendizaje profundo y procesos de aprendizaje automático para las industrias de contratación, energía y atención médica. Hannes ha realizado presentaciones sobre aprendizaje automático en una variedad de conferencias que incluyen OSCON, Open Source Bridge y Hack University.
Cole Howard(Cole Howard) es un practicante de aprendizaje automático, practicante de PNL y escritor. Un eterno buscador de patrones, se encontró en el mundo de las redes neuronales artificiales. Entre sus desarrollos se encuentran los sistemas de recomendación a gran escala para el comercio a través de Internet y las redes neuronales avanzadas para sistemas de inteligencia de máquinas de dimensiones ultraaltas (redes neuronales profundas), que ocupan los primeros lugares en las competencias de Kaggle. Ha dictado conferencias sobre redes neuronales convolucionales, redes neuronales recurrentes y su papel en el procesamiento del lenguaje natural en las conferencias Open Source Bridge y Hack University.
Acerca de la ilustración de la portada
« -, ». (Balthasar Hacquet) Images and Descriptions of Southwestern and Eastern Wends, Illyrians and Slavs (« - , »), () 2008 . (1739–1815) — , , — , - . .
200 . , , . , . , .
200 . , , . , . , .
»Más detalles sobre el libro se pueden encontrar en el sitio web de la editorial
» Tabla de contenido
» Extracto
para los habitantes un 25% de descuento en el cupón - PNL
Tras el pago de la versión impresa del libro, se envía un libro electrónico al correo electrónico.