Introducción
Este artículo describe un algoritmo de ordenación por fusión adaptativa no recursiva estable llamado quadsort.
Intercambio cuádruple
Quadsort se basa en un intercambio cuádruple. Tradicionalmente, la mayoría de los algoritmos de clasificación se basan en el intercambio binario, donde dos variables se clasifican utilizando una tercera variable temporal. Suele tener este aspecto:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}En un intercambio cuádruple, la clasificación se realiza mediante cuatro variables de sustitución (intercambio). En el primer paso, las cuatro variables se clasifican parcialmente en cuatro variables de intercambio, en el segundo paso, se clasifican completamente de nuevo en las cuatro variables originales.
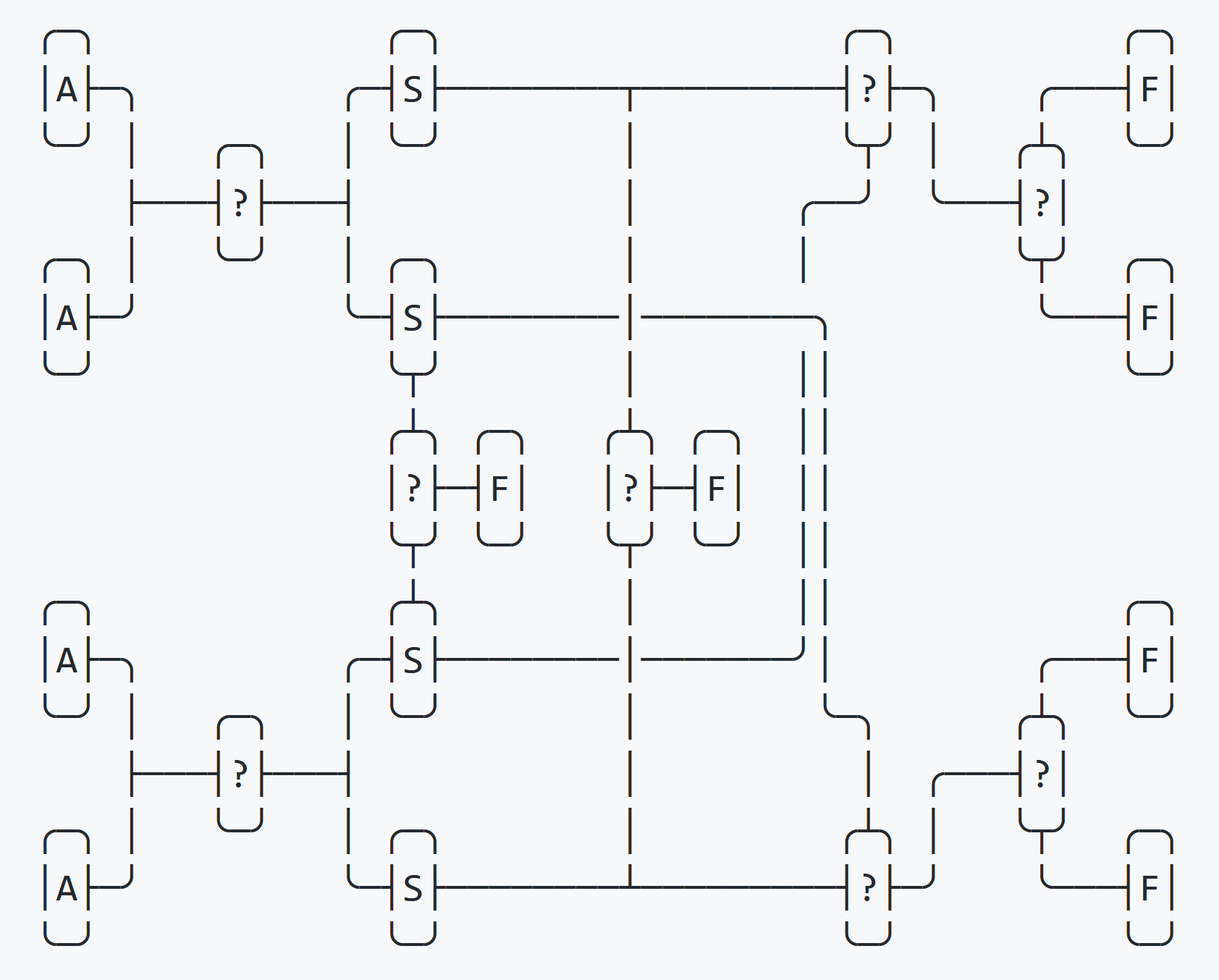
Este proceso se muestra en el diagrama anterior.
Después de la primera ronda de clasificación, una verificación determina si las cuatro variables de intercambio están clasificadas en orden. Si es así, el intercambio finaliza de inmediato. Luego verifica si las variables de intercambio están ordenadas en orden inverso. Si es así, la clasificación termina inmediatamente. Si ambas pruebas fallan, entonces se conoce la ubicación final y quedan dos pruebas para determinar el orden final.
Esto elimina una comparación redundante para las secuencias que están en orden. Al mismo tiempo, se crea una comparación adicional para secuencias aleatorias. Sin embargo, en el mundo real, rara vez comparamos datos verdaderamente aleatorios. Entonces, cuando los datos están ordenados en lugar de ser desordenados, este cambio en la probabilidad es beneficioso.
También hay una mejora general del rendimiento al eliminar el intercambio inútil. En C, un intercambio cuádruple básico se ve así:
if (val[0] > val[1])
{
tmp[0] = val[1];
tmp[1] = val[0];
}
else
{
tmp[0] = val[0];
tmp[1] = val[1];
}
if (val[2] > val[3])
{
tmp[2] = val[3];
tmp[3] = val[2];
}
else
{
tmp[2] = val[2];
tmp[3] = val[3];
}
if (tmp[1] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[1];
val[2] = tmp[2];
val[3] = tmp[3];
}
else if (tmp[0] > tmp[3])
{
val[0] = tmp[2];
val[1] = tmp[3];
val[2] = tmp[0];
val[3] = tmp[1];
}
else
{
if (tmp[0] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[2];
}
else
{
val[0] = tmp[2];
val[1] = tmp[0];
}
if (tmp[1] <= tmp[3])
{
val[2] = tmp[1];
val[3] = tmp[3];
}
else
{
val[2] = tmp[3];
val[3] = tmp[1];
}
}En caso de que la matriz no se pueda dividir perfectamente en cuatro partes, la cola de 1-3 elementos se ordena utilizando el intercambio binario tradicional.
El intercambio cuádruple descrito anteriormente se implementa en quadsort.
Fusión cuádruple
En la primera etapa, el intercambio cuádruple clasifica previamente la matriz en bloques de cuatro elementos, como se describió anteriormente.
La segunda etapa utiliza un enfoque similar para detectar órdenes ordenadas e inversas, pero en bloques de 4, 16, 64 o más elementos, esta etapa se trata como un tipo de combinación tradicional.
Esto se puede representar de la siguiente manera:
main memory: AAAA BBBB CCCC DDDD
swap memory: ABABABAB CDCDCDCD
main memory: ABCDABCDABCDABCDLa primera línea utiliza un intercambio cuádruple para crear cuatro bloques de cuatro elementos ordenados cada uno. La segunda línea utiliza una combinación cuádruple para combinar en dos bloques de ocho elementos ordenados cada uno en la memoria de intercambio. En la última línea, los bloques se fusionan nuevamente en la memoria principal, y nos queda un bloque de 16 elementos ordenados. A continuación se muestra la visualización.

Estas operaciones realmente requieren duplicar la memoria de intercambio. Más sobre esto más adelante.
Omitir
Otra diferencia es que, debido al mayor costo de las operaciones de combinación, es beneficioso verificar si cuatro bloques están en orden hacia adelante o hacia atrás.
En caso de que los cuatro bloques estén en orden, la operación de fusión se omite, ya que no tiene sentido. Sin embargo, esto requiere una verificación adicional de if, y para datos ordenados aleatoriamente, esta verificación de if se vuelve cada vez más improbable a medida que aumenta el tamaño del bloque. Afortunadamente, la frecuencia de esta verificación se cuadruplica en cada ciclo, mientras que el beneficio potencial se cuadruplica en cada ciclo.
En caso de que los cuatro bloques estén en orden inverso, se realiza un intercambio in situ estable.
En el caso de que solo dos de los cuatro bloques estén ordenados o estén en orden inverso, las comparaciones en la fusión en sí son innecesarias y posteriormente se omiten. Los datos aún deben copiarse en la memoria de intercambio, pero este es un procedimiento menos computacional.
Esto permite que el algoritmo quadsort clasifique secuencias en orden hacia adelante y hacia atrás utilizando
ncomparaciones en lugar de n * log ncomparaciones.
Verificaciones de límites
Otro problema con la ordenación por combinación tradicional es que desperdicia recursos en verificaciones de límites innecesarias. Se parece a esto:
while (a <= a_max && b <= b_max)
if (a <= b)
[insert a++]
else
[insert b++]Para la optimización, nuestro algoritmo compara el último elemento de la secuencia A con el último elemento de la secuencia B. Si el último elemento de la secuencia A es menor que el último elemento de la secuencia B, entonces sabemos que la prueba
b < b_maxsiempre será falsa, porque la secuencia A es la primera en fusionarse completamente.
Asimismo, si el último elemento de la secuencia A es mayor que el último elemento de la secuencia B, sabemos que la prueba
a < a_maxsiempre será falsa. Se parece a esto:
if (val[a_max] <= val[b_max])
while (a <= a_max)
{
while (a > b)
[insert b++]
[insert a++]
}
else
while (b <= b_max)
{
while (a <= b)
[insert a++]
[insert b++]
}Cola de fusión
Cuando ordena una matriz de 65 elementos, termina con una matriz ordenada de 64 elementos y una matriz ordenada de un elemento al final. Esto no resultará en una operación de intercambio adicional si toda la secuencia está en orden. En cualquier caso, para ello, el programa debe elegir el tamaño de matriz óptimo (64, 256 o 1024).
Otro problema es que el tamaño subóptimo de la matriz conduce a operaciones de intercambio innecesarias. Para solucionar estos dos problemas, el procedimiento de combinación cuádruple se cancela cuando el tamaño del bloque alcanza 1/8 del tamaño de la matriz y el resto de la matriz se ordena utilizando la combinación de cola. La principal ventaja de la fusión de la cola es que puede reducir el volumen de intercambio de quadsort a n / 2 sin afectar significativamente el rendimiento.
O grande
| Nombre | Mejor | Medio | Peor | Estable | Memoria |
|---|---|---|---|---|---|
| quadsort | norte | n log n | n log n | si | norte |
Cuando los datos ya están ordenados o ordenados en orden inverso, quadsort hace n comparaciones.
Cache
Dado que quadsort utiliza n / 2 intercambios, el uso de la caché no es tan ideal como la ordenación local. Sin embargo, ordenar los datos aleatorios en el lugar da como resultado intercambios subóptimos. Según mis puntos de referencia, quadsort siempre es más rápido que la ordenación en el lugar, siempre que la matriz no desborde la caché L1, que puede llegar a 64 KB en los procesadores modernos.
Wolfsort
Wolfsort es un algoritmo de clasificación híbrido radixsort / quadsort que mejora el rendimiento cuando se trabaja con datos aleatorios. Esto es básicamente una prueba de concepto que solo funciona con enteros sin signo de 32 y 64 bits.
Visualización
La visualización a continuación ejecuta cuatro pruebas. La primera prueba se basa en una distribución aleatoria, la segunda en una distribución ascendente, la tercera en una distribución descendente y la cuarta en una distribución ascendente con una cola aleatoria.
La mitad superior muestra el intercambio y la mitad inferior muestra la memoria principal. Los colores varían para las operaciones de salto, intercambio, combinación y copia.
Benchmark: quadsort, std :: stable_sort, timsort, pdqsort y wolfsort
El siguiente punto de referencia se ejecutó en la configuración de WSL gcc versión 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). El código fuente es compilado por el equipo
g++ -O3 quadsort.cpp. Cada prueba se ejecuta cien veces y solo se informa la mejor ejecución.
La abscisa es el tiempo de ejecución.
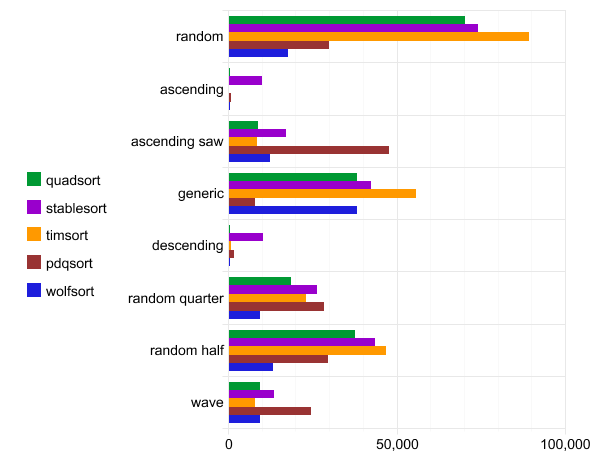
Hoja de datos de Quadsort, std :: stable_sort, timsort, pdqsort y wolfsort
| quadsort | 1000000 | i32 | 0.070469 | 0.070635 | ||
| stablesort | 1000000 | i32 | 0.073865 | 0.074078 | ||
| timsort | 1000000 | i32 | 0.089192 | 0.089301 | ||
| pdqsort | 1000000 | i32 | 0.029911 | 0.029948 | ||
| wolfsort | 1000000 | i32 | 0.017359 | 0.017744 | ||
| quadsort | 1000000 | i32 | 0.000485 | 0.000511 | ||
| stablesort | 1000000 | i32 | 0.010188 | 0.010261 | ||
| timsort | 1000000 | i32 | 0.000331 | 0.000342 | ||
| pdqsort | 1000000 | i32 | 0.000863 | 0.000875 | ||
| wolfsort | 1000000 | i32 | 0.000539 | 0.000579 | ||
| quadsort | 1000000 | i32 | 0.008901 | 0.008934 | () | |
| stablesort | 1000000 | i32 | 0.017093 | 0.017275 | () | |
| timsort | 1000000 | i32 | 0.008615 | 0.008674 | () | |
| pdqsort | 1000000 | i32 | 0.047785 | 0.047921 | () | |
| wolfsort | 1000000 | i32 | 0.012490 | 0.012554 | () | |
| quadsort | 1000000 | i32 | 0.038260 | 0.038343 | ||
| stablesort | 1000000 | i32 | 0.042292 | 0.042388 | ||
| timsort | 1000000 | i32 | 0.055855 | 0.055967 | ||
| pdqsort | 1000000 | i32 | 0.008093 | 0.008168 | ||
| wolfsort | 1000000 | i32 | 0.038320 | 0.038417 | ||
| quadsort | 1000000 | i32 | 0.000559 | 0.000576 | ||
| stablesort | 1000000 | i32 | 0.010343 | 0.010438 | ||
| timsort | 1000000 | i32 | 0.000891 | 0.000900 | ||
| pdqsort | 1000000 | i32 | 0.001882 | 0.001897 | ||
| wolfsort | 1000000 | i32 | 0.000604 | 0.000625 | ||
| quadsort | 1000000 | i32 | 0.006174 | 0.006245 | ||
| stablesort | 1000000 | i32 | 0.014679 | 0.014767 | ||
| timsort | 1000000 | i32 | 0.006419 | 0.006468 | ||
| pdqsort | 1000000 | i32 | 0.016603 | 0.016629 | ||
| wolfsort | 1000000 | i32 | 0.006264 | 0.006329 | ||
| quadsort | 1000000 | i32 | 0.018675 | 0.018729 | ||
| stablesort | 1000000 | i32 | 0.026384 | 0.026508 | ||
| timsort | 1000000 | i32 | 0.023226 | 0.023395 | ||
| pdqsort | 1000000 | i32 | 0.028599 | 0.028674 | ||
| wolfsort | 1000000 | i32 | 0.009517 | 0.009631 | ||
| quadsort | 1000000 | i32 | 0.037593 | 0.037679 | ||
| stablesort | 1000000 | i32 | 0.043755 | 0.043899 | ||
| timsort | 1000000 | i32 | 0.047008 | 0.047112 | ||
| pdqsort | 1000000 | i32 | 0.029800 | 0.029847 | ||
| wolfsort | 1000000 | i32 | 0.013238 | 0.013355 | ||
| quadsort | 1000000 | i32 | 0.009605 | 0.009673 | ||
| stablesort | 1000000 | i32 | 0.013667 | 0.013785 | ||
| timsort | 1000000 | i32 | 0.007994 | 0.008138 | ||
| pdqsort | 1000000 | i32 | 0.024683 | 0.024727 | ||
| wolfsort | 1000000 | i32 | 0.009642 | 0.009709 |
Cabe señalar que pdqsort no es una ordenación estable, por lo que funciona más rápido con datos en orden normal (orden general).
El siguiente punto de referencia se ejecutó en WSL gcc versión 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). El código fuente es compilado por el equipo
g++ -O3 quadsort.cpp. Cada prueba se ejecuta cien veces y solo se informa la mejor ejecución. Mide el rendimiento en matrices que van desde 675 hasta 100.000 elementos.
El eje X del gráfico a continuación es la cardinalidad, el eje Y es el tiempo de ejecución.

Hoja de datos de Quadsort, std :: stable_sort, timsort, pdqsort y wolfsort
| quadsort | 100000 | i32 | 0.005800 | 0.005835 | ||
| stablesort | 100000 | i32 | 0.006092 | 0.006122 | ||
| timsort | 100000 | i32 | 0.007605 | 0.007656 | ||
| pdqsort | 100000 | i32 | 0.002648 | 0.002670 | ||
| wolfsort | 100000 | i32 | 0.001148 | 0.001168 | ||
| quadsort | 10000 | i32 | 0.004568 | 0.004593 | ||
| stablesort | 10000 | i32 | 0.004813 | 0.004923 | ||
| timsort | 10000 | i32 | 0.006326 | 0.006376 | ||
| pdqsort | 10000 | i32 | 0.002345 | 0.002373 | ||
| wolfsort | 10000 | i32 | 0.001256 | 0.001274 | ||
| quadsort | 5000 | i32 | 0.004076 | 0.004086 | ||
| stablesort | 5000 | i32 | 0.004394 | 0.004420 | ||
| timsort | 5000 | i32 | 0.005901 | 0.005938 | ||
| pdqsort | 5000 | i32 | 0.002093 | 0.002107 | ||
| wolfsort | 5000 | i32 | 0.000968 | 0.001086 | ||
| quadsort | 2500 | i32 | 0.003196 | 0.003303 | ||
| stablesort | 2500 | i32 | 0.003801 | 0.003942 | ||
| timsort | 2500 | i32 | 0.005296 | 0.005322 | ||
| pdqsort | 2500 | i32 | 0.001606 | 0.001661 | ||
| wolfsort | 2500 | i32 | 0.000509 | 0.000520 | ||
| quadsort | 1250 | i32 | 0.001767 | 0.001823 | ||
| stablesort | 1250 | i32 | 0.002812 | 0.002887 | ||
| timsort | 1250 | i32 | 0.003789 | 0.003865 | ||
| pdqsort | 1250 | i32 | 0.001036 | 0.001325 | ||
| wolfsort | 1250 | i32 | 0.000534 | 0.000655 | ||
| quadsort | 675 | i32 | 0.000368 | 0.000592 | ||
| stablesort | 675 | i32 | 0.000974 | 0.001160 | ||
| timsort | 675 | i32 | 0.000896 | 0.000948 | ||
| pdqsort | 675 | i32 | 0.000489 | 0.000531 | ||
| wolfsort | 675 | i32 | 0.000283 | 0.000308 |
Benchmark: quadsort y qsort (mergesort)
El siguiente punto de referencia se ejecutó en WSL gcc versión 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). El código fuente es compilado por el equipo
g++ -O3 quadsort.cpp. Cada prueba se ejecuta cien veces y solo se informa la mejor ejecución.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)MO indica el número de comparaciones realizadas en 1 millón de elementos.
El punto de referencia anterior compara quadsort con glibc qsort () a través de la misma interfaz de propósito general y sin ninguna ventaja injusta conocida como la inserción.
random order: 635, 202, 47, 229, etc
ascending order: 1, 2, 3, 4, etc
uniform order: 1, 1, 1, 1, etc
descending order: 999, 998, 997, 996, etc
wave order: 100, 1, 102, 2, 103, 3, etc
stable/unstable: 100, 1, 102, 1, 103, 1, etc
random range: time to sort 1000 arrays ranging from size 0 to 999 containing random dataBenchmark: quadsort y qsort (quicksort)
Esta prueba en particular se realiza usando la implementación qsort () de Cygwin, que usa quicksort bajo el capó. El código fuente es compilado por el equipo
gcc -O3 quadsort.c. Cada prueba se ejecuta cien veces, solo se informa la mejor ejecución.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)En este punto de referencia, queda claro por qué la ordenación rápida a menudo es preferible a la combinación tradicional, hace menos comparaciones para los datos en orden ascendente, distribuidos uniformemente y para los datos en orden descendente. Sin embargo, en la mayoría de las pruebas funcionó peor que el quadsort. Quicksort también exhibe una velocidad de clasificación extremadamente lenta para datos ordenados por ondas. La prueba de datos aleatorios muestra que quadsort es más del doble de rápido al ordenar arreglos pequeños.
Quicksort es más rápido en pruebas estables y de propósito general, pero solo porque es un algoritmo inestable.
Ver también: