Recordemos el plan por el que nos movemos:
1 parte . Decidimos la tarea técnica y la arquitectura de la solución, escribimos una aplicación en golang.
Parte 2 (estás aquí ahora). Lanzamos nuestra aplicación a producción, la hacemos escalable y probamos la carga.
Parte 3. Tratemos de averiguar por qué necesitamos almacenar mensajes en un búfer y no en archivos, y también comparemos los servicios de cola kafka, rabbitmq y yandex entre ellos.
Parte 4. Implementaremos el clúster de Clickhouse, escribiremos la transmisión para transferir datos desde el búfer allí, configuraremos la visualización en lentes de datos.
Parte 5.Pongamos toda la infraestructura en la forma adecuada: configure ci / cd usando gitlab ci, conecte el monitoreo y el descubrimiento de servicios usando consul y prometheus.

Bueno, pasemos a nuestras tareas.
Vertimos en producción
En la parte 1, ensamblamos la aplicación, la probamos y también cargamos la imagen en el registro de contenedor privado, lista para su implementación.
En general, los siguientes pasos deberían ser casi obvios: creamos máquinas virtuales, configuramos un equilibrador de carga y escribimos un nombre DNS con proxy a cloudflare. Pero me temo que esta opción no se ajusta mucho a nuestros términos de referencia. Queremos poder escalar nuestro servicio en caso de un aumento en la carga y eliminar los nodos rotos que no pueden atender las solicitudes.
Para escalar, usaremos los grupos de instancias disponibles en la nube informática. Le permiten crear máquinas virtuales a partir de una plantilla, monitorear su disponibilidad mediante verificaciones de estado y también aumentar automáticamente la cantidad de nodos en caso de un aumento en la carga.Más detalles aquí .
Solo hay una pregunta: ¿qué plantilla usar para la máquina virtual? Por supuesto, puede instalar Linux, configurarlo, crear una imagen y cargarla en el almacenamiento de imágenes en Yandex.Cloud. Pero para nosotros es un viaje largo y difícil. Al revisar las diversas imágenes disponibles al crear una máquina virtual, nos encontramos con una instancia interesante: una imagen optimizada para contenedores ( https://cloud.yandex.ru/docs/cos/concepts/ ). Le permite ejecutar un único contenedor de Docker en modo de red. Es decir, al crear una máquina virtual, se indica aproximadamente la siguiente especificación para una imagen optimizada de contenedor:
spec:
containers:
- name: api
image: vozerov/events-api:v1
command:
- /app/app
args:
- -kafka=kafka.ru-central1.internal:9092
securityContext:
privileged: false
tty: false
stdin: false
restartPolicy: AlwaysY después del inicio de la máquina virtual, este contenedor se descargará y ejecutará localmente.
El esquema es bastante interesante:
- Creamos un grupo de instancias con escalado automático cuando se excede el 60% de uso de la CPU.
- Como plantilla, especificamos una máquina virtual con una imagen optimizada de contenedor y parámetros para ejecutar nuestro contenedor Docker.
- Creamos un balanceador de carga, que verá nuestro grupo de instancias y se actualizará automáticamente al agregar o eliminar máquinas virtuales.
- La aplicación será monitoreada como un grupo de instancias y por el balanceador mismo, lo que desequilibrará las máquinas virtuales inaccesibles.
¡Suena como un plan!
Intentemos crear un grupo de instancias usando terraform. La descripción completa se encuentra en instance-group.tf, comentaré los puntos principales:
- La identificación de la cuenta de servicio se utilizará para crear y eliminar máquinas virtuales. Por cierto, tendremos que crearlo.
service_account_id = yandex_iam_service_account.instances.id - spec.yml, , . registry , - — docker hub. , —
metadata = { docker-container-declaration = file("spec.yml") ssh-keys = "ubuntu:${file("~/.ssh/id_rsa.pub")}" } - service account id, container optimized image, container registry . registry , :
service_account_id = yandex_iam_service_account.docker.id - Scale policy. :
autoscale { initialsize = 3 measurementduration = 60 cpuutilizationtarget = 60 minzonesize = 1 maxsize = 6 warmupduration = 60 stabilizationduration = 180 }
. — fixed_scale , auth_scale.
:
initial size — ;
measurement_duration — ;
cpu_utilization_target — , ;
min_zone_size — — , ;
max_size — ;
warmup_duration — , , ;
stabilization_duration — — , .
. 3 (initial_size), (min_zone_size). cpu (measurement_duration). 60% (cpu_utilization_target), , (max_size). 60 (warmup_duration), cpu. 120 (stabilization_duration), 60% (cpu_utilization_target).
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#auto-scale-policy - Allocation policy. , , — .
allocationpolicy { zones = ["ru-central1-a", "ru-central1-b", "ru-central1-c"] } - :
deploy_policy { maxunavailable = 1 maxcreating = 1 maxexpansion = 1 maxdeleting = 1 }
max_creating — ;
max_deleting — ;
max_expansion — ;
max_unavailable — RUNNING, ;
— https://cloud.yandex.ru/docs/compute/concepts/instance-groups/policies#deploy-policy - :
load_balancer { target_group_name = "events-api-tg" }
Al crear un grupo de instancias, también puede crear un grupo de destino para el balanceador de carga. Apuntará a las máquinas virtuales asociadas. Si se eliminan, los nodos se eliminarán del equilibrio y, una vez creados, se agregarán al equilibrio después de pasar las comprobaciones estatales.
Parece que todo es básico: creemos una cuenta de servicio para el grupo de instancias y, de hecho, el grupo en sí.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_iam_service_account.instances -target yandex_resourcemanager_folder_iam_binding.editor
... skipped ...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_compute_instance_group.events_api_ig
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Se ha creado el grupo; puede ver y comprobar:
vozerov@mba:~/events/terraform (master *) $ yc compute instance-group list
+----------------------+---------------+------+
| ID | NAME | SIZE |
+----------------------+---------------+------+
| cl1s2tu8siei464pv1pn | events-api-ig | 3 |
+----------------------+---------------+------+
vozerov@mba:~/events/terraform (master *) $ yc compute instance list
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
| ef3huodj8g4gc6afl0jg | cl1s2tu8siei464pv1pn-ocih | ru-central1-c | RUNNING | 130.193.44.106 | 172.16.3.3 |
| epdli4s24on2ceel46sr | cl1s2tu8siei464pv1pn-ipym | ru-central1-b | RUNNING | 84.201.164.196 | 172.16.2.31 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmh4la5dj0m82ihoskd | cl1s2tu8siei464pv1pn-ahuj | ru-central1-a | RUNNING | 130.193.37.94 | 172.16.1.37 |
| fhmr401mknb8omfnlrc0 | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.14 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+---------------------------+---------------+---------+----------------+-------------+
vozerov@mba:~/events/terraform (master *) $Tres nodos con nombres torcidos son nuestro grupo. Comprobamos que las aplicaciones estén disponibles para ellos:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.44.106:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:04 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://84.201.164.196:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:09 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $ curl -D - -s http://130.193.37.94:8080/status
HTTP/1.1 200 OK
Date: Mon, 13 Apr 2020 16:32:15 GMT
Content-Length: 3
Content-Type: text/plain; charset=utf-8
ok
vozerov@mba:~/events/terraform (master *) $Por cierto, puede ir a las máquinas virtuales con el inicio de sesión de ubuntu y ver los registros del contenedor y cómo se inicia.
También se ha creado un grupo objetivo para el balanceador al que se pueden enviar solicitudes:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer target-group list
+----------------------+---------------+---------------------+-------------+--------------+
| ID | NAME | CREATED | REGION ID | TARGET COUNT |
+----------------------+---------------+---------------------+-------------+--------------+
| b7rhh6d4assoqrvqfr9g | events-api-tg | 2020-04-13 16:23:53 | ru-central1 | 3 |
+----------------------+---------------+---------------------+-------------+--------------+
vozerov@mba:~/events/terraform (master *) $¡Creemos ya un balanceador e intentemos enviarle tráfico! Este proceso se describe en load-balancer.tf, puntos clave:
- Indicamos qué puerto externo escuchará el balanceador y qué puerto enviar una solicitud a las máquinas virtuales. Indicamos el tipo de dirección externa - ip v4. Por el momento, el balanceador de carga opera a nivel de transporte, por lo que solo puede balancear conexiones tcp / udp. Por lo tanto, tendrá que atornillar ssl en sus máquinas virtuales o en un servicio externo que pueda manejar https, por ejemplo, cloudflare.
listener { name = "events-api-listener" port = 80 target_port = 8080 external_address_spec { ipversion = "ipv4" } } healthcheck { name = "http" http_options { port = 8080 path = "/status" } }
Chequeos de salud. Aquí especificamos los parámetros para verificar nuestros nodos - verificamos mediante http url / status en el puerto 8080. Si la verificación falla, la máquina se desequilibrará.
Más información sobre el equilibrador de carga: cloud.yandex.ru/docs/load-balancer/concepts . Curiosamente, puede conectar el servicio de protección DDOS en el equilibrador. Entonces el tráfico ya limpio llegará a sus servidores.
Nosotros creamos:
vozerov@mba:~/events/terraform (master *) $ terraform apply -target yandex_lb_network_load_balancer.events_api_lb
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Sacamos la ip del balanceador creado y probamos el trabajo:
vozerov@mba:~/events/terraform (master *) $ yc load-balancer network-load-balancer get events-api-lb
id:
folder_id:
created_at: "2020-04-13T16:34:28Z"
name: events-api-lb
region_id: ru-central1
status: ACTIVE
type: EXTERNAL
listeners:
- name: events-api-listener
address: 130.193.37.103
port: "80"
protocol: TCP
target_port: "8080"
attached_target_groups:
- target_group_id:
health_checks:
- name: http
interval: 2s
timeout: 1s
unhealthy_threshold: "2"
healthy_threshold: "2"
http_options:
port: "8080"
path: /statusAhora podemos dejar mensajes en él:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:57 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":1}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:42:58 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":2}
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://130.193.37.103/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 16:43:00 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":3}
vozerov@mba:~/events/terraform (master *) $Genial, todo funciona. Solo queda un toque final para que podamos ser accesibles a través de https: habilitaremos cloudflare con proxy. Si decide prescindir de Cloudflare, puede omitir este paso.
vozerov@mba:~/events/terraform (master *) $ terraform apply -target cloudflare_record.events
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Prueba sobre HTTPS:
vozerov@mba:~/events/terraform (master *) $ curl -D - -s -X POST -d '{"key1":"data1"}' https://events.kis.im/post
HTTP/2 200
date: Mon, 13 Apr 2020 16:45:01 GMT
content-type: application/json
content-length: 41
set-cookie: __cfduid=d7583eb5f791cd3c1bdd7ce2940c8a7981586796301; expires=Wed, 13-May-20 16:45:01 GMT; path=/; domain=.kis.im; HttpOnly; SameSite=Lax
cf-cache-status: DYNAMIC
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5836a7b1bb037b2b-DME
{"status":"ok","partition":0,"Offset":5}
vozerov@mba:~/events/terraform (master *) $Todo finalmente está funcionando.
Probando la carga
Nos queda quizás el paso más interesante: realizar pruebas de carga de nuestro servicio y obtener algunos números, por ejemplo, el percentil 95 del tiempo de procesamiento de una solicitud. También sería bueno probar el ajuste de escala automático de nuestro grupo de nodos.
Antes de comenzar a probar, vale la pena hacer una cosa simple: agregue nuestros nodos de aplicación a prometheus para realizar un seguimiento del número de solicitudes y el tiempo de procesamiento de una solicitud. Dado que aún no hemos agregado ningún descubrimiento de servicios (lo haremos en el artículo 5 de esta serie), simplemente escribiremos static_configs en nuestro servidor de monitoreo. Puede averiguar su IP de la forma estándar a través de la lista de instancias de cálculo yc, y luego agregar la siguiente configuración a /etc/prometheus/prometheus.yml:
- job_name: api
metrics_path: /metrics
static_configs:
- targets:
- 172.16.3.3:8080
- 172.16.2.31:8080
- 172.16.1.37:8080Las direcciones IP de nuestras máquinas también se pueden tomar de la lista de instancias de cómputo yc. Reinicie prometheus a través de systemctl reinicie prometheus y verifique que los nodos se estén sondeando correctamente yendo a la interfaz web disponible en el puerto 9090 (84.201.159.71:9090).
Agreguemos un tablero a grafana desde la carpeta grafana. Vamos a Grafana en el puerto 3000 (84.201.159.71:3000) y con un login / contraseña - admin / Password. A continuación, agregue un prometheus local e importe el tablero. En realidad, en este punto, la preparación está completa; puede enviar solicitudes a nuestra instalación.
Para las pruebas, usaremos el tanque yandex ( https://yandex.ru/dev/tank/ ) con un complemento para overload.yandex.netlo que nos permitirá visualizar los datos recibidos por el tanque. Todo lo que necesita para trabajar está en la carpeta de carga del repositorio de git original.
Un poco sobre lo que hay ahí:
- token.txt, un archivo con una clave API de overload.yandex.net, puede obtenerlo registrándose en el servicio.
- load.yml: un archivo de configuración para el tanque, hay un dominio para probar: events.kis.im, tipo de carga rps y el número de solicitudes 15,000 por segundo durante 3 minutos.
- datos: un archivo especial para generar una configuración en formato ammo.txt. En él escribimos el tipo de solicitud, url, grupo para mostrar estadísticas y los datos reales que se deben enviar.
- makeammo.py: secuencia de comandos para generar el archivo ammo.txt a partir del archivo de datos. Más sobre el script: yandextank.readthedocs.io/en/latest/ammo_generators.html
- ammo.txt: el archivo de munición resultante que se utilizará para enviar solicitudes.
Para las pruebas, tomé una máquina virtual fuera de Yandex.Cloud (para mantener todo honesto) y creé un registro DNS para load.kis.im. Rodé docker allí, ya que iniciaremos el tanque usando la imagen https://hub.docker.com/r/direvius/yandex-tank/ .
Bueno, empecemos. Copie nuestra carpeta al servidor, agregue un token e inicie el tanque:
vozerov@mba:~/events (master *) $ rsync -av load/ cloud-user@load.kis.im:load/
... skipped ...
sent 2195 bytes received 136 bytes 1554.00 bytes/sec
total size is 1810 speedup is 0.78
vozerov@mba:~/events (master *) $ ssh load.kis.im -l cloud-user
cloud-user@load:~$ cd load/
cloud-user@load:~/load$ echo "TOKEN" > token.txt
cloud-user@load:~/load$ sudo docker run -v $(pwd):/var/loadtest --net host --rm -it direvius/yandex-tank -c load.yaml ammo.txt
No handlers could be found for logger "netort.resource"
17:25:25 [INFO] New test id 2020-04-13_17-25-25.355490
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a266850> added
17:25:25 [INFO] Logging handler <logging.StreamHandler object at 0x7f209a20aa50> added
17:25:25 [INFO] Created a folder for the test. /var/loadtest/logs/2020-04-13_17-25-25.355490
17:25:25 [INFO] Configuring plugins...
17:25:25 [INFO] Loading plugins...
17:25:25 [INFO] Testing connection to resolved address 104.27.164.45 and port 80
17:25:25 [INFO] Resolved events.kis.im into 104.27.164.45:80
17:25:25 [INFO] Configuring StepperWrapper...
17:25:25 [INFO] Making stpd-file: /var/loadtest/ammo.stpd
17:25:25 [INFO] Default ammo type ('phantom') used, use 'phantom.ammo_type' option to override it
... skipped ...Eso es todo, el proceso se está ejecutando. En la consola se ve algo así:

Y estamos esperando la finalización del proceso y viendo el tiempo de respuesta, el número de solicitudes y, por supuesto, el escalado automático de nuestro grupo de máquinas virtuales. Puede monitorear un grupo de máquinas virtuales a través de la interfaz web, en la configuración de un grupo de máquinas virtuales hay una pestaña "Monitoreo".
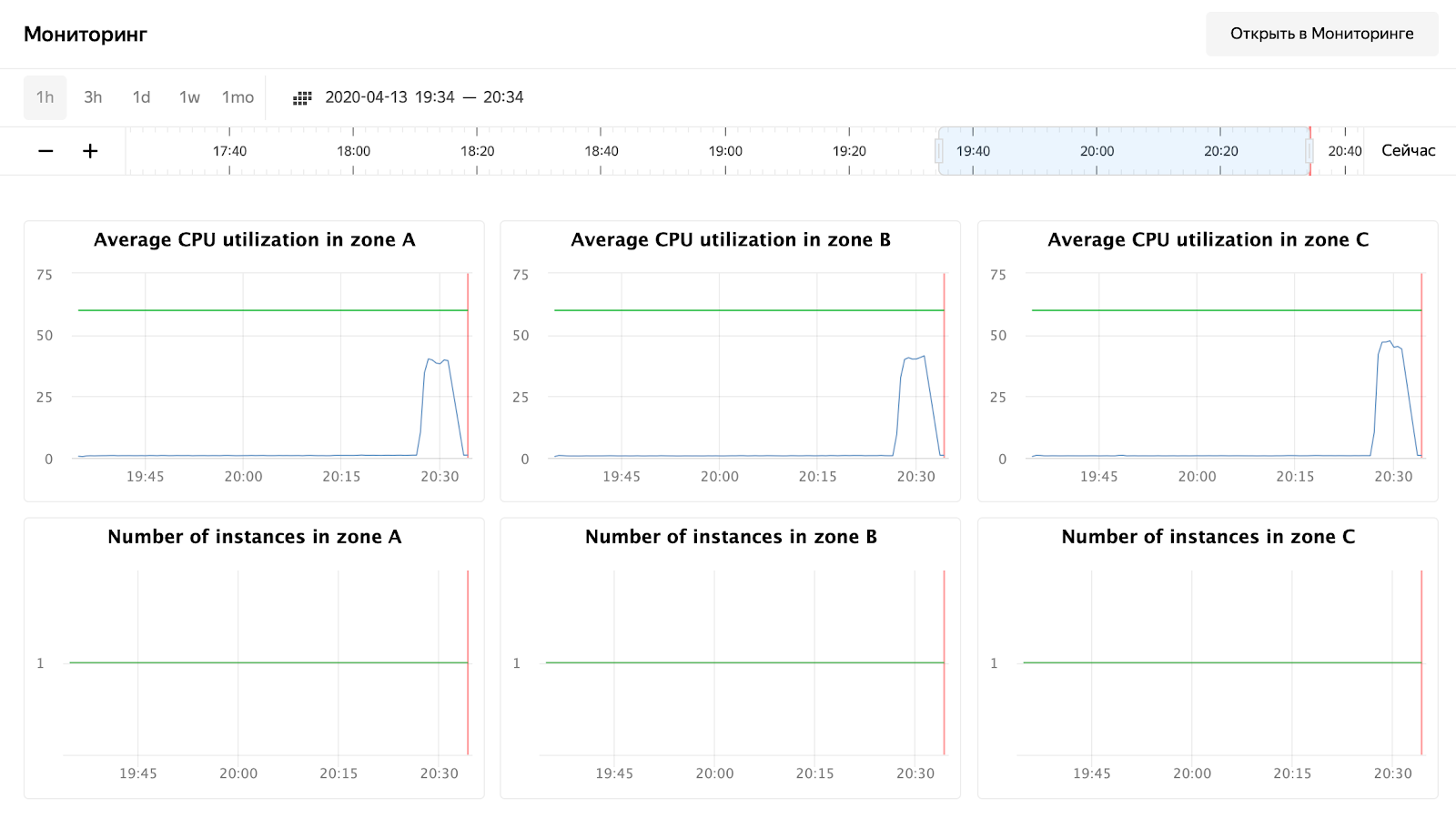
Como puede ver, nuestros nodos no cargaron ni siquiera el 50% de la CPU, por lo que habrá que repetir la prueba de autoescalado. Por ahora, echemos un vistazo al tiempo de procesamiento de la solicitud en Grafana:
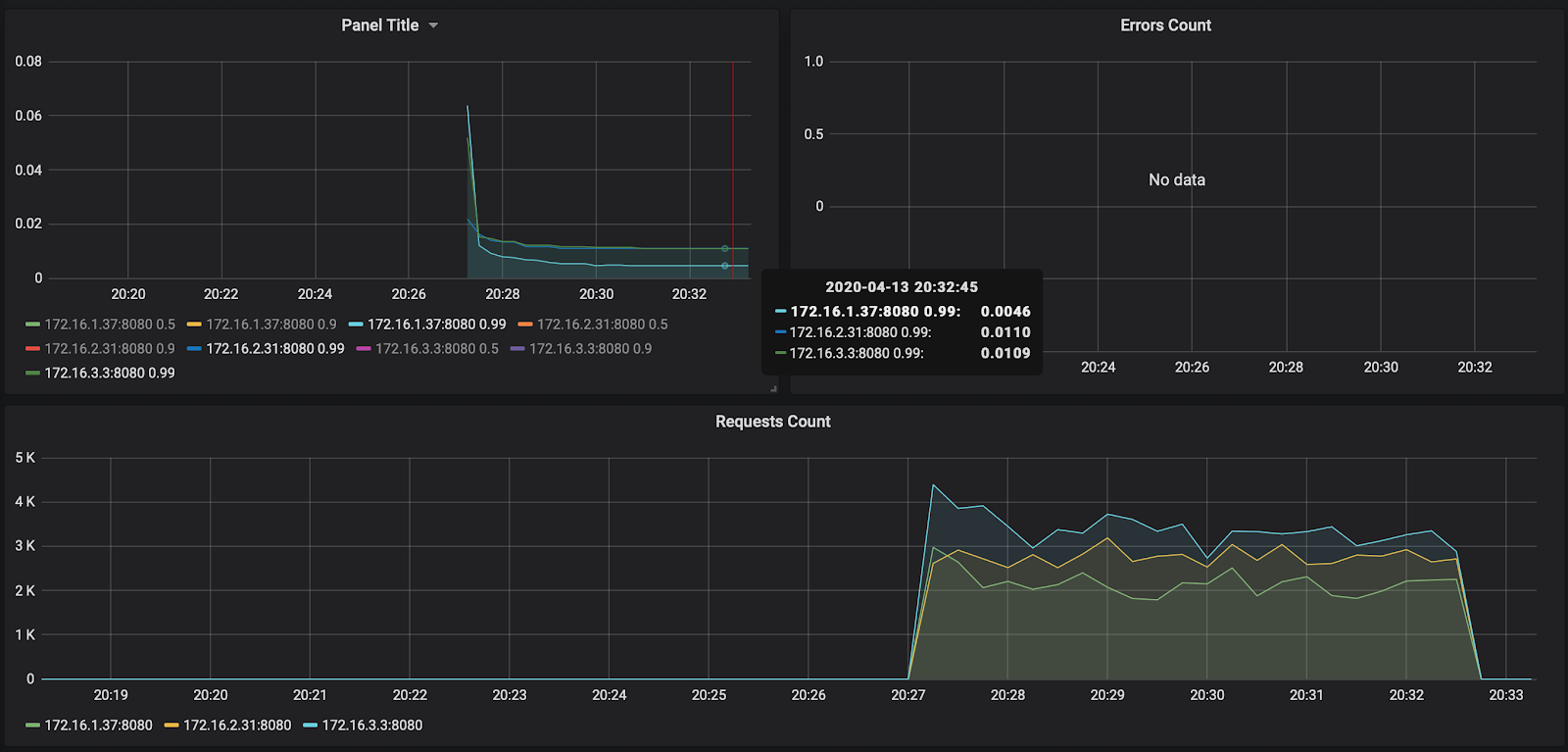
La cantidad de solicitudes, alrededor de 3000 por nodo, no se cargó un poco a 10,000. El tiempo de respuesta es agradable: aproximadamente 11 ms por solicitud. El único que se destaca, 172.16.1.37, tiene la mitad del tiempo para procesar una solicitud. Pero esto también es lógico: está en la misma zona de disponibilidad ru-central1-a que kafka, que almacena mensajes.
Por cierto, el informe sobre el primer lanzamiento está disponible en el enlace: https://overload.yandex.net/265967 .
Entonces, ejecutemos una prueba más divertida: agregue el parámetro instance: 2000 para obtener 15,000 solicitudes por segundo y aumente el tiempo de prueba a 10 minutos. El archivo resultante se verá así:
overload:
enabled: true
package: yandextank.plugins.DataUploader
token_file: "token.txt"
phantom:
address: 130.193.37.103
load_profile:
load_type: rps
schedule: const(15000, 10m)
instances: 2000
console:
enabled: true
telegraf:
enabled: falseEl lector atento notará que cambié la dirección a la IP del balanceador; esto se debe al hecho de que Cloudflare comenzó a bloquearme para una gran cantidad de solicitudes de una IP. Tuve que colocar el tanque directamente en el equilibrador Yandex.Cloud. Después del lanzamiento, puede observar la siguiente imagen:
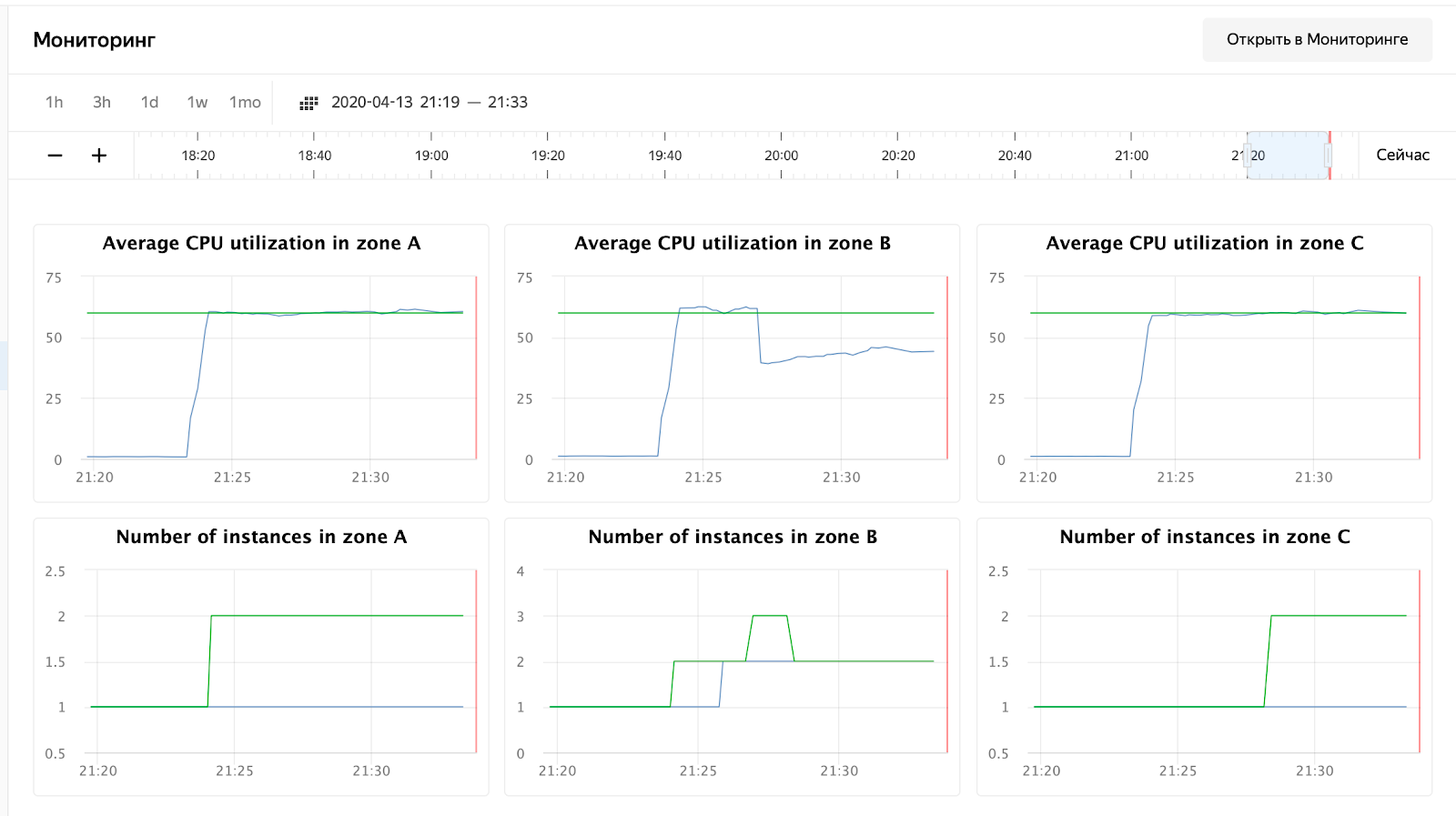
el uso de la CPU ha crecido y el programador decidió aumentar la cantidad de nodos en la zona B, lo cual hizo. Esto se puede ver en los registros del grupo de instancias:
vozerov@mba:~/events/load (master *) $ yc compute instance-group list-logs events-api-ig
2020-04-13 18:26:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 1m AWAITING_WARMUP_DURATION -> RUNNING_ACTUAL
2020-04-13 18:25:47 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 37s OPENING_TRAFFIC -> AWAITING_WARMUP_DURATION
2020-04-13 18:25:09 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 43s CREATING_INSTANCE -> OPENING_TRAFFIC
2020-04-13 18:24:26 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 6s DELETED -> CREATING_INSTANCE
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ozix.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:19 cl1s2tu8siei464pv1pn-ejok.ru-central1.internal 0s PREPARING_RESOURCES -> DELETED
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-a: 1 -> 2
2020-04-13 18:24:15 Target allocation changed in accordance with auto scale policy in zone ru-central1-b: 1 -> 2
... skipped ...
2020-04-13 16:23:57 Balancer target group b7rhh6d4assoqrvqfr9g created
2020-04-13 16:23:43 Going to create balancer target group
El planificador también decidió aumentar el número de servidores en otras zonas, pero me quedé sin el límite de direcciones IP externas :) Por cierto, se pueden aumentar mediante una solicitud al soporte técnico, especificando cuotas y valores deseados.
Conclusión
El artículo no fue fácil, tanto en volumen como en cantidad de información. Pero pasamos por la etapa más difícil e hicimos lo siguiente:
- Monitoreo elevado y kafka.
- , .
- load balancer’ cloudflare ssl .
La próxima vez, comparemos y probemos el servicio de cola rabbitmq / kafka / yandex.
¡Manténganse al tanto!
* Este material está en la grabación de video del taller abierto REBRAIN & Yandex.Cloud: Aceptamos 10,000 solicitudes por segundo en Yandex Cloud - https://youtu.be/cZLezUm0ekE
Si está interesado en asistir a tales eventos en línea y hacer preguntas en tiempo real, conéctese a canal DevOps por REBRAIN .
Nos gustaría agradecer especialmente a Yandex.Cloud por la oportunidad de realizar un evento de este tipo. Enlace a ellos
Si necesita un cambio a la nube o tiene preguntas sobre su infraestructura, no dude en dejar una solicitud .
PD: Tenemos 2 auditorías gratuitas al mes, quizás su proyecto esté entre ellas.