En mi charla en Ya.Subbotnik Pro, recordé qué y cómo terminamos en el montaje y la arquitectura del "proyecto moderno estándar" y qué resultados obtuvimos.
- Desde hace año y medio trabajo en el equipo de arquitectura de Serp. Allí desarrollamos runtime y ensamblaje de nuevo código en React y TypeScript.
Hablemos de nuestro dolor común que abordará esta charla. Cuando desee hacer un pequeño proyecto en React, solo necesita usar un conjunto estándar de herramientas llamado tres letras: CRA. Esto incluye scripts de compilación, scripts para ejecutar pruebas, configurar un entorno de desarrollo y todo ya se ha hecho para la producción. Todo se hace de manera muy simple a través de scripts de NPM, y probablemente todos los que tienen experiencia con React lo saben.
Pero supongamos que el proyecto se vuelve grande, tiene mucho código, muchos desarrolladores, aparecen características de producción, como traducciones, de las que Create React App no sabe nada. O tiene algún tipo de canalización CI / CD compleja. Luego, los pensamientos comienzan a hacer una expulsión para usar la aplicación Create React como base y personalizarla para su propio proyecto. Pero no está del todo claro qué espera allí, detrás de esta expulsión. Porque cuando haces una expulsión, dice que esta es una operación muy peligrosa, no será posible devolverla y así sucesivamente, da mucho miedo. Aquellos que presionaron Expulsar saben que se arrojan muchas configuraciones, lo cual debe comprender. En general, existen muchos riesgos y no está claro qué hacer.
Te cuento como fue con nosotros. Primero, sobre nuestro proyecto. Nuestro proyecto front-end es Serp, páginas de resultados de motores de búsqueda, páginas de resultados de búsqueda de Yandex que todos han visto. Desde 2018 no estamos moviendo React y TypeScript. Aproximadamente 12 megabytes de código ya se escribieron en Serpa el año pasado. Hay algunos estilos y mucho código TS y SCSS. Cuántos al principio, en 2018, hubo, no escribí, hay muy poco, hubo un salto muy brusco.
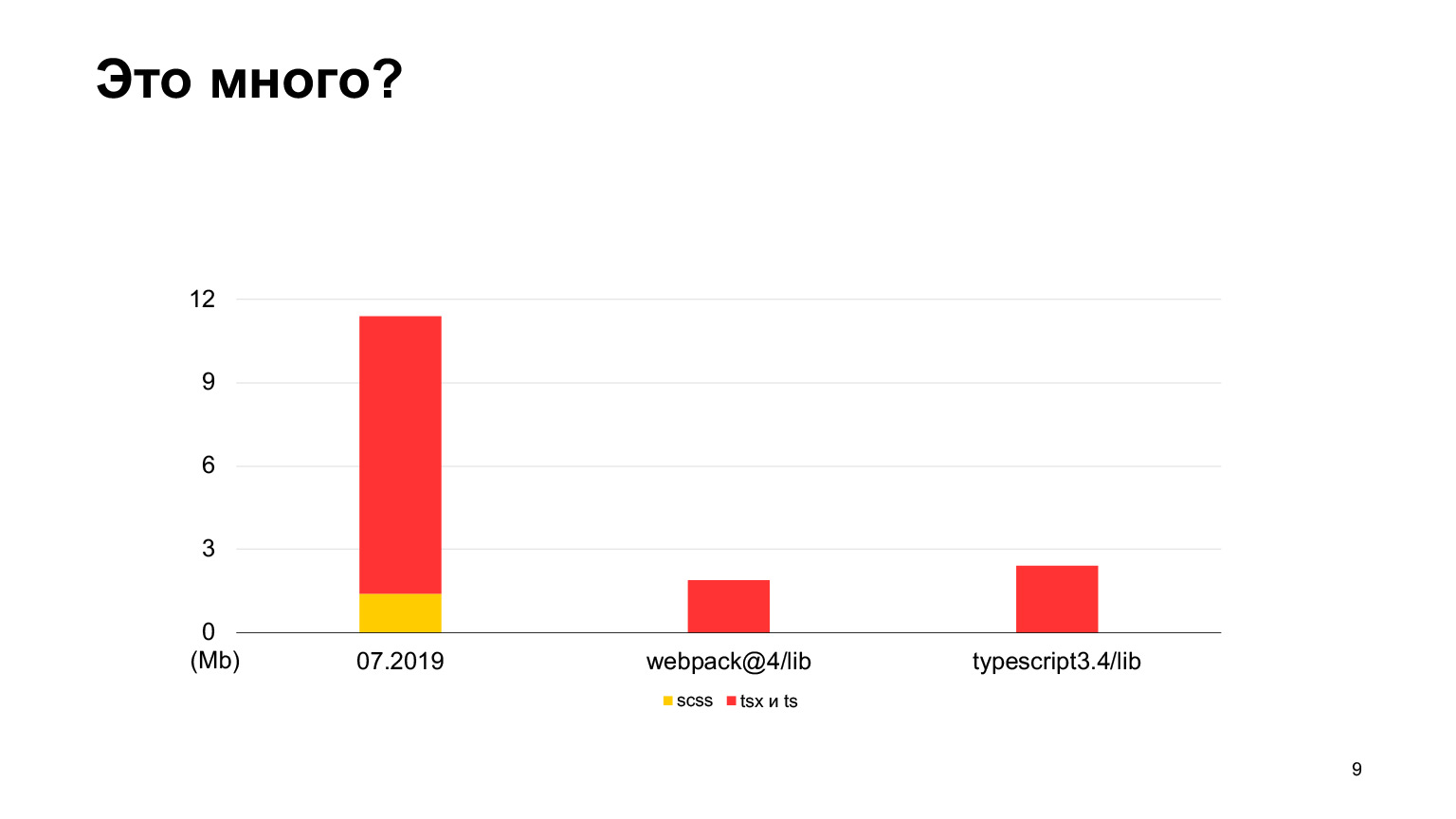
Veamos si esto es mucho código o no. En comparación con el código fuente de webpack-4, hay mucho menos código en webpack-4. Incluso el repositorio de TypeScript tiene menos código.
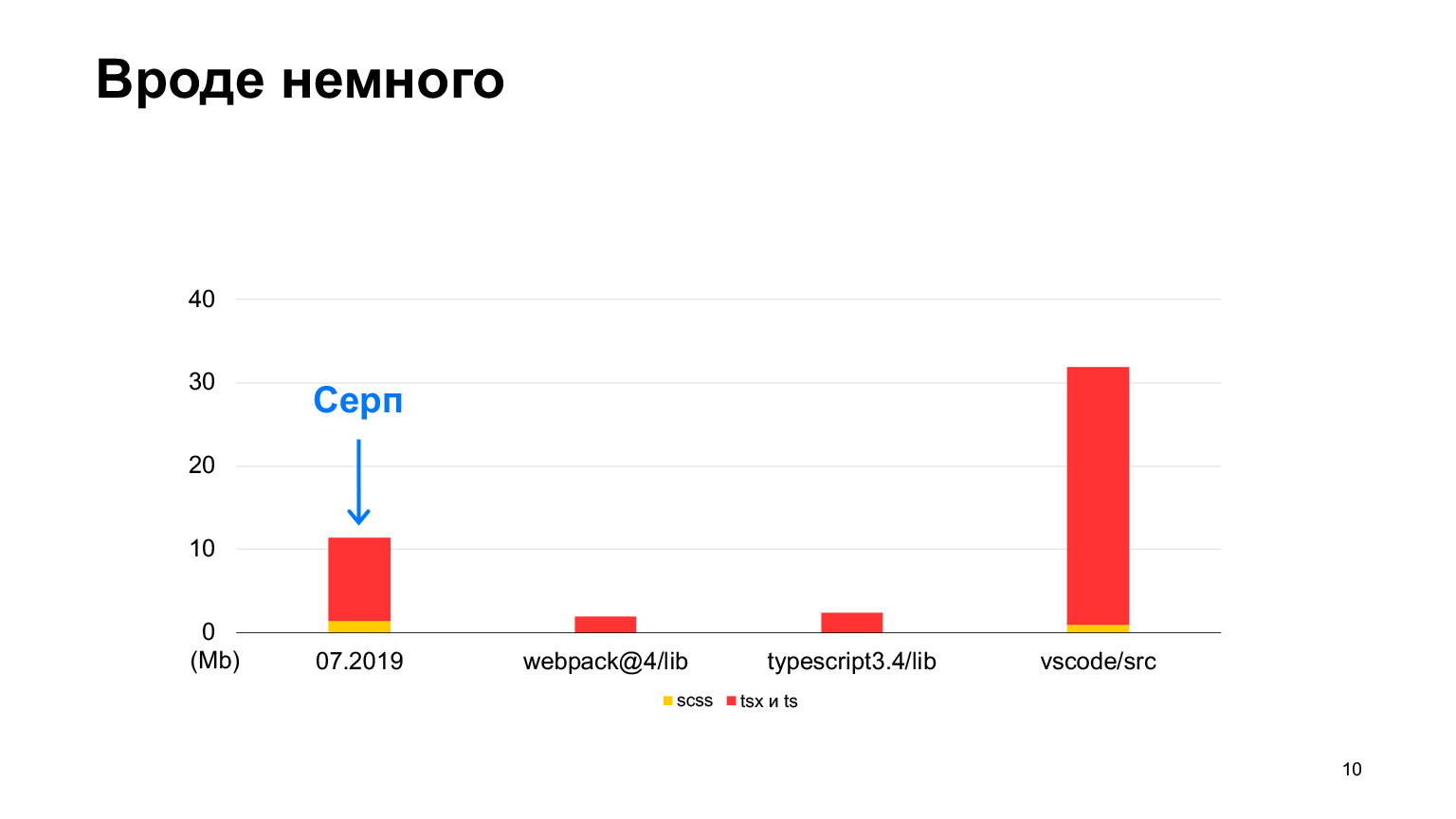
Pero vs-code contiene más código, un buen proyecto con hasta 30 megabytes de código TypeScript. Sí, también está escrito en TypeScript y el Sickle parece ser más pequeño. Comenzamos en 2018, en 2019 había 12 megabytes y 70 de nuestros desarrolladores trabajaron, haciendo 100 solicitudes de extracción vertidas por semana. En un año, triplicaron este tamaño y recibieron exactamente 30 megabytes. Tomé medidas este mes, en total tenemos 30 megabytes de código ahora, y esto ya es más que en vs-code.
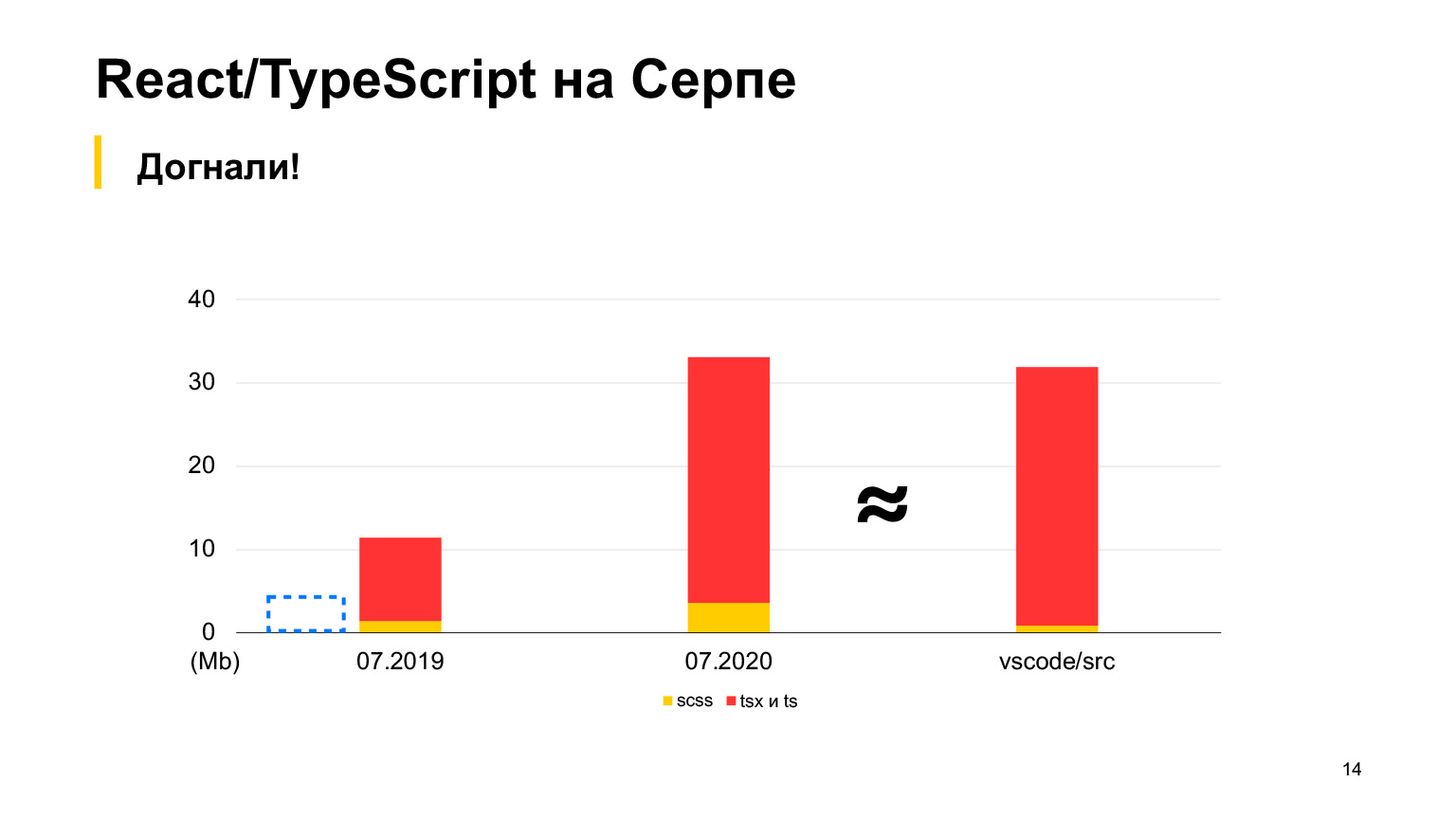
Aproximadamente igual, pero un poco más. Este es el orden de nuestro proyecto.
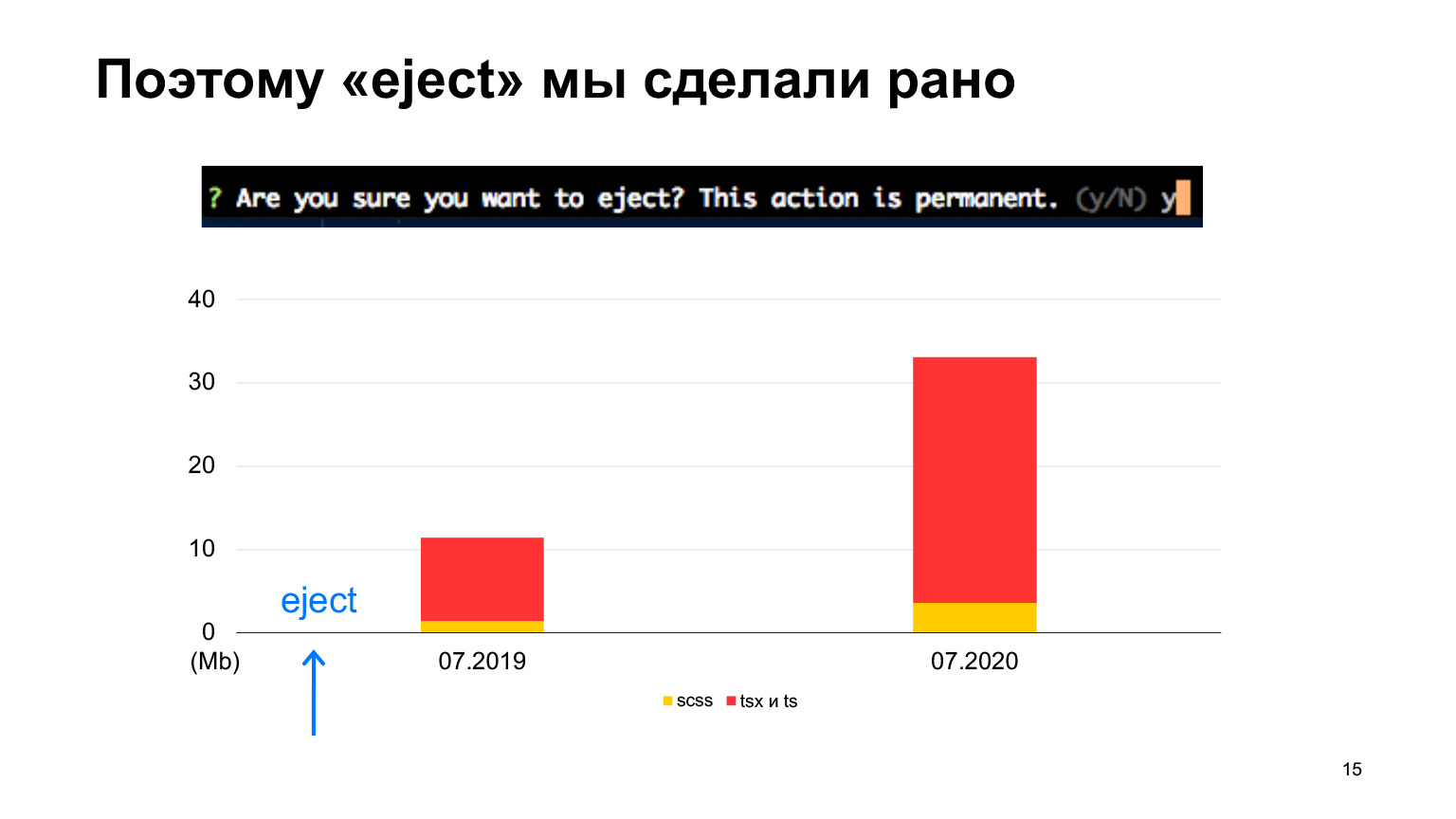
Y lo expulsamos desde el principio, porque inmediatamente supimos que tendríamos mucho código y, muy probablemente, las configuraciones iniciales que están en la aplicación Create React no funcionarían para nosotros. Pero comenzamos de la misma manera, con la aplicación Create React.
Así que de eso se tratará la historia. Queremos compartir nuestra experiencia, contarte lo que tuvimos que hacer con la aplicación Create React para que Yandex Serp funcione correctamente en ella. Es decir, cómo obtuvimos una carga e inicialización rápidas en el navegador, y cómo intentamos no ralentizar la compilación, qué configuraciones, complementos y otras cosas usamos para esto. Y, naturalmente, los resultados que hemos logrado llegarán al final.

¿Cómo razonamos? La idea original era que nuestra Sickle es una página que necesita renderizarse muy rápidamente, porque, básicamente, hay resultados de texto muy simples, por lo que necesitamos plantillas del lado del servidor, porque esta es la única forma de obtener una renderización rápida. Es decir, tenemos que dibujar algo incluso antes de que algo comience a inicializarse en el cliente.
Al mismo tiempo, quería hacer el tamaño mínimo de las estáticas, para no cargar nada superfluo y la inicialización también se realizó rápidamente. Es decir, queremos que el primer renderizado sea rápido y la inicialización rápida.

¿Qué nos ofrece la aplicación Create React? Desafortunadamente, no nos ofrece nada sobre la representación del servidor.
Dice que la renderización del servidor no es compatible con la aplicación Create React. Además, la aplicación Create React solo tiene una entrada para toda la aplicación. Es decir, de forma predeterminada, se recopila un paquete grande para toda su gran variedad de páginas. Esto es mucho. Está claro que de 30 megabytes, aproximadamente la mitad son de tipo TS, pero aún así una gran cantidad de código irá directamente al navegador.
Al mismo tiempo, la aplicación Create React tiene algunas configuraciones buenas, por ejemplo, el tiempo de ejecución del paquete web va allí en un fragmento separado. Se carga por separado, se puede almacenar en caché porque no cambia normalmente.
Además, los módulos de node_modules también se recopilan en fragmentos separados. También rara vez cambian y, por lo tanto, el navegador también los almacena en caché, lo cual es genial, debe guardarse. Pero al mismo tiempo, la aplicación Create React no tiene nada de traducciones.
Armemos nuestra lista de cómo debería verse en nuestro caso la lista de capacidades de nuestra plataforma. Primero, queremos que el renderizado del norte, como dije, haga un render rápido. Además, nos gustaría tener un archivo de entrada independiente para cada resultado de búsqueda.

Si, por ejemplo, Serpa tiene una calculadora, entonces nos gustaría que se entregara el paquete con la calculadora, y no es necesario que el paquete con el traductor se entregue rápidamente. Si todo esto se reúne en un gran paquete, entonces todo irá siempre, incluso si la mitad de estas cosas no se refieren a un tema específico.
Además, me gustaría suministrar módulos comunes en trozos separados para no cargar lo que ya se ha cargado.
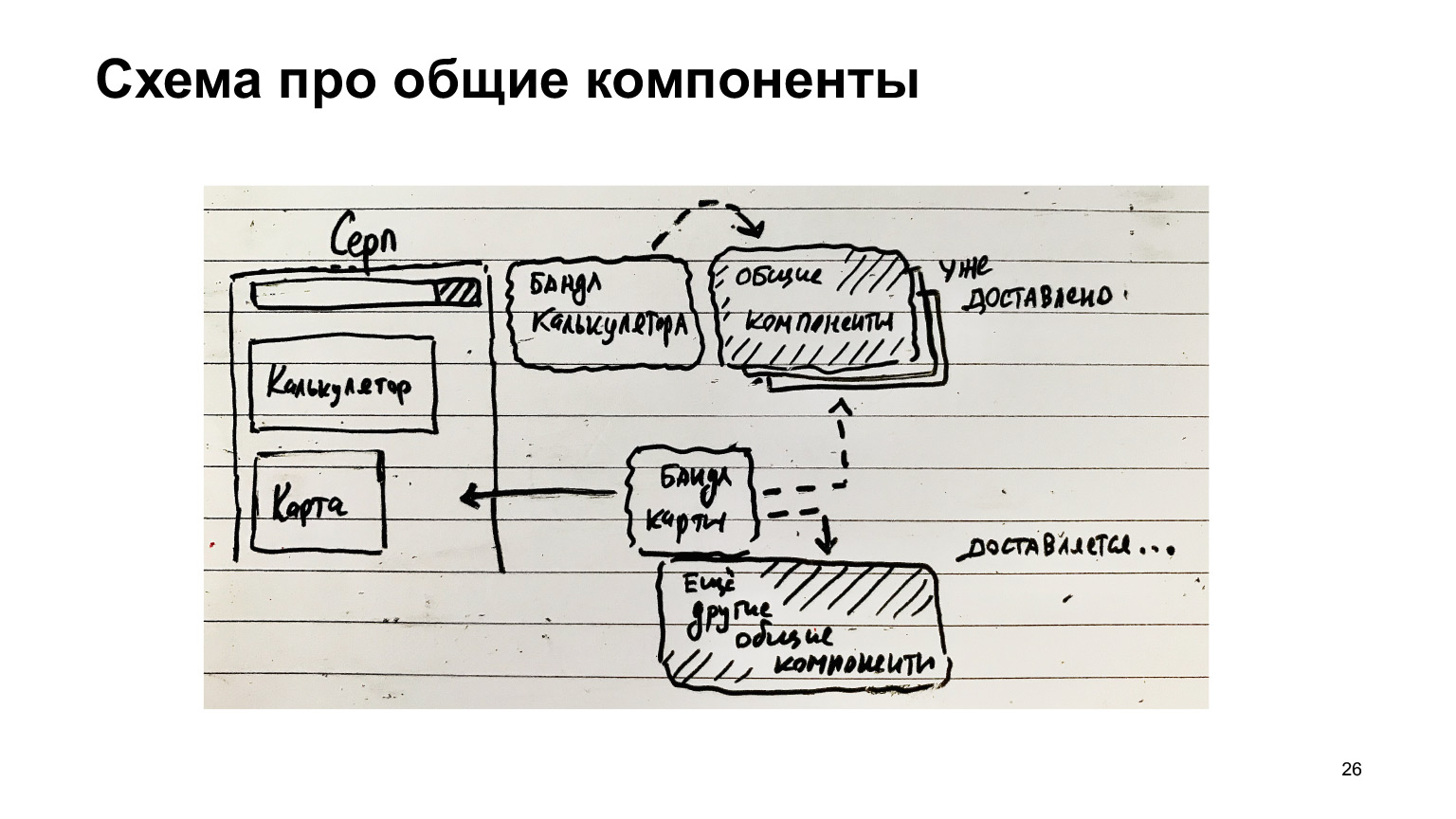
Aquí hay otro ejemplo con la hoz. Tiene una calculadora, hay un paquete de calculadoras. Hay componentes comunes. Fueron entregados al cliente. Luego apareció otra característica: un mapa. Manejé un paquete de mapas y otros componentes comunes, menos los que ya se entregaron.
Si los componentes comunes se recopilan por separado, entonces existe una gran oportunidad de optimización y solo se entrega lo que se necesita, solo diff. Y los módulos más populares que siempre están en la página, por ejemplo, el tiempo de ejecución del paquete web, que siempre es necesario para toda esta infraestructura, siempre debe estar cargado.
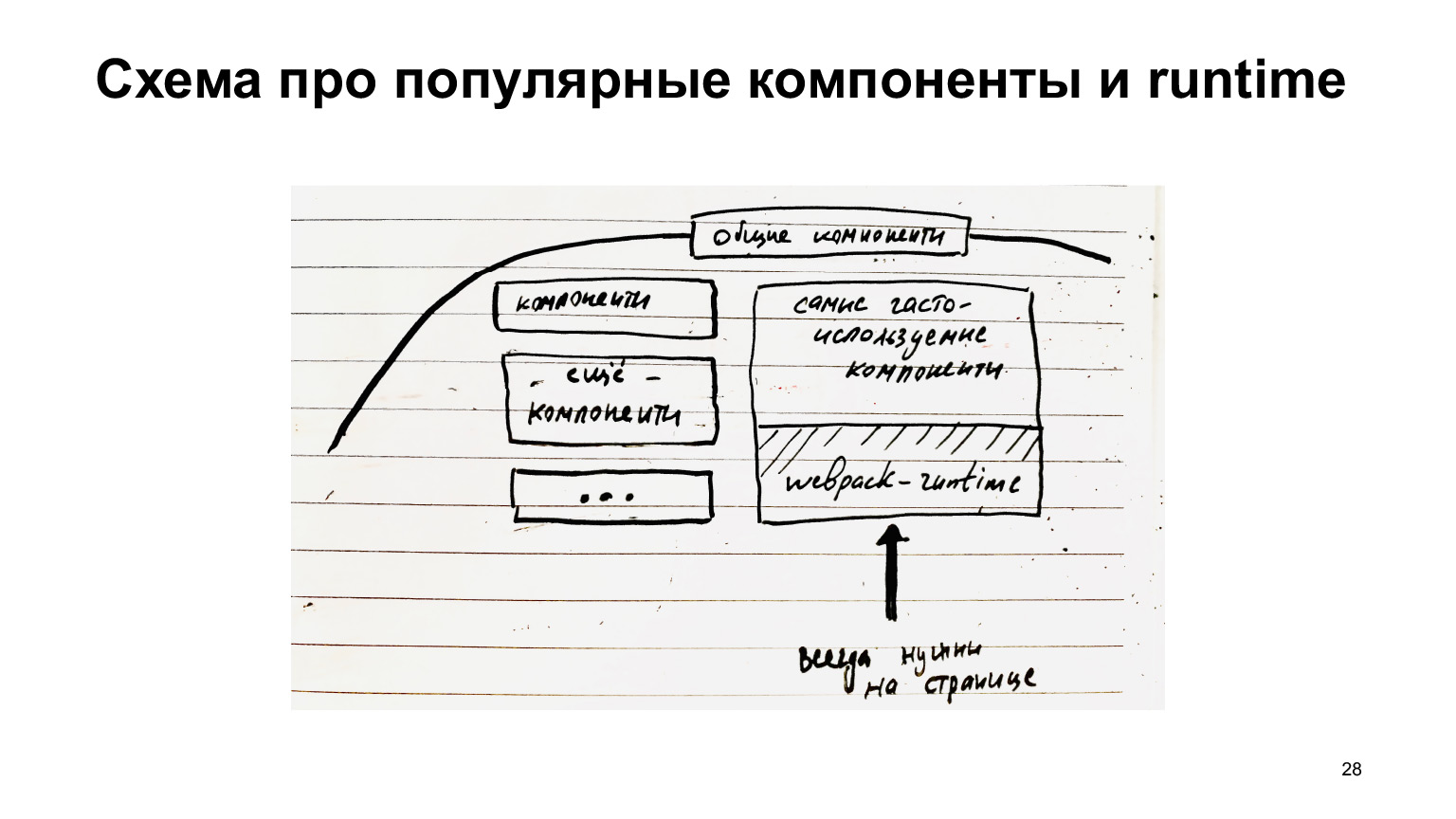
Por lo tanto, tiene sentido recopilarlos en un fragmento separado. Es decir, estos componentes comunes también se pueden dividir en aquellos componentes que no siempre son necesarios y componentes que siempre son necesarios. Pueden recopilarse en un archivo separado y cargarse siempre, y también almacenarse en caché, porque estos componentes comunes, como botones / enlaces, no cambian con mucha frecuencia, en general, obtienen una ganancia del almacenamiento en caché.

Y al mismo tiempo, debe tomar una decisión sobre el montaje de traducciones.

Todo está lo suficientemente claro aquí. Si vamos a Serp turco, nos gustaría descargar solo las traducciones al turco, y no descargar todas las demás traducciones, porque este es un código adicional.
¿Qué hicimos? Primero, sobre el código del servidor. Con respecto a esto, tendremos dos direcciones: construcción para producción y lanzamiento para desarrollo.
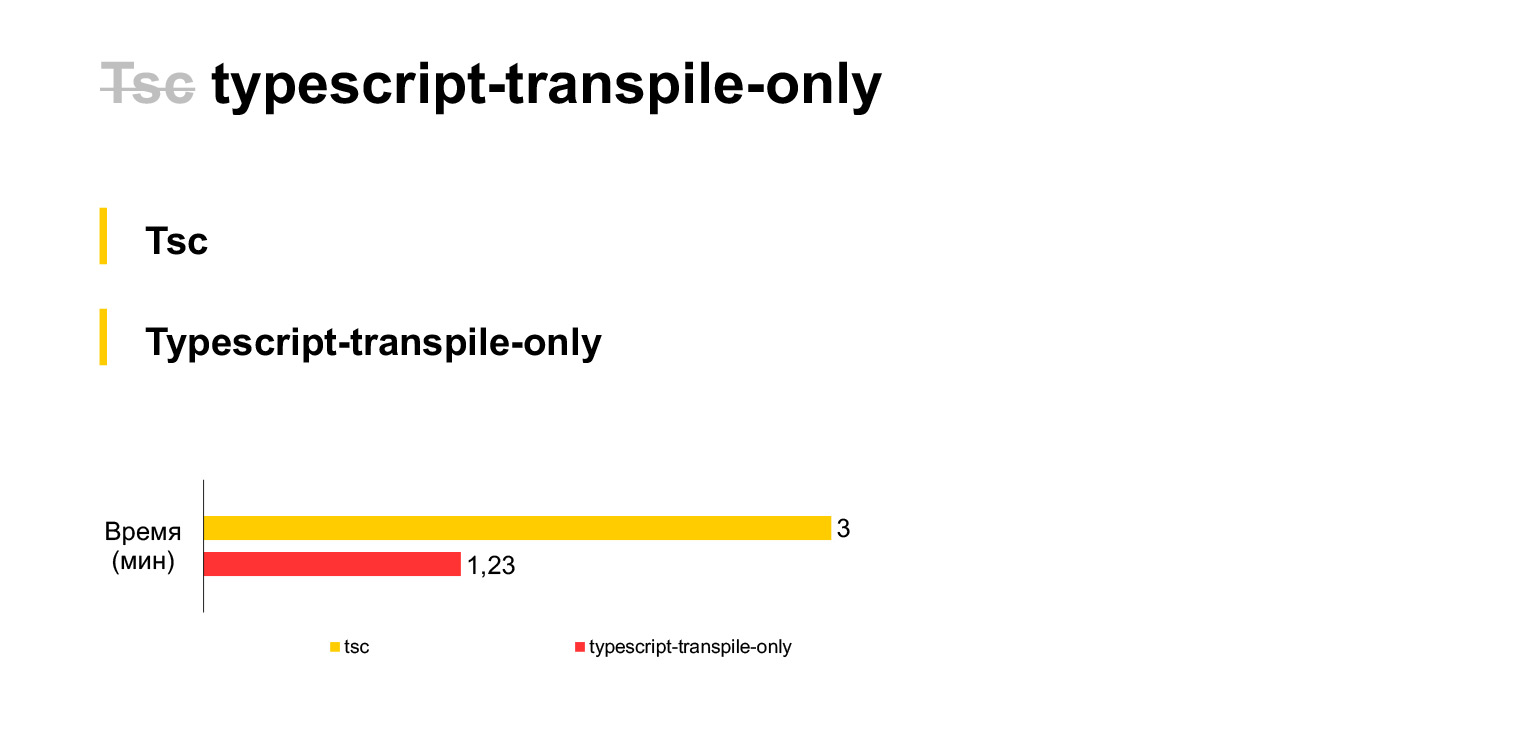
En general, primero debe hacer una declaración separada sobre TypeScript. Por lo general, los proyectos, como he oído, usan babel. Pero de inmediato decidimos utilizar el compilador estándar de TypeScript, porque creíamos que las nuevas funciones de TypeScript lo alcanzarían más rápido. Por lo tanto, abandonamos inmediatamente babel y usamos tsc.
Entonces, este es nuestro tamaño de código actual, nuestros 30 megabytes, se compilan en una computadora portátil en tres minutos. Bastante. Si se niega a la verificación de tipos y utiliza una bifurcación tsc durante cada compilación (desafortunadamente, TSC no tiene una configuración que desactive la verificación de tipos, tuvo que bifurcar), entonces puede ahorrar el doble de tiempo. La compilación de nuestro código tomará solo un minuto y medio.
¿Por qué no podemos verificar el tipo en tiempo de compilación? Porque nosotros, por ejemplo, podemos verificarlos en ganchos de confirmación previa. Cree un linter que solo ejecute la verificación de tipos, y el ensamblaje en sí se puede realizar sin verificación de tipos. Tomamos esta decisión.
¿Cómo corremos en dev? Dev generalmente también usa un paquete de babel con webpack, pero usamos una herramienta como ts-node.

Esta es una herramienta muy sencilla. Para ejecutarlo, es suficiente escribir tal requerimiento (ts-node) en el archivo JavaScript de entrada, y anulará los requisitos de todo el código TS más adelante en el proceso. Y si se carga un código TS en este proceso a lo largo del camino, se compilará sobre la marcha. Algo muy sencillo.
Naturalmente, existe una pequeña sobrecarga asociada con el hecho de que si el archivo aún no se ha cargado en este proceso, debe volver a compilarse. Pero en realidad, estos gastos generales son mínimos y generalmente aceptables.
Además, hay algunas líneas más interesantes en este listado. La primera es ignorar los estilos, porque no necesitamos estilos para las plantillas del lado del servidor. Solo necesitamos obtener HTML. Por lo tanto, también usamos un módulo de este tipo: ignorar estilos. Y además, desactivamos la verificación de tipos (solo transpile) exactamente como lo hicimos en TSC para acelerar el trabajo de ts-node.
Pasando al código de cliente. ¿Cómo recopilamos el código ts en el paquete web? Usamos ts-loader y la opción transpileOnly, es decir, aproximadamente el mismo paquete. En lugar de babel-loader, herramientas ts-loader y transpileOnly más o menos estándar.
Desafortunadamente, la compilación incremental no funciona en ts-loader. Es decir, después de todo, ts-loader no es una herramienta estándar y no está hecha por los mismos tipos que usan TypeScript. Por lo tanto, no todas las opciones del compilador son compatibles. Por ejemplo, no se admite la compilación incremental.
Una compilación incremental es algo que puede resultar muy útil en el desarrollo. Del mismo modo, puede agregar estos cachés a la canalización. En general, cuando los cambios son pequeños, no puede volver a compilar completamente todo, todo TypeScript, sino solo lo que ha cambiado. Funciona con bastante eficacia.
En general, para prescindir de las compilaciones incrementales, utilizamos el cargador de caché. Esta es la solución estándar de webpack. Todo está bastante claro. Cuando el código TypeScript intenta conectarse durante la compilación de un paquete web, el compilador lo procesa, lo agrega a la caché y, la próxima vez, si no hubo cambios en los archivos fuente, el cargador de caché no ejecutará ts-loader y lo tomará de la caché. Es decir, aquí todo es bastante sencillo.
Se puede usar para cualquier cosa, pero específicamente para TypeScript, es algo útil, porque ts-loader es un cargador bastante pesado, por lo que el cargador de caché es muy apropiado aquí.

Pero el cargador de caché tiene un inconveniente: funciona con el tiempo de modificación del archivo. Aquí hay un fragmento del código fuente. Y no funcionó para nosotros.

Tuvimos que bifurcar y rehacer el algoritmo de almacenamiento en caché basado en el hash del contenido del archivo, porque no nos convenía para usar el cargador de caché en la canalización.
El hecho es que cuando desee reutilizar los resultados de la compilación entre varias solicitudes de extracción, este mecanismo no funcionará. Porque si el montaje fue, por ejemplo, hace mucho tiempo. Luego, intenta realizar una nueva solicitud de extracción, que no cambia los archivos que se recopilaron la vez anterior.
Pero su mtime es más reciente. En consecuencia, el cargador de caché pensará que los archivos se han actualizado, pero en realidad no, porque no se trata de una hora de modificación, sino de una hora de pago. Y si lo hace así, se compararán los valores hash del contenido. El contenido no ha cambiado, se utilizará el resultado anterior.
Cabe señalar aquí que si estuviéramos usando babel, babel-loader tiene un mecanismo de almacenamiento en caché interno por defecto, y ya está hecho con hashes del contenido, no en mtime. Por tanto, quizás pensemos un poco más y miremos hacia babel.
Ahora sobre el ensamblaje de trozos.

Hablemos un poco sobre lo que hace el paquete web por defecto. Si tenemos un archivo de índice de entrada, los componentes están conectados a él. También tienen componentes, etc. Además, se conectan módulos comunes: React, React-dom y lodash, por ejemplo.
Entonces, de forma predeterminada, el paquete web, como probablemente todos saben, pero por si acaso, repito, reúne todas las dependencias en un gran paquete.
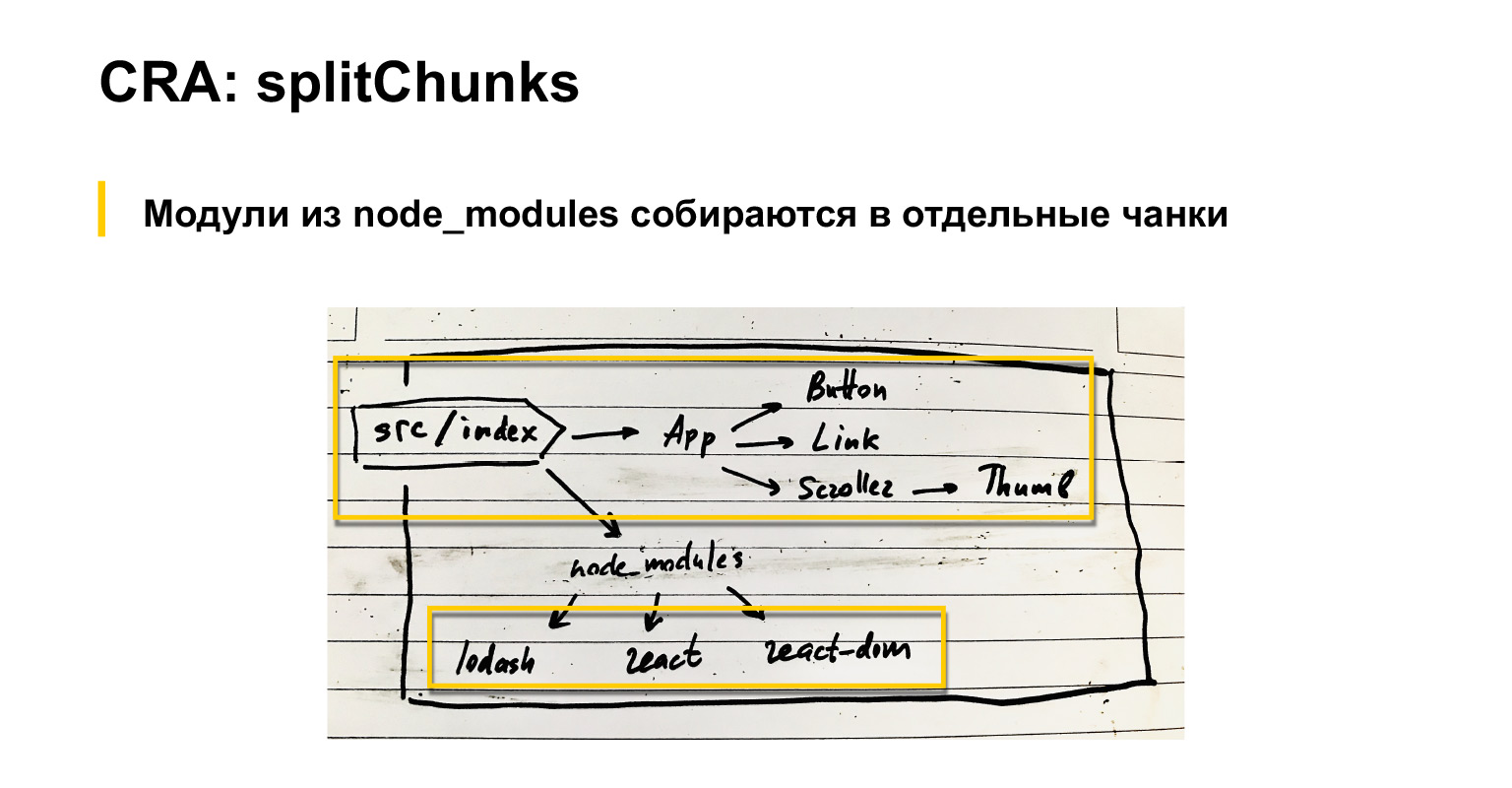
Al mismo tiempo, todo lo que está conectado a través de node_modules se puede ensamblar como externos, cargar con scripts separados o en un fragmento separado configurando una configuración especial optimization.splitChunks en webpack. En mi opinión, incluso de forma predeterminada, estos módulos de proveedores se recopilan en un fragmento separado. CRA tiene una versión ligeramente modificada de este splitChunks.

Recordemos qué son los runtimeChunks. Lo mencioné. Este es el tipo de código que contiene un "encabezado" de carga de scripts y funciones que aseguran el funcionamiento del sistema modular en el cliente. Y luego una matriz (o caché), que, de hecho, contiene los módulos.

¿Por qué les hablé de esto? Porque Create React App todavía usa una configuración que recopila estos runtimeChunks en un archivo separado. Este archivo no se incluirá en el paquete saludable original, sino en un archivo separado. Se puede almacenar en caché en el navegador y todo eso.
Entonces, ¿qué no funciona para nosotros en la aplicación Create React?

Este splitChunks, que se utiliza allí de forma predeterminada, recopila solo node_modules en fragmentos separados. Pero, de hecho, hay componentes comunes, bibliotecas comunes, que están a nivel de proyecto. También me gustaría recopilarlos en trozos separados, porque, quizás, también rara vez cambian. ¿Por qué nos limitamos solo a lo que hay en node_modules?
Además, con respecto a runtimeChunks, también podemos decir que sería genial, como discutimos originalmente, además del tiempo de ejecución en sí, también recopilar módulos allí, en el mismo fragmento, que siempre son necesarios. Mismos botones / enlaces. Siempre hay enlaces en Serp. Siempre me gustaría recopilar enlaces. Es decir, no solo el tiempo de ejecución del paquete web, sino también algunos componentes súper populares.
Esto no está presente en la aplicación Create React. ¿Cómo lo hicimos con nosotros?

Ajustamos splitChunks de tal manera que deshabilitamos todo el comportamiento estándar y pedimos recopilar en código común no solo lo que está en node_modules, sino también cuáles son los componentes comunes de nuestro proyecto y el código de biblioteca de nuestro proyecto, lo que está en src / lib , src / components contiene.
Además, recopilamos en fragmentos separados lo que está conectado a través de importaciones dinámicas y lo que normalmente se denomina fragmentos asincrónicos.
Aquí debes prestar atención a dos opciones. Uno es hacer cumplir y el otro es inicial. En general, aplicar es una configuración lo suficientemente conveniente que deshabilita cualquier heurística compleja en splitChunks.
De forma predeterminada, splitChunks intenta comprender cuántos módulos hay en demanda y tener en cuenta estas estadísticas en la división. Pero es difícil seguir esto, y la demanda del módulo puede cambiar de vez en cuando, y el módulo "saltará" entre trozos. Desde el fragmento general hasta el paquete de funciones y viceversa. Es decir, este es un comportamiento muy impredecible, por lo que lo deshabilitamos.
Es decir, siempre decimos todo lo que satisfaga las condiciones en el campo de prueba, nos metemos en los trozos comunes. No queremos ninguna heurística.
Pero chunks: initial también es algo bueno, se trata del hecho de que estos módulos síncronos, módulos que se conectan a través de importaciones dinámicas, se pueden conectar en diferentes lugares de diferentes formas. Es decir, puede conectar el mismo módulo mediante importación dinámica o mediante importación regular.
Y el valor inicial permite construir el mismo módulo de dos formas. Es decir, está ensamblado, tanto asíncrono como síncrono, lo que permite su uso en ambos sentidos. Lo suficientemente conveniente. Esto infla ligeramente el tamaño de las estadísticas recopiladas, pero le permite usar cualquier importación.
A propósito de la documentación, esto es bastante difícil de entender. Recientemente releí la documentación del paquete web y no se ha escrito nada normal sobre initial.

Esto es lo que hicimos con splitChunks. Ahora, ¿qué hemos hecho con runtimeChunks. En lugar de recopilar solo el tiempo de ejecución en runtimeChunks, queremos agregar más componentes súper populares allí.
Así que escribimos nuestro propio complemento llamado MainChunkPlugin. Y tiene un entorno muy trivial. Solo hay una lista de módulos que deben recopilarse allí, que consideramos populares.
Con solo usar nuestras herramientas de prueba A / B, varias herramientas fuera de línea, nos dimos cuenta de qué componentes aparecen con mayor frecuencia en los resultados de búsqueda. Ahí es donde se escribieron en una lista tan plana. Y al final, nuestro complemento recopila estos componentes de la lista, así como las bibliotecas, así como el tiempo de ejecución del paquete web que recopila este optimization.splitChunks estándar.

Aquí, por cierto, hay un fragmento de código que pega el tiempo de ejecución. Tampoco es tan trivial para mostrar que los complementos no son tan fáciles de escribir, pero luego veamos qué dio.

También debe tenerse en cuenta que, en términos generales, webpack tiene un mecanismo estándar para hacer esto, llamado DLLPlugin. También le permite recopilar un fragmento separado de acuerdo con la lista de dependencias. Pero tiene varias desventajas. Por ejemplo, no incluye runtimeChunks. Es decir, runtimeChunks siempre tendrá un fragmento separado y habrá un fragmento ensamblado por DLLPlugin. Esto no es muy conveniente.
Además, DLLPlugin requiere un ensamblaje separado. Es decir, si quisiéramos construir este fragmento separado con los componentes más percusivos usando DLLPlugin, tendríamos que ejecutar dos ensamblajes.
Es decir, uno ensambla este fragmento separado con el archivo de manifiesto, y el resto del ensamblado recopila todo lo demás, simplemente restando a través del archivo de manifiesto, no recopila lo que ya ha entrado en el fragmento con componentes populares. Y esto ralentiza la compilación, porque la implementación de DLLPlugin nos llevó siete segundos localmente. Eso es mucho. Y no se puede optimizar porque tiene una ejecución secuencial estricta.
Además, en cierto momento necesitábamos construir este bloque principal nuestro con componentes populares sin CSS, solo JS. DLLPlugin no hace eso. Siempre recopila todo lo que está disponible a través de las necesidades a través de las importaciones. Es decir, si incluyes CSS, siempre impacta también. Fue incómodo para nosotros. Pero si esto no es un problema para usted y no desea escribir un código tan complicado, DLLPlugin es una solución bastante normal. Resuelve el problema principal. Es decir, entrega los componentes más populares en un archivo separado. Puede ser usado.
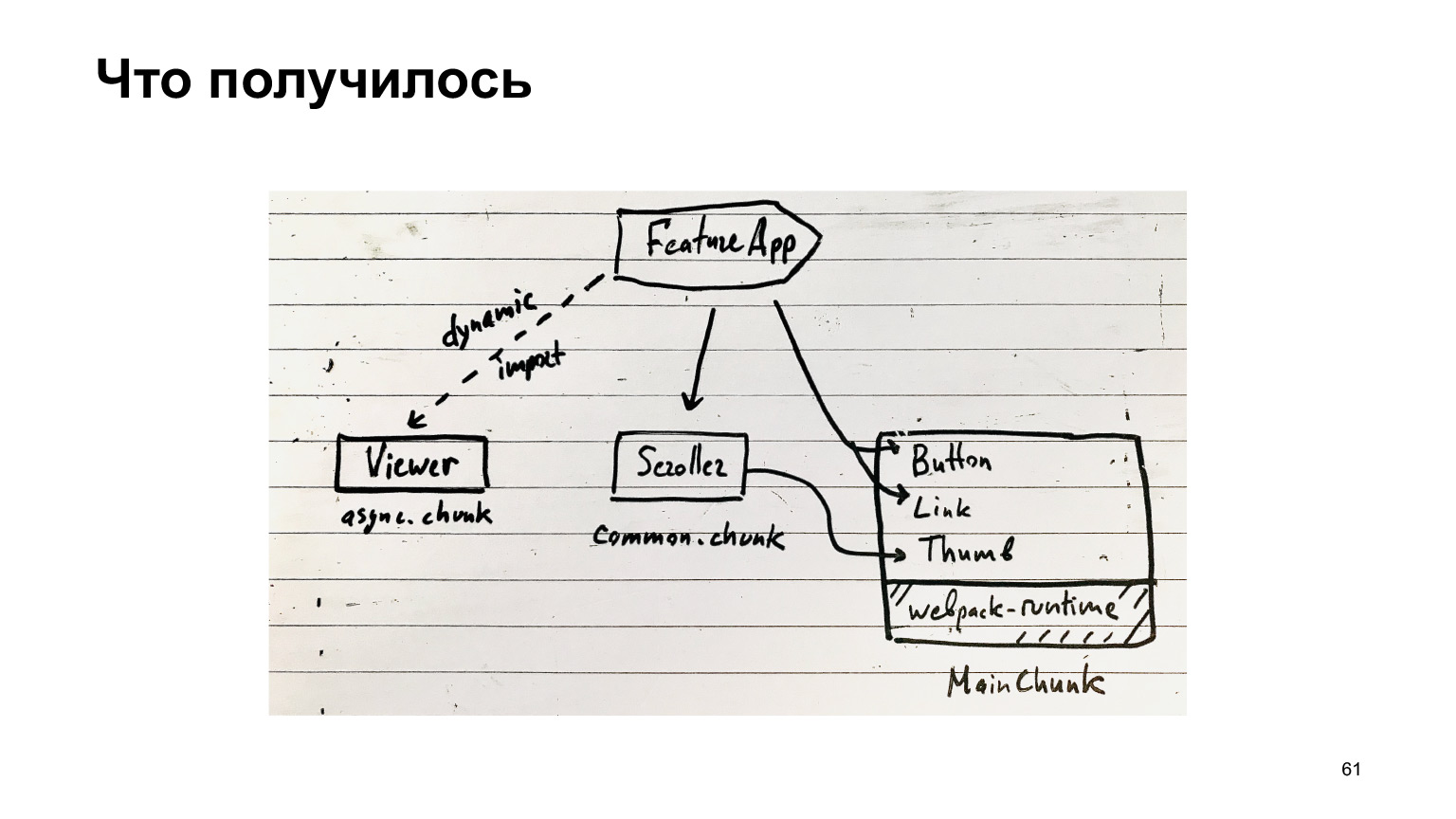
Entonces que fue lo que recibimos? Nuestra función puede usar componentes súper populares de nuestro MainChunk, que se ensamblan mediante un complemento especial del mismo nombre. Además, hay fragmentos comunes, que incluyen todo tipo de componentes comunes, y fragmentos asincrónicos, que se cargan mediante importaciones dinámicas.
El resto del código está en los paquetes de funciones. En principio, esta es su estructura de fragmentos.
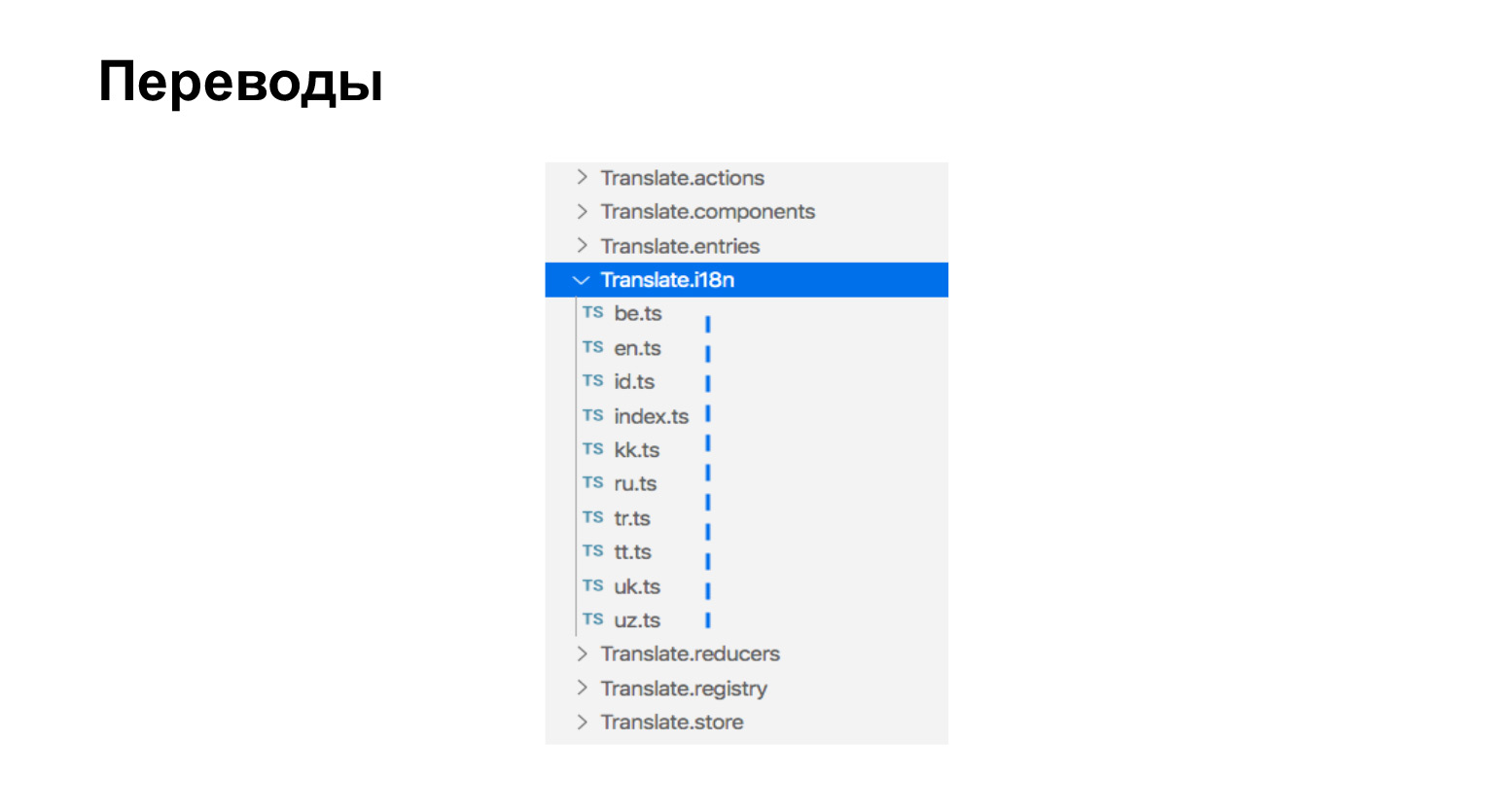
Sobre el montaje de traducciones. Nuestras traducciones son solo archivos ts que están junto a los componentes que necesitan traducciones. Aquí tenemos nueve idiomas, aquí hay nueve archivos.

Las traducciones se ven así. Es simplemente un objeto que contiene una frase clave y el significado de la frase traducida.

Así es como se conectan las traducciones al componente y luego se usa un ayudante especial.

¿Cómo se podrían recopilar estas traducciones? Pensamos: necesitamos recopilar traducciones, buscar en Internet, qué escriben, cómo podemos hacerlo.
Dicen en internet: usa la multicompilación. Es decir, en lugar de ejecutar una compilación de paquete web, simplemente ejecute la compilación de paquete web para cada idioma. Pero, dicen, todo saldrá bien, porque hay un cargador de caché, esto es todo este trabajo general con TypeScript, o lo que sea que tengas, se guardará en caché, y por tanto no tardará.
No se desanime, no crea que serán nueve ejecuciones de paquetes web reales. No será así, será bueno.
Lo único que debe corregirse es agregar el módulo ReplacementPlugin, que, en lugar de un archivo de índice que conecta todos los idiomas, lo reemplazará con un idioma específico. Todo es bastante trivial y sí, la salida debe corregirse. Ahora resulta que necesitamos recopilar un paquete separado para cada idioma.

El diagrama de esta receta es el siguiente. Había un traductor. Conectó traducciones del traductor. Él conectó los idiomas y nosotros, en lugar de recopilar esta estructura, la replicamos para cada idioma, obtuvimos uno separado y recopilamos cada uno como una compilación separada.
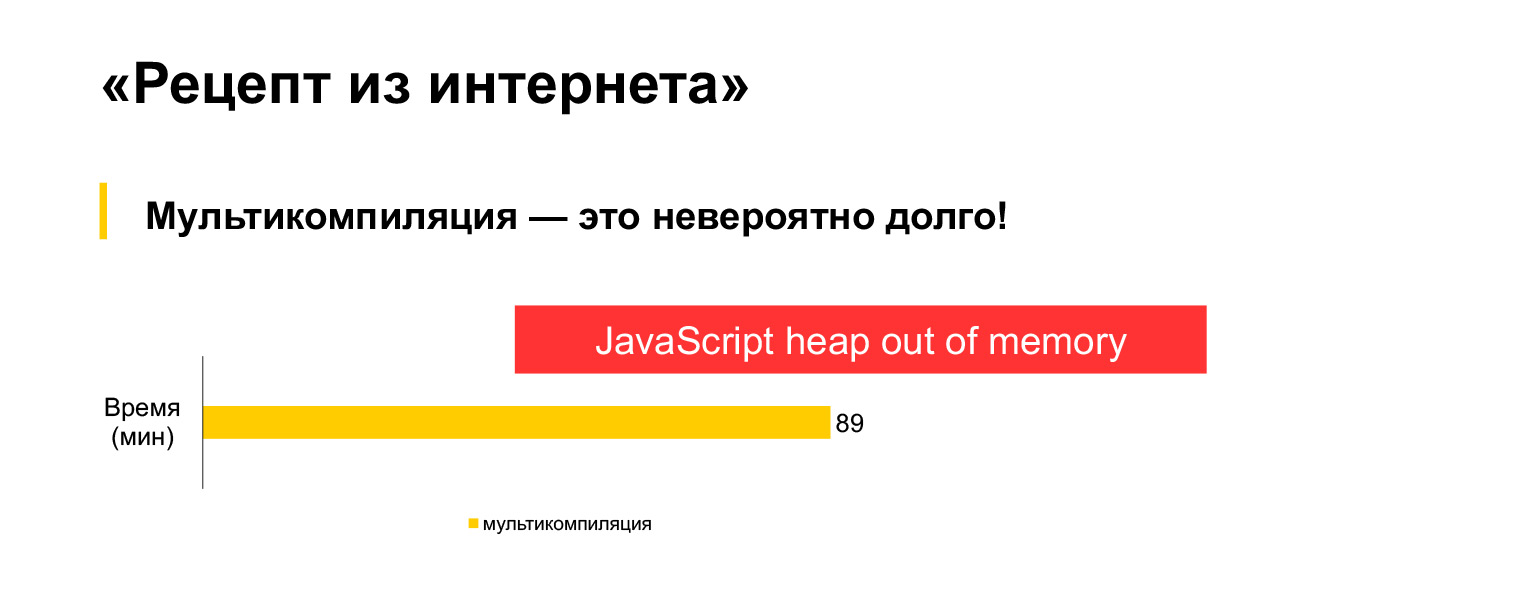
Desafortunadamente, no funciona. Intenté ejecutar esta opción de compilación múltiple para nuestro código actual de 30 MB, esperé una hora y media y obtuve este error.

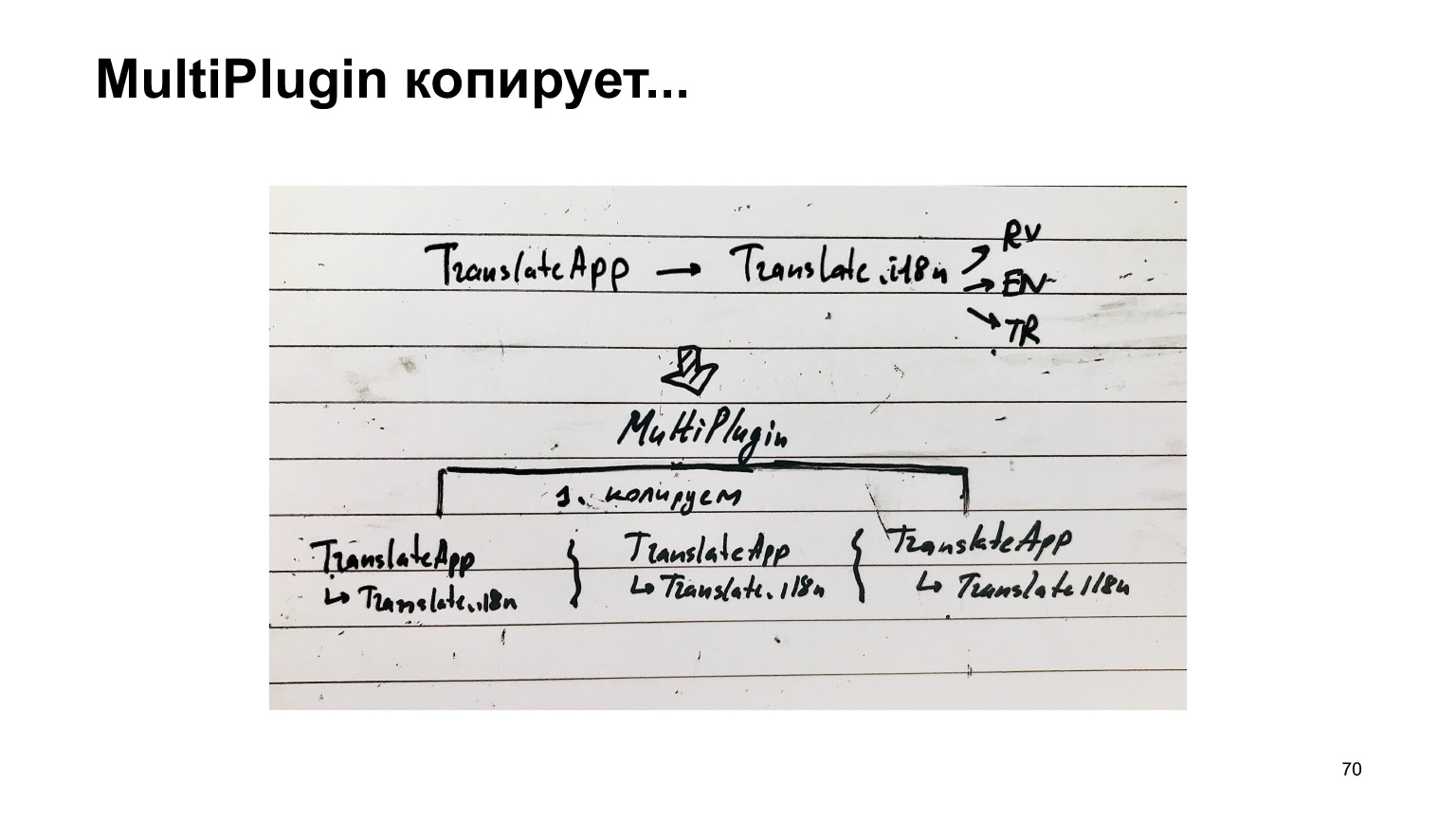
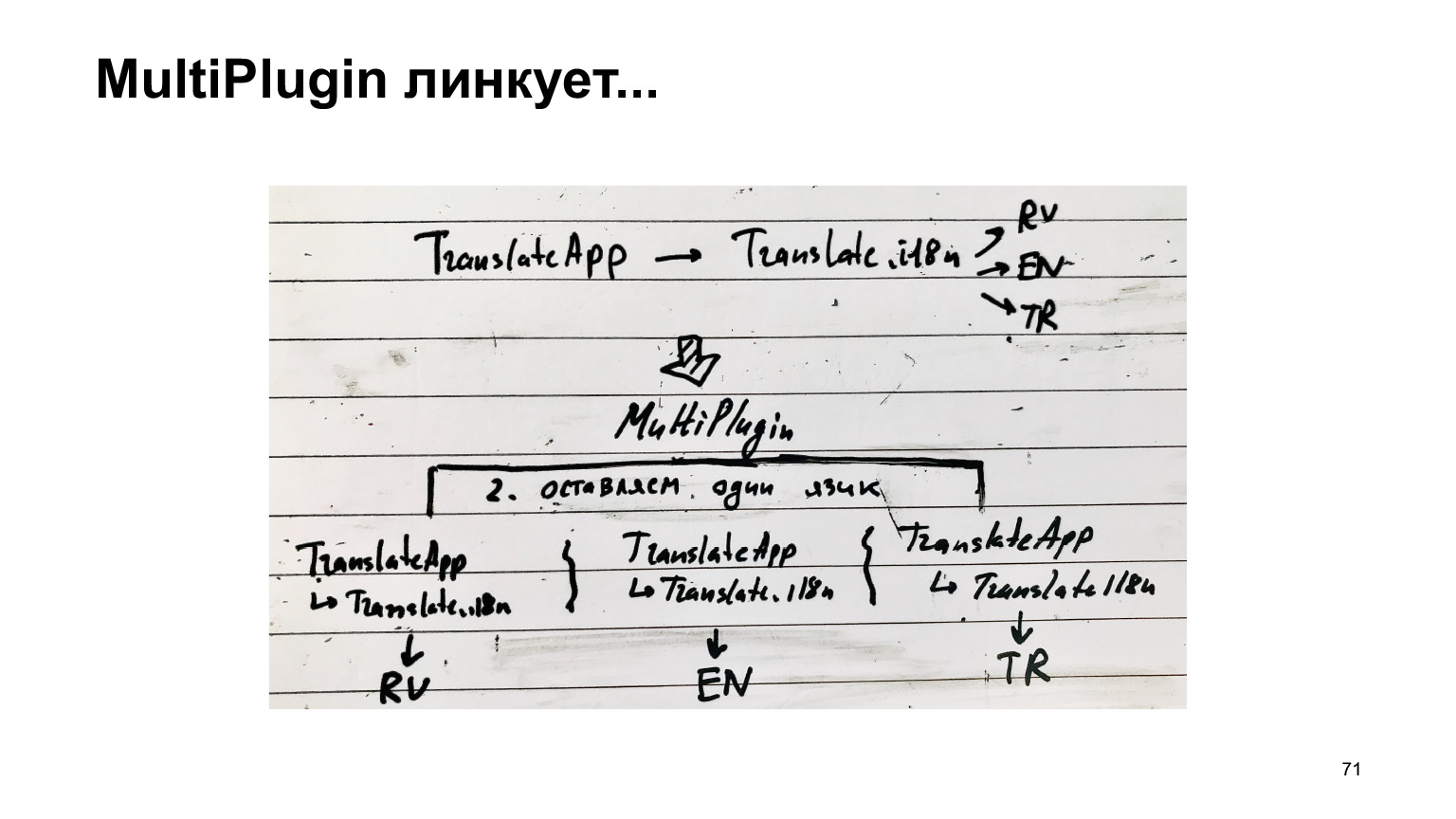
Es muy largo e imposible. ¿Qué hemos hecho con esto? Hemos creado otro complemento. Tomamos la misma estructura y nos metemos en el trabajo de webpack cuando está a punto de guardar los archivos de salida en el disco. Copiamos esta estructura tantas veces como idiomas tengamos y pegamos un idioma a cada uno. Y solo entonces creamos los archivos.

Al mismo tiempo, el trabajo principal que realiza webpack para evitar las dependencias de compilación no se repite. Es decir, nos metemos en la última etapa y, por lo tanto, podemos esperar que sea rápido.

Pero el código del complemento resultó ser complicado. Esto es literalmente una octava parte de nuestro complemento. Solo estoy mostrando lo difícil que es. Y allí encontramos regularmente errores pequeños y desagradables. Pero no fue más fácil implementarlo. Pero funciona muy bien.
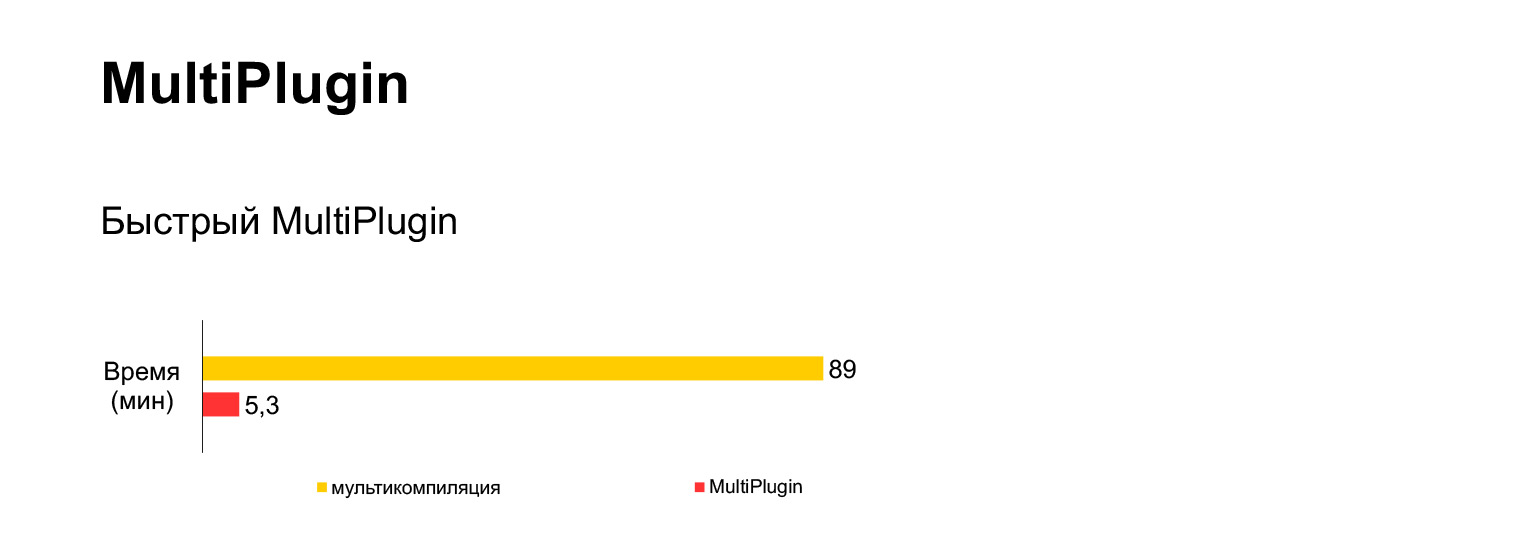
Es decir, en lugar de una hora y media con un error, obtenemos cinco minutos de montaje con este plugin nuestro.
Ahora entrega e inicialización.

La entrega y la inicialización son sencillas. Lo que cargamos en recursos separados, usamos precarga, como todos los demás, supongo. Luego incluimos CSS, JS, en realidad HTML para nuestros componentes, y cargamos estos recursos, pero sin async.
Experimentamos. Si usamos async, entonces se retrasa el momento del inicio de la interactividad, lo que no querríamos. Así que solo use la precarga y cargue al final de la página. En general, nada especial.

Al mismo tiempo, alineamos todo lo demás. Es decir, este es nuestro MainChunk, insertamos su CSS. Componentes generales, estilos, en general, todo lo que esté escrito en la diapositiva, lo incluiremos en línea. Esta fue también una serie de experimentos que mostraron que "en línea" da el mejor resultado para el primer render y el inicio de la interactividad.
Y ahora a los números. Para hablar de números, debe decir dos palabras sobre métricas.

Contamos con un equipo de velocidad dedicado que tiene como objetivo hacer que todo el código front-end funcione de manera eficiente. Esto se refiere a la creación de plantillas en el lado del servidor, la carga de recursos y la inicialización en el cliente, en general, todo esto.
Tenemos un montón de métricas que se envían desde la producción a nuestro sistema de registro especial. Podemos controlar esto en experimentos A / B. Tenemos herramientas fuera de línea, en general, estamos siguiendo muy activamente todo esto.
Y usamos estas herramientas cuando implementamos este nuevo código nuestro en React y TypeScript.

Hagamos un seguimiento ahora con la ayuda de herramientas fuera de línea (porque no pude armar un experimento en línea honesto que usara todas nuestras métricas). Veamos qué sucede si retrocedemos de nuestra solución actual a Create React App en estas métricas clave.
La herramienta funciona de manera muy sencilla. Se toma una porción de solicitudes, en este caso se toma una solicitud con características en React, porque no todo Serp se ha reescrito todavía en React. Luego, se disparan nuestras plantillas, se recopilan las mediciones, se insertan en una utilidad especial que compara y encuentra estos resultados y métricas. En este caso, solo quedan resultados estadísticamente significativos. En general, todo es razonable allí.
Veamos qué pasa.

La desactivación de MultiPlugin, que, de hecho, recopila todas las traducciones en lugar de solo la traducción requerida, no mostró cambios estadísticamente significativos.
Al principio estaba un poco molesto, luego me di cuenta de que, de hecho, esto no es un problema, porque ahora no tenemos muchas características que tengan muchas traducciones traducidas a React. Por lo tanto, cuando haya más características de este tipo, estos cambios significativos definitivamente aparecerán. Es solo que ahora hay funciones que se muestran principalmente en Rusia y no tienen traducción. Y la cantidad de código contenido en los componentes supera con creces la cantidad de traducciones. Por lo tanto, es imperceptible que todas las traducciones estén en camino.
Quizás se notaría en experimentos más honestos, si se llevara a cabo un experimento honesto. Pero la herramienta sin conexión no mostró estos cambios.

Si desactivamos MainChunkPlugin, el tiempo para el inicio de la interactividad se ralentiza y la carga de HTML también se ralentiza mucho. Por tanto, la cosa es bastante necesaria.
¿Por qué se ralentiza la carga de HTML? Porque todo el código que solía cargarse en este fragmento separado por un recurso separado ahora está incluido en HTML. Es como si lo pusiéramos todo en línea, pero la interactividad también se ralentiza. En principio, bastante esperado.
Y ahora la pregunta: ¿qué pasaría si pones todo en un paquete, no usas ningún trozo con componentes comunes? Resulta que esta no es una imagen feliz en absoluto.

El primer render se ralentiza drásticamente. La interactividad también casi se duplicó. Esto hace que el HTML sea más pequeño ya que todo el código comienza a entregarse en un recurso separado. Pero la interactividad, como puede ver, no ayuda.
Y montaje. Últimas diapositivas.
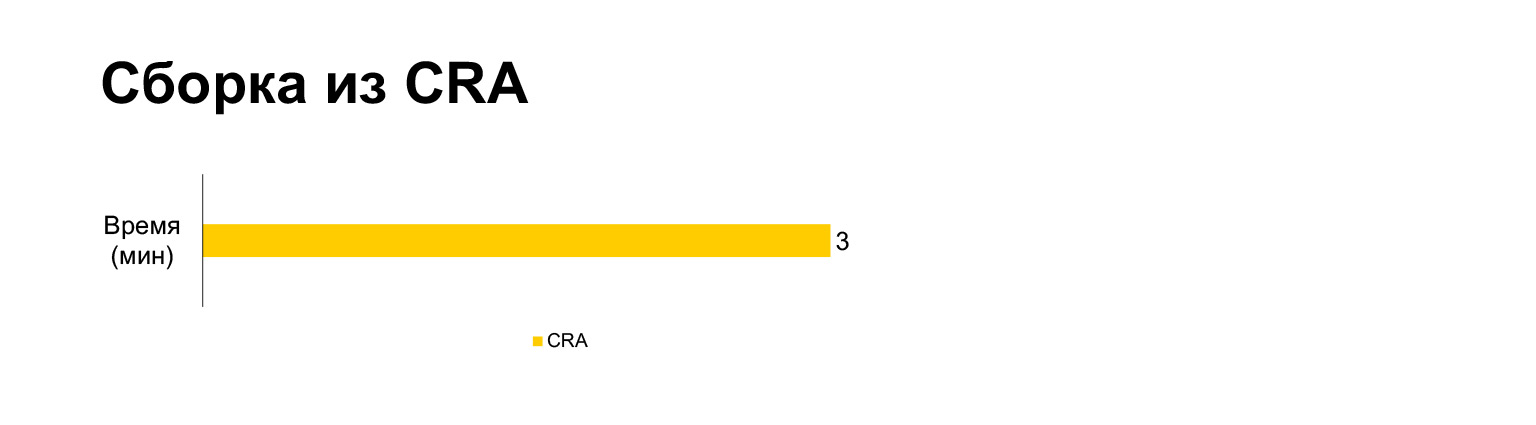
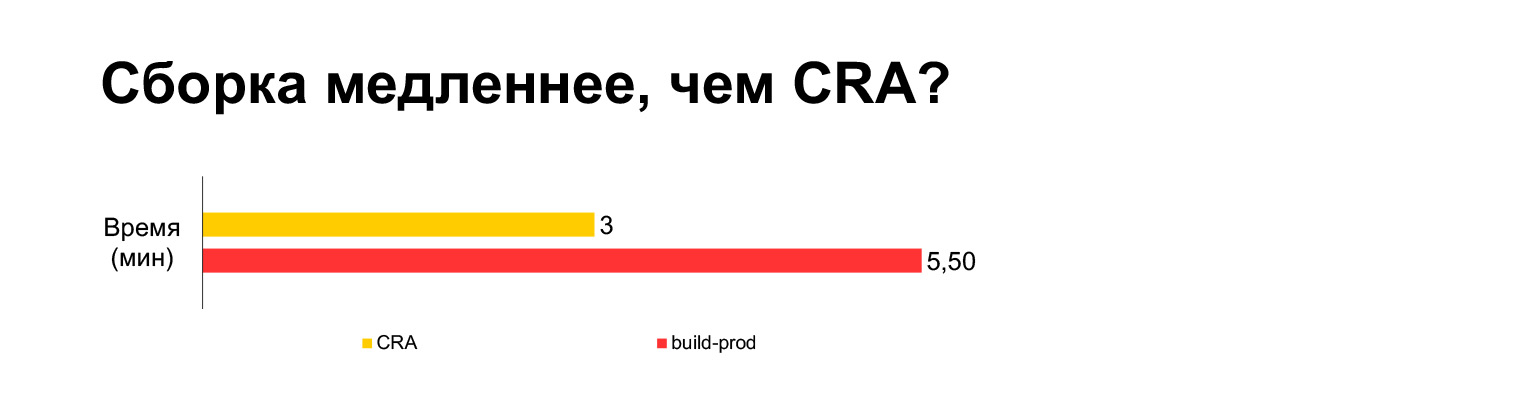
El tiempo de compilación de la aplicación Create React para el proyecto actual toma tres minutos en una computadora portátil. Y con todas nuestras campanas y silbidos, cinco minutos. ¿Largo?
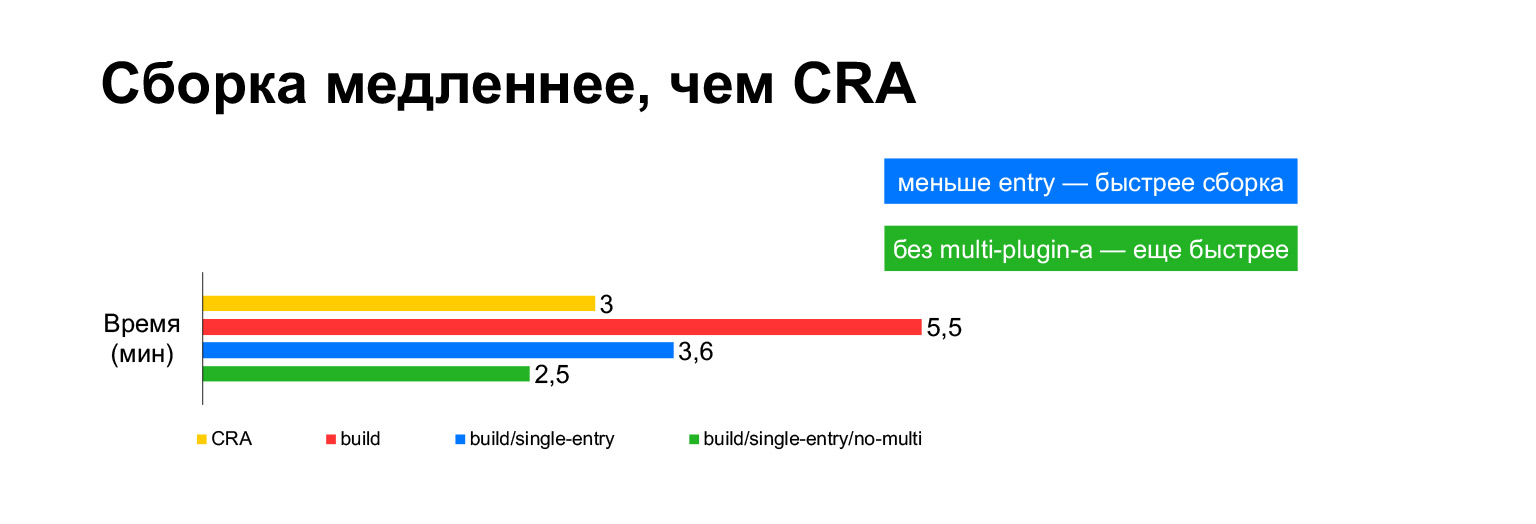
Sin embargo, de hecho, si se juntan en un paquete, resultan tres minutos. Construir sin MultiPlugin lo hace incluso más rápido que la aplicación Create React. Pero como mostré en las diapositivas anteriores, no podemos rechazar estas modificaciones a los scripts de compilación originales, porque sin ellos, las métricas de velocidad se volverán muy malas.
Ahora repasemos lo que es útil aprender de este informe.

Babel no es la única forma de trabajar con TypeScript. Se pueden utilizar TSC, ts-node y ts-loader. Funciona bastante bien.
Dicho esto, las verificaciones de TypeScript, la verificación de tipos, no tienen que realizarse cada vez que compila. Esto se ralentiza mucho, como recordará, dos veces. Por lo tanto, es mejor colocar esas cosas en controles separados, ganchos de confirmación previa, por ejemplo.
Es mejor recopilar los componentes de uso frecuente en un fragmento separado. También es deseable recopilar componentes comunes en fragmentos separados, porque esto permite cargar solo lo que se necesita, solo diff.
Lo más importante es que si no tiene todo el código utilizado en todas las páginas, debe dividirlo en entradas separadas, recopilar paquetes separados y cargar a medida que el usuario ve los tipos correspondientes de resultados de búsqueda. Descargue solo los archivos que necesite. Esto, como ha visto, da el mejor resultado. Algo bastante obvio, pero no estoy seguro de si todos hacen esto, porque todavía permanecen en la aplicación Create React.
La multicompilación es muy larga. No crea si alguien dice que la multicompilación está bien y que los cachés en algún lugar adentro pueden manejar todo esto. El uso de precarga e inline también da resultados.
Varios enlaces sobre la hoz:
- clck.ru/PdRdh y clck.ru/PdRjb : dos informes que tratan de reescribir Serp en React, esta es la primera etapa, sobre cómo llegamos a esto y por qué comenzamos a hacerlo. El segundo informe trata sobre cómo planeamos e hicimos todo esto desde un punto de vista gerencial, cuáles fueron las etapas.
- clck.ru/PdRnr : informe sobre nuestras métricas de velocidad. Es para aquellos que de repente se preguntaron qué más hay, cómo funcionan las herramientas en línea.
Gracias a todos.