
La versión completa de dos horas se puede ver en el canal de YouTube de Hexlet .
Tabla de contenido:
Historia de la empresa y del producto
Cómo funciona el desarrollo de productos
Selección y evolución de tecnología
- Flash → Lienzo
- Angular → Reaccionar
- Servidores y bases de datos
- Java
- Prueba de evolución
- Crecimiento de carga y refactorización
Procesos en desarrollo
- Revisión de código y solución técnica
- Revisión de desempeño
- Cómo funciona la contratación de ingenieros
- Posiciones junior
Historia del producto y de la empresa
Miro es una plataforma de pizarra colaborativa en línea para la colaboración visual. La palabra clave es colaboración, colaboración, respectivamente, las métricas clave por las que medimos nuestra efectividad son el número de tableros de colaboración y sesiones colaborativas que se producen en el producto.
Nos llamamos plataforma porque ya hemos ido más allá de un producto: tenemos una API abierta, un mercado, una oficina de desarrollo, por lo que cualquier empresa puede expandir el producto por sí misma.
Nuestro público objetivo son los equipos de productos que operan desde la misma oficina o desde diferentes. Muy a menudo, Miro se utiliza para realizar talleres, sesiones estratégicas, lluvia de ideas, prácticas ágiles (planificación, retrospectivas).

Lidero el desarrollo en Miro. Crecí en Perm y sigo viviendo aquí. Históricamente, la empresa apareció en Perm, de donde proceden nuestros fundadores. La mayor parte de nuestro departamento de desarrollo ya está aquí, y en 2019 lanzamos y estamos desarrollando activamente una segunda oficina de ingeniería en Ámsterdam.
Anteriormente, trabajé en desarrollo personalizado: comencé construyendo almacenes de datos analíticos como desarrollador, luego los diseñé y luego dirigí grandes proyectos. En 2016 se incorporó a Miro cuando la empresa empleaba a 30 personas. Desde entonces hemos crecido mucho: ahora tenemos cinco oficinas, 400 personas, de las cuales 140 son ingenieros.
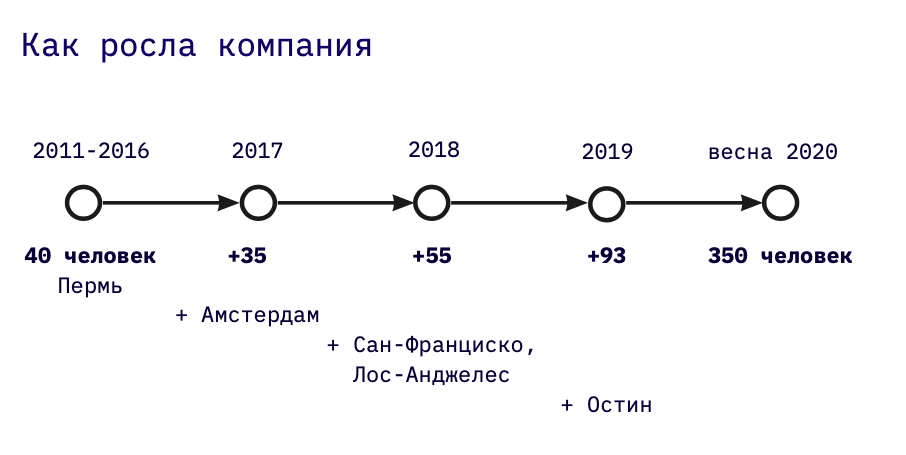
La empresa fue fundada en 2011. Nuestra principal función fue y sigue siendo el desarrollo de productos, que hoy representa aproximadamente la mitad de la empresa.
Cambio de nombre
Pensamos en cambiar la marca en 2015, pero terminamos haciéndolo en 2018. Nuestro nombre anterior RealtimeBoard es largo y complejo. A menudo se equivocaba, se abreviaba como RTB o, lo peor de todo, se olvidaba por completo. Además, no tiene emociones, no hay ninguna historia detrás. Queríamos que el nuevo nombre fuera breve, espacioso, hablado y memorable.
Como resultado, nos inspiramos en las obras del artista Joan Miró y elegimos su apellido como título. La investigación en sí y la elección del nombre tomaron varios meses, y luego lanzamos una nueva marca durante varios meses. A raíz de este proyecto, hay una serie de artículos sobre cómo se organizó el trabajo en el proyecto, y un artículo separado sobre una tarea técnica pequeña pero no trivial para la migración sin problemas de usuarios autorizados del antiguo al nuevo dominio.
Tanto nosotros como los usuarios nos acostumbramos rápidamente al nuevo nombre. Estamos creciendo rápidamente, por lo que varios millones de nuevos usuarios ni siquiera saben que nos llamaron de manera diferente. Una buena ventaja del cambio de marca fueron los premios de los European Design Awards por la identidad, que desarrollamos como parte del cambio de marca junto con la agencia europea Vruchtvlees .
Cómo funciona el desarrollo de productos en Miro
Todo el equipo de desarrollo de productos de 170 personas se encuentra en Perm y Amsterdam: ingenieros, productos, diseñadores de productos, scrum masters.
Antes me resultaba difícil imaginar que tanta gente pudiera trabajar en un producto. Pero hoy, sé que hay miles de ingenieros trabajando en el mismo producto en Uber, Slack y Atlassian. Seguimos creciendo y entendemos que claramente no somos suficientes ahora, y el próximo objetivo en mi cabeza son 300 personas en desarrollo, y luego continuaremos creciendo más. No es solo un número fuera de tu cabeza. Tenemos planificación estratégica, entendemos dónde queremos estar en dos años, en cinco años y qué debemos hacer para ello.
En términos de estructura organizativa, hay gremios: frontend, backend, QA, etc. Para trabajar en proyectos, se combinan en equipos multifuncionales.
Los equipos se distribuyen en áreas clave:
- El producto horizontal es la principal funcionalidad del producto que ven todos los usuarios: pegatinas, texto, formas, marcos, etc.
- Dirección de sistemas : responsable de la plataforma central y la infraestructura.
- Crecimiento : todo sobre el crecimiento del número de usuarios: activación, participación, retorno, monetización.
- Enterprise — , . -, Miro, . -, SaaS-, . , , .
- — 2019 . API, , marketplace, — , , .
- — , . , , , Miro, : Meetings & Workshops, Ideation & Brainstorming, Research & Design, Agile Workflows, Strategy & Planning, Mapping & Diagramming.
: , , . , . , : - .
El software principal de los ingenieros: IntelliJ Idea, Jira, Slack, Zoom, Miro, Confluence. La mayoría de los empleados trabajan en MacBooks, la mayoría de los ingenieros trabajan en MacBook Pros y, para algunos, compramos máquinas más potentes cuando es necesario.
Usamos nuestro propio producto todos los días: reuniones internas, talleres, sesiones de lluvia de ideas, planificación.Esto le permite probar rápidamente todas las innovaciones del producto y simplifica enormemente la adaptación de los nuevos desarrolladores que, desde el primer día, trabajan con el producto no solo en términos de código, sino también como usuarios. Esta es una parte importante de nuestra cultura: hacemos un producto que nosotros mismos deberíamos ser cómodos y agradables de usar.
Pila, monolito
El frente es Typecript, React y AngularJS. El backend es Java. Bases de datos: Redis, Postgres, para comunicación de clústeres: Hazelcast y ActiveMQ. Hospedamos en Amazon, en el mismo centro de datos. Hay unos 400 servidores en producción. Los servidores de aplicaciones que procesan tableros de usuarios pueden ser de hasta 100, todo se organiza automáticamente.
Usamos una pila de Atlassian: Jira, Bitbucket, Bamboo y nuestros propios scripts que están atornillados a Bamboo y permiten que todo se implemente en los servidores. Hasta ahora, todos los lanzamientos son un gran lanzamiento frontal y un gran lanzamiento posterior. Ahora estamos pensando en cómo hacer más de estos lanzamientos.
Nuestra aplicación principal es un monolito modular: hay un módulo que se encarga de la API, de la placa, de la función de servicio. El monolito se despliega en módulos a los servidores requeridos, y no en una gran parte a todos los servidores seguidos, es decir, también tenemos servidores con diferentes roles.
Dentro de la aplicación, hay muchas integraciones y servicios adicionales que hicimos inmediatamente por separado y que los equipos lanzan de forma independiente por separado del resto del anverso y el reverso.
Cuando tienes una empresa pequeña, es mucho más fácil comenzar con un monolito y no cercar la infraestructura para los servicios. Pero ahora hemos llegado a comprender que un monolito común no nos da la capacidad de escalar direcciones individuales (producto horizontal, plataforma, empresa, etc.), por lo que estamos desarrollando un enfoque para dejar un solo monolito.
Lanzamientos
El montaje en sí toma de 15 a 20 minutos, incluida la ejecución de pruebas unitarias. Las pruebas de un extremo a otro pueden tardar hasta 40 minutos. Todo el proceso lleva de una hora y media a dos horas para que el maestro se libere. Esto es mucho tiempo, todavía tenemos algo en lo que trabajar aquí.
Probablemente sea ideal lanzarlo cada cinco minutos. Pero para ello todavía no tenemos un equipo tan grande ni una audiencia diaria tan numerosa. Una gran audiencia es importante para los lanzamientos frecuentes, ya que le permite asegurarse rápidamente de que todo está bien implementando cambios en una pequeña proporción de usuarios.
Selección y evolución de tecnología
Creo que la elección de la tecnología debe tratarse así: no importa lo que elijas, todavía tienes que cambiarlo algún día, especialmente si la empresa y el producto crecen. Por tanto, el proceso de cambio de tecnologías es normal. La tecnología es importante, pero debe tratarse de manera diferente en las diferentes etapas del desarrollo de una empresa.
Las pequeñas empresas que recién están comenzando y buscan productos que se ajusten al mercado corren rápido, crean MVP rápidamente y los desechan rápidamente. Encontrar un mercado es más importante para ellos que crear soluciones técnicas complejas. Pero cuando se encuentra el mercado, las soluciones técnicas pasan a primer plano, porque le permiten crear un margen de seguridad para el crecimiento y la seguridad.
Primero tratamos de comprender el problema que queremos resolver cambiando de tecnología. Luego investigamos mucho, exploramos alternativas, probamos el desempeño. Esto se hace con las soluciones técnicas que vayamos a implementar: “no tomes lo primero que escuchaste en el mercado, sino investiga y estudia lo que es más adecuado para resolver el problema”.
En un producto grande y en un equipo, un cambio en la tecnología es una decisión estratégica importante; puede llevar a una interrupción parcial o total en el desarrollo del producto, un cambio de equipos a nuevas tareas, etc. Es largo y caro, pero si no se hace a tiempo, los problemas que aparecen pueden traer muchas más dificultades.
Hemos tenido algunos grandes cambios tecnológicos, en la parte delantera y trasera. Aquí hay unos ejemplos.
Flash → Lienzo
Hasta 2015, todo el frente estaba en Flash, luego Flash comenzó a morir y cambiamos a HTML y Canvas. El cambio de pila tuvo un buen efecto en el rendimiento y la usabilidad del producto y condujo a un aumento notable en la audiencia. La transición tomó alrededor de un año, fue un proyecto grande y complejo. Un artículo sobre los detalles de este proyecto .
Actualmente estamos considerando migrar a WebGL, pero aún no hay evidencia clara de que valga la pena.
Angular → Reaccionar
En los últimos años, nos hemos movido gradualmente de Angular JS a React. Razones principales:
- React permite escribir mejor, y luego permite una mejor refactorización del código y asegura que nada se caiga.
- React . «» , Angular . Angular, React, .
- React , Angular JS .
En 2015, pasamos de los servidores arrendados de Hetzner al hosting de Amazon. Durante más de un año, ha habido un proyecto para migrar la base de datos principal de Redis a PostgreSQL. Tenemos artículos sobre esto: gestión de proyectos de migración de datos , creación de un clúster de conmutación por error .
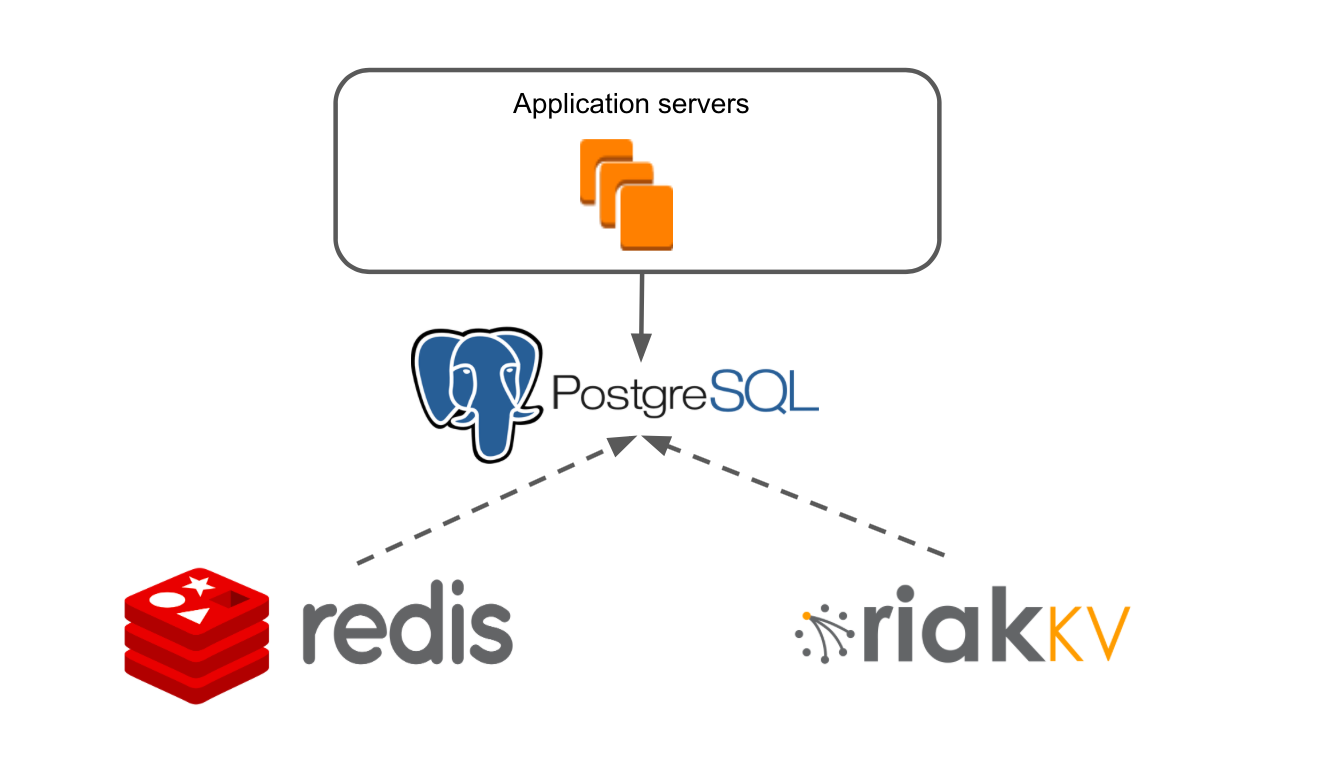
Nuestro caso se complica por el hecho de que desde el valor clave del almacenamiento nos estamos moviendo a una base de datos SQL. Hay mucha refactorización. Es importante hacer todo lo posible para que la aplicación no se detenga. Es como cambiar la rueda de un automóvil en movimiento, porque la base de datos es la base sobre la que se basa la aplicación. Para el contenido de los tableros, en realidad hicimos todo sin mantenimiento. Sí, el proceso de transición se retrasó, pero los usuarios no notaron nada, el producto funcionó.
La estabilidad del producto es un aspecto clave. Los usuarios almacenan mucho contenido en Miro. En consecuencia, si un usuario ha programado una sesión o reunión, ha preparado un tablero de contenido para ello y el producto no está disponible en ese momento, esto es un error, el contenido no se puede utilizar. Si bien el Zoom condicional se puede reemplazar rápidamente con Hangouts, el contenido no se puede reemplazar rápidamente. Por lo tanto, una de nuestras tareas clave es garantizar que el contenido para los usuarios esté siempre disponible.
Java
Java nos ayuda enormemente en términos de productividad y recursos para desarrolladores que podemos encontrar. Sé que Booking está cambiando de Pearl a Java porque están cansados de volver a capacitar a sus ingenieros.
Los ingenieros de C ++ y .Net vienen a nosotros y se adaptan normalmente. Si es un desarrollador experimentado, ha probado diferentes tecnologías y sabe cómo se construye el sistema, entonces no es tan difícil sumergirse en un nuevo idioma. Lo principal es que al ingeniero se le ocurren las soluciones adecuadas, y definitivamente podrá enterrarse en el idioma, creo en esto.
Prueba de evolución
Inicialmente, solo teníamos pruebas manuales. Los lanzamientos se implementaron cada dos o tres semanas, la preparación para el lanzamiento tomó una semana: realiza pruebas de regresión en unos pocos días → encuentra errores críticos → corrige → prueba manual nuevamente. Cuando había varios equipos, funcionaba, pero con veinte equipos es imposible probar todo manualmente.
Entonces comenzamos a pensar en la automatización. En primer lugar, escribimos pruebas automáticas para deshacernos por completo de las pruebas de regresión. Ahora estamos trabajando para configurar los procesos de gestión de calidad correctos a lo largo de todo el ciclo de desarrollo. Cuanto antes pensemos en la calidad, antes encontraremos casos extremos, entenderemos cómo probarlos; esto finalmente reducirá el costo y acelerará el proceso de desarrollo. Un error que encuentra a la venta no solo vale la pena el tiempo y los recursos para revertir la versión y solucionarlo. El error afecta la experiencia general del usuario del producto y es muy costoso arreglar esa experiencia.
Tenemos un gremio de QA, en el que los ingenieros toman decisiones sobre qué procesos necesitamos implementar ahora, desarrollan una estrategia de calidad y luego cada ingeniero de QA ayuda a sus equipos a implementar estos procesos en sí mismos:
- QA- -, . QA , . .
- QA , .
- QA , , .
Los lanzamientos de Canary también son una forma de prueba, cuando lanzamos una función a una audiencia pequeña y verificamos si nos hemos perdido algo. Lanzamos grandes funciones nuevas a través de casillas de verificación, las implementamos para usuarios beta que han expresado su deseo de participar en las pruebas beta (nuestros gerentes de producto se enterarán durante las entrevistas de investigación). La cantidad de usuarios beta y alfa incluye necesariamente a nuestros equipos; en primer lugar, implementamos absolutamente todas las funciones nuevas para nosotros.
Una descripción detallada de todas las etapas de nuestro proceso de control de calidad .
Crecimiento de carga y refactorización
Debido al cambio masivo al teletrabajo en 2020, nuestra base de usuarios se ha disparado y nuestra infraestructura anual y la capacidad de recuperación de las aplicaciones se agotaron en unas pocas semanas. En la primera semana de un fuerte aumento en la carga, detuvimos todo el desarrollo de productos y reorientamos los equipos para trabajar en la tolerancia a fallas y el rendimiento.
El margen de seguridad era necesario no solo en el backend, sino también en el front-end y el cliente, ya que la cantidad de trabajos sincrónicos aumentaba en el producto. Si antes 20 personas podían trabajar en un tablero al mismo tiempo, ahora son 300 personas. Nuestros ingenieros de front-end han hecho mucho y continúan abordando el rendimiento de carga. Por ejemplo, hacemos que el tablero con la lista de tableros se cargue por separado de todo lo demás y lo hacemos más rápido que antes. Y si el usuario va directamente al tablero, no a través del tablero, entonces se debe cargar el código y el contenido del tablero, sin todo lo demás.
Refactorizaremos mucho para que el usuario obtenga comentarios y contenido del tablero más rápido, y luego toda la funcionalidad principal (scripts, la interfaz) aumenta lentamente. Para hacer esto, cambiamos a dividir el código en módulos "perezosos". Gracias a esto, hemos acelerado en aproximadamente un tercio, y en el próximo mes planeamos duplicar la velocidad en términos de carga.
Es lo mismo en términos de rendimiento en la placa: hay una guerra por la velocidad y los recursos en la computadora en la que se ejecuta el usuario.No todo el mundo se conectaba a Internet con buenas máquinas; alguien sacó del estante una vieja computadora portátil de bajo rendimiento. Pero nuestro producto debería funcionar bien en cualquier portátil. Este es otro gran truco en el que estamos trabajando mucho en este momento.
Procesos en desarrollo
Revisión de código y solución técnica
Cualquier tarea comienza con la preparación de una solución de producto. Una solución de producto es una respuesta a la pregunta "¿Qué vamos a hacer?". Un gerente de producto basado en la estrategia del producto y los OKR está investigando mucho para descubrir qué les falta a los usuarios en nuestro producto. Basado en la investigación, el producto describe la solución. El gremio de alimentos discute la solución y la revisa si es necesario.
Sobre la base de una solución de producto, se forma una solución técnica que responde a la pregunta "¿Cómo vamos a hacer esto?" Está desarrollado por los ingenieros del equipo que implementará la funcionalidad. La solución técnica pasa por varios procesos de revisión:
- con equipos con los que hay intersecciones en funcionalidad;
- revisión de seguridad de los componentes que tocaremos en la arquitectura;
- cómo implementaremos el resultado.
Después de eso, comienza el desarrollo en sí. Es importante que la revisión de código no ralentice el desarrollo, por lo que recientemente, en lugar de la recepción obligatoria de dos revisiones de código, introdujimos la responsabilidad personal a nivel de componente. Ahora, a nivel de código, siempre sabemos quién es el responsable de esta pieza, lo que facilita enormemente la comunicación durante el desarrollo. En consecuencia, tan pronto como haya realizado cambios en el código, se asignará automáticamente al revisor el propietario de este código. Si el código es suyo, entonces un miembro de su equipo hace la revisión.
¿Por qué introdujimos la responsabilidad personal? Solía haber algunas personas, "viejos", que sabían cómo funcionaba todo el producto y podían verificar cualquier fragmento de código. Pero a medida que el producto crecía, las capacidades de estas personas comenzaron a faltar, ya no podían saber todo lo que estaba sucediendo en el desarrollo.El proceso de revisión del código comenzó a ralentizar el resto del proceso, no estaba claro a quién acudir para revisar el código. Luego comenzamos a traer toda la competencia necesaria para bloques de productos específicos al equipo que trabaja en ellos. De modo que los equipos pudieron realizar revisiones de códigos por su cuenta. En un momento, esto nos ayudó a acelerar mucho.
Revisión de desempeño
La empresa tiene grados, gracias a los cuales entendemos quién tiene qué competencias, a qué grado corresponden y, lo más importante, qué deben hacer todos para avanzar. La revisión de desempeño se lleva a cabo dos veces al año, ayuda a capturar una imagen de dónde se encuentra cada persona ahora y recibe comentarios personalizados.
Con base en esta imagen, el líder del equipo forma planes de desarrollo personal con cada miembro del equipo: el empleado mismo dice dónde quiere desarrollarse y la Revisión de desempeño destaca sus fortalezas y deficiencias.
Luego, regularmente, una vez cada una o dos semanas, el líder del equipo con el empleado lleva a cabo reuniones 1: 1, donde, entre otras cosas, discuten y hacen un seguimiento del movimiento en la dirección planificada. En año y medio, sobre la base de los resultados de este movimiento, hay un aumento de grado y salario.
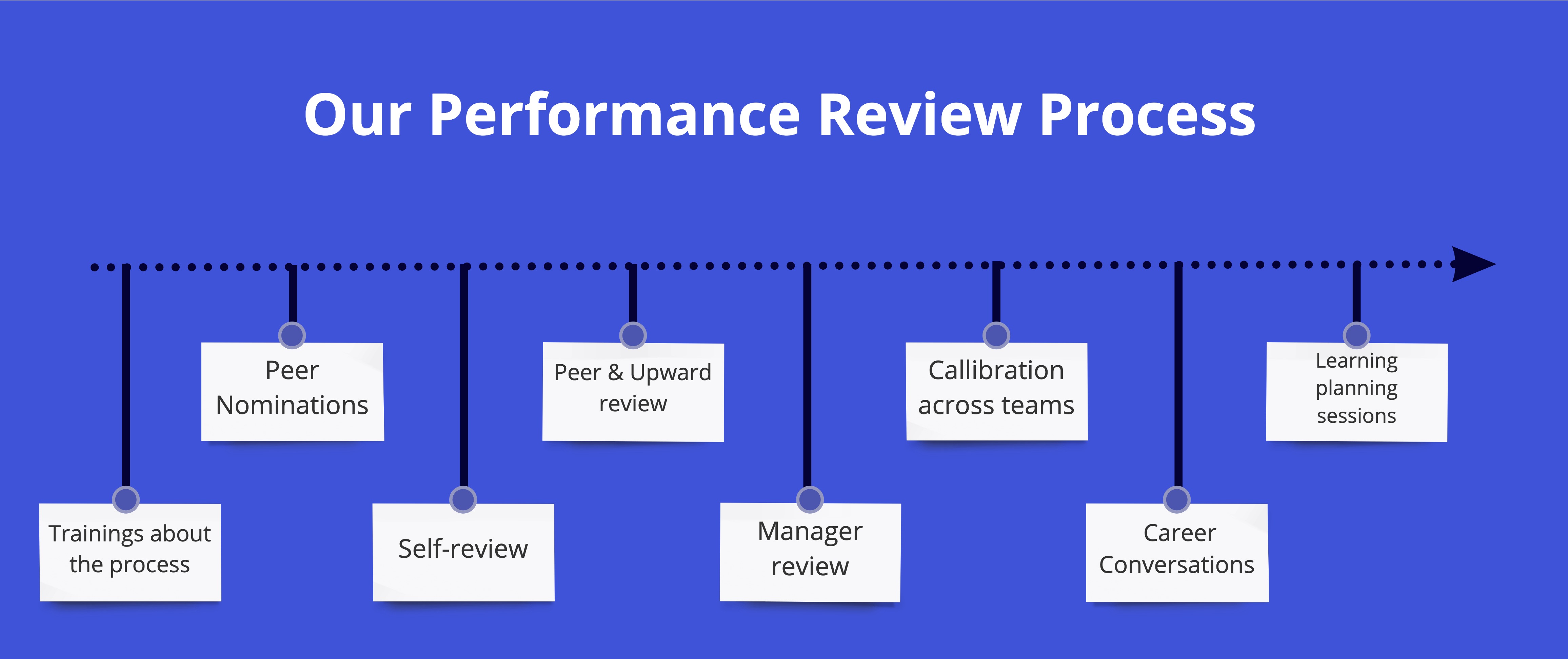
Todo es exactamente igual con los jefes de equipo, además hay formación externa y mentoría externa para ellos.
Desafortunadamente, las personas a menudo no crecen tan rápido como la empresa, eso está bien. Estamos dispuestos a invertir mucho en formación, porque el crecimiento de una empresa depende directamente del crecimiento de los empleados. Tenemos compensación por cursos externos, tenemos cursos recomendados y mentores. Compensamos la formación obligatoria al 100% (por ejemplo, inglés), tratamos de compensar el resto 50 a 50, para que exista una responsabilidad mutua por los resultados.
Rara vez vamos a conferencias. Intentamos elegir aquellos que hablan de tecnologías y casos que nos son relevantes en este momento y para los que no tenemos conocimientos suficientes.
Cómo funciona la contratación de ingenieros
Nuestra cadena de contratación es estándar para Rusia y Europa. En Rusia, el embudo de contratación ya es estrecho, por lo que la primera entrevista puede ser realizada no por un reclutador, sino por un gerente de contratación (generalmente el líder del equipo al que contratamos a una persona) después de que el reclutador haya procesado el currículum y eliminado las vacantes que no son adecuadas para los requisitos.
Tengo la sensación de que en Rusia hay muchos menos ingenieros que buscan trabajo activamente, en comparación con Europa, porque no quieren correr riesgos. Y cuando muchas empresas entraron en la zona de riesgo debido al aislamiento, la gente se volvió aún menos inclinada a correr riesgos y cambiar de trabajo.
De cualquier manera, la cadena de contratación comienza con una entrevista telefónica de selección con un candidato, que es realizada por un reclutador o gerente de contratación. El propósito de la selección es comprender rápidamente cómo un candidato se ajusta a los requisitos clave de la vacante.
Después de la selección, una tarea de prueba, luego una entrevista técnica, que incluye, entre otras cosas, una discusión sobre la tarea de prueba. Luego, una reunión con el equipo en el que trabajará el candidato. Para nosotros, este es un paso obligatorio, porque ayuda, en primer lugar, a comprender el encaje cultural del candidato, y no sus habilidades técnicas.
Después de todas las entrevistas, recopilamos los comentarios de los participantes y hacemos una oferta.
Para evaluar las tareas de prueba, usamos un sistema de puntos, luego clasificamos los resultados y así vemos los mejores resultados. En los puestos superiores, a veces cancelamos una tarea de prueba si el candidato tiene un buen repositorio público.
Posiciones junior
Antes de pasar al trabajo a distancia, comenzamos a trabajar con especialistas junior: contratamos a Juns, graduados, aunque no muy activamente. Ahora hemos congelado por completo esta historia, porque es muy difícil incorporarlos en una ubicación remota, y hasta ahora tenemos muy poca experiencia en esto. Por lo tanto, nos enfocamos en medianos con al menos 3-4 años de experiencia.
Pero incluso cuando trabajamos con Juniors, era importante para nosotros que pudieran crecer hasta la mitad de un año, para que pudieran aprender y adaptarse muy rápidamente.
Altos requisitos de contratación
Existe la leyenda de que es muy difícil para nosotros conseguir un trabajo debido a los altos requisitos. Esto no es enteramente verdad.
A menudo somos entrevistados por candidatos con el puesto de Team Lead, que según nuestro criterio interno son intermedios. Esto sucede porque, en busca de puestos, acuden a empresas que están dispuestas a ceder puestos por encima de sus competencias actuales en varios pasos, solo para contratar a una persona. Como resultado, el resultado es un flaco favor: la persona aún no se ha bombeado al nivel requerido, pero ya ocupa una posición alta; entonces difícilmente podrá dejar la empresa, porque no será contratado para el mismo puesto en otras empresas.
El mayor obstáculo en la contratación es el inglés. Antes podíamos contratar sin conocimientos de inglés, pero ahora esto es imposible, y es imposible bombearlo en unos meses: un ingeniero de las primeras semanas de trabajo deberá leer la documentación en inglés, corresponder en inglés con colegas, asistir a juntas generales, la mayoría de las cuales se realizan en inglés. idioma.
El producto está creciendo, aparecen nuevas tareas interesantes, por lo que siempre tenemos muchos puestos vacantes en ingeniería tanto en Perm como en Amsterdam.