Decidí crear la multisesión a partir de grabaciones de audio acumuladas durante un mes calendario para evitar el desorden innecesario de Adobe Audition. Por supuesto, una sesión de este tipo se puede construir manualmente, pero es un trabajo largo y laborioso. El principal interés de esta tarea es automatizar la construcción de una multisesión por software. Más precisamente, escriba un programa que, basándose en una lista de archivos de grabación de audio, genere un archivo SES para una multisesión de Adobe Audition. Para los que no lo saben: una multisesión, en definitiva, es un proyecto que consta de muchas grabaciones de audio diferentes distribuidas en el tiempo y sobre pistas (tracks) y diseñadas para crear una mezcla a partir de ellas.
Primero que nada, vale la pena discutir cómo obtengo las grabaciones de audio de las conversaciones telefónicas. No es ningún secreto que los teléfonos inteligentes modernos tienen la capacidad de grabar llamadas telefónicas con varias herramientas, tanto integradas en el sistema como de terceros. Personalmente, uso una tableta Lenovo TAB3 (con procesador MT8735P). El dispositivo permite realizar grabaciones de audio en modo manual en formato comprimido, recibiendo archivos con la extensión 3gpp. Las grabaciones se obtienen en estéreo con canales separados: en un canal, se graba la voz del suscriptor y en el otro, su propia voz. El formato comprimido de las grabaciones de audio afecta su distorsión durante la reproducción. Debido a esto, utilizo aplicaciones de grabación de audio de terceros, de las cuales hay innumerables. Una de las aplicaciones que más me gustó es “Grabar mi llamada”.Esta aplicación graba llamadas en modo automático, tiene muchos ajustes relacionados, en particular, con la elección del formato y la calidad de la grabación de audio. Y también, como beneficio adicional, la aplicación tiene un registro de llamadas incorporado muy conveniente, que se guarda en el archivo de base de datos db (Fig. 1).
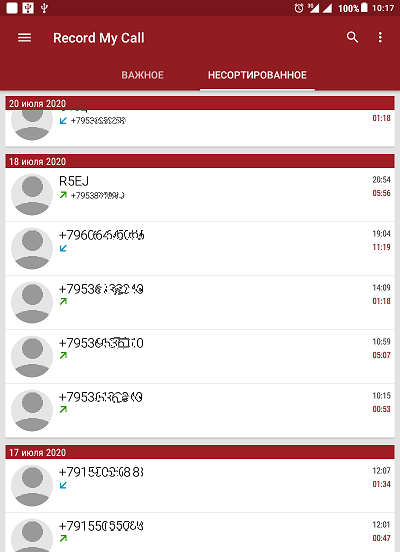
Figura: 1. Registro de llamadas en la aplicación "Grabar mi llamada".
Los mejores parámetros de grabación de audio para la calidad del sonido son WAV 8000Hz 16bit Stereo. Con tales configuraciones, la grabación no tiene distorsiones, suena claro, aunque ocupa más espacio en la memoria. La aplicación está configurada de tal manera que la grabación de audio se inicia automáticamente incluso antes del inicio de una conversación telefónica: cuando llega una llamada entrante antes de “levantar el auricular” o al marcar un número durante los pitidos. Es decir, también se registran las llamadas perdidas y no contestadas. Puede configurarse para grabar solo la conversación. El formato del nombre del archivo de grabación de audio también se puede configurar. En mi caso, lo configuré como se muestra en la Figura 2.
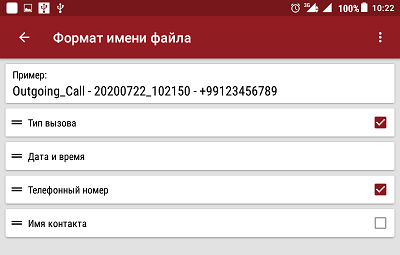
Fig. 2. Configurar el formato del nombre de archivo en "Grabar mi llamada".
Durante el desarrollo del programa de generación multisesión, será necesario tomar información sobre la fecha y hora de la grabación de audio de la llamada telefónica. Esta información se tomará del nombre del archivo en posiciones fijas.
Antes de comenzar a crear un archivo SES multisesión, debe comprender cómo funciona dicho archivo. Por supuesto, no hay documentación sobre este formato en ninguna parte, así que tuve que resolverlo por mi cuenta, confiando en la experiencia y el conocimiento personal. Este archivo no es un archivo de texto, por lo que tiene poco sentido abrirlo en el Bloc de notas. "WinHex": un editor hexadecimal viene al rescate. Ya he escrito varios artículos sobre cómo trabajar con datos binarios y descifrar información, en particular, un artículo sobre cómo escribir un programa de reempaquetado de video 264-avi. Allí escribí más o menos en detalle sobre el dispositivo del archivo avi.
Primero, creé una simple multisesión arbitraria en Adobe Audition 1.5, que consta de una pista y un archivo de audio (Fig. 3), guardándola en un archivo con la extensión ses. El archivo tiene un tamaño de 2422 bytes. Luego abrí este archivo en WinHex (Fig. 4).
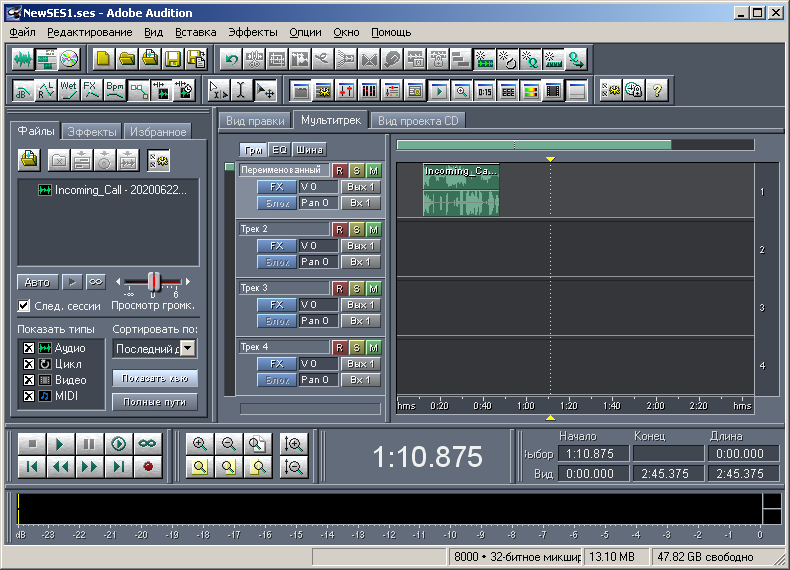
Figura: 3. Vista de multisesión en Adobe Audition 1.5 - Ejemplo 1.
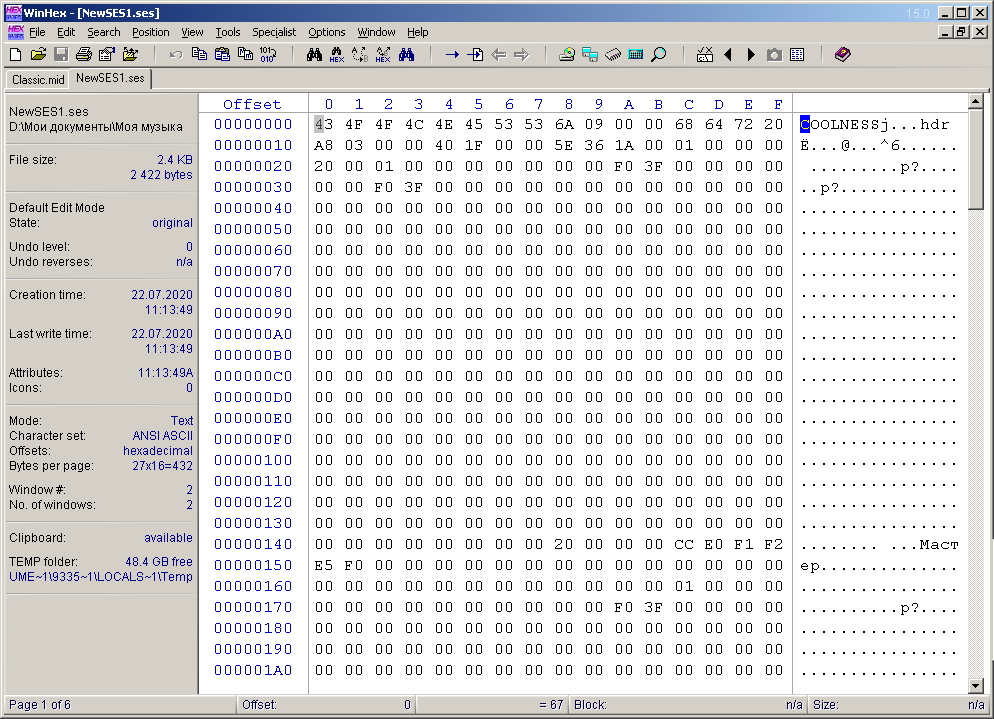
Fig. 4. Archivo multisesión abierto en WinHex.
A primera vista, nada está claro en absoluto. En la parte simbólica de la ventana, puede ver las palabras semánticas "COOLNESS", "hdr", "Master". Si se desplaza por el documento a continuación, puede ver el texto que contiene la ruta completa al archivo (y, en dos versiones), que se utiliza en la multisesión. Esto se muestra en la Figura 5 y se describe en verde. Inmediatamente llama la atención las palabras semánticas cortas encerradas en un círculo en un marco rojo en la misma figura.
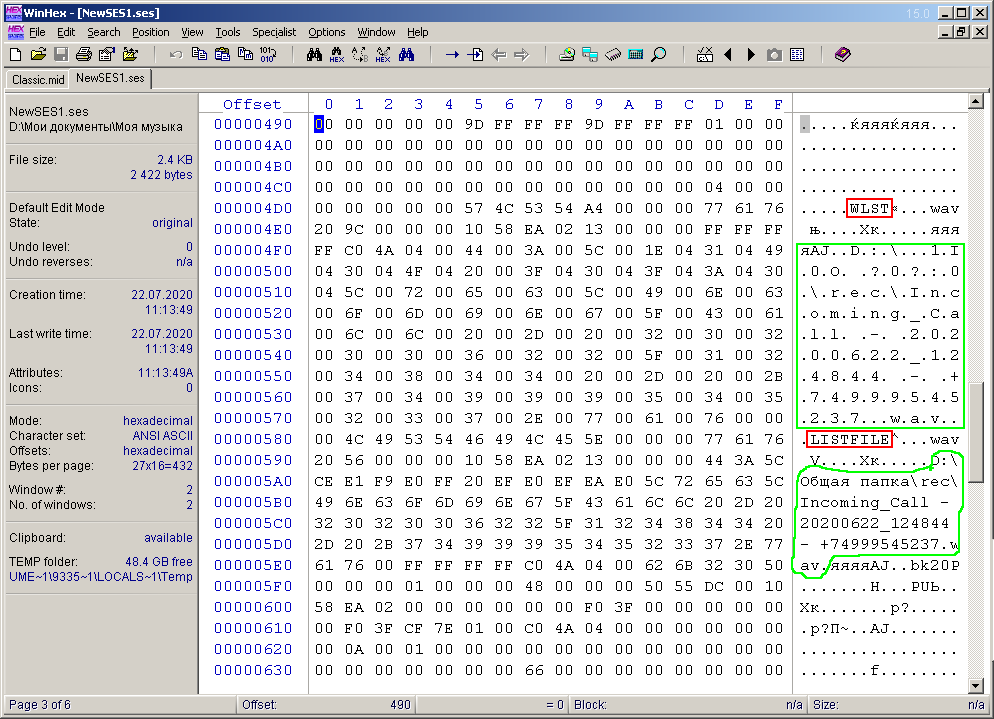
Figura: 5. Bytes de rutas a archivos de audio multisesión.
Mirando más de cerca este documento de principio a fin, noté algunas otras palabras semánticas cortas. También noté que la longitud de cualquier palabra significativa es múltiplo de cuatro. Aparentemente, estas palabras son las cabeceras de los bloques que componen todo el archivo multisesión. Me recordó a la estructura RIFF de un archivo avi o wav que consta de bloques que también tienen encabezados del mismo tamaño. Estos encabezados fueron seguidos por un número de 32 bits (4 bytes) que indica el tamaño del bloque actual. Con este hecho en mente, decidí verificar si este principio funciona para el archivo ses. Resultó que en el caso del formato ses, esto también funciona (fig. 6).
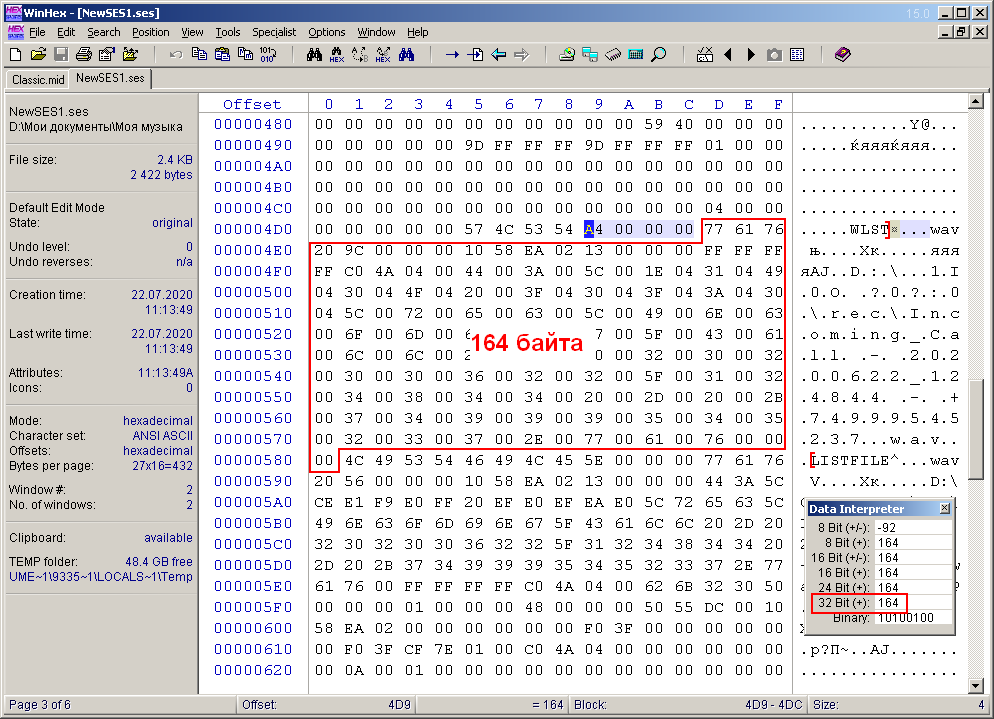
Figura: 6. Similitud con la estructura RIFF (por ejemplo, el bloque "WLST").
La primera palabra "COOLNESS" en el archivo ses parece ser el encabezado principal y el tipo de este archivo. Los siguientes 4 bytes son el tamaño del contenido que se coloca a continuación, hasta el final del archivo. Es decir, si calcula con cuidado, este valor es 12 bytes menos que el tamaño de todo el archivo. Y el contenido adicional consiste en una colección de diferentes bloques. Un bloque tiene un encabezado de cuatro u ocho bytes, seguido de 4 bytes que indican el tamaño de este bloque, y después de ellos sigue el contenido de este bloque. En algunos bloques, identifiqué la presencia de subbloques, pero esto se discutirá en el transcurso de una descripción más detallada de cada bloque. En este archivo, que en el ejemplo conté 17 bloques, están listados en la tabla de la Figura 7.
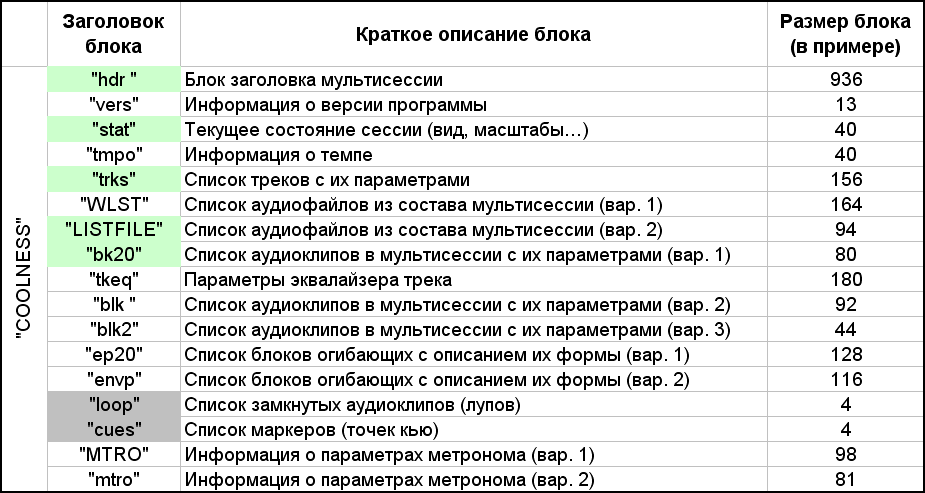
Fig. 7. Lista de bloques que componen la multisesión.
Como puede ver en la tabla, parte de la misma información se presenta en diferentes versiones por diferentes bloques. Probablemente esto se haga para la compatibilidad de diferentes versiones del programa. De cara al futuro, esos bloques están resaltados en verde, sin los cuales la multisesión presentada en el ejemplo no puede existir. Dos bloques de 4 bytes están resaltados en gris, que son ficticios en esta sesión. De hecho, tenía una pregunta: ¿qué pasará si eliminas algunos de los bloques del archivo? Después de todo, yo, por ejemplo, no necesito información sobre el metrónomo y el tempo, y las envolventes en los clips (más precisamente, en un clip) faltan en mi ejemplo simple. Las envolventes son curvas en la parte superior de un clip de audio que establecen la dinámica de los parámetros de sonido (volumen, balance) a lo largo del tiempo. Comencé secuencialmente a cortar bloques del archivo dado,sin olvidar recalcular y corregir el valor después de la palabra "COOLNESS". Como resultado, la multisesión se abrió con éxito con al menos cinco bloques resaltados en verde. La sesión contiene dos bloques de la lista de archivos de audio. Cualquiera de ellos podría quedarse. Prefiero la segunda opción (el bloque "LISTFILE"), ya que en la primera opción (el bloque "WLST") hay dos bytes por carácter en la descripción de la ruta del archivo. Es posible que esto se haya hecho para un alfabeto de caracteres extendido, pero el alfabeto ASCII estándar es suficiente para mí. Además, los caracteres rusos, como puede ver, están bien soportados. La descripción de los clips de audio se presenta en tres versiones. Elegí la primera opción (bloque "bk20"), porque descubrí su descripción más rápido.La sesión contiene dos bloques de la lista de archivos de audio. Cualquiera de ellos podría quedarse. Prefiero la segunda opción (el bloque "LISTFILE"), ya que en la primera opción (el bloque "WLST") hay dos bytes por carácter en la descripción de la ruta del archivo. Es posible que esto se haya hecho para el alfabeto de caracteres extendido, pero el alfabeto ASCII estándar es suficiente para mí. Además, los caracteres rusos, como puede ver, están bien soportados. La descripción de los clips de audio se presenta en tres versiones. Elegí la primera opción (bloque "bk20"), porque descubrí su descripción más rápido.La sesión contiene dos bloques de la lista de archivos de audio. Cualquiera de ellos podría quedarse. Prefiero la segunda opción (el bloque "LISTFILE"), ya que en la primera opción (el bloque "WLST") hay dos bytes por carácter en la descripción de la ruta del archivo. Es posible que esto se haya hecho para un alfabeto de caracteres extendido, pero el alfabeto ASCII estándar es suficiente para mí. Además, los caracteres rusos, como puede ver, están bien soportados. Las descripciones de los clips de audio se presentan en tres versiones. Elegí la primera opción (bloque "bk20"), porque descubrí su descripción más rápido.pero el alfabeto ASCII estándar es suficiente para mí. Además, los caracteres rusos, como puede ver, están bien soportados. La descripción de los clips de audio se presenta en tres versiones. Elegí la primera opción (bloque "bk20"), porque descubrí su descripción más rápido.pero el alfabeto ASCII estándar es suficiente para mí. Además, los caracteres rusos, como puede ver, están bien soportados. La descripción de los clips de audio se presenta en tres versiones. Elegí la primera opción (bloque "bk20"), porque descubrí su descripción más rápido.
Una multisesión de grabaciones de audio de conversaciones telefónicas será similar en complejidad a la multisesión presentada en este ejemplo. La única diferencia es que será más voluminosa: la cantidad de archivos de audio será bastante grande y la cantidad de pistas será igual a la cantidad de días en un mes. Para tal multisesión, no se necesitan otras "campanas y silbidos". Los tamaños de bloque "hdr" y "stat" son estáticos y siempre son de 936 y 40 bytes, respectivamente, independientemente del tamaño de la multisesión. Los tamaños de los bloques "trks" y "bk20" dependen del número de pistas y clips de audio en la multisesión, respectivamente. Pero el tamaño del bloque "LISTFILE" es el más impredecible: depende no solo del número de archivos de audio en la multisesión, sino también de la longitud de sus nombres y sus rutas de ubicación.
Descifrar y componer una descripción completa de los bloques de un archivo multisesión es una tarea bastante laboriosa. Por lo tanto, decodifiqué parcialmente la información, prestando atención solo a aquellas secciones de bytes que deben tenerse en cuenta al formar una multisesión de contenido simplificado. En este artículo, proporcionaré una descripción del contenido de cada bloque, que pude descifrar.
En el contenido del bloque de encabezado multisesión "hdr" (hay un espacio al final), los bytes clave son los primeros 12 bytes, es decir, 3 palabras de 4 bytes cada una (Fig. 8). La primera palabra es la tasa de muestreo de muestras en una multisesión. Para mi multisesión, este valor es 8000 Hz (0x1F40). En la Figura 8 está resaltado con relleno verde. Permítame recordarle que los bytes en palabras para valores numéricos se leen al revés. La segunda palabra es la duración (longitud) de la multisesión, expresada en el número de muestras (relleno de naranja en la figura). En este ejemplo, este valor es 0x1A365E (1717854). Si se traduce a minutos, obtiene 1717854/8000/60, que es aproximadamente tres minutos y medio. Y así es: en una escala mínima, una multisesión tiene exactamente esta duración.Y para una sesión múltiple de registros de llamadas telefónicas, la duración debe ser de un día, o 24 * 3600 * 8000 = 691200000 = 0x2932E000 muestras. En esta situación, por cierto, el tiempo de reproducción actual de la multisesión en el panel de abajo, que es el tiempo relativo, coincidirá exactamente con el valor del tiempo absoluto de la llamada telefónica actual (o un grupo de llamadas por día). La siguiente palabra resaltada en amarillo indica la cantidad de clips de audio en la multisesión. En el ejemplo, este valor es igual a uno, pero en el caso de las llamadas telefónicas, el número de dichos clips será igual al número de archivos de audio. De cara al futuro, la última afirmación no es del todo correcta. De hecho, la cantidad de clips de audio puede ser un poco mayor que la cantidad de archivos de audio. Un archivo puede tener dos clips en caso de quesi ha llegado un nuevo día durante una conversación telefónica. En este caso, tendrá que "transferir" la grabación a una nueva pista y un clip no funcionará. Pero estos casos son raros en la práctica, ya que la transición a un nuevo día se produce por la noche, cuando la actividad de las llamadas telefónicas es mínima. Por cierto, no tomé en cuenta este punto al crear el diagrama SVG en el artículo anterior. Después de la palabra del valor del número de bloques sigue, muy probablemente una "media palabra" de dos bytes 0x0020, o 32 en forma decimal. También podría resaltarse con un relleno de color, ya que, lo más probable, significa la profundidad de bits de la mezcla. En Adobe Audition, la barra de estado en la parte inferior dice: 8000 Hz, mezcla de 32 bits. Además de las tres palabras más esenciales del contenido "hdr", hay otros bytes oscuros. Por ejemplo, ni siquiera conozco la palabra "Maestro".a qué se refiere. Aparentemente, este es el nombre del bus de mezcla principal. Pero los grupos de bytes más interesantes los rodeé en un marco gris. El hecho es que esta secuencia se encuentra a menudo en otros bloques del archivo multisesión. No es casualidad que haya combinado exactamente 8 bytes en un grupo, ya que, muy probablemente, este es un tipo de datos real. En particular, esta constante "00 00 00 00 00 00 F0 3F" HEX por el editor en el tipo Doble se interpreta como 1.0e + 0, es decir, como una unidad. Lo más probable es que estos sean los valores de los niveles de sonoridad y otros "giros", pero no especificados en decibelios, sino en forma de coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.Pero los grupos de bytes más interesantes los rodeé en un marco gris. El hecho es que esta secuencia se encuentra a menudo en otros bloques del archivo multisesión. No es casualidad que haya combinado exactamente 8 bytes en un grupo, ya que, muy probablemente, este es un tipo de datos real. En particular, esta constante "00 00 00 00 00 00 F0 3F" HEX por el editor en el tipo Doble se interpreta como 1.0e + 0, es decir, como una unidad. Lo más probable es que estos sean los valores de los niveles de sonoridad y otros "giros", pero no se especifican en decibeles, sino en forma de coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.Pero los grupos de bytes más interesantes los rodeé en un marco gris. El hecho es que esta secuencia se encuentra a menudo en otros bloques del archivo multisesión. No es casualidad que haya combinado exactamente 8 bytes en un grupo, ya que, muy probablemente, este es un tipo de datos real. En particular, esta constante "00 00 00 00 00 00 F0 3F" HEX por el editor en el tipo Doble se interpreta como 1.0e + 0, es decir, como una unidad. Lo más probable es que estos sean los valores de los niveles de sonoridad y otros "giros", pero no especificados en decibelios, sino en forma de coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.No es casualidad que haya combinado exactamente 8 bytes en un grupo, ya que, muy probablemente, este es un tipo de datos real. En particular, esta constante "00 00 00 00 00 00 F0 3F" HEX por el editor en el tipo Double se interpreta como 1.0e + 0, es decir, como una unidad. Lo más probable es que estos sean los valores de los niveles de sonoridad y otros "giros", pero no se especifican en decibeles, sino en forma de coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.No es casualidad que haya combinado exactamente 8 bytes en un grupo, ya que, muy probablemente, este es un tipo de datos real. En particular, esta constante "00 00 00 00 00 00 F0 3F" HEX por el editor en el tipo Double se interpreta como 1.0e + 0, es decir, como una unidad. Lo más probable es que estos sean los valores de los niveles de sonoridad y otros "giros", pero no especificados en decibeles, sino en forma de coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.y como coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.y como coeficiente. Debo decir de inmediato que todos los bytes de cualquier bloque que no pude reconocer (o no eran necesarios) se escribirán en el archivo multisesión generado sin cambios, como en el ejemplo.
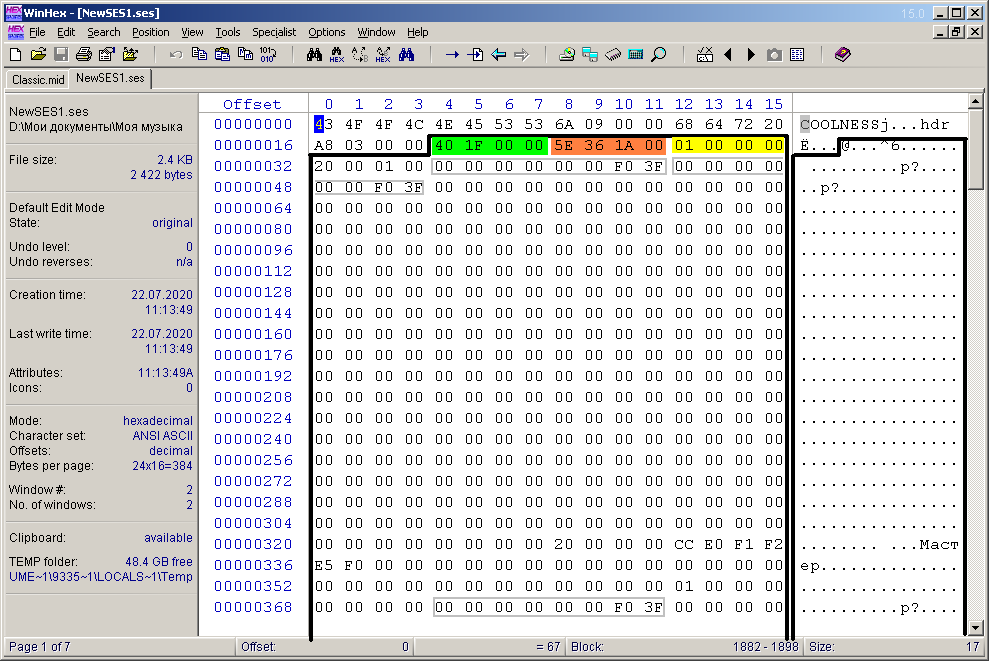
. 8. «hdr ».
Decidí no estudiar el bloque "stat" del estado multisesión actual (el más corto). Creé otra multisesión de muestra a partir de un archivo de audio, la estiré durante 24 horas y la hice vista completa (escala) horizontalmente. Y verticalmente, la vista de las pistas se escaló para que cuando se expandiera la ventana de Adobe Audition, caben 31 pistas en la pantalla FullHD. Este es el número máximo de días en un mes. El cursor multisesión se colocó al principio. Luego guardé esta multisesión en otro archivo y luego saqué el bloque "stat" con todos sus encabezados. Guardé estos bytes en el archivo "stat_31_full.BLK" para su uso posterior en el desarrollo del programa. La vista del contenido de dicho archivo se muestra en la Figura 9. El tamaño de este archivo era de 48 bytes (40 bytes del contenido del bloque + 4 bytes del encabezado + 4 bytes de la descripción del tamaño del contenido).
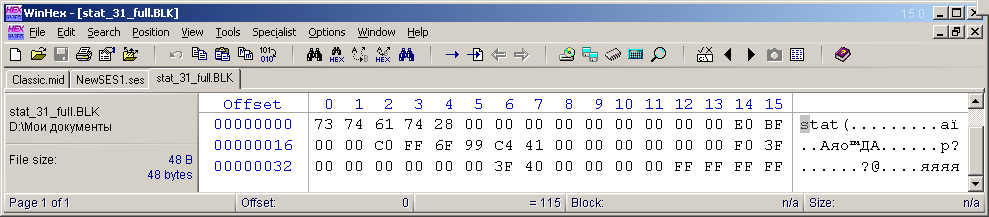
. 9. «stat» .
Para una descripción más visual de los siguientes tres bloques en el curso de la redacción de este artículo, decidí crear una multisesión más compleja, que consta de dos pistas, dos archivos y tres clips (Fig. 10). El primer archivo "Incoming_Call - 20200622_124844 - + 74999545237.wav" tiene una duración de 281280 muestras. El segundo archivo "Outgoing_Call - 20200621_231753 - + 79536170218.wav" tiene una duración de 63360 muestras. La primera pista denominada "First" (renombrada) contiene dos clips. El primer clip se desplaza desde el comienzo de la sesión en 10 segundos (en 80.000 muestras). El clip está representado por el contenido completo del primer archivo de audio, es decir, la duración del clip es la misma que la duración del archivo. El segundo clip se desplaza 50 segundos desde el comienzo de la sesión (50 * 8000 = 400000 muestras). El clip está representado por el contenido incompleto del segundo archivo de audio. Dentro de un clip determinado, el audio comienza desde el principio del archivo,pero solo dura 5 segundos (40.000 muestras). Es decir, la duración del clip es de 5 segundos. La segunda pista denominada "Second" contiene un clip. Se desplaza desde el inicio de la sesión en un segundo (en 8000 muestras). Este clip está representado por contenido incompleto del primer archivo de audio. Dentro de este clip, el audio no comienza desde el principio, sino después de 3 segundos, pero lo contiene hasta el final. Por lo tanto, el desplazamiento de los datos de audio dentro de este clip es de 3 segundos (24 000 muestras). Y la duración de un clip determinado se calcula como la diferencia entre la duración del audio correspondiente y el desplazamiento de los datos de audio dentro del clip. En este caso, la longitud del clip es 281280-24000 = 257280 muestras.Este clip está representado por contenido incompleto del primer archivo de audio. Dentro de este clip, el audio no comienza desde el principio, sino después de 3 segundos, pero lo contiene hasta el final. Por lo tanto, el desplazamiento de los datos de audio dentro de este clip es de 3 segundos (24 000 muestras). Y la duración de un clip determinado se calcula como la diferencia entre la duración del audio correspondiente y el desplazamiento de los datos de audio dentro del clip. En este caso, la longitud del clip es 281280-24000 = 257280 muestras.Este clip está representado por contenido incompleto del primer archivo de audio. Dentro de este clip, el audio no comienza desde el principio, sino después de 3 segundos, pero lo contiene hasta el final. Por lo tanto, el desplazamiento de los datos de audio dentro de este clip es de 3 segundos (24 000 muestras). Y la duración de un clip determinado se calcula como la diferencia entre la duración del audio correspondiente y el desplazamiento de los datos de audio dentro del clip. En este caso, la longitud del clip es 281280-24000 = 257280 muestras.En este caso, la longitud del clip es 281280-24000 = 257280 muestras.En este caso, la longitud del clip es 281280-24000 = 257280 muestras.
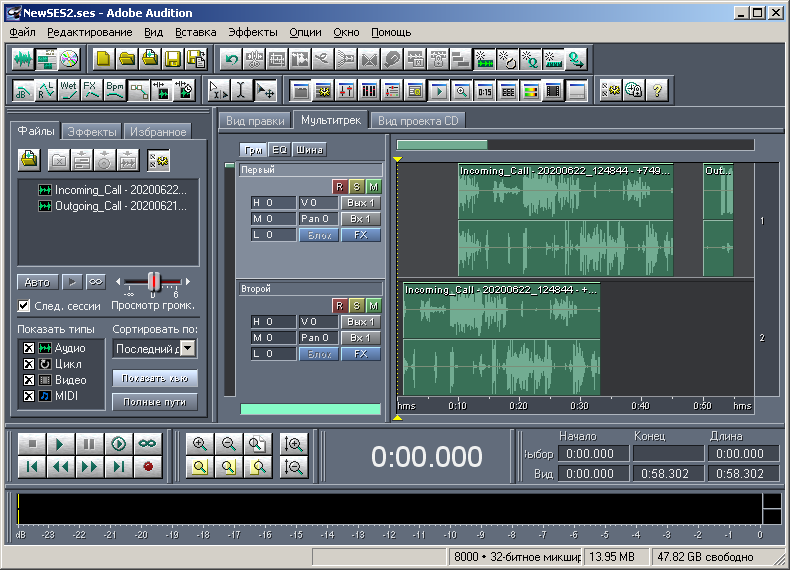
. 10. Adobe Audition 1.5 — 2.
La figura 11 muestra la vista del contenido del bloque de descripción de la pista "trks". Los 4 bytes del encabezado del bloque están resaltados en el marco rojo y el tamaño del contenido del bloque está en el verde. Esto ya se ha discutido anteriormente. Luego viene el contenido del bloque, cuyos bytes se resaltan en el editor WinHex con un característico relleno azulado. El tamaño de la selección, cuyo valor se muestra en la esquina inferior derecha del editor (también en un círculo verde), coincide con el valor de los bytes después del encabezado, y ya en este ejemplo es de 308 bytes. Si en el primer ejemplo (anterior) de una pista el tamaño del bloque era de 156 bytes, y en el actual - 308 bytes, entonces se puede sacar la siguiente conclusión. Debido al supuesto de homogeneidad y equivalencia de pistas, las áreas de descripción de cada pista deben tener el mismo tamaño. Estas áreas, por así decirlo, son sub-bloques del bloque "trks".Están delineados en azul en la figura. Resultó que el tamaño de uno de esos subbloques es de 152 bytes. Y al comienzo de los subbloques consecutivos hay un subtítulo de cuatro bytes, marcado en la figura con un relleno amarillo. Estos cuatro bytes no son más que el valor del número de pistas en una multisesión o el número de subbloques. Y así, el tamaño S del contenido del bloque "trks" se puede calcular mediante la fórmula S = 4 + 152 * n, donde n es el número de pistas en la sesión. Entonces es: 4 + 152 * 1 = 156 y 4 + 152 * 2 = 308.el tamaño S del contenido del bloque "trks" se puede calcular mediante la fórmula S = 4 + 152 * n, donde n es el número de pistas en la sesión. Entonces es: 4 + 152 * 1 = 156 y 4 + 152 * 2 = 308.el tamaño S del contenido del bloque "trks" se puede calcular mediante la fórmula S = 4 + 152 * n, donde n es el número de pistas en la sesión. Entonces es: 4 + 152 * 1 = 156 y 4 + 152 * 2 = 308.
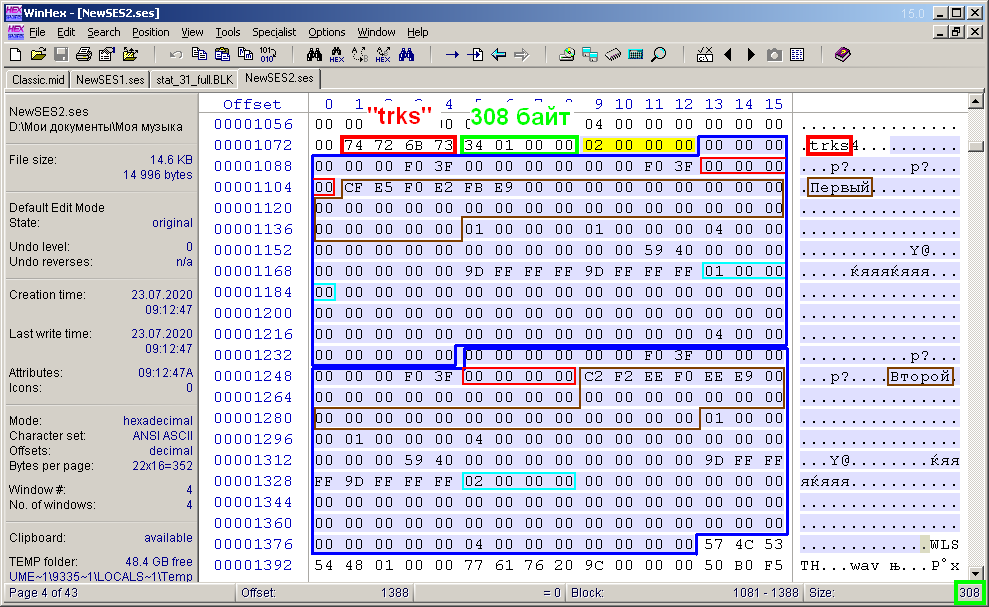
. 11. «trks».
Pasemos ahora a describir el contenido del subbloque. Hay mucho allí, pero solo he descifrado lo más esencial. Solo hay tres parámetros: 4 bytes de indicadores binarios (encerrados en un círculo en rojo), nombre de la pista (en un círculo en marrón) e ID de la pista (en un círculo en azul). El identificador de pista es su número de secuencia. Es necesario indicar un enlace a una pista en la descripción de los clips de audio (más sobre esto más adelante). El nombre de la pista ocupa un área de 36 bytes. Este es el número máximo de caracteres en el nombre de la pista, pero puede ser menor, como en el ejemplo actual. Los bytes no utilizados son cero. En una multisesión con grabaciones de audio de llamadas telefónicas, los nombres de las pistas coincidirán con la grabación de las fechas correspondientes. Puede agregar el día de la semana correspondiente junto a la fecha en dos letras mayúsculas en forma abreviada.Cuatro bytes de banderas binarias (32 banderas en total) están destinados a describir los parámetros binarios inherentes a la pista. De hecho, puede haber menos de 32. Decodifiqué solo una parte de las banderas. De estos, al menos tres banderas indican si la pista es “R” (Grabar), “S” (Solo) o “M” (Silenciar). En el ejemplo anterior, no se presiona ninguno de estos tres botones en las pistas y el valor de los indicadores binarios es cero (0x00000000). Pero si presiona el botón "R" en la pista (es decir, pone la pista en registro) y vuelve a guardar la sesión, entonces el valor de las banderas binarias será igual a 0x00000004, en otras palabras, el tercer bit de la derecha (bit2) se convertirá en uno. Este bit es el responsable de la propiedad de "registro" de la pista. Esta propiedad no tiene valor en mi proyecto, ya que mi multisesión está diseñada para visualización y reproducción visual.Sin embargo, tuve la idea de que se presionaba el botón "R" en aquellas pistas que corresponden al fin de semana. Esta técnica facilitará la visualización de la multisesión.
El bloque de la lista de archivos de audio de la multisesión "LISTFILE" (Fig. 12) consta de las siguientes partes. Como en el caso del bloque de descripción de la pista, también se puede dividir en subbloques según el número de archivos de la sesión. Similar a la Figura 11, también he resaltado el encabezado del bloque de 8 bytes en un cuadro rojo y el tamaño de su contenido en un cuadro verde. En este ejemplo particular, este valor es 188 bytes. El contenido se resalta por analogía con la Fig. 11. Está dividido en dos áreas resaltadas con una línea azul. Estos son los subbloques del bloque de lista de archivos.
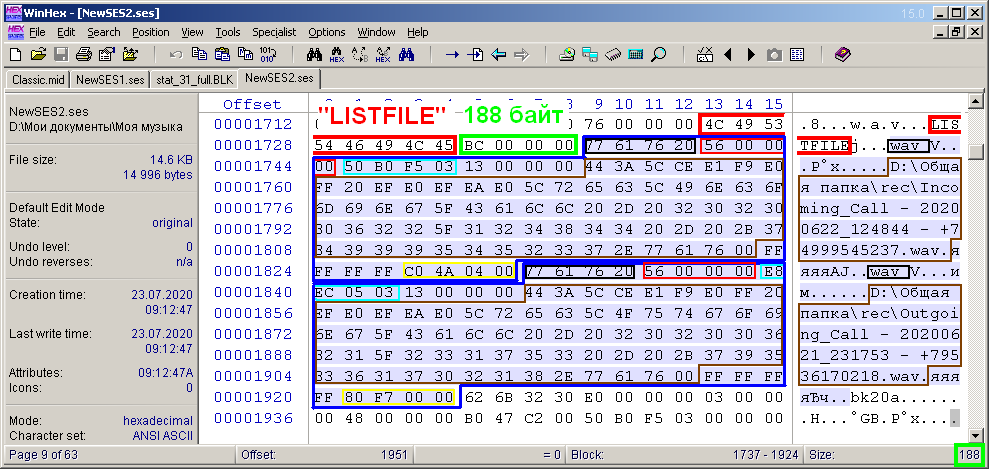
Figura: 12. Bytes del bloque de descripción de archivos de audio "LISTFILE".
Cada subbloque corresponde a un archivo de audio. El ejemplo usa dos archivos de audio, por lo que el número de subbloques es apropiado. A diferencia del caso anterior con descripciones de pistas, no hay un subtítulo sobre el número de subbloques. El subbloque contiene 4 bytes de su encabezado "wav" (resaltado en negro) y 4 bytes que indican el tamaño del contenido adicional (resaltado en violeta). Para ambos sub-bloques, este valor es el mismo en este ejemplo y es 0x56 (86) bytes. Esto se debe al hecho de que los archivos están ubicados en la misma ruta y tienen el mismo nombre. Más precisamente, los nombres de archivo totalmente calificados tienen el mismo número de caracteres. De lo contrario, las subunidades tendrían diferentes tamaños. El área de contenido del subbloque (más bytes) contiene la siguiente información. Un número que identifica un archivo de audio se resalta en un marco azul.A diferencia del ID de pista, este número no es un número de secuencia de archivo. Según tengo entendido, al guardar una multisesión, se asigna aleatoriamente o pseudoaleatoriamente para cada archivo. Lo principal es que no hay coincidencia entre estos valores. Estaba convencido de esto cuando guardé la multisesión dos veces y comparé los archivos ses por contenido. Como resultado, resultó que los archivos difieren solo por estos mismos bytes. Y no solo estos. También se asigna un número aleatorio al ID de las capas de envolvente en el bloque "ep20". Pero en este bloque, como se mencionó anteriormente, no hay ninguna necesidad en absoluto, y su descripción no se considerará en este artículo. Se necesitan ID de audio para vincularlos a los clips. Este enlace tiene lugar en el bloque con la descripción de clips.En mi caso, para una multisesión con registros telefónicos, los identificadores para los archivos de audio serán una secuencia de números naturales, pero comenzando no desde cero, sino, por ejemplo, desde 1000.Los siguientes 4 bytes, que no resalté, en ambos subbloques tienen el valor 0x13. Lo más probable es que este valor indique el tipo de formato de archivo de audio. Puede considerar condicionalmente este valor como una constante, ya que todos mis archivos de audio son del mismo tipo. La siguiente cadena de bytes describe el nombre completo del archivo de audio, con un terminador nulo (como un terminador de línea). El tamaño de esta cadena es uno más que el número de caracteres del nombre completo del archivo de audio. Luego viene la constante 0xFFFFFFFF. Le sigue un valor que indica el número de muestras en este archivo de audio (en la Fig. 12 resaltado en un marco amarillo). Para el primer archivo, este valor es 0x44AC0 y para el segundo es 0xF780.Solo corresponden a los valores decimales 281280 y 63360, respectivamente, que ya aparecieron arriba en la descripción del segundo ejemplo multisesión.
Finalmente, queda por considerar la descripción del bloque más difícil: el bloque para describir clips de audio "bk20" (Fig. 13). Por analogía con las dos figuras anteriores, se resaltan el título y el tamaño del contenido del bloque.
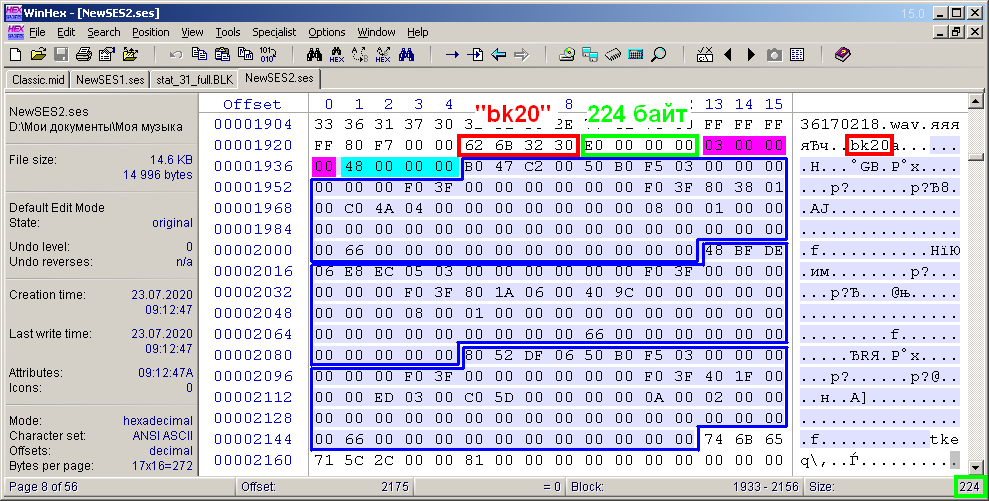
Figura: 13. Bytes del bloque de descripción de los clips de audio "bk20".
En el contenido del bloque, en primer lugar, hay dos subtítulos de 4 bytes cada uno. Están resaltados con rellenos magenta y cian. El primer subtítulo es el número de clips de la sesión. Hay tres de ellos en el ejemplo. El segundo subtítulo es la constante 0x48 (72). Aparentemente indica el tamaño de cada subbloque, y simplemente van más allá. Su número coincide con el número de clips de la sesión. Cada uno de estos subbloques describe los parámetros de un clip. Por cierto, resulta que el tamaño D del contenido del bloque "bk20" se puede calcular mediante la fórmula D = 8 + 72 * b, donde b es el número de clips de audio en una multisesión. En la figura, no hay asignaciones de bytes explicativas dentro de los subbloques, ya que hay muchos parámetros necesarios. Se enumeran en una tabla separada (Fig. 14). El relleno azul marca aquellos parámetros que son necesarios en mi proyecto, y el relleno gris - constantes no reconocidas.Esta tabla también muestra los valores de los parámetros para cada uno de los tres clips multisesión del último ejemplo.
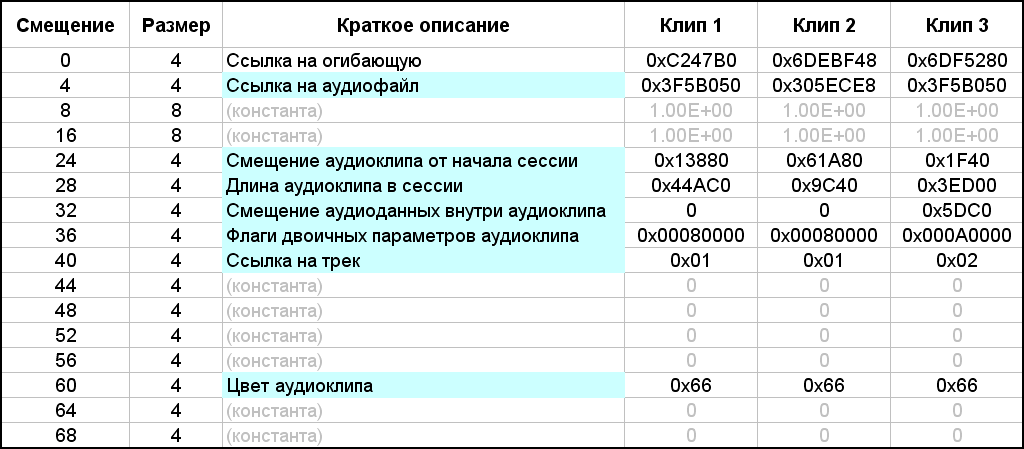
. 14. .
La primera palabra (grupo de 4 bytes) es una referencia al sobre, que no necesitamos. El segundo parámetro es un enlace al archivo de audio. El valor de este parámetro es igual al valor del identificador del archivo de audio al que corresponde este clip de audio. Luego hay dos constantes reales, que ya han aparecido antes. Les siguen tres parámetros de coordinación, expresados en el número de muestras: el desplazamiento del clip desde el comienzo de la sesión, la longitud (duración) del clip en la sesión y el desplazamiento del audio dentro del clip. Todo debe quedar claro a partir de los nombres de estos parámetros. Anteriormente, al describir en detalle el segundo ejemplo de una multisesión, indiqué los valores numéricos de todas las compensaciones y duraciones. En la Figura 14, la tabla enumera los parámetros de cada clip en forma hexadecimal. Ingresé estos valores en la tabla reescribiéndolos directamente desde la Figura 13.Pero si los convierte a forma decimal, coincidirán con los valores correspondientes de la descripción del segundo ejemplo (verificado por separado). Cabe señalar que los enlaces al archivo de audio para el primer y tercer clips tienen el mismo valor 0x3F5B050, ya que ambos clips hacen referencia al mismo archivo de audio con el identificador correspondiente. A esto le sigue un bloque de bytes de parámetros binarios (4 bytes). Como en el caso de la descripción de las pistas, decodifiqué solo parte de los bits. El valor predeterminado es 0x00080000, es decir, si se convierte a binario, sólo un bit19 se "eleva" a uno y los 31 bits restantes son iguales a cero. Sin este bit único, como ha demostrado la práctica, la multisesión se niega a cargar. En el ejemplo actual, dicho valor es característico del primer y segundo clips, pero para el tercero, por alguna razón, el valor de las banderas es igual a 0x000A0000.Si cuenta, entonces en este valor se "suben" dos bits: todavía el bit19 y otro bit17. No sé por qué sucedió. Intenté restablecer bit17 a cero, cambiando el valor de todo el parámetro a 0x00080000, como en los clips vecinos. Como resultado, la sesión en Adobe Audition se abrió sin cambios visibles. Mientras trabajaba en Adobe Audition, noté propiedades de clip como "Fijar a tiempo" y "Fijar solo para reproducción". Es lógico suponer que ciertos bits en el bloque de parámetros binarios son responsables de almacenar estas propiedades. También hay otras propiedades binarias para los clips, pero no las necesitamos. Y las dos propiedades enumeradas serán muy útiles. La propiedad "Fijar en el tiempo" es útil porque el clip estará protegido de la posibilidad de un movimiento accidental del puntero del mouse en la dirección horizontal.Pero en un clip de este tipo, se dibujará visualmente un símbolo en forma de candado en un círculo en la esquina inferior izquierda, y esta es información gráfica innecesaria para su visualización. La segunda propiedad del clip "Corregir solo para reproducción" es útil porque cuando el parámetro "R" (Grabar) está activado en la pista correspondiente, el clip no adquirirá un color rojo forzado. Por lo que decidí usar el parámetro "R" en algunas pistas, está escrito arriba. Empíricamente, descubrí que bit1 es responsable de la primera propiedad del clip y bit3 de la segunda. De todo lo dicho, se sigue lo siguiente. Para configurar la propiedad Clip in Time, debe escribir el valor 0x00080002 en los parámetros binarios. La propiedad Confirmar solo para reproducción es 0x00080008. Para ambas propiedades, su suma lógica es 0x0008000A. Se ocupa de los parámetros binarios.Después de estos bytes hay un enlace a la pista en la que se encuentra el clip. De hecho, se registra el identificador de la pista, que coincide con su número de serie. Adobe Audition 1.5, por cierto, no admite más de 128 pistas, por lo que dicho identificador cabe en un byte, aunque aparece como un valor de 32 bits. Luego hay constantes cero no descifradas (4 constantes, 4 bytes cada una). Finalmente, el último parámetro significativo es el color del clip. El editor de Adobe Audition 1.5 le permite establecer un valor de color de 0 a 239 para un clip en el cuadro de diálogo correspondiente o seleccionarlo de la paleta (Fig. 15). La paleta de colores no es particularmente agradable, pero no se ofrecen otras opciones. El color de clip predeterminado es 102 (0x66) (verde).por cierto, no admite más de 128 pistas, por lo que dicho identificador cabe en un byte, aunque aparece como un valor de 32 bits. Luego hay constantes cero no descifradas (4 constantes, 4 bytes cada una). Finalmente, el último parámetro significativo es el color del clip. El editor de Adobe Audition 1.5 le permite establecer un valor de color de 0 a 239 para un clip en el cuadro de diálogo correspondiente o seleccionarlo de una paleta (Fig. 15). La paleta de colores no es particularmente agradable, pero no se ofrecen otras opciones. El color de clip predeterminado es 102 (0x66) (verde).por cierto, no admite más de 128 pistas, por lo que dicho identificador cabe en un byte, aunque aparece como un valor de 32 bits. Luego hay constantes cero no descifradas (4 constantes, 4 bytes cada una). Finalmente, el último parámetro significativo es el color del clip. El editor de Adobe Audition 1.5 le permite establecer un valor de color de 0 a 239 para un clip en el cuadro de diálogo correspondiente o seleccionarlo de la paleta (Fig. 15). La paleta de colores no es particularmente agradable, pero no se ofrecen otras opciones. El color de clip predeterminado es 102 (0x66) (verde).5 permite establecer un valor de color de 0 a 239 para el clip en el cuadro de diálogo correspondiente o seleccionarlo de la paleta (Fig. 15). La paleta de colores no es particularmente agradable, pero no se ofrecen otras opciones. El color de clip predeterminado es 102 (0x66) (verde).5 permite establecer un valor de color de 0 a 239 para el clip en el cuadro de diálogo correspondiente o seleccionarlo de la paleta (Fig. 15). La paleta de colores no es particularmente agradable, pero no se ofrecen otras opciones. El color de clip predeterminado es 102 (0x66) (verde).
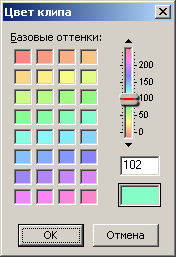
. 15. Adobe Audition 1.5.
El parámetro de color en el archivo ses es de 32 bits y, de hecho, solo hay 240 colores, que caben en un byte. Los otros tres bytes más significativos son cero. Tenía la idea de que si intento editar estos bytes para diferentes valores, al abrir una sesión múltiple, aparecerán nuevos colores en el clip. Pero este truco no funcionó. Como se discutió en el artículo anterior, los colores en un gráfico son útiles para resaltar visualmente una característica particular de una llamada telefónica. Una multisesión de grabaciones de audio de llamadas telefónicas se parecerá a un diagrama similar, por lo que el color de los clips será muy útil. El parámetro de color del clip va seguido de dos palabras de ceros. Esto completa la descripción de la subunidad. Estos ocho bytes de ceros son los últimos en el subbloque del último bloque. Por tanto, también serán los últimos de todo el archivo ses.
Mientras pensaba en el proyecto, se me ocurrió otra idea: agregar marcadores (puntos de referencia) a la multisesión, colocándolos cada hora y señalándolos con las marcas correspondientes. Si comparamos esta idea con el artículo anterior, entonces esta es una analogía completa de las líneas verticales en el diagrama, dibujadas cada hora. Para que los cue points estén presentes en la multisesión, es necesario tener en cuenta el sexto bloque denominado "cues". No comencé a comprender los bytes de este bloque. Por analogía con el bloque "stat", en la multisesión creada durante 24 horas, coloqué 23 puntos de referencia manualmente cada hora y les di los nombres apropiados. Luego guardé la multisesión como un archivo ses separado, corté el contenido del bloque "cues" y lo guardé en el archivo "cues_24h.BLK". Este archivo se tendrá en cuenta a la hora de desarrollar el programa. Los bytes de este archivo se muestran en la Figura 16. No sé por qué,pero guardé exactamente el contenido, sin el título y el campo de tamaño del contenido (a diferencia de "stat_31_full.BLK"). Estas dos palabras se agregarán en el código del programa. Y el tamaño del contenido es de 556 bytes. De estos, 4 bytes están ocupados por el subtítulo (el número de puntos de referencia) y 23 subbloques de 24 bytes cada uno. En la Figura 16, se completan los bytes de contenido del primer subbloque. Decidí hacer los nombres de los puntos de referencia (etiquetas) de la siguiente manera: 01h, 02h,…, 23h.
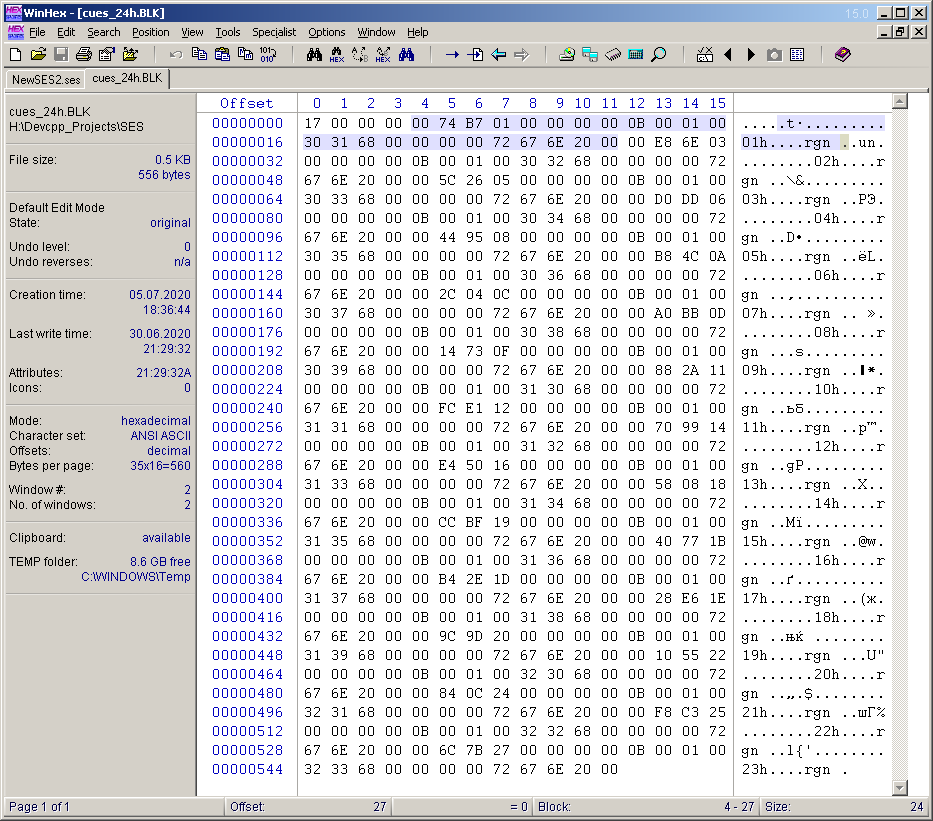
. 16. «cues» .
Con esto concluye la descripción del formato multisesión. Ahora tenemos la base de conocimientos necesaria para comenzar a escribir un programa para crear una multisesión. Escribir un programa es una tarea más fácil que aprender y descifrar el formato ses. Completé el programa en dos tardes y pasé al menos una semana estudiando el formato. Además, escribí el programa utilizando funciones previamente utilizadas, en particular, trabajando con archivos y directorios. Por lo tanto, el principal apoyo para escribir el programa no fueron los libros de referencia o Internet, sino mis proyectos anteriores, sobre los que también escribí en Habré. De Internet, tomé solo una función que devuelve el día de la semana por fecha. Pero antes de citar el texto del programa, decidí compartir algo más de información, sobre la cual inicialmente no quería escribir en este artículo.
La idea de formar una sesión múltiple a partir de grabaciones telefónicas se me ocurrió cuando estaba trabajando en una versión más reciente de Adobe Audition 3.0, que admite entrada / salida de audio a través de ASIO. Al guardar la multisesión, descubrí que se puede guardar en dos formatos: el clásico SES habitual y el nuevo formato XML, que no estaba en versiones anteriores del programa. Habiendo guardado la sesión en formato XML, inmediatamente abrí este archivo en el bloc de notas, donde encontré una descripción de un montón de parámetros vinculados entre sí en una estructura jerárquica compleja. Para la conveniencia de ver esta jerarquía, utilicé el programa WMHelp XmlPad. La Figura 17 muestra una captura de pantalla de este programa con un archivo multisesión simple de prueba abierto en él. A la izquierda está la jerarquía de documentos. El elemento activo (seleccionado) de la jerarquía es el parámetro de longitud del primer archivo de audio,en el primer subbloque del bloque de descripción del archivo de audio.
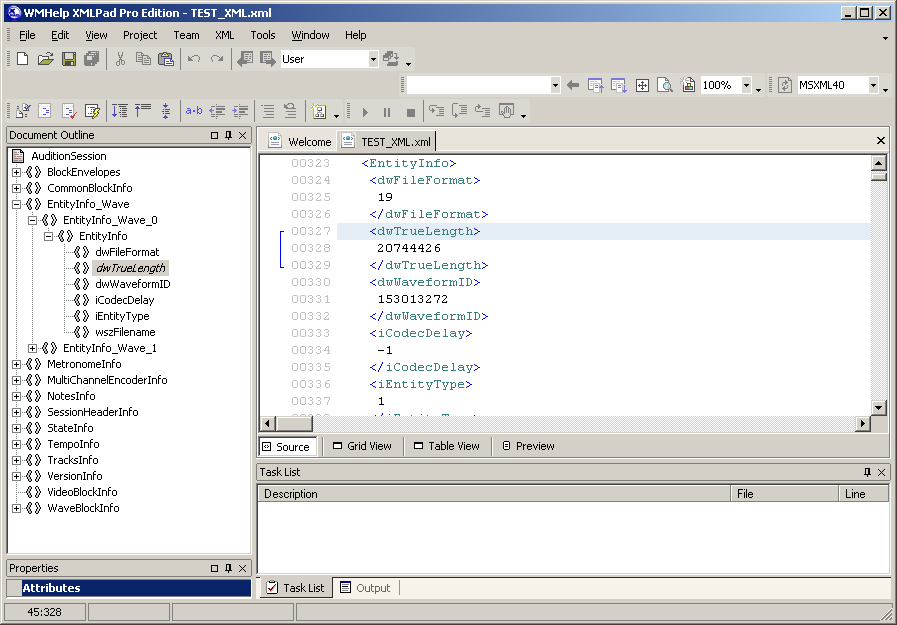
. 17. XML Adobe Audition 3.0.
Decidí estudiar este formato en particular, y en el futuro generar programáticamente el texto XML requerido, obteniendo la multisesión deseada en la salida. Incluso hubo una idea de usar Excel para este propósito. La dificultad es que aproximadamente el 95% de todo el archivo XML está ocupado por el bloque de descripción de la pista. Hay una cantidad colosal de parámetros, que no podría excluir sin dañar la multisesión. El caso es que en esta versión de Adobe Audition hay muchas más funciones relacionadas con las pistas. Lógicamente, no hay necesidad de estas funciones para mi simple multisesión. Sin embargo, al excluir los campos correspondientes del documento XML, la sesión deja de estar activa. Y tendría que "tirar" de este gran trozo de texto en la descripción de cada pista para la sesión más simple. Este es el único inconveniente al generar un archivo XML multisesión. Conocimiento,las variantes multisesión obtenidas durante el estudio de XML textual, por supuesto, fueron útiles durante el estudio de ses binarios. E incluso en XML, no pude descifrar algunos parámetros. Los campos de cada parámetro tienen un nombre abreviado en inglés, pero aun así, no siempre entendí qué era este parámetro. Lo principal es que pude estudiar y descifrar los parámetros básicos necesarios, sus bloques y campos jerárquicos. Luego me atormentó durante mucho tiempo la pregunta: ¿cómo abrir una sesión de este tipo en una versión anterior de Adobe Audition? Las nuevas versiones de los programas tienen una interfaz demasiado sofisticada (casi 3D), lo cual es muy inconveniente para visualizar una multisesión como diagramas. Y debido a este "tres de" en Adobe Audition 3.0 con una ventana completamente expandida en la pantalla FullHD, cabe un máximo (a escala mínima) de 28 pistas. Y en Adobe Audition 1.5, caben 37 (Fig.18, escala 1: 2). En total, es necesario mostrar 31 pistas en la pantalla.
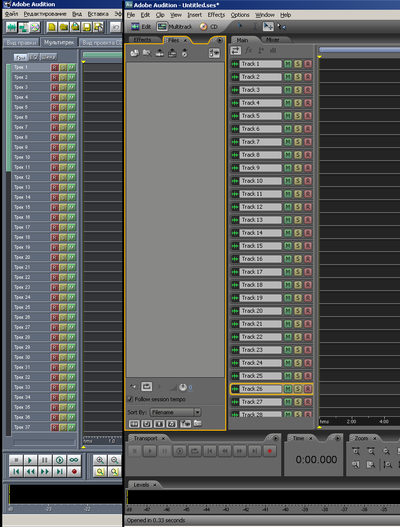
. 18. Adobe Audition .
Pero sobre todo rematé la calidad del sonido al reproducir una multisesión con una frecuencia de 8000 Hz en la nueva versión del programa. El sonido no es muy bueno, hay distorsión armónica. Esto se debe al hecho de que el sonido se emite a una frecuencia de muestreo diferente (48 kHz) y ASIO no puede hacer otra cosa. La situación no cambia cuando selecciona otro dispositivo de salida "Audition 3.0 Windows Sound" en la configuración. La nueva versión del programa no es compatible con los dispositivos de salida clásicos "DirectSound" (yo llamo a la versión 3.0 nueva). La Figura 19 muestra el espectro de audio cuando se reproduce audio (o sesión) de 8 kHz en Adobe Audition 3.0 con una distorsión armónica de espectro invertido. Esas frecuencias están encerradas en un círculo verde, lo que debería sonar idealmente (y nada más). Y las frecuencias están rodeadas de rojo,que son distorsión adicional. Es muy probable que este efecto se deba a la falta de filtrado después del procedimiento de muestreo superior. Fue después de esto que decidí emprender el estudio del formato binario SES del programa Adobe Audition 1.5, más simple y divertido. Esperaba que después de aprender el formato XML "humano" de una versión más reciente del programa, no me resultaría difícil entenderlo, dada mi experiencia con archivos binarios. Y así sucedió: rápidamente "promocioné" el formato SES. Y lo principal es que la compatibilidad con versiones anteriores, de cara al futuro, funciona bien: una sesión formada para la versión 1.5 se abre con éxito en la versión 3.0. Arriba, señalé las desventajas de Adobe Audition 3.0 relacionadas con la calidad del sonido y la interfaz gráfica. Pero esta versión del programa tiene ventajas en la navegación multisesión. Por ejemplo,Existe la posibilidad de escuchar operativamente un clip de audio en una multisesión haciendo clic en él con el mouse y luego desplazándolo hacia la derecha.
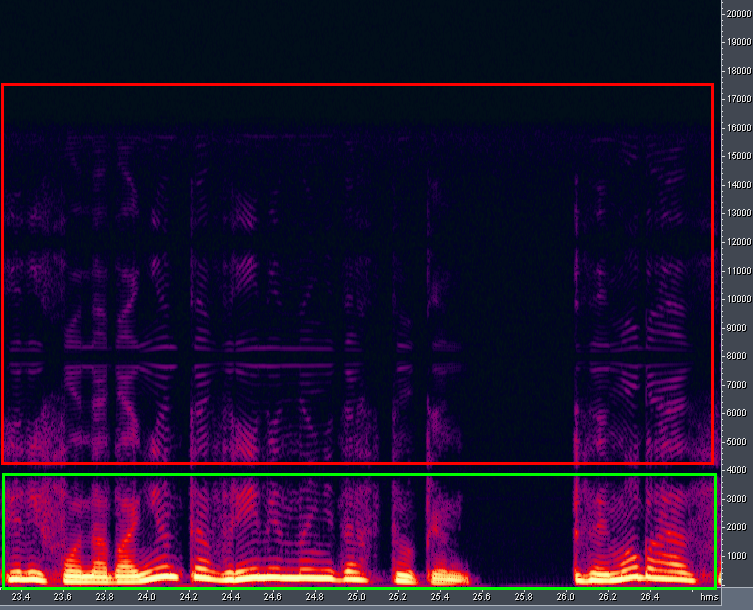
Figura: 19. Distorsión armónica durante la reproducción.
Ahora daré el texto del programa debajo del spoiler. El programa, por supuesto, no tiene una interfaz gráfica, ya que no es necesaria para esta tarea. El texto del programa se proporciona con comentarios detallados, por lo que no se necesitan explicaciones adicionales. El programa se inicia en la línea de comandos y en un segundo procesa una lista de cuatrocientos archivos, formando un archivo multisesión. Dentro del programa, hay cuatro variables paramétricas que, si lo desea, le permiten no generar marcadores de cue, no poner una "R" en las pistas los fines de semana, no establecer la propiedad "Fix in time" en los clips y seleccionar el criterio para colorear los clips (por tipo de llamada o por números de teléfono) ... Estas tres variables tendrían que ser excluidas del texto del programa y "sacadas", es decir, en un archivo separado con los parámetros del programa.
Código fuente del programa C
/********************************************************************
"RMC" ,
wav .
, .
yyyy-mn,
. .
(.. -),
.
, ,
"RMC" "I:".
*********************************************************************/
#include <windows.h>
#include <stdio.h>
#include <string.h>
DWORD wr; // , ;
DWORD ww; // , ;
DWORD wi; // , ;
// ( );
int Date( int D, int M, int Y ){
int a, y, m, R;
a = ( 14 - M ) / 12;
y = Y - a;
m = M + 12 * a - 2;
R = 6999 + ( D + y + y / 4 - y / 100 + y / 400 + (31 * m) / 12 );
return R % 7;
}
// ;
HANDLE openInputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_READ, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
// ;
void filepos(HANDLE f, __int64 p){
LONG HPos;
LONG LPos;
HPos = p>>32;
LPos = p;
SetFilePointer (f, LPos, &HPos, FILE_BEGIN);
}
// 32- ;
void write32(HANDLE f, signed long int a){
WriteFile(f, &a, 4, &ww, NULL);
}
// ;
void fill(HANDLE f, signed long int a, unsigned char c){
unsigned char i;
for(i=0;i<c;i++){
write32(f,a);
}
}
int main(){
HANDLE out; // Adobe Audition;
HANDLE stat; // "stat" (+ );
HANDLE cues; // "cues";
HANDLE lf; // "LISTFILE";
HANDLE blk; // "bk20";
char* week[7]={"", "", "", "", "", "", ""}; // -;
unsigned char dm[]={31,29,31,30,31,30,31,31,30,31,30,31}; // ;
unsigned char p_cues=1; //: (cues);
unsigned char p_R=1; //: "R" ( ) ;
unsigned char p_lock=1; //: ;
unsigned char p_color=2; // ;
unsigned char flg; // , . ;
unsigned long int lfsize=0; // "LISTFILE";
unsigned long int blksize=0; // "bk20";
unsigned long int smp; // ;
unsigned long int offset; // ;
unsigned int cfile=0; // ;
unsigned int cblk=0; // ;
char name[100]; // ( ...);
char fullname[100]; // ;
char infld[8]; // ;
char number[11]; // . ;
unsigned char len; // ;
printf("Input yyyy-dd name of folder:\n"); // ;
scanf("%s",infld); // ;
WIN32_FIND_DATA fld; // ;
HANDLE hf; // ( , );
char buf1[48],buf2[556]; // "stat" "cues";
char str[16]; // ;
unsigned long int outpos=0; // ;
unsigned char byte; // "LISTFILE" "bk20";
unsigned char i; // ;
unsigned char mn,d,dw,h,m,s; // -;
unsigned char cdm; // ;
int yy; // ;
yy=2000+(infld[2]-48)*10+(infld[3]-48); // ;
mn=(infld[5]-48)*10+(infld[6]-48); // ;
sprintf(name,"I:\\RMC\\%s.ses",infld); // ( );
out=openOutputFile(name); // ;
WriteFile(out, "COOLNESS", 8, &wi, NULL); // : ;
write32(out,0); // ( , );
WriteFile(out, "hdr ", 4, &wi, NULL); //, : ;
write32(out,936); // , 936;
write32(out,8000); // ;
write32(out,24*3600*8000); // (. 24 );
write32(out,0); // ( );
write32(out,0x00010020);
write32(out,0);
write32(out,0x3ff00000);
write32(out,0);
write32(out,0x3ff00000);
filepos(out,328); // ;
write32(out,0x20);
WriteFile(out, "", 6, &wi, NULL); // ;
filepos(out,376); // ;
write32(out,0x3ff00000);
filepos(out,892); // ;
write32(out,0x0430041c);
write32(out,0x04420441);
write32(out,0x04400435);
filepos(out,956); // ;
stat=openInputFile("stat_31_full.BLK"); // ,
ReadFile(stat, &buf1, 48, &wr, NULL); // ;
WriteFile(out, buf1, 48, &wi, NULL);
CloseHandle(stat);
if(mn==2){ // ,
if(!(yy%4)){ // ,
cdm=29; // 29 ,
}else{
cdm=28; // - 28;
}
}else{ // ,
cdm=dm[mn-1]; // ;
}
WriteFile(out, "trks", 4, &wi, NULL); // ;
write32(out,4+cdm*152); // ;
write32(out,cdm); // ;
outpos=1016; // ;
for(i=0;i<cdm;i++){ //
dw=Date(i+1,mn,yy); // ;
write32(out,0); // ses, ;
write32(out,0x3ff00000);
write32(out,0); // 8- double;
write32(out,0x3ff00000);
if((dw%7==5||dw%7==6)&&p_R){ // - , "R",
write32(out,4); // "R",
}else{
write32(out,0); // - ;
}
sprintf(str,"%02d.%02d.%i %s",i+1,mn,yy,week[dw]); // , ;
WriteFile(out, str, strlen(str), &wi, NULL);
filepos(out,1072+152*i); // (i+1)- ;
write32(out,1); // , ;
write32(out,1);
write32(out,4);
write32(out,0);
write32(out,0);
write32(out,0x40590000);
write32(out,0);
write32(out,0);
write32(out,0xffffff9d);
write32(out,0xffffff9d);
write32(out,i+1); // , ;
fill(out,0,11);
write32(out,4);
write32(out,0);
outpos+=152; // ;
}
if(p_cues){ // , "cues";
WriteFile(out, "cues", 4, &wi, NULL); // ,
write32(out,556); // - ;
cues=openInputFile("cues_24h.BLK"); // , ;
ReadFile(cues, &buf2, 556, &wr, NULL); //( , "stat");
WriteFile(out, buf2, 556, &wi, NULL);
CloseHandle(cues);
outpos+=564;
}
DeleteFile("LISTFILE"); // ( )
DeleteFile("bk20"); // "LISTFILE" "bk20",
lf=openOutputFile("LISTFILE"); // ()
blk=openOutputFile("bk20"); // ;
WriteFile(lf, "LISTFILE", 8, &wi, NULL); // ;
WriteFile(blk, "bk20", 4, &wi, NULL);
write32(lf,0);
write32(blk,0);
write32(blk,0);
write32(blk,0x48); // , ;
sprintf(name,"I:\\RMC\\%s\\*.wav",infld); // wav ;
hf=FindFirstFile(name,&fld); // ;
do{ // ;
len=strlen(fld.cFileName); // ;
for(i=10;i>=1;i--){ // 10 ;
number[10-i]=fld.cFileName[len-i-4]; // ;
}
number[10]=0; // , ;
cfile+=1; // ;
sprintf(fullname,"I:\\RMC\\%s\\%s",infld,fld.cFileName); // ;
d=(fld.cFileName[22]-48)*10+(fld.cFileName[23]-48); // () ;
h=(fld.cFileName[25]-48)*10+(fld.cFileName[26]-48); // ;
m=(fld.cFileName[27]-48)*10+(fld.cFileName[28]-48); // ;
s=(fld.cFileName[29]-48)*10+(fld.cFileName[30]-48); // ;
offset=(h*3600+m*60+s)*8000; // ;
smp=(fld.nFileSizeLow-44)/4; // ( );
WriteFile(lf, "wav ", 4, &wi, NULL); // ;
write32(lf,17+strlen(fullname)); // ( );
write32(lf,1000+cfile); // ( , 1000 );
write32(lf,0x14); // ( );
WriteFile(lf, fullname, strlen(fullname), &wi, NULL); // ( );
WriteFile(lf, "\0", 1, &wi, NULL); // ;
write32(lf,0xffffffff); //;
write32(lf,smp); // ;
lfsize+=(25+strlen(fullname)); // "LISTFILE";
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile); // ();
write32(blk,0); // ;
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,offset); // ;
if(((24*3600*8000)-offset)>smp){ // ( ) ,
write32(blk,smp); // ,
}else{
write32(blk,(24*3600*8000)-offset); // ;
}
write32(blk,0); // ;
if(p_lock){ // ,
write32(blk,0x0008000a); // (3 32 ),
}else{
write32(blk,0x00080008); // (2 32 );
} // - " ";
write32(blk,d); // ( );
fill(blk,0,4); // ;
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ;
case 'I': // "I" ( ),
write32(blk,0); // ;
break;
case 'O': // "O" ( ),
write32(blk,102); // ( );
break;
default: // - ,
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0; // ;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // - ();
if(!flg){ // ( ),
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
if(((24*3600*8000)-offset)<=smp){ // ( ) ( ),
cblk+=1; // ;
write32(blk,0); // , ;
write32(blk,1000+cfile);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0);
write32(blk,0x3ff00000);
write32(blk,0); // ,
write32(blk,smp-((24*3600*8000)-offset)); // ,
write32(blk,(24*3600*8000)-offset); // , ;
if(p_lock){
write32(blk,0x0008000a);
}else{
write32(blk,0x00080008);
}
write32(blk,d+1); // () ();
fill(blk,0,4);
switch(p_color){ // ;
case 1: // ;
switch(fld.cFileName[0]){ // ( );
case 'I': // ,
write32(blk,0); // ;
break;
case 'O': // ,
write32(blk,102); // , ;
break;
default: // - ( ),
write32(blk,102); // ;
break;
}
break;
case 2: // ;
flg=0;
if(!strcmp("9530000000",number)){ // - - ,
write32(blk,05); // - -,
flg=1; //( );
}
#include "numbers_and_colors.cpp" // ( );
if(!flg){ // ,
write32(blk,102); // ;
}
break;
}
write32(blk,0);
write32(blk,0);
}
}while(FindNextFile(hf,&fld)); // wav ;
filepos(lf,8);
write32(lf,lfsize); // "LISTFILE", ;
filepos(blk,4);
blksize=8+72*cblk; // "bk20", ;
write32(blk,blksize); // "bk20";
write32(blk,cblk); // ;
blksize+=8; // "bk20", . ;
lfsize+=12; // "LISTFILE", . ;
CloseHandle(lf); // . ;
CloseHandle(blk); // . ;
lf=openInputFile("LISTFILE"); // . ;
do{ // , ( );
ReadFile(lf, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(lf); // . ;
blk=openInputFile("bk20"); // . ;
do{ // , ( );
ReadFile(blk, &byte, 1, &wr, NULL);
if(wr){
WriteFile(out, &byte, 1, &wi, NULL);
}
}while(wr);
CloseHandle(blk); // . ;
outpos=outpos+blksize+lfsize; // ;
filepos(out,8);
write32(out,outpos-12); // ;
filepos(out,28);
write32(out,cblk); // ;
CloseHandle(out); // ! ;
printf("c_files: %i\nc_block: %i\n",cfile,cblk); // ( );
system("PAUSE");
return 0;
}
Ahora puede mostrar capturas de pantalla de los resultados. Habrá varios de ellos: a diferentes escalas de visualización, en diferentes versiones del programa y con diferentes criterios de coloración. Se estaba procesando el catálogo "2020-05", es decir, registros de mayo del año en curso. Se procesaron un total de 446 registros. El número de bloques es el mismo, ya que no hay registros con la transición a un nuevo día.
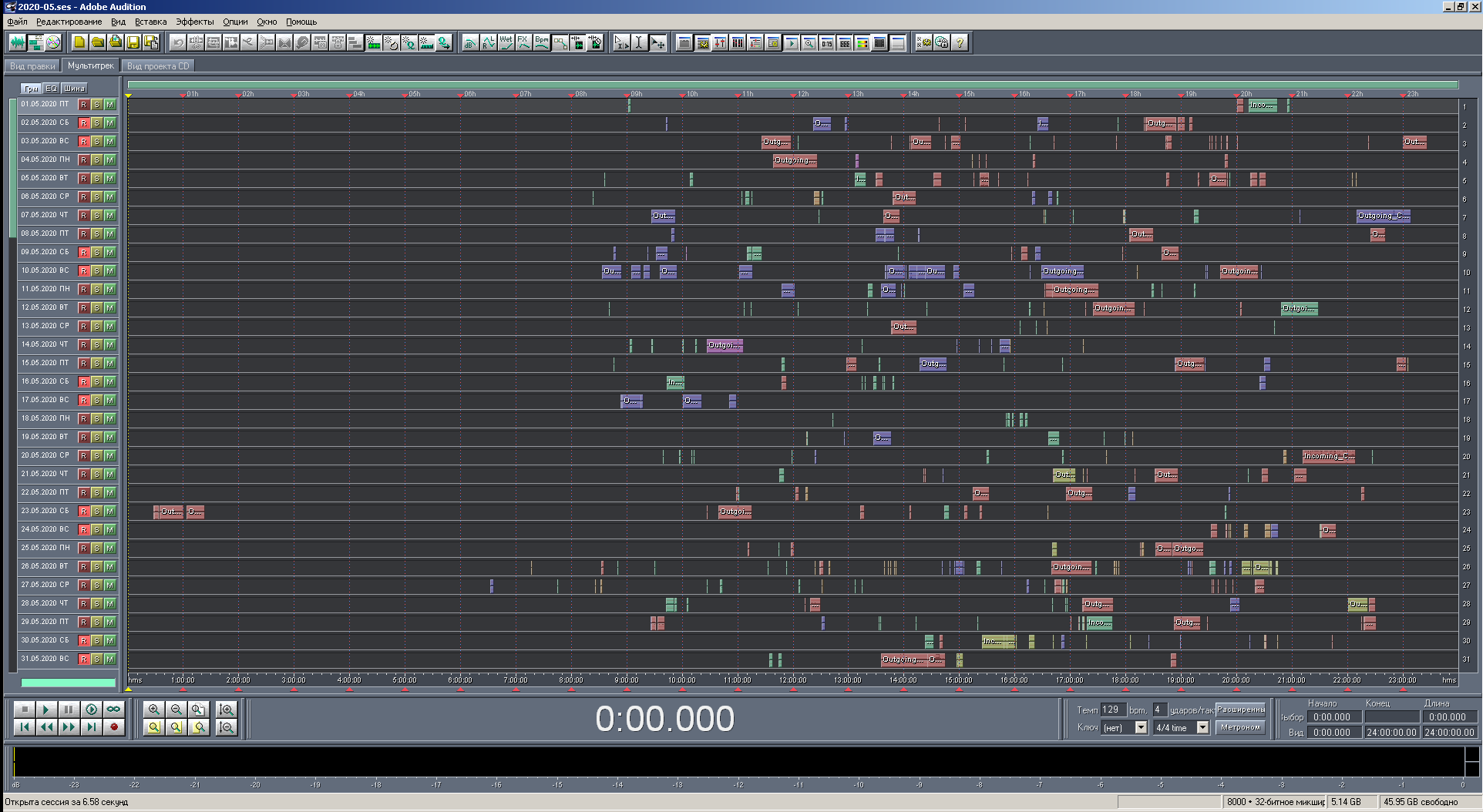
Figura: 20. Vista de la multisesión a escala completa con colorear por teléfono. números.
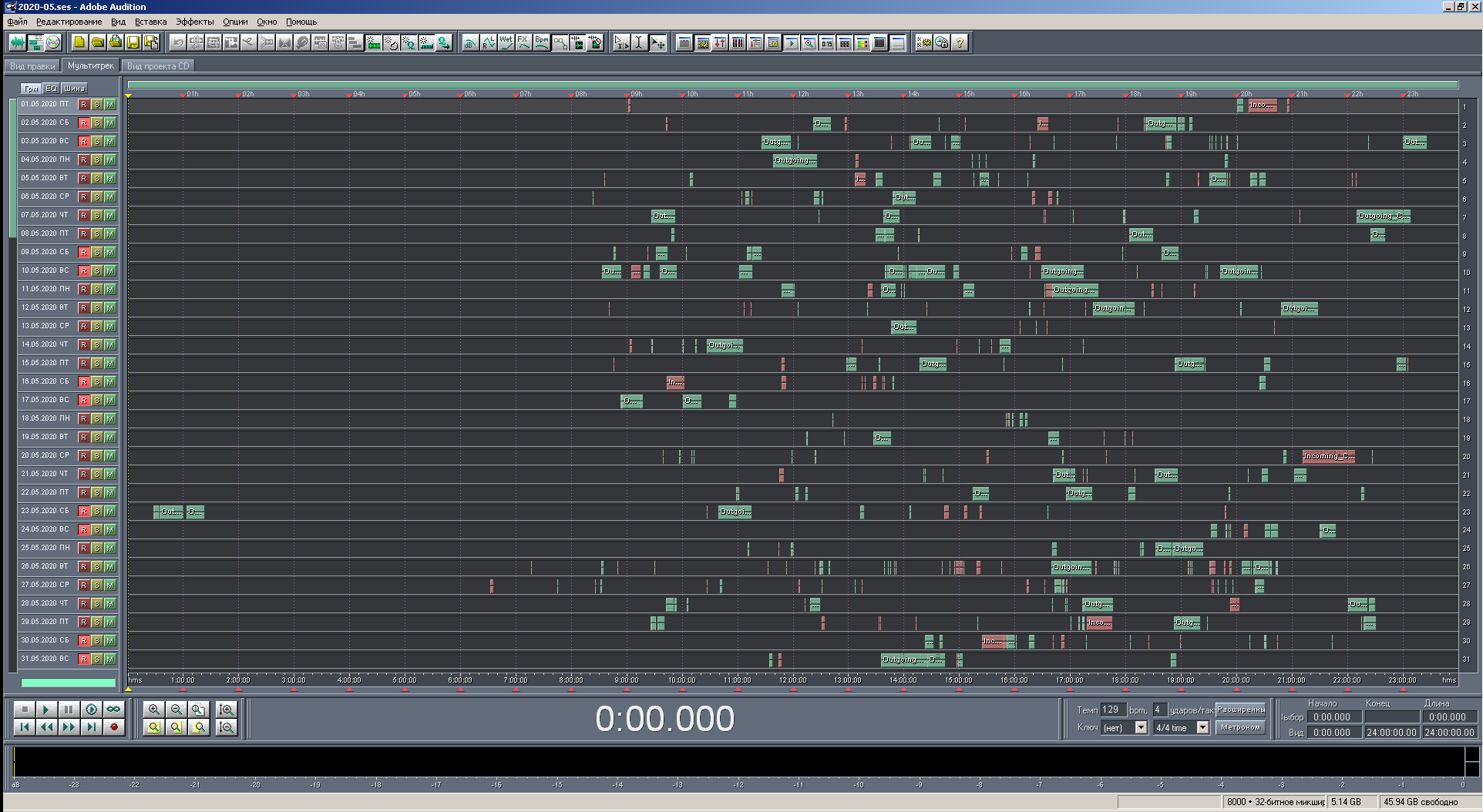
Figura: 21. Vista de multisesión a escala completa con coloración por tipo de llamada.
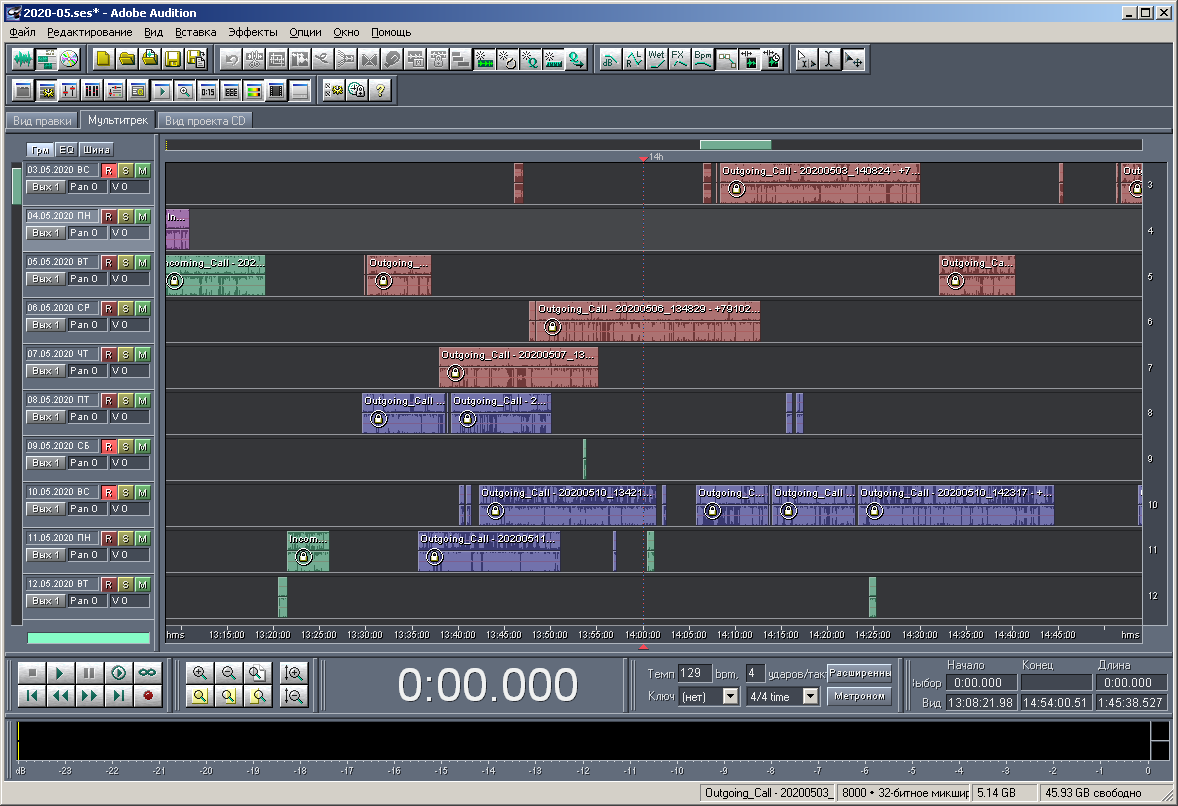
Figura: 22. Vista de una multisesión a mediana escala.
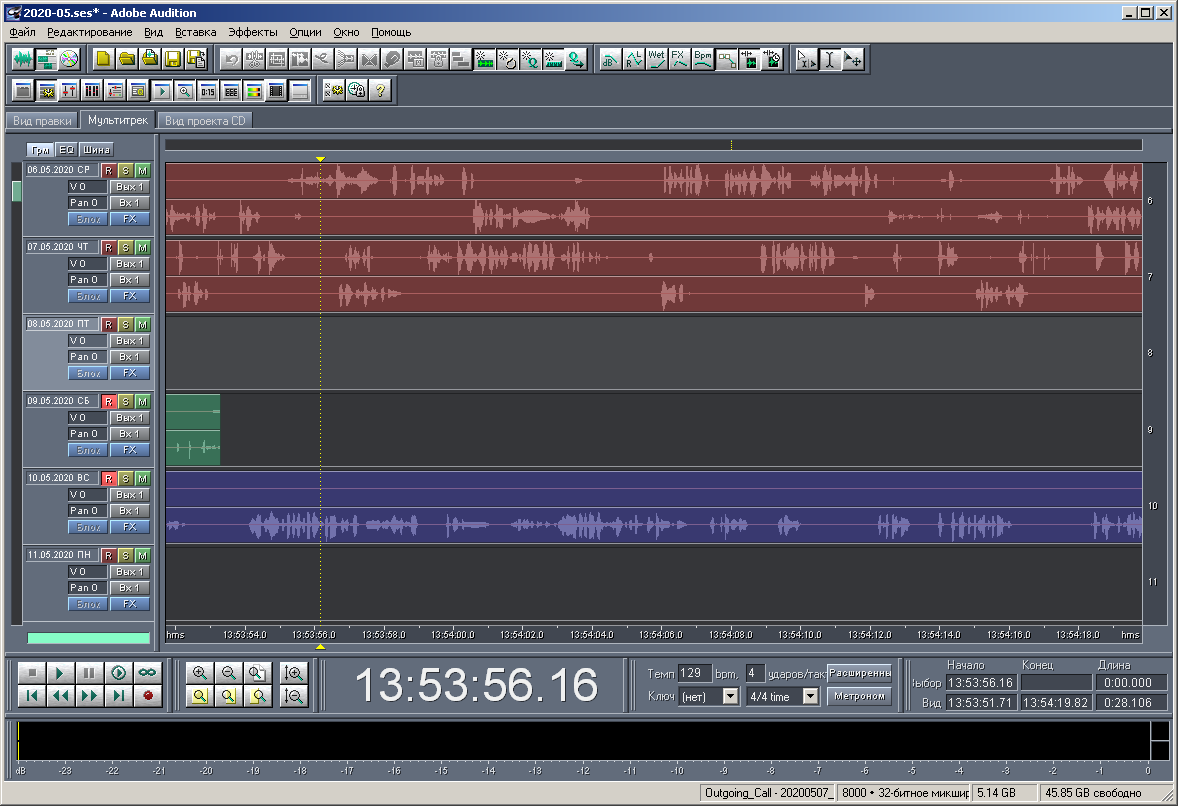
Figura: 23. Visión de una multisesión a gran escala.
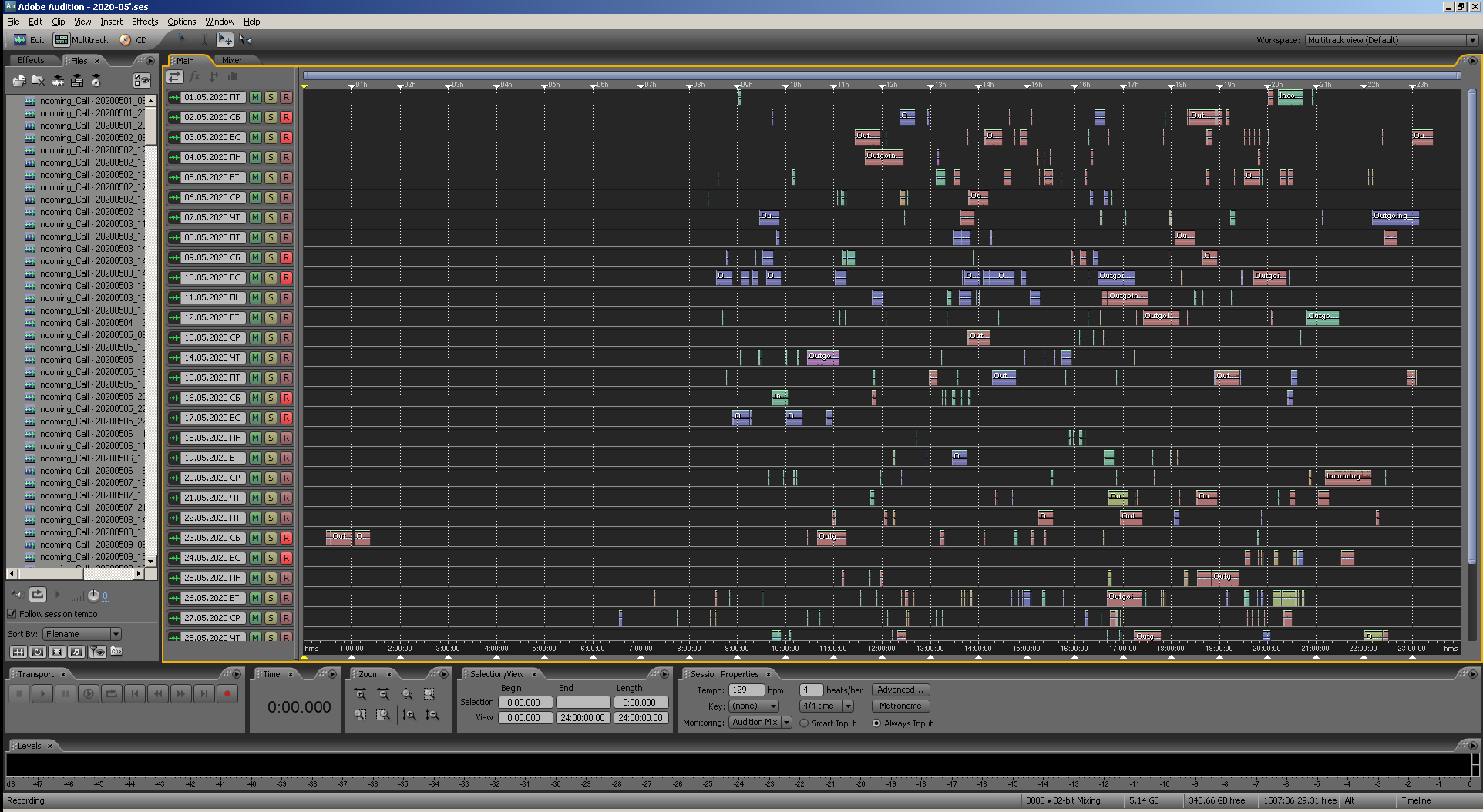
Figura: 24. Vista de la misma multisesión en Adobe Audition 3.0.