
Desde el principio, me gustaría aclarar que en este caso Oracle se presenta como un lenguaje SQL colectivo. Las agrupaciones y cómo se aplican se aplican a toda la familia de SQL (que aquí se entiende como un lenguaje de consulta estructurado) y es aplicable a todas las consultas, con correcciones de sintaxis para cada idioma.
Intentaré explicar de forma breve y sencilla toda la información necesaria en dos partes. Lo más probable es que la publicación sea útil para desarrolladores novatos. A quién le importa, bienvenido a cat.
Parte 1: Ofertas Ordenar por, Agrupar por, Tener
Aquí hablaremos de ordenar - Ordenar por, agrupar - Agrupar por, filtrar - Tener y plan de consultas. Pero lo primero es lo primero.
Ordenar por
El operador Orden por ordena los valores de salida, es decir ordena el valor recuperado por una columna específica. La ordenación también se puede aplicar mediante un alias de columna que se define mediante un operador.
La ventaja de Order by es que se puede aplicar a columnas numéricas y de cadena. Las columnas de cadenas suelen estar ordenadas alfabéticamente.
La ordenación ascendente se aplica de forma predeterminada. Si desea ordenar las columnas en orden descendente, utilice el operador DESC adicional.
Sintaxis:
SELECT col1, columna2, ... (nombre indica)
DE nombre_tabla
ORDER BY column1, columna2 ... ASC | DESC ;
Veamos todo con ejemplos:
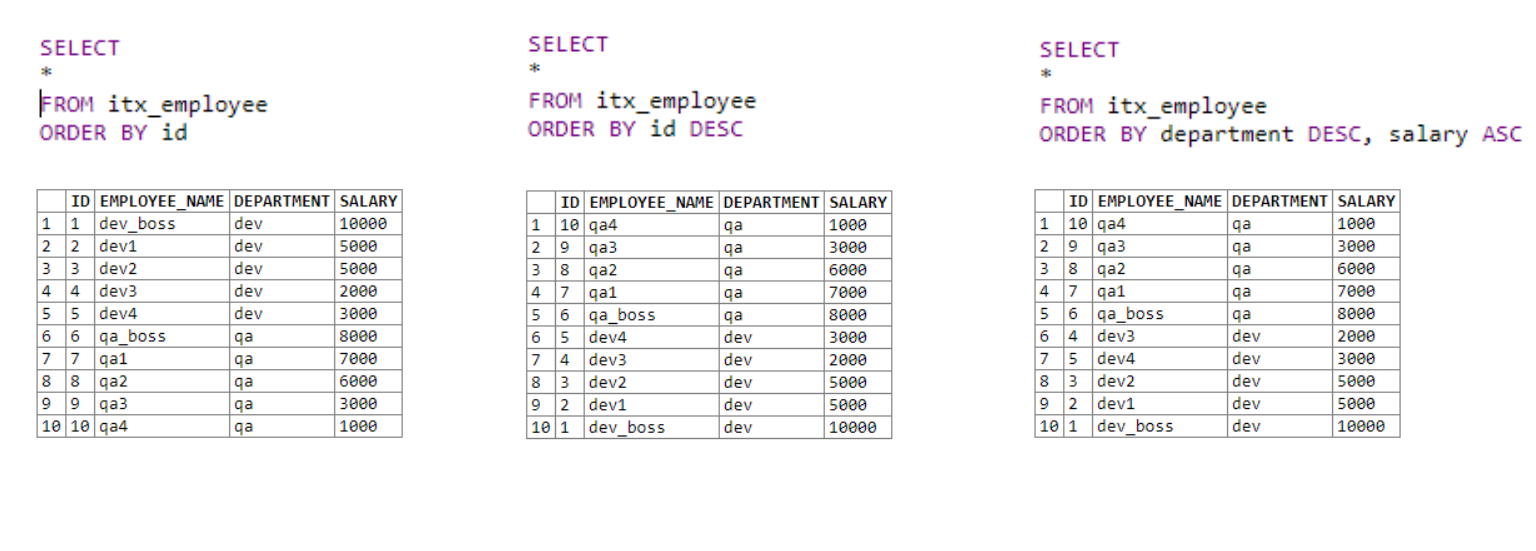
En la primera tabla, obtenemos todos los datos y los clasificamos en orden ascendente por la columna de ID.
En el segundo, también obtenemos todos los datos. Ordene por la columna de ID en orden descendente utilizando la palabra clave DESC .
La tercera tabla utiliza varios campos de clasificación. Primero viene la clasificación por departamento. Si el primer operador es igual para campos con el mismo departamento, se aplica la segunda condición de clasificación; en nuestro caso, este es el salario.
Es bastante simple. Podemos establecer más de una condición de ordenación, lo que nos permite ordenar las listas de salida de forma más inteligente.
Agrupar por
En SQL, la cláusula Group by recopila datos recuperados de una base de datos en grupos específicos. La agrupación divide todos los datos en conjuntos lógicos para que los cálculos estadísticos se puedan realizar por separado en cada grupo.
Este operador se utiliza para combinar los resultados de una selección por una o más columnas. Después de agrupar, solo habrá una entrada para cada valor utilizado en la columna.
El uso de la instrucción SQL Group by está estrechamente relacionado con el uso de funciones agregadas y la instrucción Taking SQL. Una función agregada en SQL es una función que devuelve un solo valor sobre un conjunto de valores de columna. Por ejemplo: COUNT (), MIN (), MAX (), AVG (), SUM ()
Sintaxis:
SELECT column_name (s)
FROM table_name
DONDE condición
GROUP BY nombre (s) columna (s)
ORDER BY nombre (s) columna (s);
Agrupar por aparece después de la cláusula WHERE en la consulta SELECT . Opcionalmente, puede utilizar ORDER BY para ordenar los valores de salida.
Entonces, según la tabla del ejemplo anterior, necesitamos encontrar el salario máximo para los empleados de cada departamento. La muestra final debe incluir el nombre del departamento y el salario máximo.
Solución 1 (sin usar agrupación):
SELECT DISTINCT
ie.department
ie.slary
FROM itx_employee ie
WHERE ie.salary = (
SELECT
max(ie1.salary)
FROM itx_employee ie1
WHERE ie.department = ie1.department
)
Solución 2 (usando agrupación):
SELECT
department,
max(salary)
FROM itx_employee
GROUP BY department
En el primer ejemplo, resolvemos el problema sin usar agrupaciones, pero usando una sub-selección, es decir poner el segundo en una selección. En la segunda solución, usamos la agrupación.
El segundo ejemplo es más breve y legible, aunque realiza las mismas funciones que el primero.
Cómo funciona Group by para nosotros: primero divide dos departamentos en grupos de qa y de desarrollo. Luego busca el salario máximo para cada uno de ellos.
Teniendo
Tener es una herramienta de filtrado. Indica el resultado de realizar funciones agregadas. Tener cláusula se usa en SQL donde no se puede usar WHERE.
Si la cláusula WHERE define un predicado para filtrar filas, entonces se usa Have después de la agrupación para definir un predicado lógico que filtra el grupo por los valores de las funciones agregadas. La cláusula es necesaria para probar los valores obtenidos utilizando funciones agregadas de grupos de filas.
Sintaxis:
SELECT column_name (s)
FROM table_name
WHERE condition
GROUP BY column_name (s)
HAVING condition
Primero, mostramos los departamentos con un salario promedio mayor que 4000. Luego mostramos el salario máximo usando el filtrado.
Solución 1 (sin usar GROUP BY y HAVING):
SELECT DISTINCT
ie.department AS "DEPARTMENT",
(
(SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department)
) AS "AVG SALARY"
FROM itx_employee ie
where (SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department) > 4000
Solución 2 (usando GROUP BY y HAVING):
SELECT
department,
AVG(salary)
FROM itx_employee
GROUP BY department
HAVING AVG(salary) > 4000
El primer ejemplo usa dos subselecciones, una para encontrar el salario máximo y la otra para filtrar el salario promedio. El segundo ejemplo, nuevamente, resultó mucho más simple y conciso.
Solicitar plan
Muy a menudo, hay situaciones en las que una solicitud lleva mucho tiempo y consume importantes recursos de memoria y discos. Para comprender por qué una consulta se está ejecutando durante mucho tiempo y de manera ineficiente, podemos mirar el plan de consultas.
Un plan de consulta es el plan de ejecución previsto para una consulta, es decir cómo lo ejecutará el DBMS. El DBMS anotará todas las operaciones que se realizarán dentro de la subconsulta. Después de analizar todo, podremos entender dónde están las debilidades en la solicitud y utilizando el plan de consultas podremos optimizarlas.
La ejecución de cualquier declaración SQL en Oracle recupera el llamado "plan de ejecución". Este plan de ejecución de consultas es una descripción de cómo Oracle obtendrá datos de acuerdo con la instrucción SQL que se está ejecutando. Un plan es un árbol que contiene el orden de los pasos y la relación entre ellos.
Las herramientas que permiten obtener el plan de ejecución estimado de una consulta incluyen Toad, SQL Navigator, PL / SQL Developer , etc. Dan una serie de indicadores del consumo de recursos de una consulta, entre los que se encuentran los principales: costo - costo de ejecución y cardinalidad (o filas ) - cardinalidad (o cantidad) líneas).
Cuanto mayor sea el valor de estos indicadores, menos eficiente será la consulta.
A continuación puede ver el análisis del plan de consultas. La primera solución usa una sub-selección, la segunda usa una agrupación. Tenga en cuenta que la primera solución procesó 22 filas, la segunda procesó 15.
Análisis del plan de consultas:
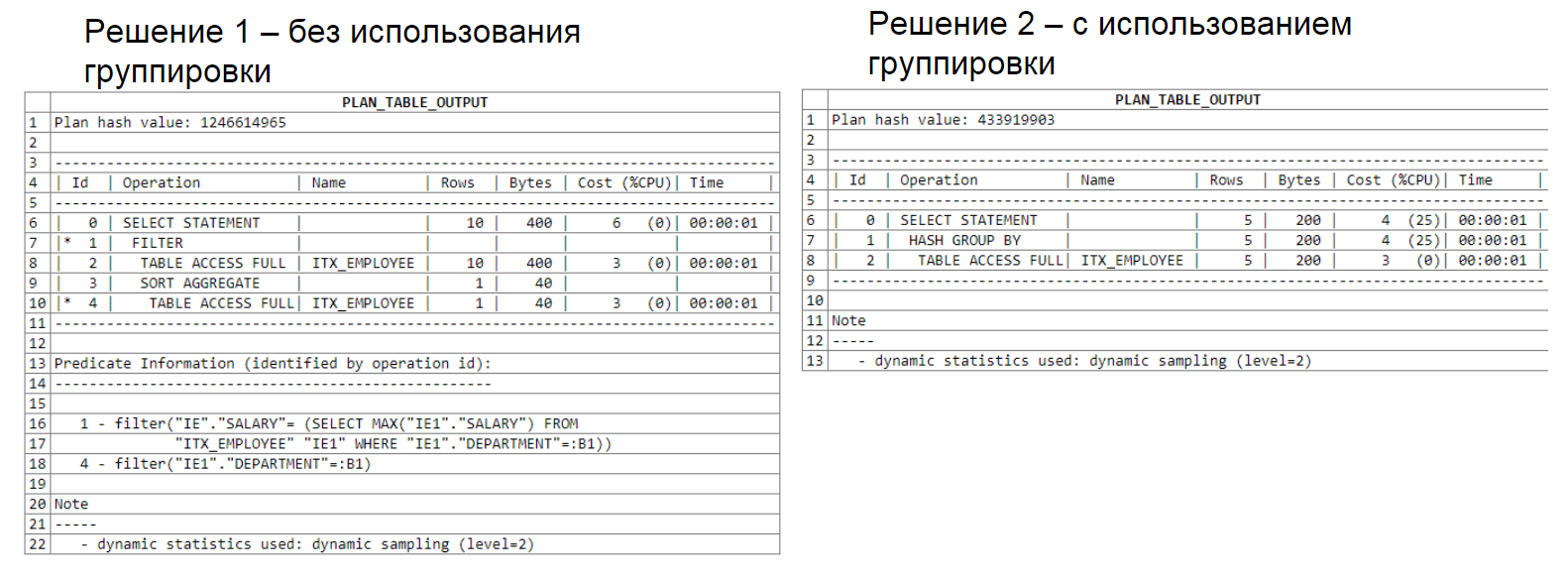
otro análisis del plan de consultas que utiliza dos subselecciones:
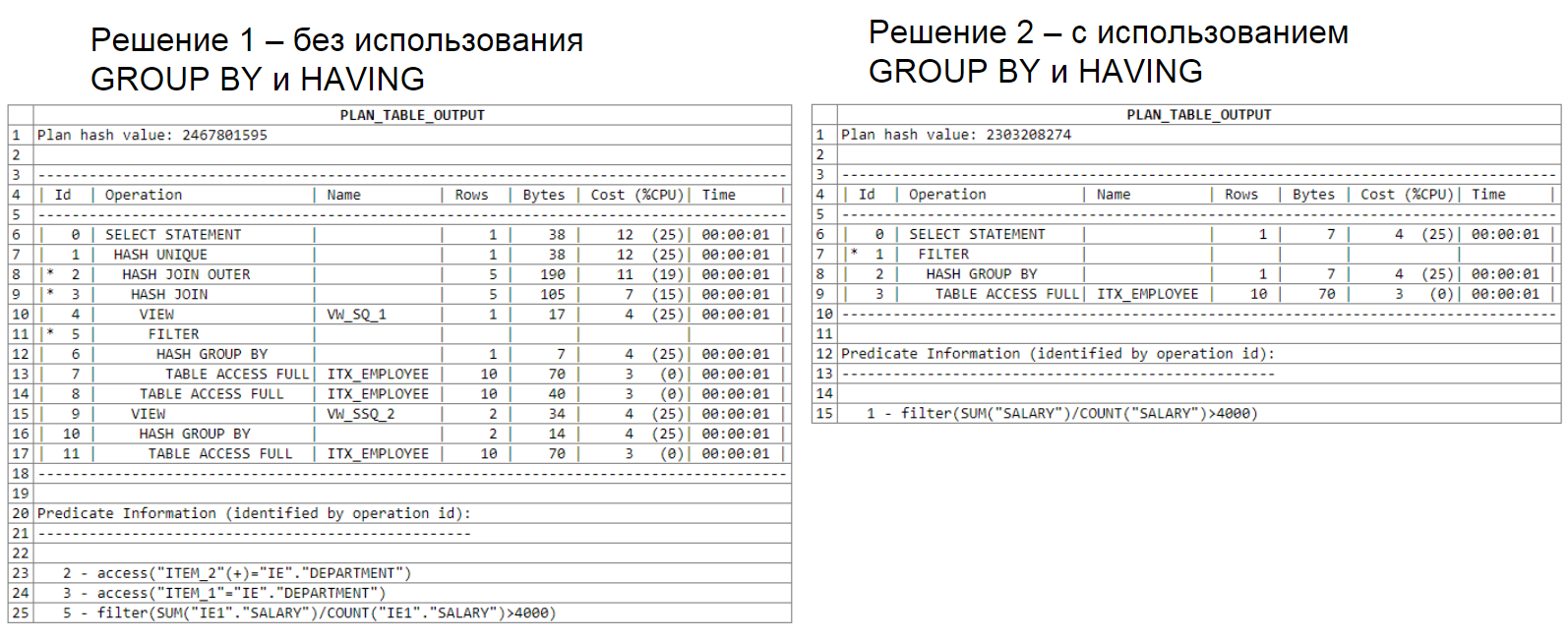
Este ejemplo se presenta como una variante del uso ineficiente de herramientas SQL y no recomiendo que lo use en sus consultas.
Todas las características anteriores le facilitarán la vida al escribir consultas y aumentarán la calidad y la legibilidad de su código.
Parte 2: Funciones de ventana
Las funciones de ventana se remontan a Microsoft SQL Server 2005. Realizan cálculos en un rango determinado de filas dentro de una cláusula Select. En resumen, una "ventana" es un conjunto de líneas dentro de las cuales se realiza un cálculo. "Ventana" le permite reducir los datos y procesarlos mejor. Esta función le permite dividir todo el conjunto de datos en ventanas.
Las ventanas tienen una gran ventaja. No es necesario formar un conjunto de datos para los cálculos, lo que le permite guardar todas las filas del conjunto con su ID único. El resultado de las funciones de la ventana se agrega a la selección resultante en un campo más.
Sintaxis:
SELECT column_name (s)
Función agregada (columna que se calculará)
OVER ([ PARTITION BYcolumna a grupo]
FROM table_name
[ ORDER BY columna a ordenar]
[ ROWS o RANGE expresión para limitar filas dentro de un grupo])
OVER PARTITION BY es una propiedad para establecer el tamaño de la ventana. Aquí puede especificar información adicional, dar comandos de servicio, por ejemplo, agregar un número de línea. La sintaxis de la función de ventana encaja perfectamente en la selección de columna.
Veamos todo con un ejemplo: se ha agregado otro departamento a nuestra tabla, ahora hay 15 filas en la tabla. Intentaremos retirar empleados, su salario, así como el salario máximo de la organización.
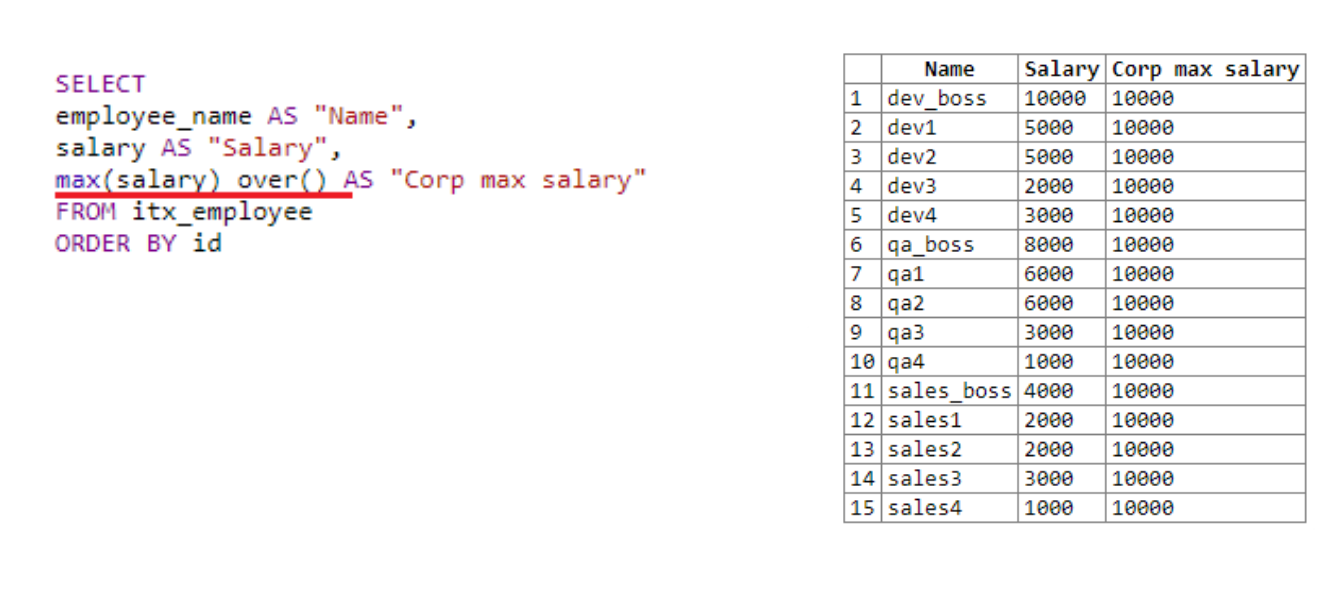
En el primer campo tomamos el nombre, en el segundo, el salario. A continuación, usamos la función de ventana sobre ()... Lo usamos para sacar el máximo salario en toda la organización, ya que no se indica el tamaño de la "ventana". Over () con paréntesis vacíos se aplica a toda la selección. Por lo tanto, el salario máximo en todas partes es de 10,000. El resultado de la función de ventana se agrega a cada línea.
Si eliminamos la mención de la función de ventana de la cuarta línea de la consulta, es decir, solo queda el máximo (salario) , la solicitud no funcionará. El salario máximo simplemente no se pudo calcular. Dado que los datos se procesarían línea por línea, y en el momento de llamar a max (salario) , solo habría un número en la línea actual, es decir, empleado actual. Aquí es donde puede ver la ventaja de la función de ventana. En el momento de la llamada, funciona con toda la ventana y con todos los datos disponibles.
Veamos otro ejemplo en el que necesita mostrar el salario máximo de cada departamento: de
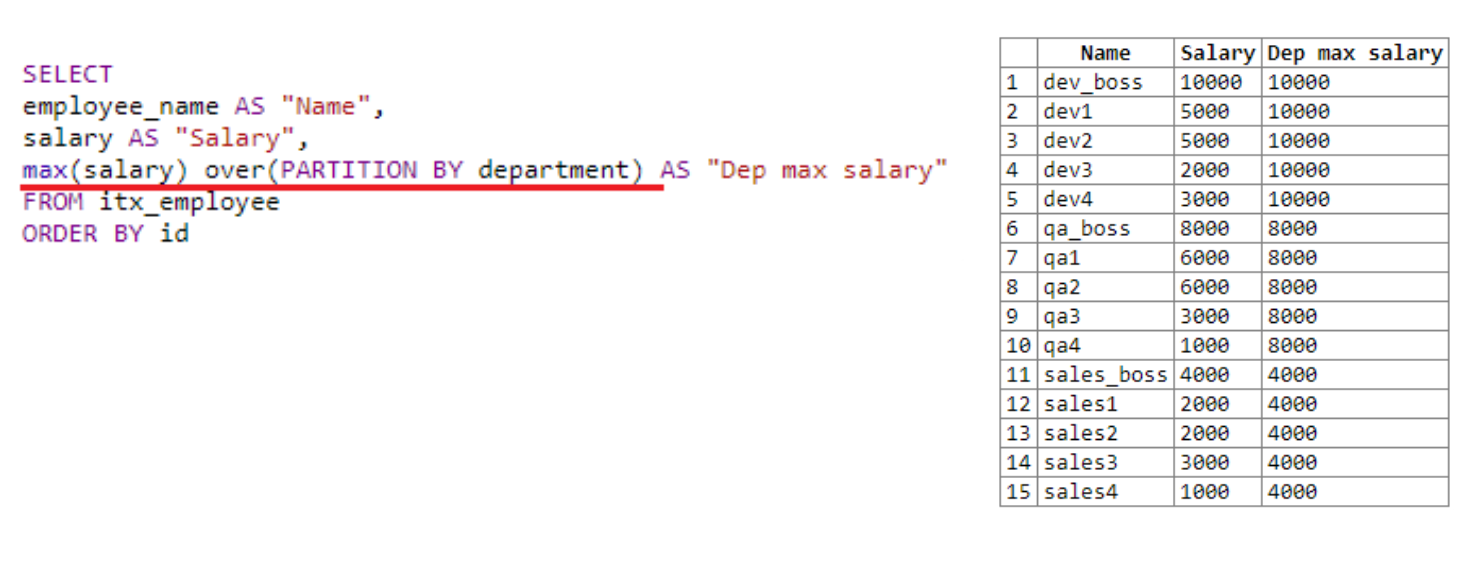
hecho, establecemos el marco para la "ventana", dividiéndola en departamentos. Usamos el departamento como ejemplo de clasificación. Tenemos tres departamentos: dev, qa y sales.
"Ventana" encuentra el salario máximo para cada departamento. Como resultado de la selección, vemos que encontró el salario máximo primero para dev, luego para qa, luego para ventas. Como se mencionó anteriormente, el resultado de la función de ventana se escribe en el resultado de búsqueda de cada fila.
En el ejemplo anterior, no se especificaron los paréntesis después de over. Aquí usamos PARTICIÓN POR, lo que nos permitió establecer el tamaño de nuestra ventana. Aquí puede especificar información adicional, enviar comandos de servicio, por ejemplo, número de línea.
Conclusión
SQL no es tan simple como parece a primera vista. Todo lo descrito anteriormente es la funcionalidad básica de las funciones de ventana. Con su ayuda, puede "simplificar" nuestras solicitudes. Pero hay mucho más potencial oculto en ellos: hay operadores de servicios públicos (por ejemplo, ROWS o RANGE) que se pueden combinar para agregar más funcionalidad a las consultas.
Espero que la publicación haya sido útil para todos los interesados en este tema.