
Foto del sitio web de Unsplash . Por Sasha • Historias
Scikit-learn es una de las bibliotecas de aprendizaje automático de Python más utilizadas. Su interfaz simple y estándar permite el preprocesamiento, el entrenamiento, la optimización y la evaluación del modelo de datos.
Este proyecto, diseñado por David Cournapeau, nació como parte del programa Google Summer of Code y se lanzó en 2010. Desde sus inicios, la biblioteca se ha convertido en una rica infraestructura para construir modelos de aprendizaje automático. Las nuevas funciones le permiten resolver aún más tareas y mejorar la usabilidad. En este artículo, presentaré diez de las características más interesantes que quizás no conozca.
1. Conjuntos de datos integrados
En la API de scikit-learn, puede encontrar conjuntos de datos incrustados que contienen datos generados y del mundo real . Puede usarlos con solo una línea de código. Dichos datos son extremadamente útiles si recién está aprendiendo o simplemente quiere probar algo rápidamente.
Además, con una herramienta especial, puede generar datos sintéticos usted mismo para tareas de regresión
make_regression(), agrupación make_blobs()y clasificación make_classification().
Cada método produce datos ya desglosados en X (características) e Y (variable de destino) para que puedan usarse directamente para entrenar el modelo.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Acceso a conjuntos de datos públicos de terceros
Si desea acceder a una variedad de conjuntos de datos públicos directamente a través de scikit-learn, consulte la práctica función que le permite importar datos directamente desde openml.org . Este sitio contiene más de 21.000 conjuntos de datos diferentes que se pueden utilizar en proyectos de aprendizaje automático.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Clasificadores listos para entrenar modelos de referencia
Al crear un modelo de aprendizaje automático para un proyecto, es aconsejable crear primero un modelo de referencia. Es un modelo ficticio que siempre predice la clase más común. Esto le dará puntos de referencia para comparar su modelo más complejo. Además, puede estar seguro de la calidad de su trabajo, por ejemplo, que produce más que un conjunto de datos seleccionados al azar.
La biblioteca scikit-learn tiene una
DummyClassifier()para problemas de clasificación y DummyRegressor()para trabajar con regresión.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. API propia para visualización
Scikit-learn tiene una API de visualización incorporada que le permite visualizar cómo funciona su modelo sin importar ninguna otra biblioteca. Proporciona las siguientes opciones: gráficos de dependencia, matriz de error, curvas ROC y Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()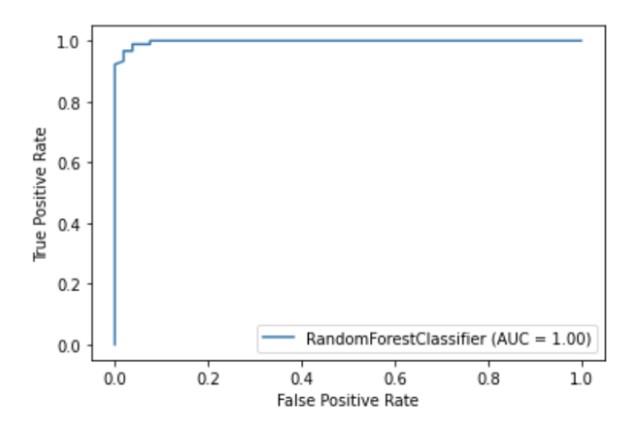
Ilustración del autor
5. Métodos integrados de selección de funciones
Una de las formas de mejorar la calidad del modelo es utilizar solo las funciones más útiles en el entrenamiento o eliminar las menos informativas. Este proceso se llama selección de características.
Scikit-learn tiene varios métodos para realizar la selección de características , uno de los cuales es
SelectPercentile(). Este método selecciona el percentil X de las características más informativas en función del método estadístico de estimación especificado.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Canalizaciones para conectar etapas en el proceso de aprendizaje automático
Además de poder utilizar una gran lista de algoritmos de aprendizaje automático, scikit-learn también proporciona una serie de funciones para el preprocesamiento y la transformación de datos. Para garantizar la reproducibilidad y accesibilidad en el proceso de aprendizaje automático en scikit-learn se creó Pipeline , que reúne los diferentes pasos y etapa de preprocesamiento del modelo de entrenamiento.
La canalización almacena todas las etapas del flujo de trabajo como un único objeto al que pueden llamar los métodos de ajuste y predicción. Cuando ejecuta el método de ajuste en un objeto de canalización, los pasos de preprocesamiento y entrenamiento del modelo se realizan automáticamente.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer para variar los métodos de preprocesamiento para diferentes funciones
Muchos conjuntos de datos contienen diferentes tipos de características, que requieren varias etapas diferentes para preprocesarse. Por ejemplo, es posible que se enfrente a una combinación de datos categóricos y numéricos, y que desee escalar columnas numéricas y convertir características categóricas en numéricas mediante la codificación one-hot.
La canalización de scikit-learn está equipada con una función ColumnTransformer , que le permite indicar fácilmente el método de preprocesamiento más apropiado para columnas específicas mediante la indexación o especificando los nombres de las columnas.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Obtenga fácilmente una imagen HTML de su canalización
Las canalizaciones a menudo se vuelven bastante complejas, especialmente cuando se trabaja con datos reales. Por lo tanto, es muy conveniente que pueda usar scikit-learn para mostrar el diagrama HTML de los pasos de su canalización.
from sklearn import set_config
set_config(display='diagram')
lr
Ilustración del autor
9. Función de trazado para visualizar árboles de decisión
La función le
plot_tree()permite crear un diagrama de los pasos presentes en el modelo de árbol de decisión.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Muchas bibliotecas de terceros que amplían las funciones de scikit-learn
Hay muchas bibliotecas de terceros que son compatibles con scikit-learn y amplían su funcionalidad.
Por ejemplo, la biblioteca Category Encoders , que ofrece una selección más amplia de métodos de preprocesamiento para características categóricas, o la biblioteca ELI5 , para una interpretación más detallada del modelo.
También se puede acceder a ambos recursos directamente a través de la canalización de scikit-learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))¡Gracias por su atención!