- En resumen, ¿qué plan tendremos? Primero, hablaremos sobre por qué vamos a aprender Python. Luego veamos cómo funciona el intérprete CPython con más profundidad, cómo administra la memoria, cómo funciona el sistema de tipos en Python, diccionarios, generadores y excepciones. Creo que tardará aproximadamente una hora.
- ¿Por qué Python?
- Dispositivo de intérprete
- Mecanografía
- Diccionarios
- Gestión de la memoria
- Generadores
- Excepciones
¿Por qué Python?
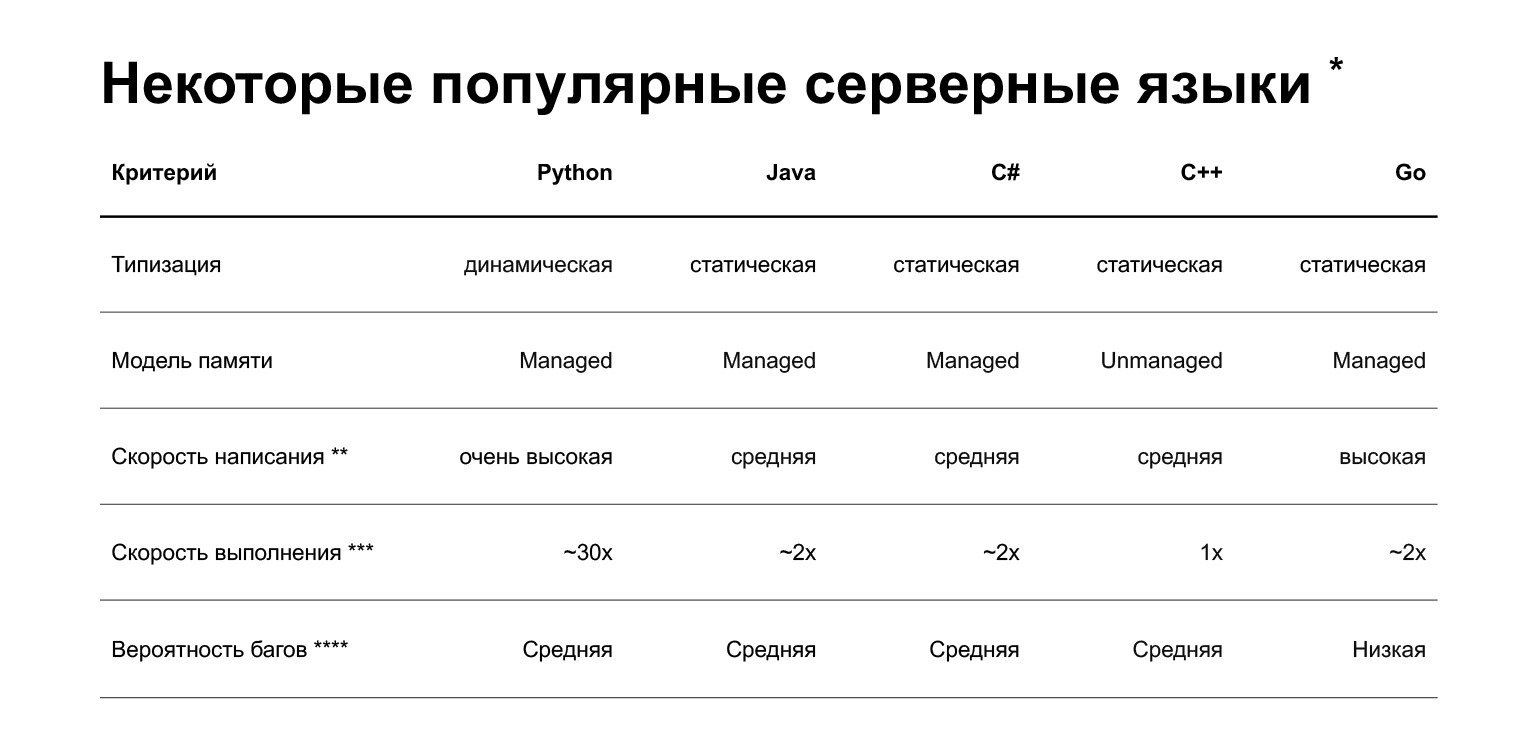
* insights.stackoverflow.com/survey/2019
** muy subjetiva
*** interpretación de la investigación
**** interpretación de la investigación
Empecemos. ¿Por qué Python? La diapositiva muestra una comparación de varios lenguajes que se utilizan actualmente en el desarrollo de backend. Pero, en resumen, ¿cuál es la ventaja de Python? Puede escribir código rápidamente en él. Esto, por supuesto, es muy subjetivo: las personas que escriben C ++ o Go geniales pueden discutir esto. Pero, en promedio, escribir en Python es más rápido.
¿Cuales son las desventajas? La primera y probablemente la principal desventaja es que Python es más lento. Puede ser 30 veces más lento que otros idiomas, aquí hay unestudiosobre este tema. Pero su velocidad depende de la tarea. Hay dos clases de tareas:
- CPU enlazadas, tareas enlazadas a la CPU, enlazadas a la CPU.
- E / S enlazadas, tareas limitadas por entrada-salida: ya sea a través de la red o en bases de datos.
Si está resolviendo el problema de la CPU, entonces sí, Python será más lento. Si la E / S está vinculada, y esta es una gran clase de tareas, entonces para comprender la velocidad de ejecución es necesario ejecutar evaluaciones comparativas. Y quizás al comparar Python con otros lenguajes, ni siquiera notará la diferencia de rendimiento.
Además, Python se escribe dinámicamente: el intérprete no comprueba los tipos en tiempo de compilación. En la versión 3.5, aparecieron sugerencias de tipo, lo que le permite especificar tipos estáticamente, pero no son muy estrictos. Es decir, detectará algunos errores ya en producción y no en la etapa de compilación. Otros lenguajes populares para el backend (Java, C #, C ++, Go) tienen escritura estática: si pasa el objeto incorrecto en el código, el compilador le informará al respecto.
Más realista, ¿cómo se usa Python en el desarrollo de productos de taxi? Avanzamos hacia una arquitectura de microservicios. Ya tenemos 160 microservicios, a saber, comestibles - 35, 15 de ellos en Python, 20 - con ventajas. Es decir, ahora estamos escribiendo solo en Python o con ventajas.
¿Cómo elegimos el idioma? El primero son los requisitos de carga, es decir, vemos si Python puede manejarlo o no. Si tira, entonces miramos la competencia de los desarrolladores del equipo.
Ahora quiero hablar del intérprete. ¿Cómo funciona CPython?
Dispositivo de intérprete
Puede surgir la pregunta: ¿por qué necesitamos saber cómo trabaja el intérprete? La pregunta es válida. Puede escribir servicios fácilmente sin saber qué hay debajo del capó. Las respuestas pueden ser las siguientes:
1. Optimización para cargas elevadas. Imagina que tienes un servicio de Python. Funciona, la carga es baja. Pero un día te llega la tarea: escribir un bolígrafo, listo para una carga pesada. No puede escapar de esto, no puede reescribir todo el servicio en C ++. Por lo tanto, debe optimizar el servicio para cargas elevadas. Comprender cómo trabaja el intérprete puede ayudar con esto.
2. Depuración de casos complejos. Digamos que el servicio se está ejecutando, pero la memoria comienza a "perder" en él. En Yandex.Taxi, tuvimos un caso así recientemente. El servicio consumía 8 GB de memoria cada hora y fallaba. Necesitamos resolverlo. Se trata del lenguaje, Python. Se requiere conocimiento de cómo funciona la administración de memoria en Python.
3. Esto es útil si va a escribir bibliotecas complejas o código complejo.
4. Y en general, se considera de buena forma conocer la herramienta con la que estás trabajando a un nivel más profundo, y no solo como usuario. Esto se aprecia en Yandex.
5. Hacen preguntas al respecto en las entrevistas, pero ese ni siquiera es el punto, sino su perspectiva general de TI.

Recordemos brevemente qué tipos de traductores son. Contamos con compiladores e intérpretes. El compilador, como probablemente sepa, es lo que traduce su código fuente directamente en código de máquina. Más bien, el intérprete traduce primero al código de bytes y luego lo ejecuta. Python es un lenguaje interpretado.
Bytecode es un tipo de código intermedio que se obtiene del original. No está vinculado a la plataforma y se ejecuta en una máquina virtual. ¿Por qué virtual? Esta no es una máquina real, sino una especie de abstracción.

¿Qué tipos de máquinas virtuales existen? Regístrese y apile. Pero aquí debemos recordar no esto, sino el hecho de que Python es una máquina de pila. A continuación, veremos cómo funciona la pila.
Y una advertencia más: aquí solo hablaremos de CPython. CPython es una implementación de Python de referencia, escrita, como puede suponer, en C. Usado como sinónimo: cuando hablamos de Python, generalmente hablamos de CPython.
Pero también hay otros intérpretes. Está PyPy, que usa la compilación JIT y se acelera unas cinco veces. Rara vez se usa. Sinceramente, no me he encontrado. Hay JPython, hay IronPython, que traduce el código de bytes para la máquina virtual Java y para la máquina Dotnet. Esto está fuera del alcance de la conferencia de hoy; para ser honesto, no lo he encontrado. Así que echemos un vistazo a CPython.

Veamos qué pasa. Tienes una fuente, una línea, quieres ejecutarla. ¿Qué hace el intérprete? Una cadena es solo una colección de caracteres. Para hacer algo significativo con él, primero traduce el código en tokens. Un token es un conjunto agrupado de caracteres, un identificador, un número o algún tipo de iteración. De hecho, el intérprete traduce el código en tokens.

Además, el árbol de sintaxis abstracta, AST se construye a partir de estos tokens. Además, no te molestes todavía, estos son solo algunos árboles, en los nodos de los cuales tienes operaciones. Digamos que en nuestro caso existe BinOp, una operación binaria. Operación: exponenciación, operandos: el número a aumentar y la potencia a aumentar.
Además, ya puede compilar código utilizando estos árboles. Me pierdo muchos pasos, hay un paso de optimización, otros pasos. Luego, estos árboles de sintaxis se traducen en código de bytes.
Veamos con más detalle aquí. Un código de bytes es, como su nombre lo indica, un código formado por bytes. Y en Python, a partir de 3.6, el código de bytes es de dos bytes.

El primer byte es el propio operador, denominado código de operación. El segundo byte es el argumento oparg. Parece que lo tenemos desde arriba. Es decir, alguna secuencia de bytes. Pero Python tiene un módulo llamado dis, de Disassembler, con el que podemos ver una representación más legible por humanos.
Cómo se ve? Hay un número de línea de la fuente, el más a la izquierda. La segunda columna es la dirección. Como dije, el bytecode en Python 3.6 toma dos bytes, por lo que todas las direcciones son pares y vemos 0, 2, 4 ...
Load.name, Load.const ya son las opciones de código en sí mismas, es decir, los códigos de esas operaciones que Python debería ejecutarse. 0, 0, 1, 1 son oparg, es decir, los argumentos de estas operaciones. Veamos cómo se hacen a continuación.
(...) Veamos cómo se ejecuta el bytecode en Python, qué estructuras hay para esto.

Si no conoce C, está bien. Las notas al pie son para comprensión general.
Python tiene dos estructuras que nos ayudan a ejecutar bytecode. El primero es CodeObject, puedes ver su resumen. De hecho, la estructura es más grande. Este es un código sin contexto. Esto significa que esta estructura contiene, de hecho, el código de bytes que acabamos de ver. Contiene los nombres de las variables utilizadas en esta función, si la función contiene referencias a constantes, nombres de constantes, algo más.

La siguiente estructura es FrameObject. Este ya es el contexto de ejecución, la estructura que ya contiene el valor de las variables; referencias a variables globales; la pila de ejecución, de la que hablaremos un poco más adelante, y mucha otra información. Digamos el número de ejecución de la instrucción.
Como ejemplo: si desea llamar a una función varias veces, tendrá el mismo CodeObject y se creará un nuevo FrameObject para cada llamada. Tendrá sus propios argumentos, su propia pila. Entonces están interconectados.

¿Cuál es el bucle principal del intérprete, cómo se ejecuta el código de bytes? Viste que teníamos una lista de estos códigos de operación con oparg. ¿Cómo se hace todo esto? Python, como cualquier intérprete, tiene un ciclo que ejecuta este código de bytes. Es decir, ingresa un marco y Python simplemente recorre el código de bytes en orden, mira qué tipo de oparg es y va a su controlador usando un interruptor enorme. Aquí solo se muestra un código de operación, por ejemplo. Por ejemplo, aquí tenemos una resta binaria, una resta binaria, digamos que "AB" se realizará en este lugar.
Expliquemos cómo funciona la resta binaria. Muy simple, este es uno de los códigos más simples. La función TOP toma el valor más alto de la pila, lo saca del más alto, no solo lo saca de la pila, y luego se llama a la función PyNumber_Subtract. Resultado: la función SET_TOP de barra inclinada se devuelve a la pila. Si no está claro acerca de la pila, seguirá un ejemplo.

Muy brevemente sobre el GIL. El GIL es un mutex a nivel de proceso en Python que toma este mutex en el bucle principal del intérprete. Y solo después de eso, el código de bytes comienza a ejecutarse. Esto se hace para que solo un hilo ejecute el código de bytes a la vez, con el fin de proteger la estructura interna del intérprete.
Digamos, yendo un poco más allá, que todos los objetos en Python tienen varias referencias a ellos. Y si dos hilos cambian este número de enlaces, el intérprete se romperá. Por tanto, existe un GIL.
Se le informará sobre esto en la conferencia sobre programación asincrónica. ¿Cómo puede esto ser importante para ti? El subproceso múltiple no se usa, porque incluso si crea varios subprocesos, entonces en general solo tendrá uno de ellos ejecutado, el código de bytes se ejecutará en uno de los subprocesos. Por lo tanto, use multiprocesamiento, extensión sish o algo más.

Un pequeño ejemplo. Puede explorar este marco de forma segura desde Python. Hay un módulo sys que tiene una función de subrayado get_frame. Puede obtener un marco y ver qué variables hay. Hay una instrucción. Esto es más para enseñar, en la vida real no lo usé.
Intentemos ver cómo funciona la pila de la máquina virtual Python para la comprensión. Tenemos un código bastante simple que no comprende lo que hace.
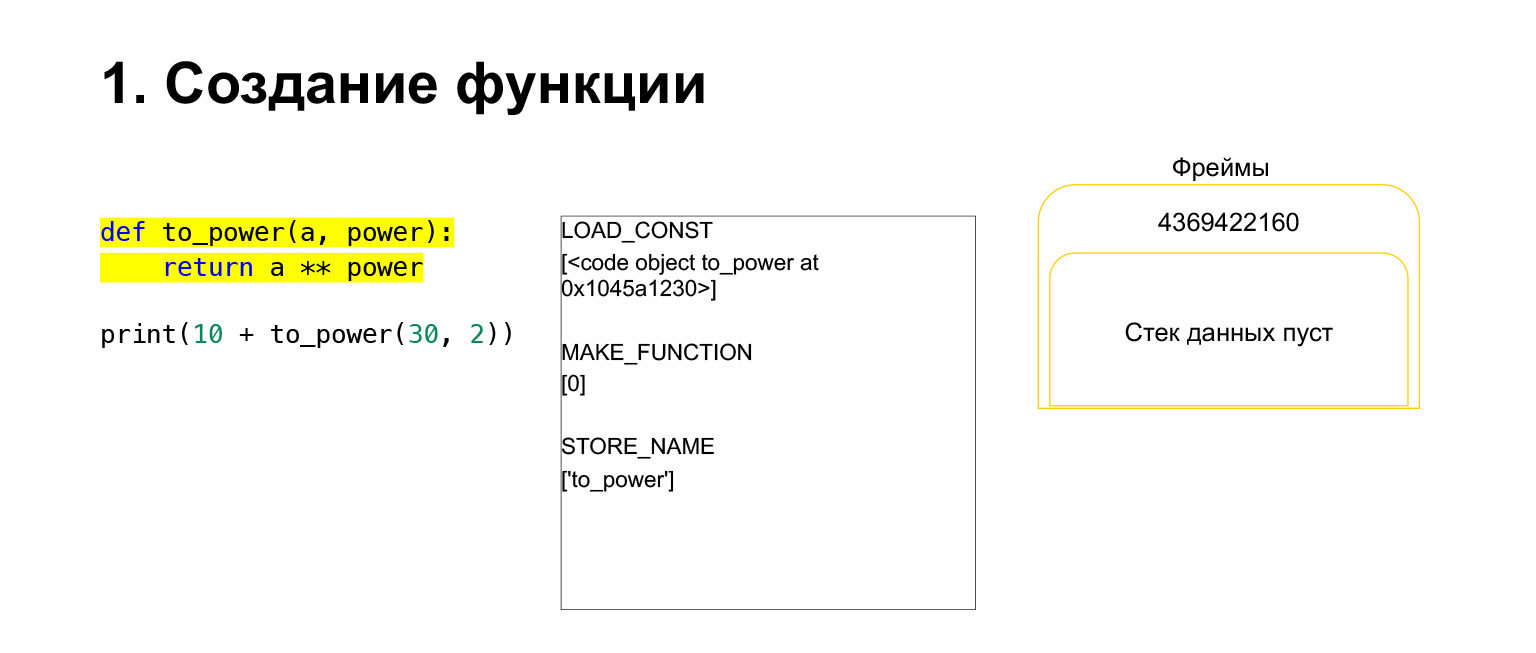
A la izquierda está el código. La parte que ahora estamos examinando está resaltada en amarillo. En la segunda columna, tenemos el bytecode de esta pieza. La tercera columna contiene marcos con pilas. Es decir, cada FrameObject tiene su propia pila de ejecución.
¿Qué hace Python? Simplemente va en orden, bytecode, en la columna del medio, se ejecuta y trabaja con la pila.
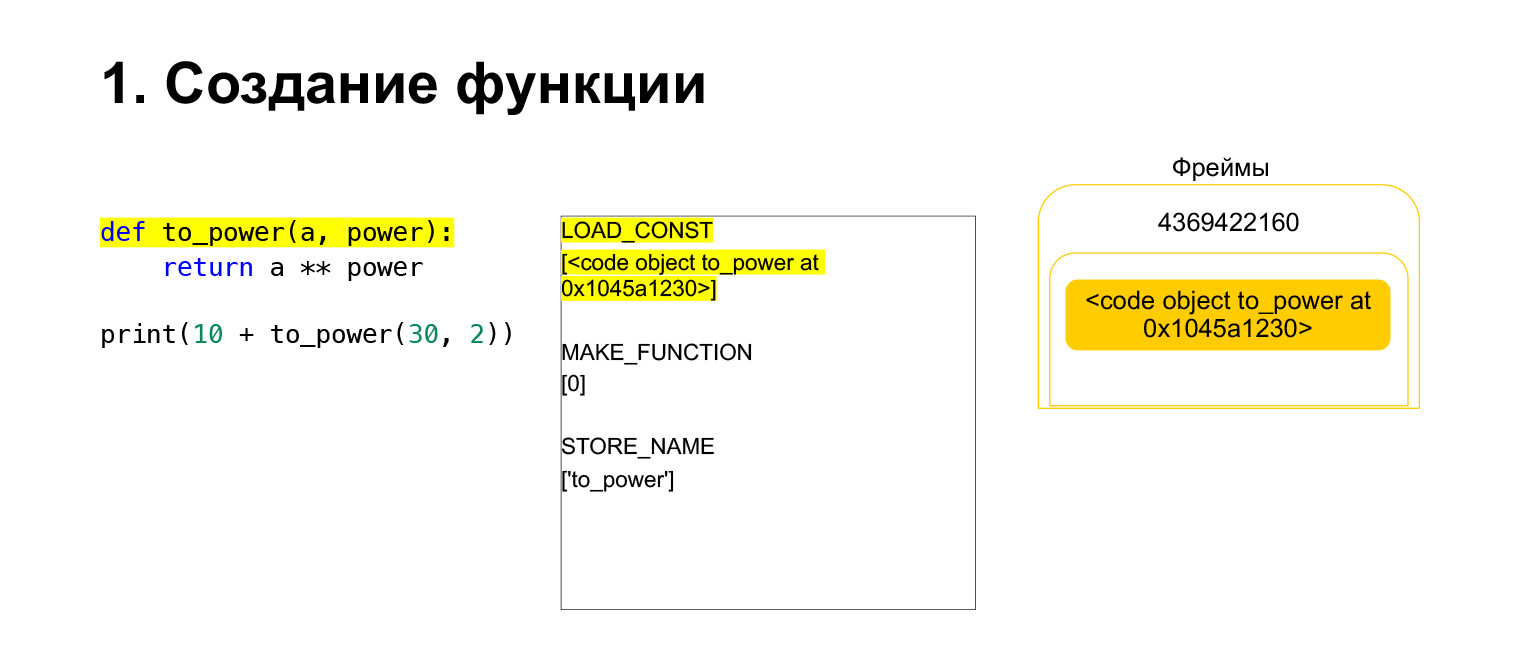
Hemos ejecutado el primer código de operación llamado LOAD_CONST. Carga una constante. Saltamos la parte, se crea un CodeObject allí y teníamos un CodeObject en algún lugar de las constantes. Python lo cargó en la pila usando LOAD_CONST. Ahora tenemos un CodeObject en la pila en este marco. Podemos seguir adelante.
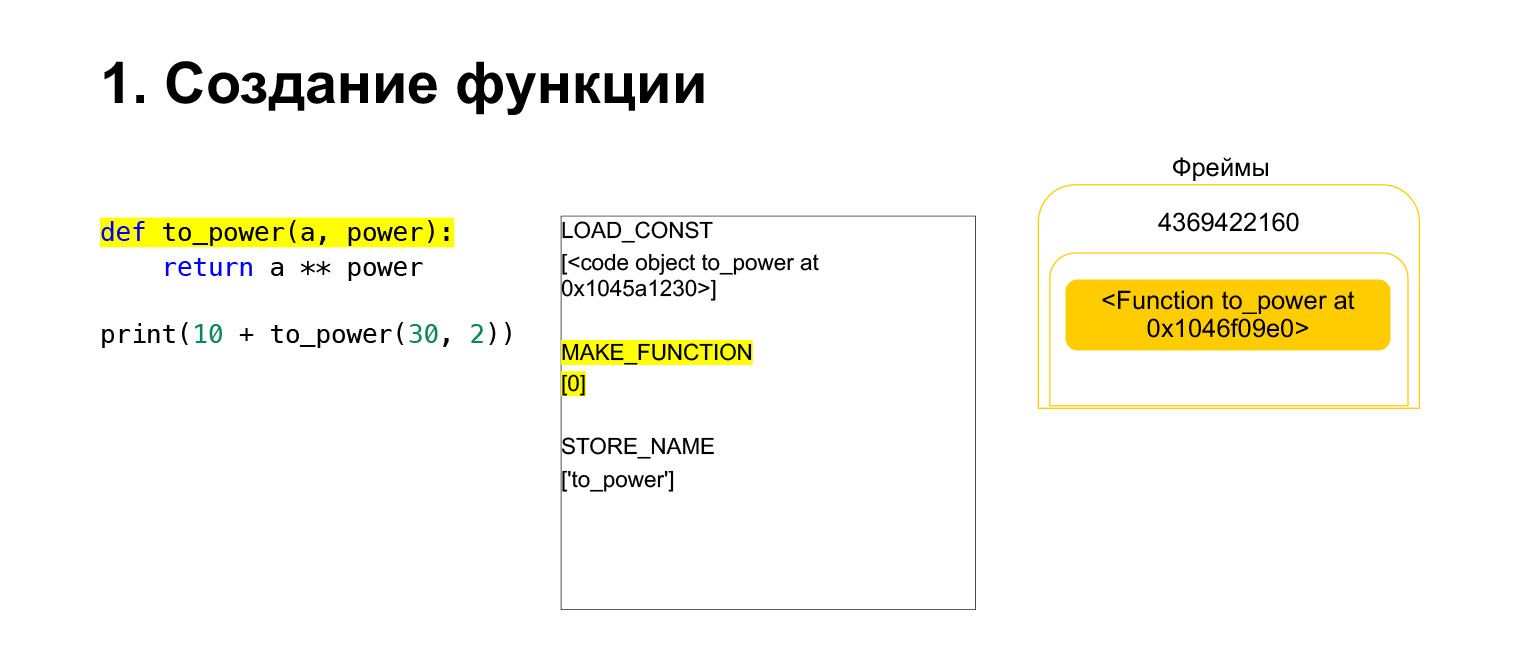
Entonces Python realiza el código de operación MAKE_FUNCTION. MAKE_FUNCTION obviamente hace una función. Se espera que tenga un CodeObject en la pila. Realiza alguna acción, crea una función y devuelve la función a la pila. Ahora tiene FUNCTION en lugar de CodeObject que estaba en la pila de marcos. Y ahora esta función debe colocarse en la variable to_power para que pueda consultarla.
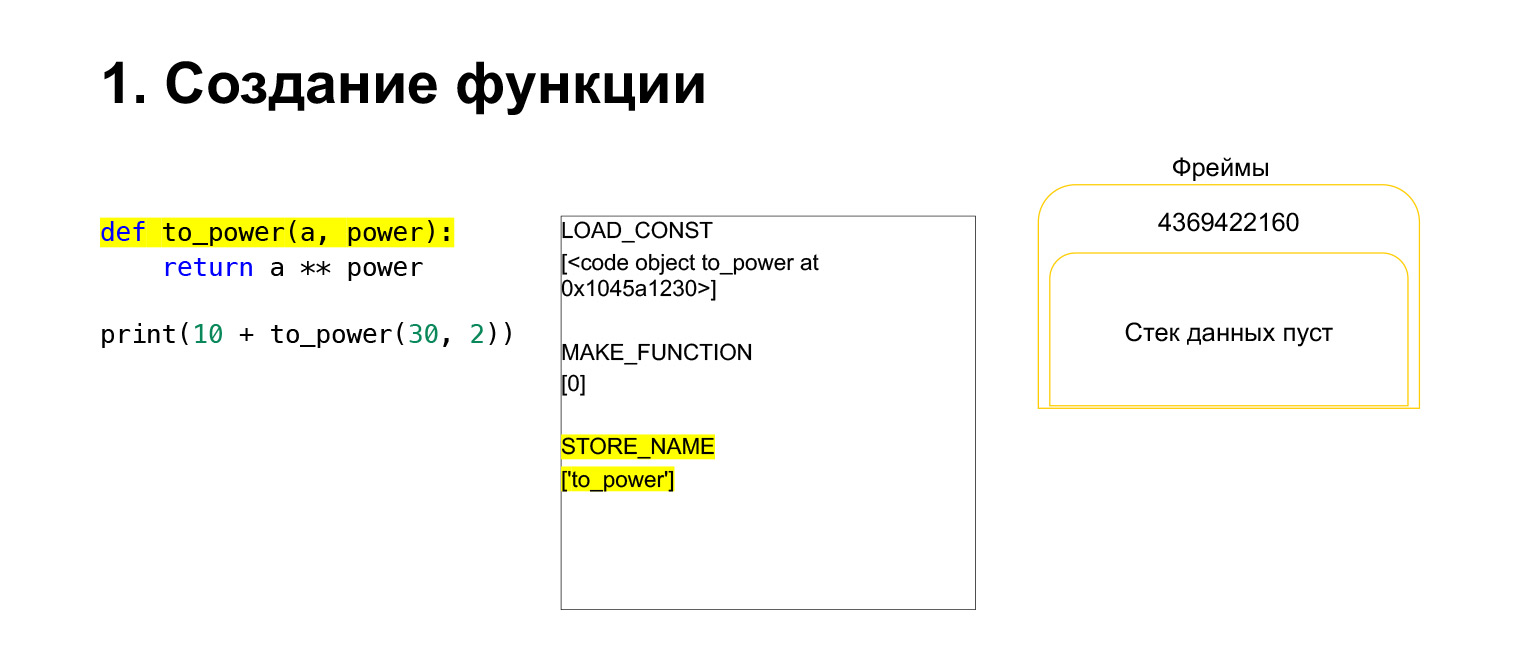
Se ejecuta el código de operación STORE_NAME, se coloca en la variable to_power. Teníamos una función en la pila, ahora es la variable to_power, puede consultarla.
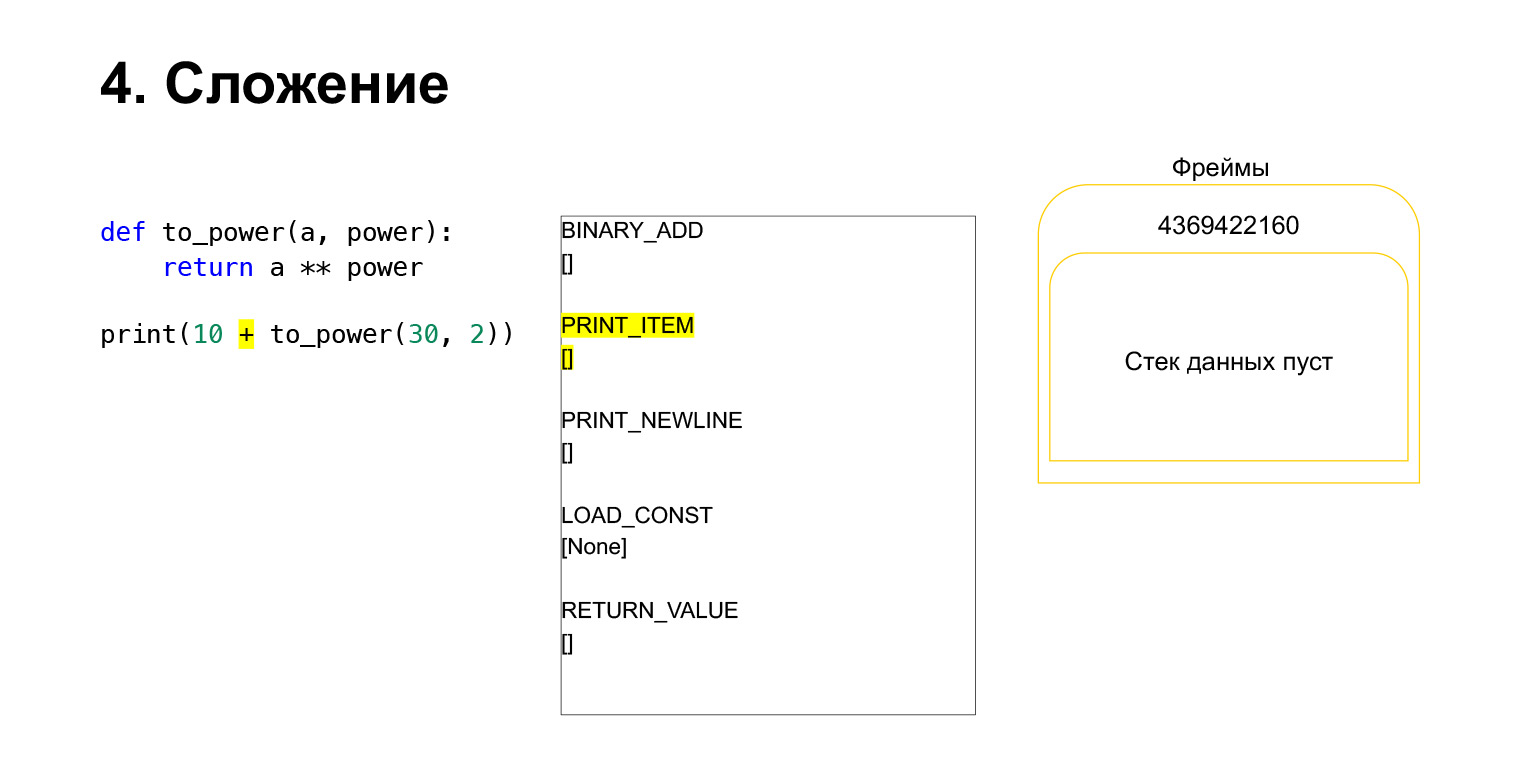
A continuación, queremos imprimir 10 + el valor de esta función.
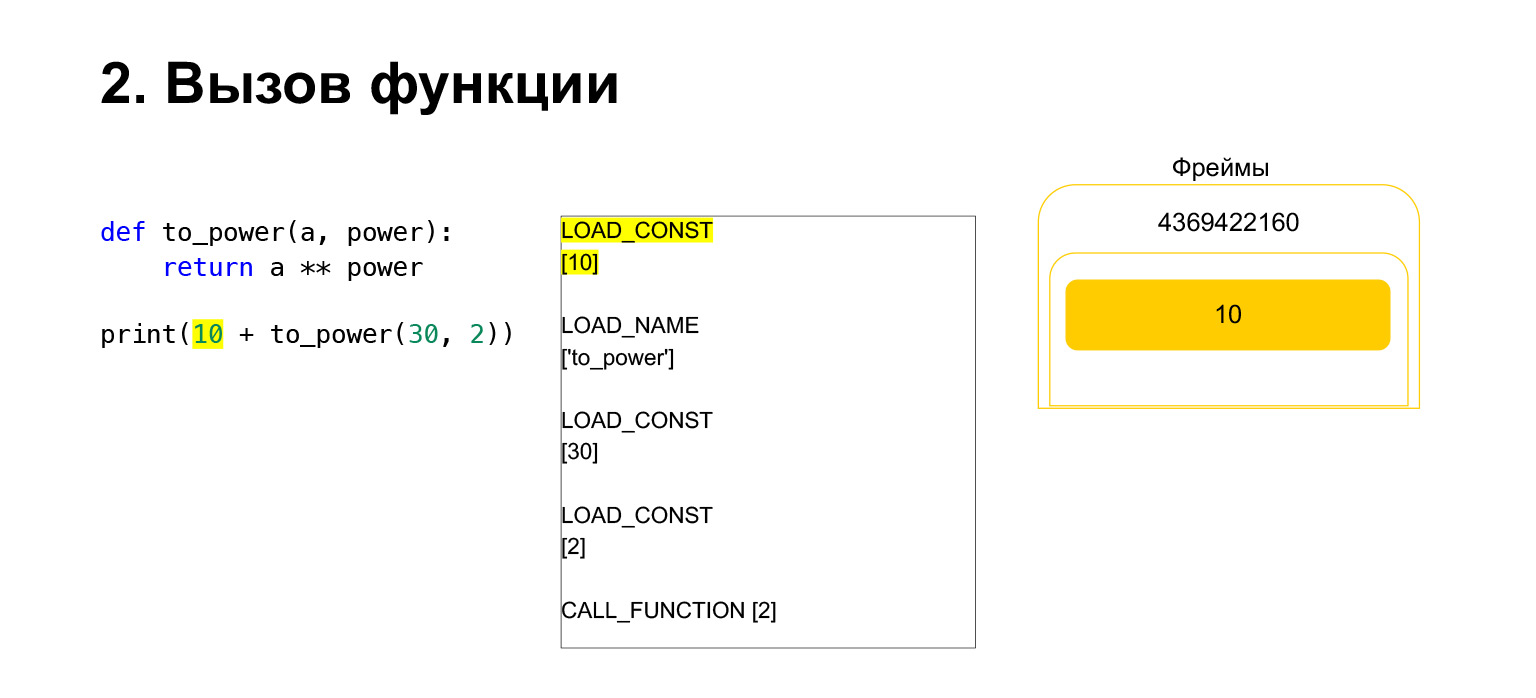
¿Qué hace Python? Esto se convirtió a código de bytes. El primer código de operación que tenemos es LOAD_CONST. Cargamos los diez primeros en la pila. Aparecieron una docena en la pila. Ahora necesitamos ejecutar to_power.

La función se realiza de la siguiente manera. Si tiene argumentos posicionales, no veremos el resto por ahora, entonces primero Python coloca la función en la pila. Luego ingresa todos los argumentos y llama a CALL_FUNCTION con el número de argumentos de la función.
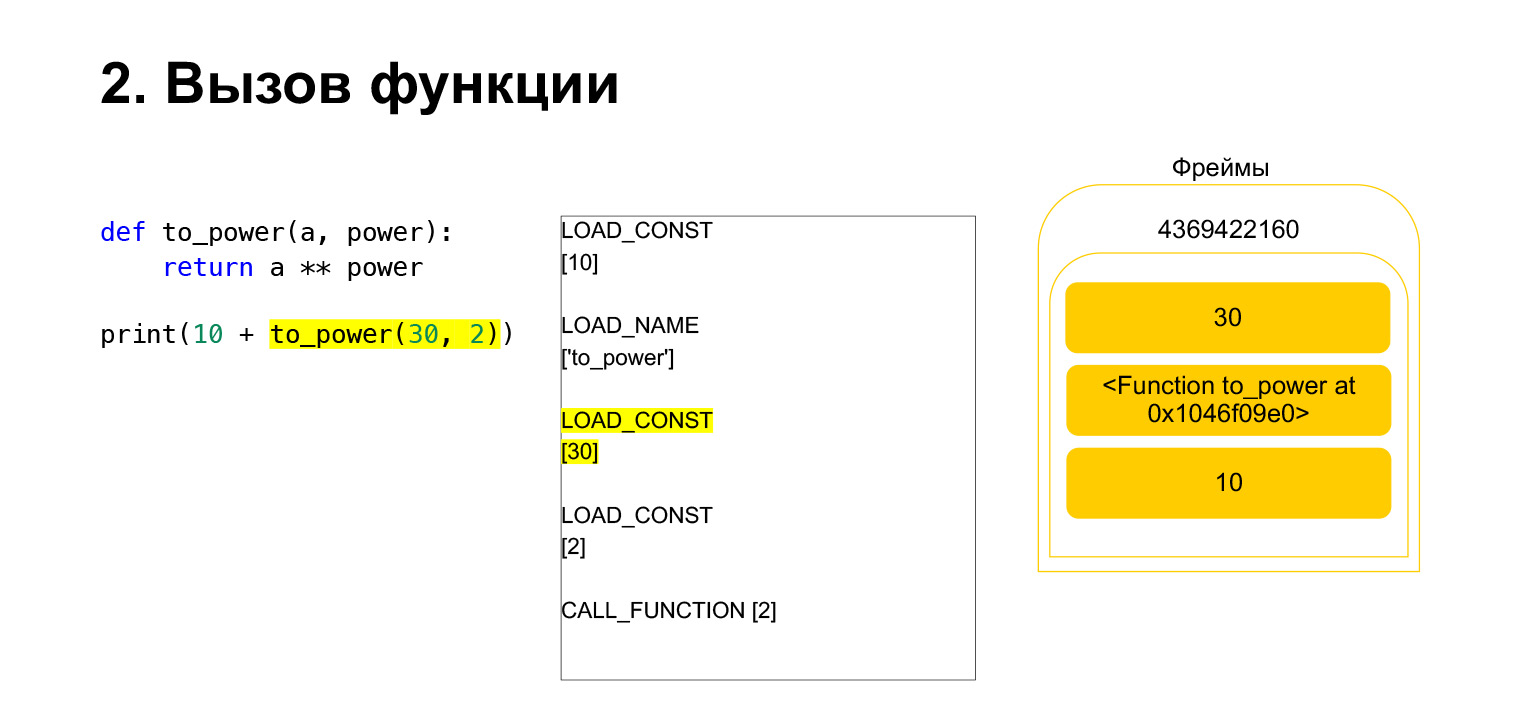
Cargamos el primer argumento en la pila, esta es una función.
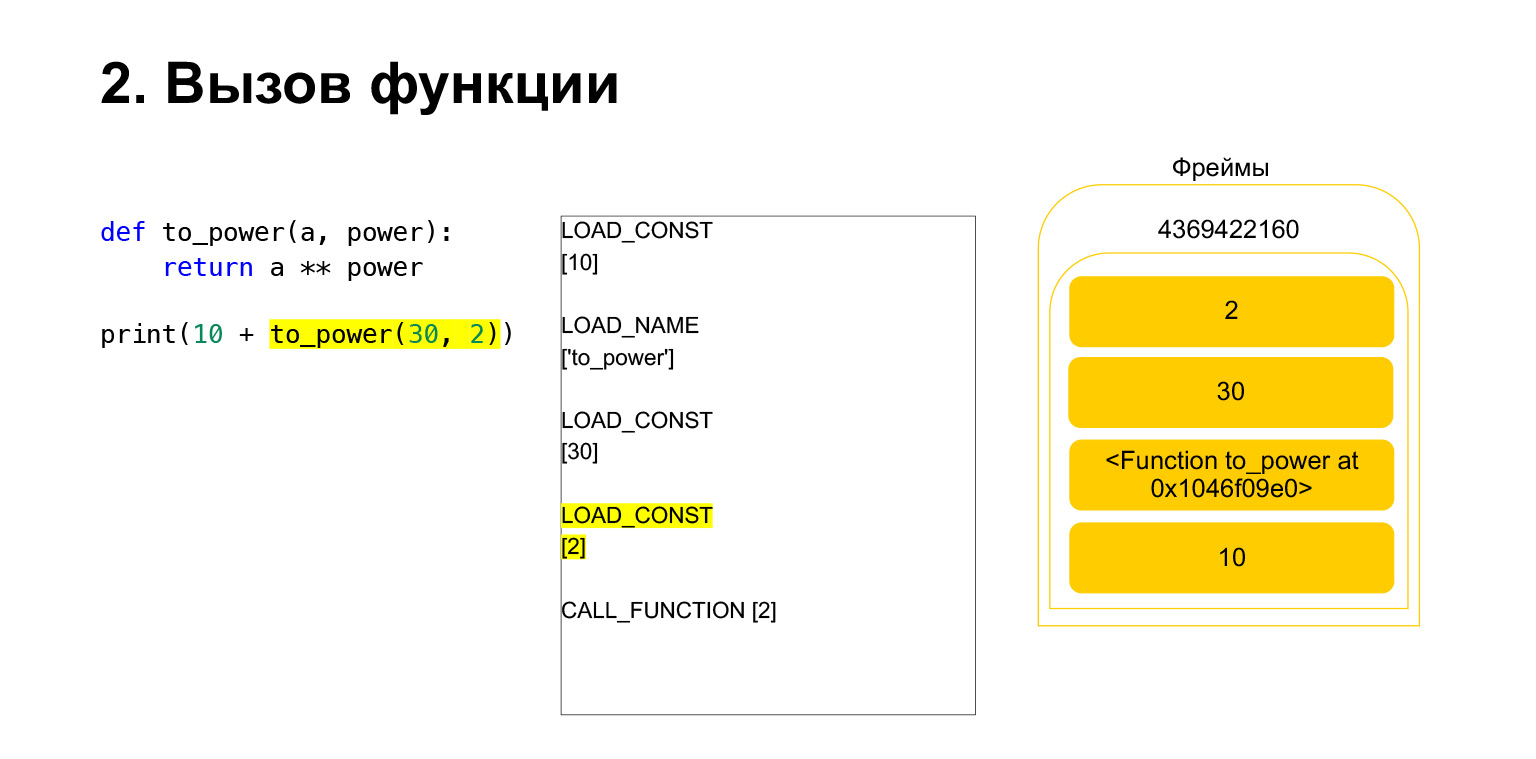
Cargamos dos argumentos más en la pila: 30 y 2. Ahora tenemos una función y dos argumentos en la pila. La parte superior de la pila está arriba. CALL_FUNCTION nos espera. Decimos: CALL_FUNCTION (2), es decir, tenemos una función con dos argumentos. CALL_FUNCTION espera tener dos argumentos en la pila, seguidos de una función. Lo tenemos: 2, 30 y FUNCIÓN.
Código de operación en curso.
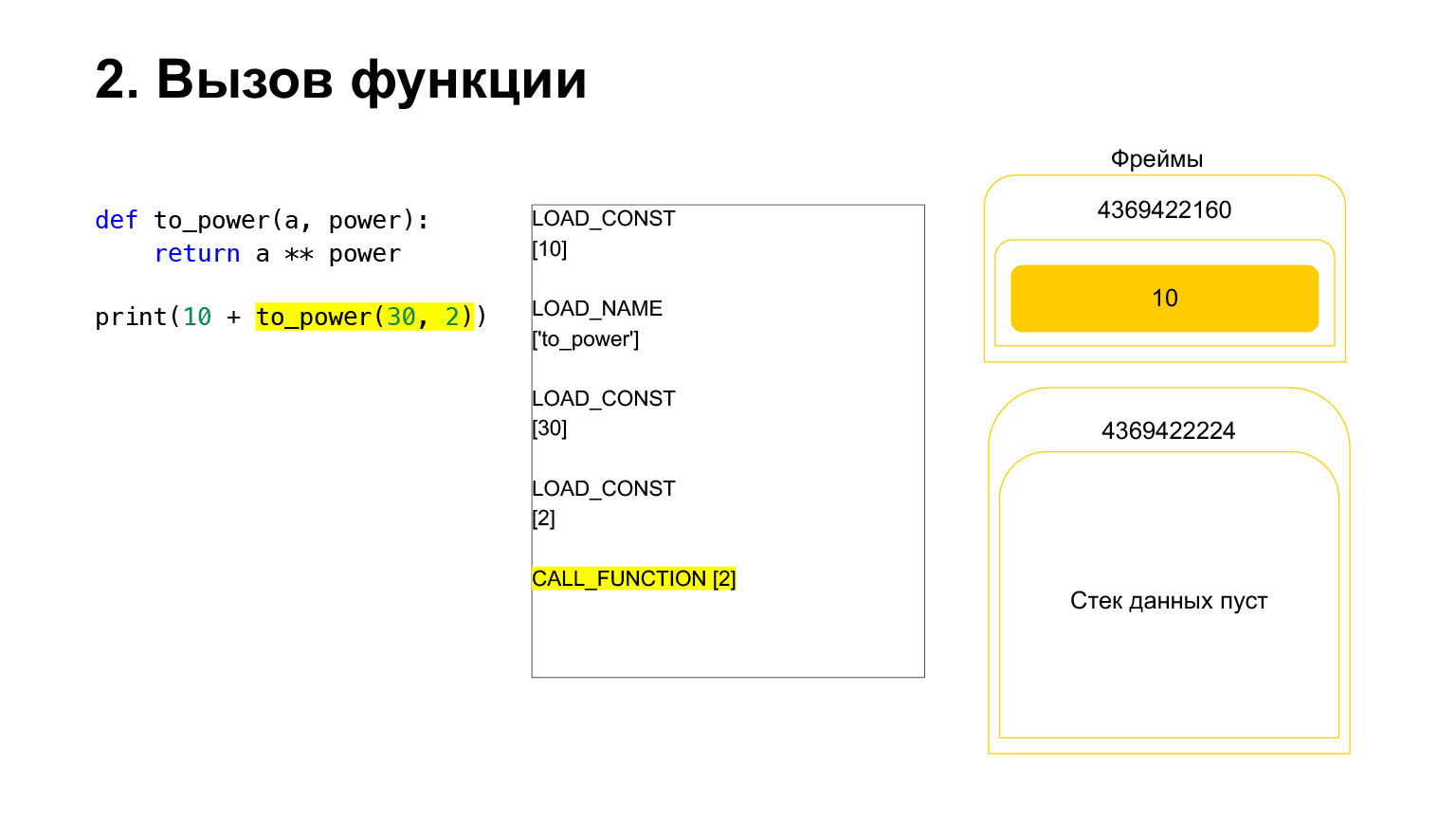
Para nosotros, en consecuencia, esa pila se va, se crea una nueva función, en la que ahora tendrá lugar la ejecución.
El marco tiene su propia pila. Se ha creado un nuevo marco para su función. Todavía está vacío.
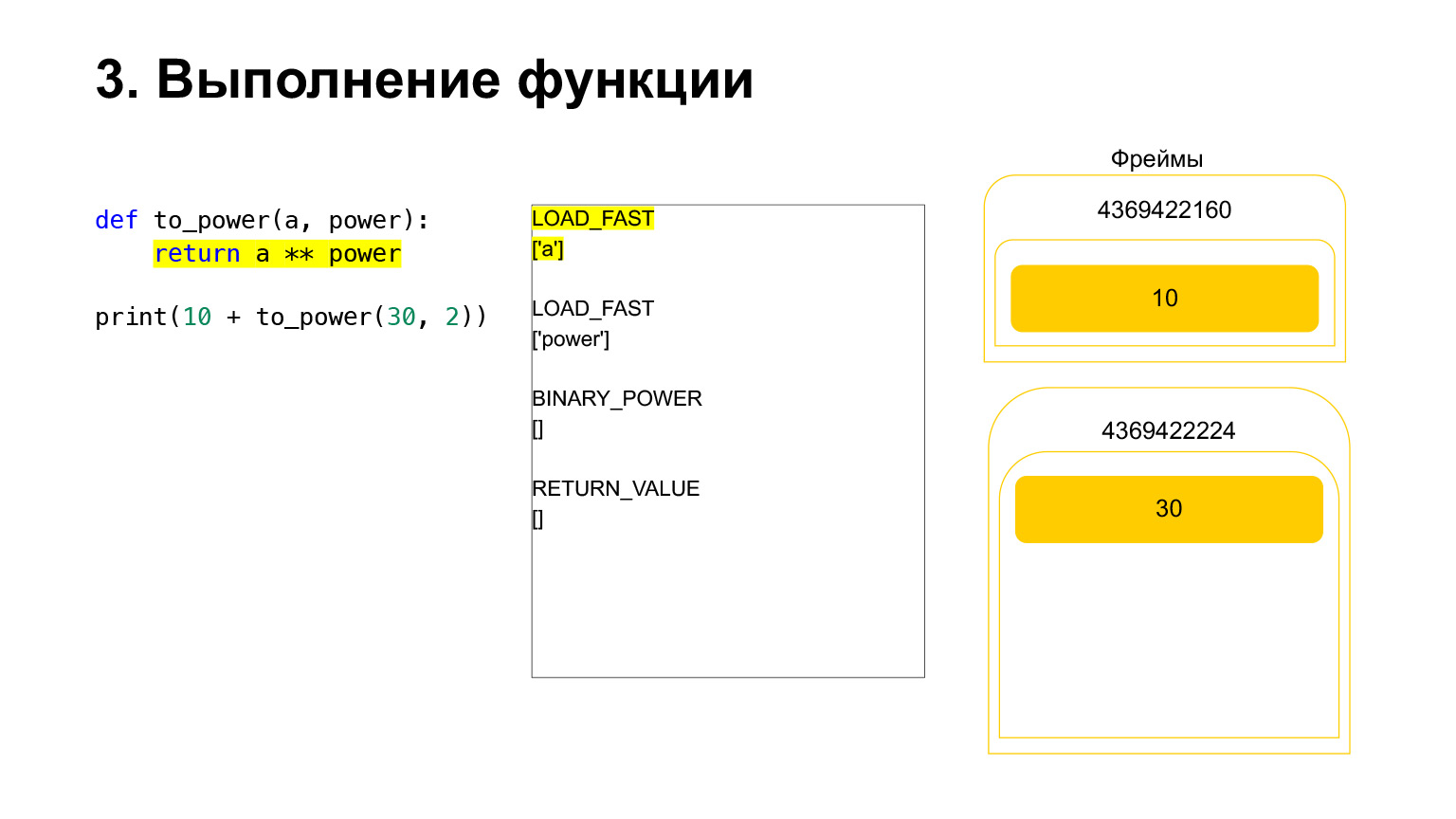
Tiene lugar una ejecución adicional. Ya es más fácil aquí. Necesitamos elevar a A al poder.
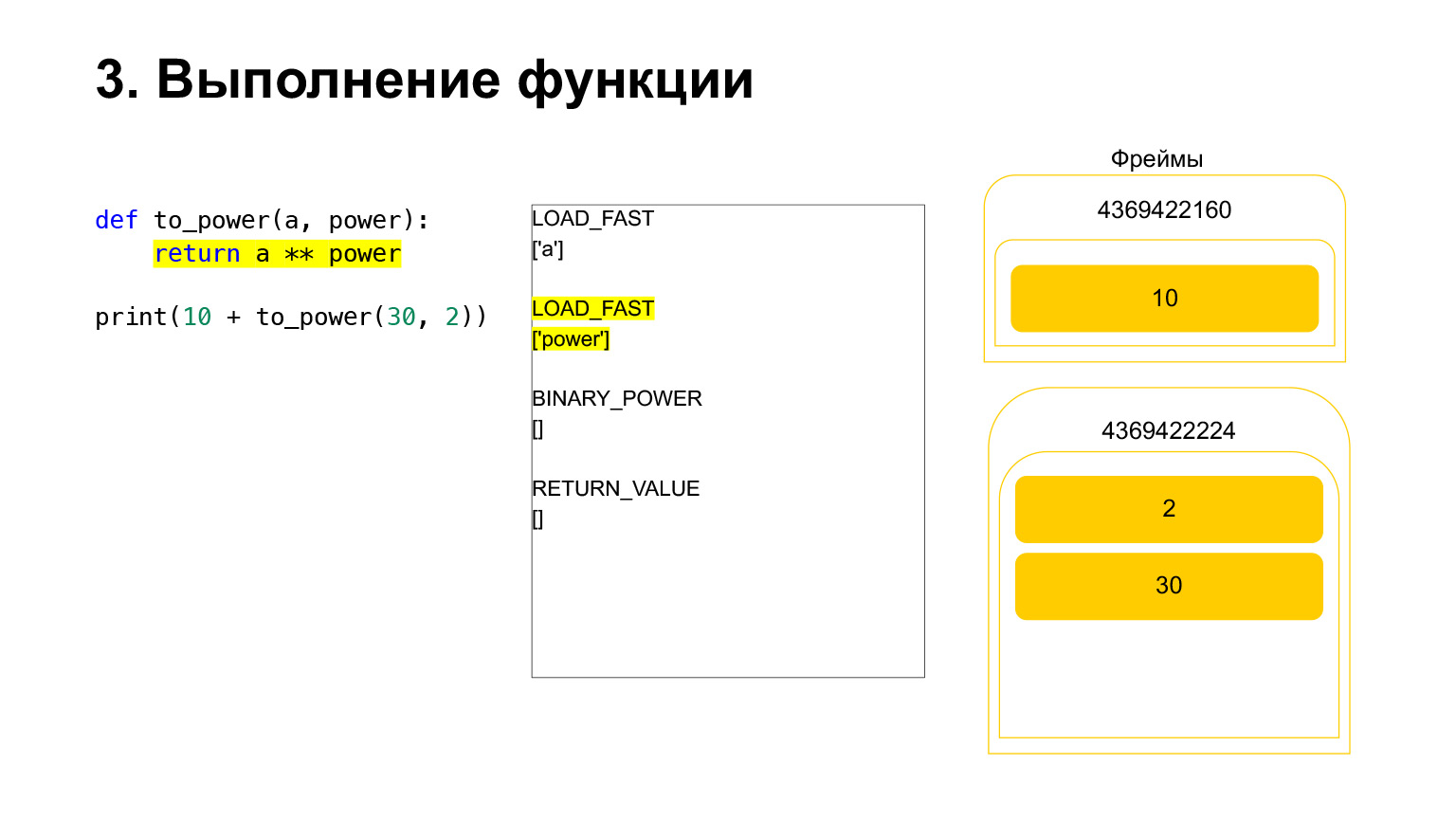
Cargamos en la pila el valor de la variable A - 30. El valor de la variable power - 2. Y se ejecuta el código de operación BINARY_POWER.
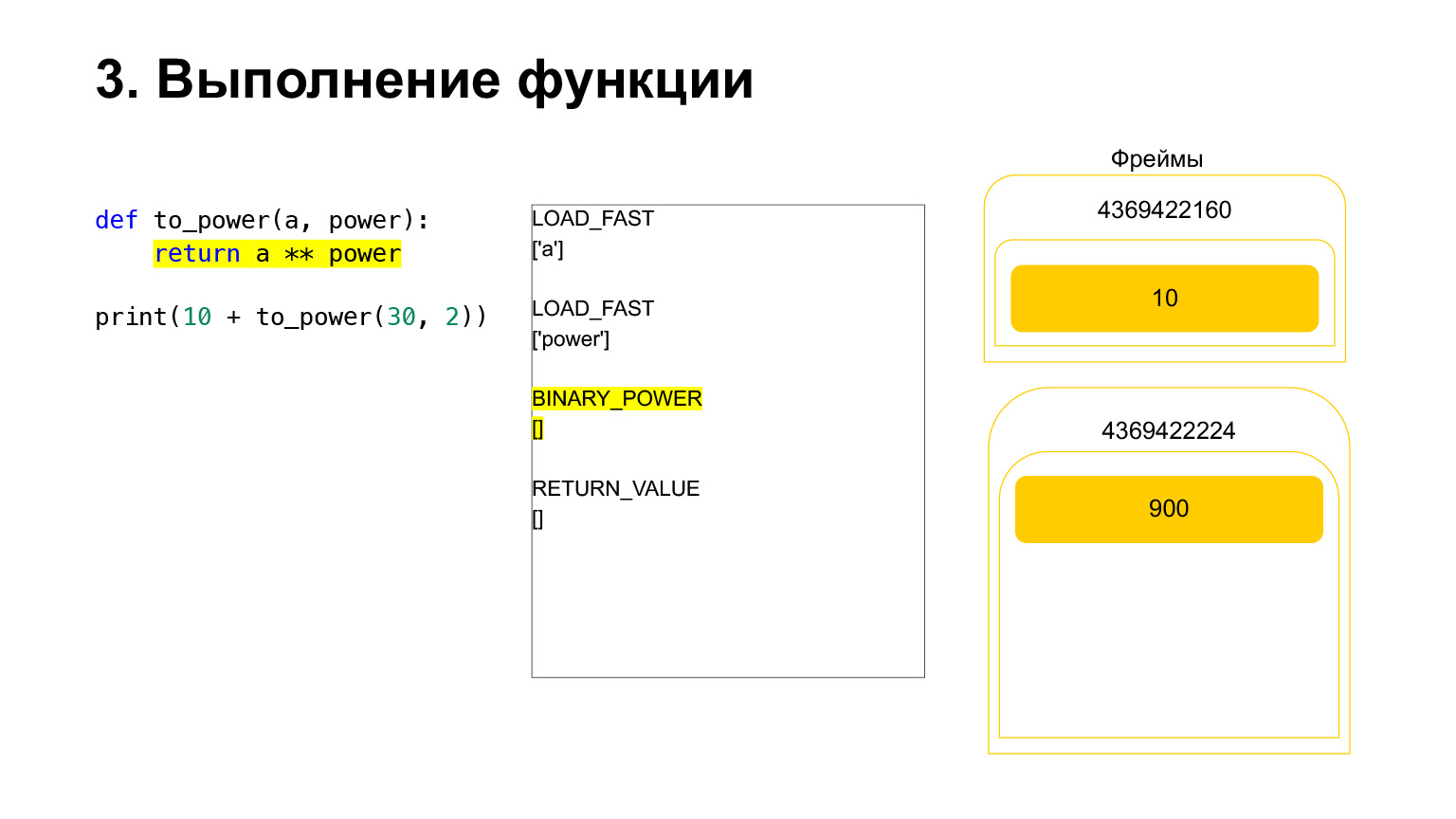
Elevamos un número a la potencia de otro y lo volvemos a poner en la pila. Resultó 900 en la pila de funciones.
El siguiente código de operación RETURN_VALUE devolverá el valor de la pila al marco anterior.

Así es como se lleva a cabo la ejecución. La función se ha completado, lo más probable es que el marco se borre si no tiene referencias y habrá dos números en el marco de la función anterior.

Entonces todo es más o menos igual. Se produce la adición.
(...) Hablemos de tipos y PyObject.
Mecanografía

Un objeto es una estructura sish, en la que hay dos campos principales: el primero es el número de referencias a este objeto, el segundo es el tipo de objeto, por supuesto, una referencia al tipo de objeto.
Otros objetos heredan de PyObject encerrándolo. Es decir, si miramos un float, un número de coma flotante, la estructura allí es PyFloatObject, entonces tiene un HEAD, que es una estructura PyObject, y, además, datos, es decir, double ob_fval, donde se almacena el valor de este flotante en sí.

Y este es el tipo de objeto. Acabamos de ver el tipo en PyObject, es una estructura que denota un tipo. De hecho, también es una estructura C que contiene punteros a funciones que implementan el comportamiento de este objeto. Es decir, hay una estructura muy grande allí. Tiene funciones especificadas que se llaman si, por ejemplo, desea agregar dos objetos de este tipo. O desea restar, llamar a este objeto o crearlo. Todo lo que pueda hacer con los tipos debe especificarse en esta estructura.

Por ejemplo, veamos int, enteros en Python. También una versión muy abreviada. ¿Qué nos puede interesar? Int tiene tp_name. Puede ver que hay tp_hash, podemos obtener hash int. Si llamamos hash en int, se llamará a esta función. tp_call tenemos cero, no definido, esto significa que no podemos llamar a int. tp_str: conversión de cadena no definida. Python tiene una función str que se puede convertir en una cadena.
No apareció en la diapositiva, pero todos ustedes ya saben que int todavía se puede imprimir. ¿Por qué hay cero aquí? Debido a que también existe tp_repr, Python tiene dos funciones de paso de cadenas: str y repr. Fundición más detallada para encordar. En realidad, está definido, simplemente no apareció en la diapositiva y se llamará si realmente conduce a una cadena.
Al final, vemos tp_new, una función que se llama cuando se crea este objeto. tp_init tenemos cero. Todos sabemos que int no es un tipo mutable, inmutable. Después de crearlo, no tiene sentido cambiarlo, inicializarlo, por lo que hay un cero.

Miremos también a Bool, por ejemplo. Como algunos de ustedes sabrán, Bool en Python en realidad hereda de int. Es decir, puede agregar Bool, compartir entre sí. Esto, por supuesto, no se puede hacer, pero es posible.
Vemos que hay un tp_base, un puntero al objeto base. Todo, además de tp_base, son las únicas cosas que se han anulado. Es decir, tiene su propio nombre, su propia función de presentación, donde no es un número el que se escribe, sino verdadero o falso. Representación como Número, algunas funciones lógicas se anulan allí. Docstring es suya y su creación. Todo lo demás proviene de int.

Te hablaré muy brevemente de las listas. En Python, una lista es una matriz dinámica. Una matriz dinámica es una matriz que funciona así: inicializa un área de memoria de antemano con alguna dimensión. Agrega elementos allí. Tan pronto como el número de elementos supere este tamaño, lo amplías con un cierto margen, es decir, no en uno, sino en algún valor más de uno, para que haya un buen punto de entrada.
En Python, el tamaño crece como 0, 4, 8, 16, 25, es decir, según algún tipo de fórmula que nos permite hacer la inserción de forma asintótica para una constante. Y puede ver que hay un extracto de la función de inserción en la lista. Es decir, estamos cambiando el tamaño. Si no tenemos resize, arrojamos un error y asignamos el elemento. En Python, esta es una matriz dinámica normal implementada en C.
(...) Hablemos brevemente de los diccionarios. Están en todas partes en Python.
Diccionarios
Todos sabemos que en los objetos, toda la composición de las clases está contenida en diccionarios. Muchas cosas se basan en ellos. Diccionarios en Python en una tabla hash.
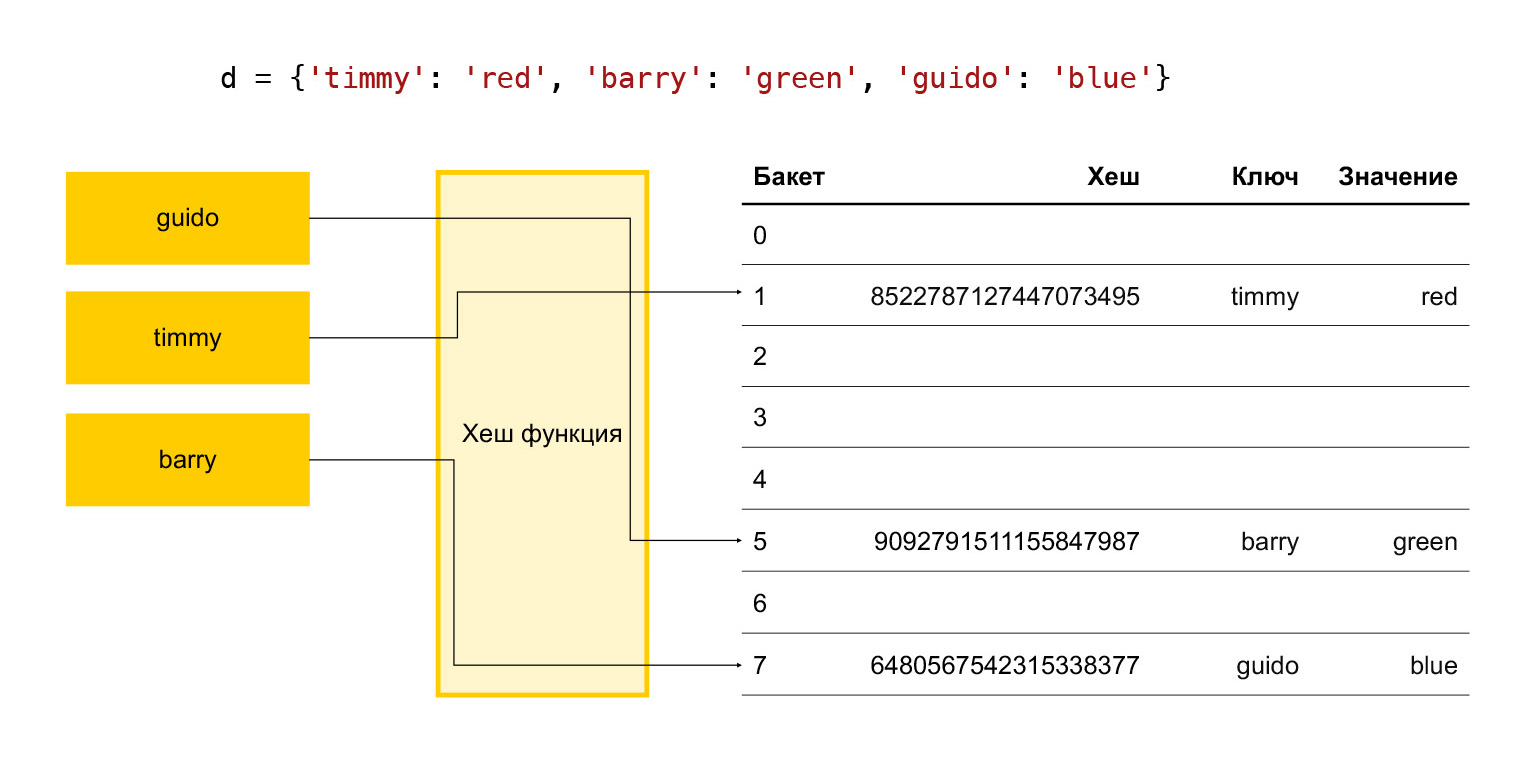
En resumen, ¿cómo funciona una tabla hash? Hay algunas claves: timmy, barry, guido. Queremos ponerlos en un diccionario, ejecutamos cada tecla a través de una función hash. Resulta un hash. Usamos este hash para encontrar el cubo. Un cubo es simplemente un número en una serie de elementos. Se produce la división de módulo final. Si el cubo está vacío, simplemente colocamos el artículo deseado en él. Si no está vacío y ya hay algún elemento allí, entonces esto es una colisión y elegimos el siguiente cubo, veamos si está libre o no. Y así sucesivamente hasta que encontremos un balde gratis.
Por lo tanto, para que la operación de agregar tenga lugar en un tiempo adecuado, debemos mantener constantemente una cierta cantidad de cubos libres. De lo contrario, cuando nos acerquemos al tamaño de esta matriz, buscaremos un depósito libre durante mucho tiempo y todo se ralentizará.
Por lo tanto, está aceptado empíricamente en Python que un tercio de los elementos de la matriz son siempre libres. Si su número es más de dos tercios, la matriz se expande. Esto no es bueno, porque un tercio de los elementos se desperdician, no se almacena nada útil.

Enlace de la diapositiva
Por lo tanto, desde la versión 3.6, Python ha hecho tal cosa. A la izquierda puedes ver cómo era antes. Tenemos una matriz dispersa donde se almacenan estos tres elementos. Desde 3.6, decidieron hacer una matriz tan dispersa como una matriz regular, pero al mismo tiempo almacenar los índices de los elementos del cubo en una matriz de índices separada.
Si miramos la matriz de índices, entonces en el primer depósito tenemos Ninguno, en el segundo hay un elemento con índice 1 de esta matriz, etc.
Esto permitió, en primer lugar, reducir el uso de memoria, y en segundo lugar, también lo sacamos de la caja de forma gratuita matriz ordenada. Es decir, agregamos elementos a esta matriz, condicionalmente, con el sish append habitual, y la matriz se ordena automáticamente.
Hay algunas optimizaciones interesantes que usa Python. Para que estas tablas hash funcionen, necesitamos tener una operación de comparación de elementos. Imagina que ponemos un elemento en una tabla hash y luego queremos tomar un elemento. Cogemos el hachís, vamos al cubo. Vemos: el cubo está lleno, hay algo allí. ¿Pero es este el elemento que necesitamos? Tal vez hubo una colisión cuando se colocó y el artículo realmente cabe en otro cubo. Por lo tanto, debemos comparar claves. Si la clave es incorrecta, usamos el mismo mecanismo de búsqueda del siguiente depósito que se usa para la resolución de colisiones. Y vamos más allá.

Enlace de la diapositiva
Por lo tanto, necesitamos tener una función de comparación clave. En general, la función de comparación de objetos puede resultar muy cara. Por lo tanto, se utiliza dicha optimización. Primero, comparamos los ID de los artículos. ID en CPython es, como saben, una posición en la memoria.
Si los ID son los mismos, entonces son los mismos objetos y, por supuesto, son iguales. Luego devolvemos True. Si no es así, mire los valores hash. El hash debería ser una operación bastante rápida si no lo hemos anulado de alguna manera. Tomamos valores hash de estos dos objetos y los comparamos. Si sus valores hash no son iguales, los objetos definitivamente no son iguales, por lo que devolvemos False.
Y solo en un caso muy poco probable, si nuestros hashes son iguales, pero no sabemos si es el mismo objeto, solo entonces comparamos los objetos en sí.
Una pequeña cosa interesante: no puede insertar nada en las claves durante la iteración. Esto es un error.

Bajo el capó, el diccionario tiene una variable llamada versión, que almacena la versión del diccionario. Cuando cambia el diccionario, la versión cambia, Python entiende esto y le arroja un error.

¿Para qué se pueden utilizar los diccionarios en un ejemplo más práctico? En Taxi tenemos pedidos, y los pedidos tienen estados que pueden cambiar. Cuando cambia el estado, debe realizar ciertas acciones: enviar SMS, registrar pedidos.
Esta lógica está escrita en Python. Para no escribir un enorme if de la forma "si el estado del pedido es tal o cual, haz esto", hay un dictado en el que la clave es el estado del pedido. Y para VALUE hay una tupla, que contiene todos los controladores que deben ejecutarse al pasar a este estado. Esta es una práctica común, de hecho, es un reemplazo para el interruptor del interruptor.

Algunas cosas más por tipo. Te hablaré de inmutable. Estos son tipos de datos inmutables y los mutables son, respectivamente, tipos mutables: dictados, clases, instancias de clases, hojas y tal vez algo más. Casi todo lo demás son cadenas, números ordinarios, son inmutables. ¿Para qué sirven los tipos mutables? Primero, hacen que el código sea más fácil de entender. Es decir, si ves en el código que algo es una tupla, ¿entiendes que no cambia más y esto te facilita la lectura del código? comprender lo que sucederá a continuación. En tuple ds no puede escribir elementos. Comprenderá esto y le ayudará a leerlo a usted y a todas las personas que leerán el código por usted.
Por lo tanto, hay una regla: si no cambia algo, es mejor usar tipos inmutables. También conduce a un trabajo más rápido. Hay dos constantes que usa tuple: pit_tuple, tap_tuple, max y CC. ¿Cuál es el punto de? Para todas las tuplas hasta el tamaño 20, se utiliza un método de asignación específico, que acelera esta asignación. Y puede haber hasta dos mil de estos objetos de cada tipo, muchos. Esto es mucho más rápido que las hojas, por lo que si usa tupla será más rápido.
También hay comprobaciones en tiempo de ejecución. Obviamente, si está intentando conectar algo en un objeto y no es compatible con esta función, entonces habrá un error, algún tipo de comprensión de que hizo algo mal. Las claves de un dictado solo pueden ser objetos que tengan un hash que no cambie durante su vida. Solo los objetos inmutables satisfacen esta definición. Solo ellos pueden ser claves de dic.

¿Cómo se ve en C? Ejemplo. A la izquierda hay una tupla, a la derecha hay una lista normal. Aquí, por supuesto, no todas las diferencias son visibles, sino solo las que quería mostrar. En list en el campo tp_hash tenemos NotImplemented, es decir, list no tiene hash. En tupla hay alguna función que realmente le devolverá un hash. Esta es exactamente la razón por la que tuple, entre otras cosas, puede ser una clave de dictado y list no.
Lo siguiente que se resalta es la función de asignación de elementos, sq_ass_item. En la lista es, en la tupla es cero, es decir, naturalmente no se puede asignar nada a la tupla.

Una cosa más. Python no copia nada hasta que lo solicitamos. Esto también debe recordarse. Si desea copiar algo, use, digamos, el módulo de copia, que tiene una función copy.deepcopy. ¿Cuál es la diferencia? copy copia el objeto, si es un objeto contenedor, como una lista de hermanos. Todas las referencias que estaban en este objeto se insertan en el nuevo objeto. Y deepcopy copia recursivamente todos los objetos dentro de este contenedor y más allá.
O, si desea copiar rápidamente una lista, puede usar un solo segmento de dos puntos. Obtendrá una copia, este atajo es simple.
(...) A continuación, hablemos de la gestión de la memoria.
Gestión de la memoria

Tomemos nuestro módulo sys. Tiene una función que te permite ver si está usando memoria. Si inicia el intérprete y observa las estadísticas de los cambios de memoria, verá que ha creado muchos objetos, incluidos los pequeños. Y estos son solo los objetos que se crean actualmente.
De hecho, Python crea muchos objetos pequeños en tiempo de ejecución. Y si usáramos la función estándar malloc para asignarlos, nos encontraríamos muy rápidamente en el hecho de que nuestra memoria está fragmentada y, en consecuencia, la asignación de memoria es lenta.

Esto implica la necesidad de utilizar su propio administrador de memoria. En resumen, ¿cómo funciona? Python se asigna a sí mismo bloques de memoria, llamados arena, de 256 kilobytes cada uno. En el interior, se divide en grupos de cuatro kilobytes, este es el tamaño de una página de memoria. Dentro de las piscinas, tenemos bloques de diferentes tamaños, desde 16 hasta 512 bytes.
Cuando intentamos asignar menos de 512 bytes a un objeto, Python selecciona a su manera un bloque adecuado para este objeto y coloca el objeto en este bloque.
Si el objeto se desasigna, se elimina, este bloque se marca como libre. Pero no se le da al sistema operativo, y en la siguiente ubicación podemos escribir este objeto en el mismo bloque. Esto acelera mucho la asignación de memoria.

Liberando memoria. Anteriormente vimos la estructura PyObject. Ella tiene este recuento de referencias refcnt. Funciona de forma muy sencilla. Cuando hace referencia a este objeto, Python incrementa el recuento de referencias. Tan pronto como tenga un objeto, la referencia desaparece, desasigne el recuento de referencias.
Lo que se resalta en amarillo. Si refcnt no es cero, entonces estamos haciendo algo allí. Si refcnt es cero, inmediatamente desasignamos el objeto. No estamos esperando a ningún recolector de basura, nada, pero justo en este momento borramos la memoria.
Si se encuentra con el método del, simplemente elimina la vinculación de la variable al objeto. Y el método __del__, que puede definir en la clase, se llama cuando el objeto se elimina de la memoria. Llamará a del en el objeto, pero si todavía tiene referencias, el objeto no se eliminará en ninguna parte. Y su Finalizador, __del__, no se llamará. Aunque se llaman muy similares.
Una breve demostración sobre cómo puede ver la cantidad de enlaces. Está nuestro módulo sys favorito, que tiene una función getrefcount. Puede ver la cantidad de enlaces a un objeto.

Te diré más. Se hace un objeto. El número de enlaces se toma de él. Detalle interesante: la variable A apunta a TaxiOrder. Toma el número de enlaces y obtendrá "2" impreso. ¿Parecería por qué? Tenemos una referencia de objeto. Pero cuando llama a getrefcount, este objeto se vende para un argumento dentro de la función. Por lo tanto, ya tiene dos referencias a este objeto: la primera es la variable, la segunda es el argumento de la función. Por lo tanto, se imprime "2".
El resto es trivial. Asignamos otra variable al objeto, obtenemos 3. Luego eliminamos este enlace, obtenemos 2. Luego eliminamos todas las referencias a este objeto, y al mismo tiempo se llama al finalizador, que imprimirá nuestra línea.

(...) Hay otra característica interesante de CPython, sobre la que no se puede construir, y parece que no se dice al respecto en ninguna parte de los documentos. A menudo se utilizan números enteros. Sería un desperdicio recrearlos cada vez. Por lo tanto, los números más utilizados, los desarrolladores de Python eligieron el rango de –5 a 255, son Singleton. Es decir, se crean una vez, se encuentran en algún lugar del intérprete y, cuando intenta obtenerlos, obtiene una referencia al mismo objeto. Tomamos unos A y B, los imprimimos y comparamos sus direcciones. Se hizo verdad. Y tenemos, por ejemplo, 105 referencias a este objeto, simplemente porque ahora hay tantas.
Si tomamos un número mayor, por ejemplo, 1408, estos objetos no son iguales para nosotros y hay, respectivamente, dos referencias a ellos. De hecho, uno.
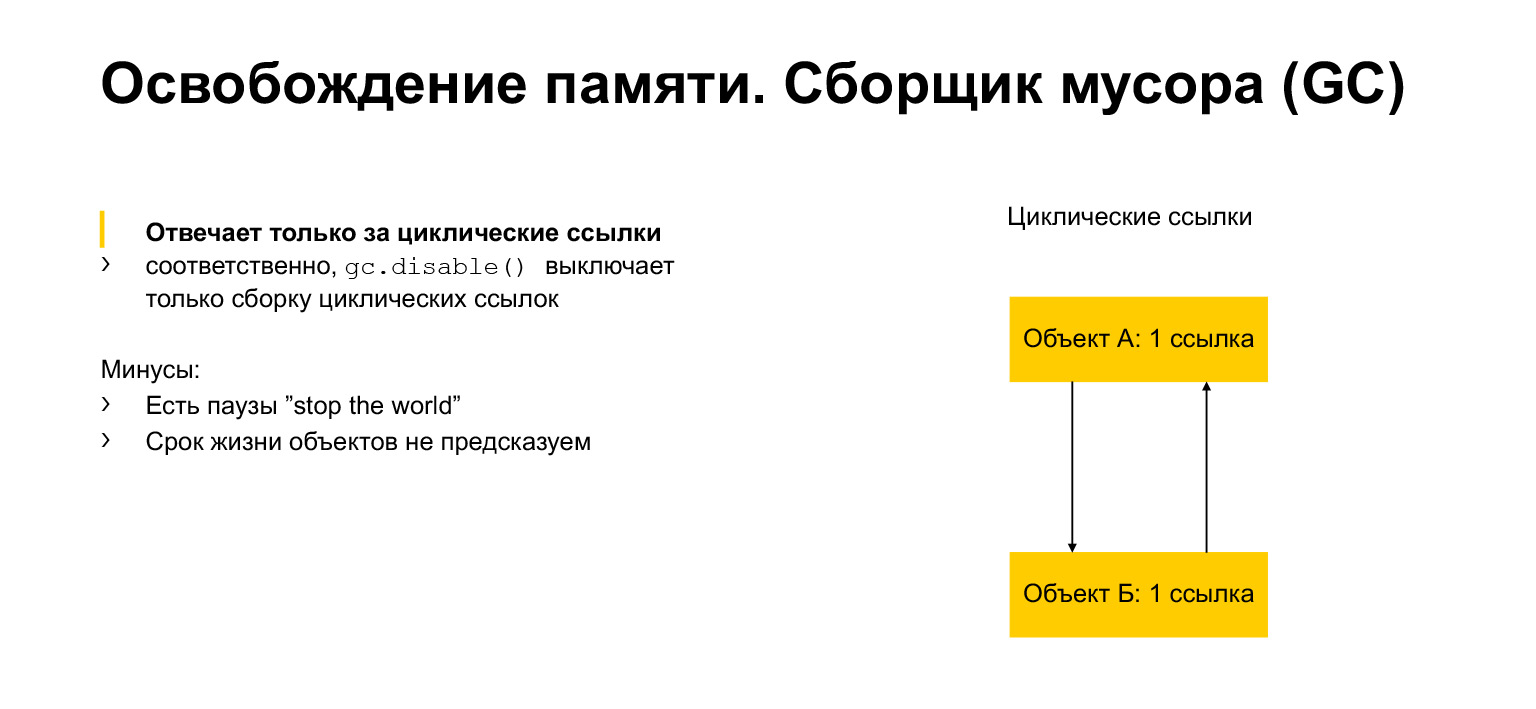
Hablamos un poco sobre la asignación y liberación de memoria. Ahora hablemos del recolector de basura. ¿Para qué sirve? Parece que tenemos varios enlaces. Una vez que nadie haya hecho referencia al objeto, podemos eliminarlo. Pero podemos tener enlaces circulares. Un objeto puede referirse a sí mismo, por ejemplo. O, como en el ejemplo, puede haber dos objetos, cada uno de los cuales se refiere a un vecino. A esto se le llama ciclo. Y luego estos objetos nunca pueden dar una referencia a otro objeto. Pero al mismo tiempo, por ejemplo, son inalcanzables desde otra parte del programa. Necesitamos eliminarlos porque son inaccesibles, inútiles, pero tienen enlaces. Esto es exactamente para lo que es el módulo recolector de basura. Detecta ciclos y elimina estos objetos.
Como trabaja Primero, hablaré brevemente sobre las generaciones y luego sobre el algoritmo.
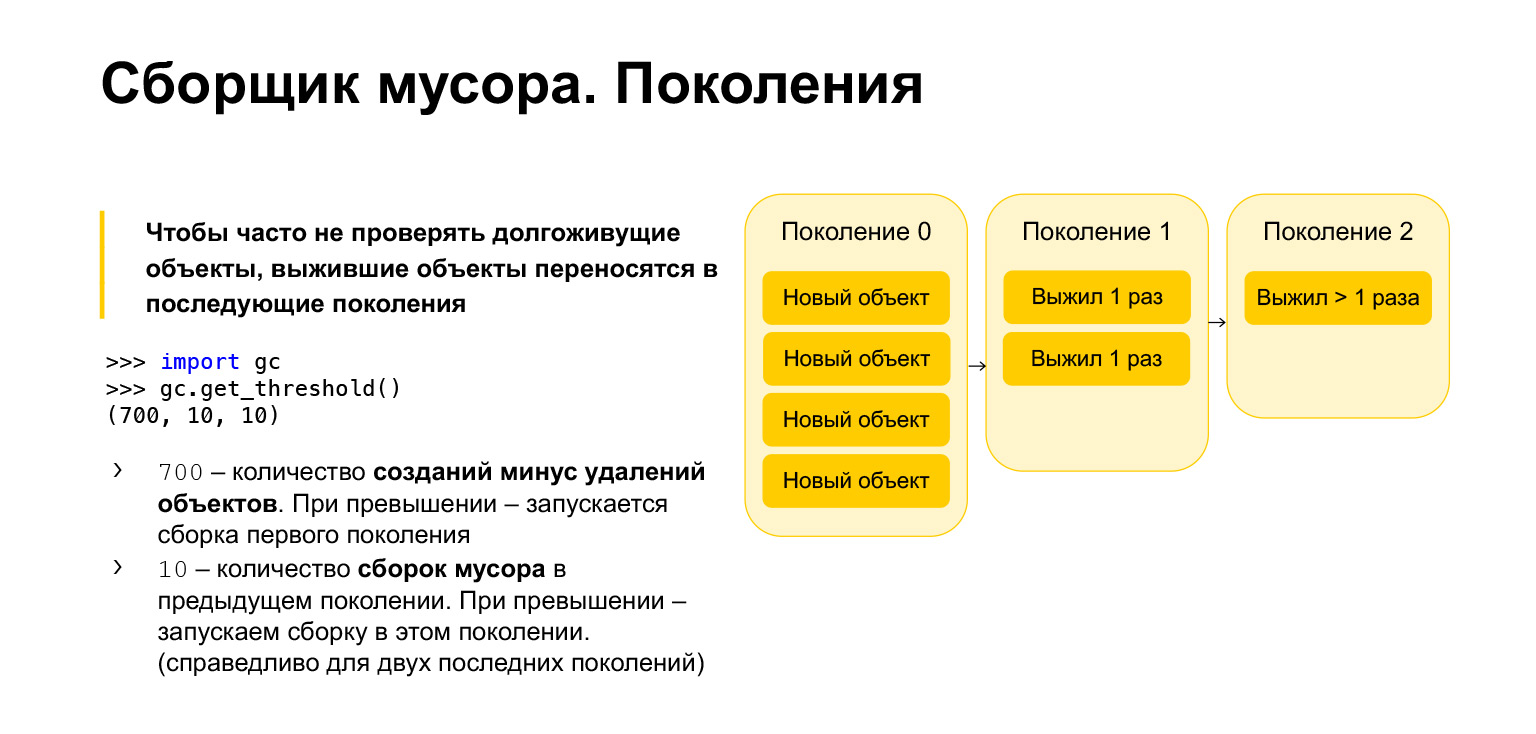
Para optimizar la velocidad del recolector de basura en Python, es generacional, es decir, funciona usando generaciones. Hay tres generaciones. ¿Para qué se necesitan? Está claro que los objetos que se han creado recientemente tienen más probabilidades de ser innecesarios que los objetos de larga duración. Digamos que crea algo en el curso de funciones. Lo más probable es que no sea necesario al salir de la función. Lo mismo ocurre con los bucles, con variables temporales. Todos estos objetos deben limpiarse con más frecuencia que los que han existido durante mucho tiempo.
Por lo tanto, todos los objetos nuevos se colocan en la generación cero. Esta generación se limpia periódicamente. Python tiene tres parámetros. Cada generación tiene su propio parámetro. Puede obtenerlos, importar el recolector de basura, llamar a la función get_threshold y obtener esos umbrales.
Por defecto hay 700, 10, 10. ¿Qué es 700? Este es el número de creación de objetos menos el número de eliminaciones. Tan pronto como supera los 700, comienza una nueva generación de recolección de basura. Y 10, 10 es el número de recolecciones de basura en la generación anterior, después de lo cual debemos comenzar la recolección de basura en la generación actual.
Es decir, cuando borramos la generación cero 10 veces, comenzaremos la compilación en la primera generación. Después de limpiar la primera generación 10 veces, comenzaremos la construcción en la segunda generación. En consecuencia, los objetos se mueven de generación en generación. Si sobreviven, pasan a la primera generación. Si sobrevivieron a una recolección de basura en la primera generación, se mueven a la segunda. A partir de la segunda generación ya no se mueven a ningún lado, permanecen ahí para siempre.
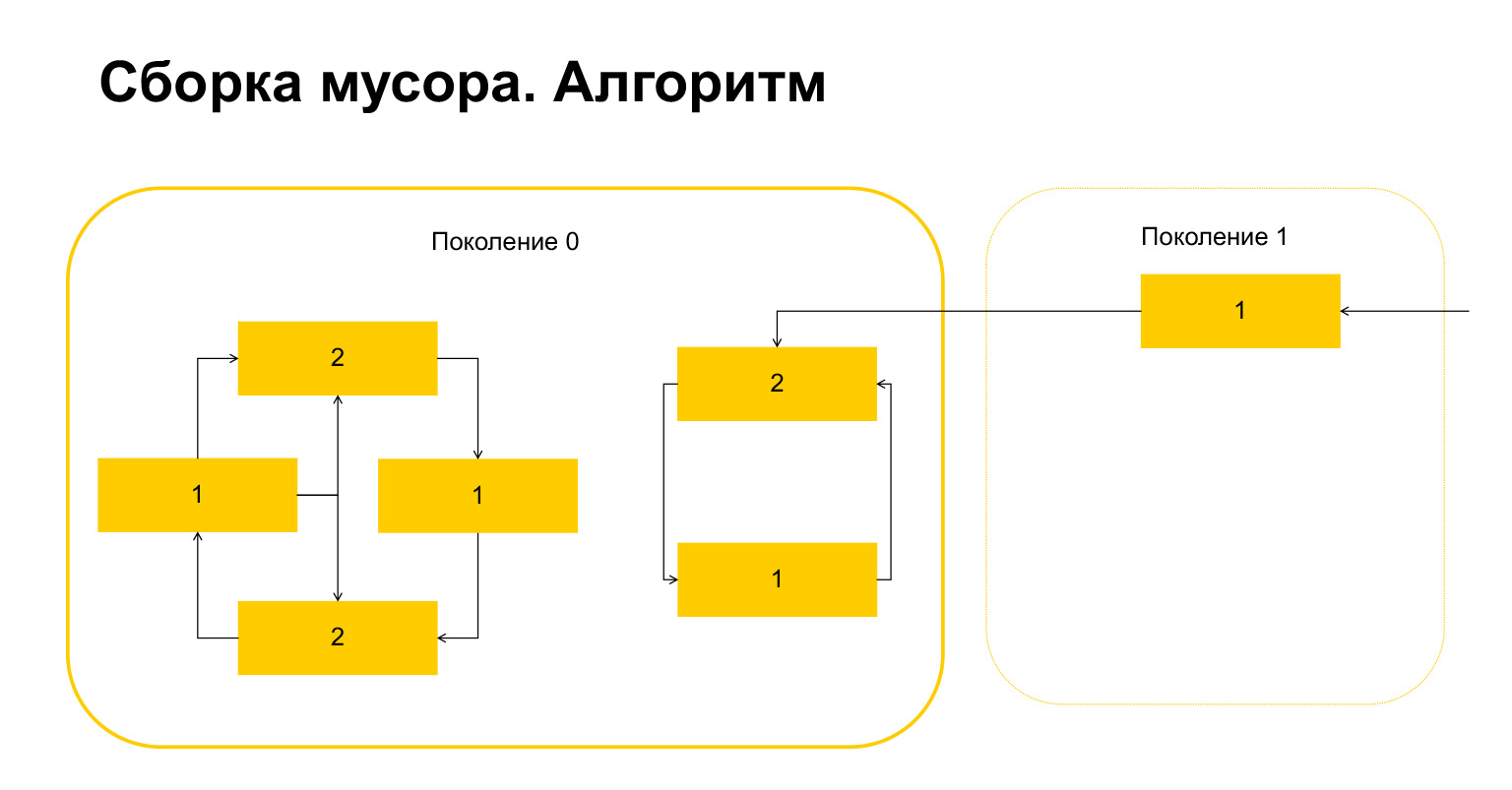
¿Cómo funciona la recolección de basura en Python? Digamos que comenzamos la recolección de basura en la generación 0. Tenemos algunos objetos, tienen ciclos. Hay un grupo de objetos a la izquierda que se refieren entre sí, y el grupo de la derecha también se refiere entre sí. Un detalle importante: también se hace referencia a ellos desde la generación 1. ¿Cómo detecta Python los bucles? Primero, se crea una variable temporal para cada objeto y se escribe en ella el número de referencias a este objeto. Esto se refleja en la diapositiva. Tenemos dos enlaces al objeto en la parte superior. Sin embargo, se hace referencia a un objeto de la generación 1 desde el exterior. Python recuerda esto. Luego (¡importante!) Pasa por cada objeto dentro de la generación y borra, disminuye el contador por el número de referencias dentro de esta generación.
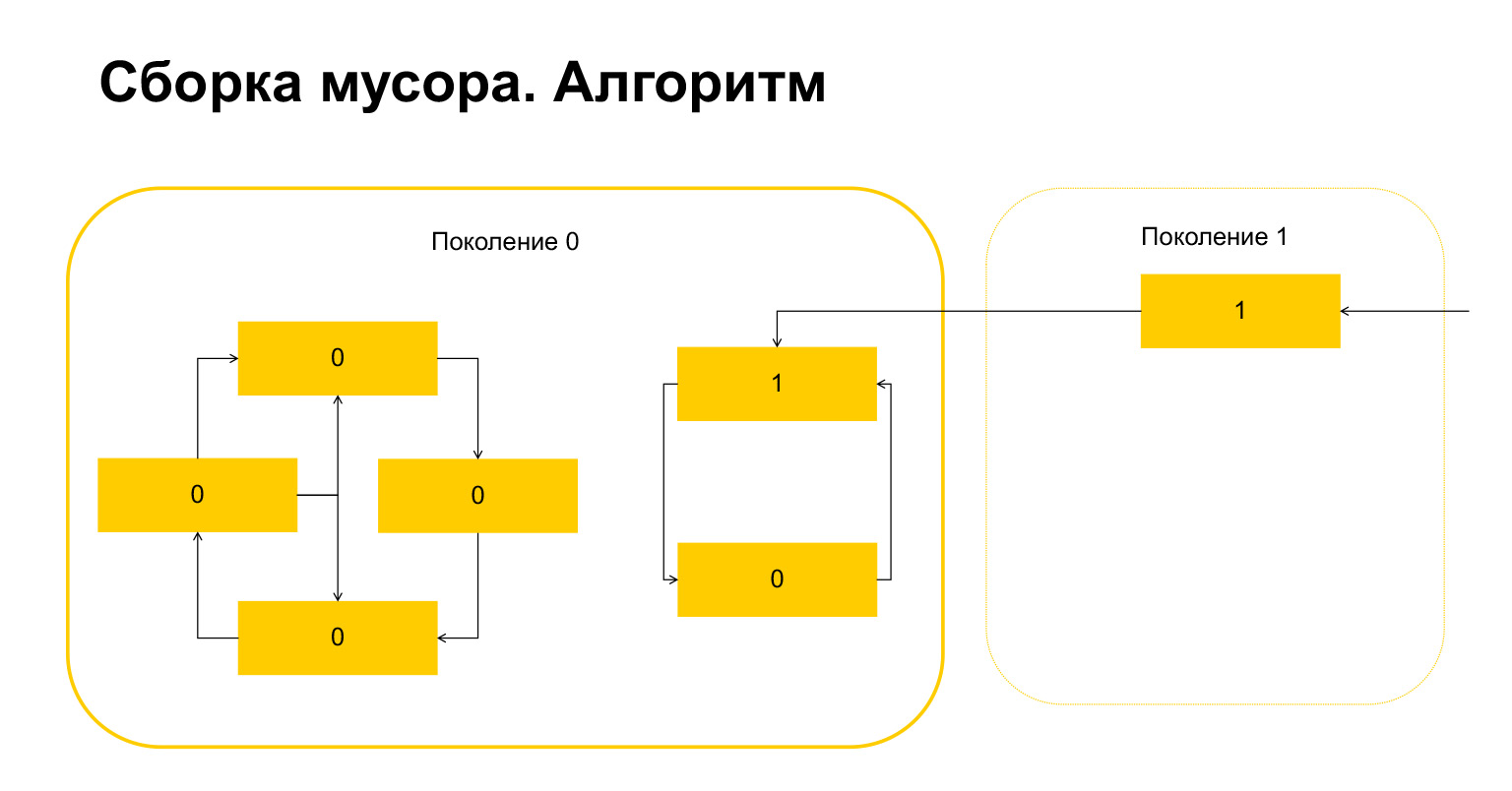
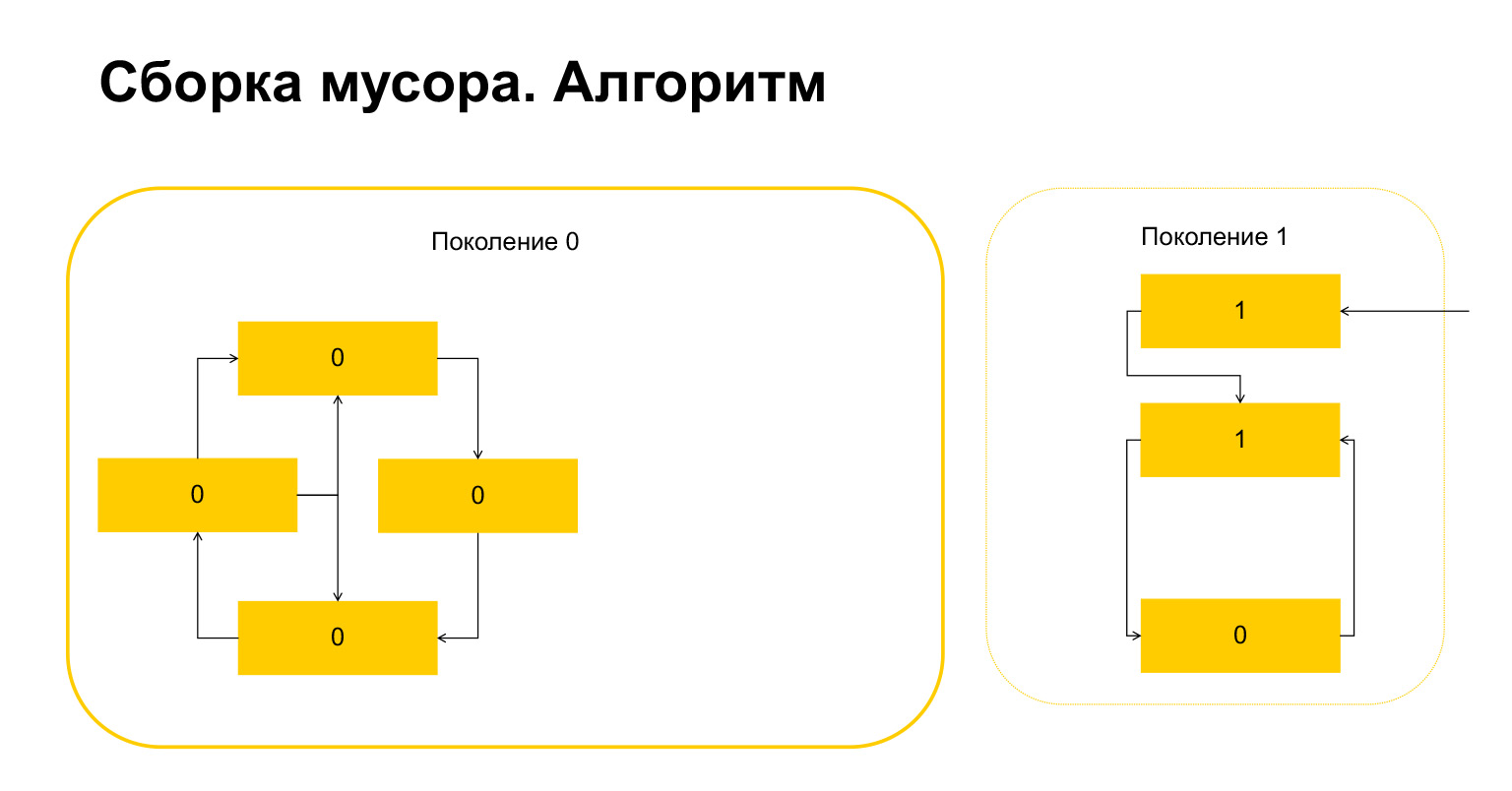
Esto es lo que sucedió. Para los objetos que solo se refieren entre sí dentro de una generación, esta variable se ha convertido automáticamente en cero por construcción. Solo los objetos a los que se hace referencia desde el exterior tienen una unidad.
¿Qué hace Python a continuación? Él, como hay uno aquí, entiende que estos objetos están referenciados desde fuera. Y no podemos eliminar ni este objeto ni este, porque de lo contrario acabaremos con una situación no válida. Por lo tanto, Python transfiere estos objetos a la generación 1, y todo lo que queda en la generación 0, lo elimina, lo limpia. Todo sobre recolector de basura.
(...) Siga adelante. Te hablaré muy brevemente de los generadores.
Generadores

Desafortunadamente, aquí no habrá una introducción a los generadores, pero intentemos decirle qué es un generador. Esta es una especie de función, relativamente hablando, que recuerda el contexto de su ejecución usando la palabra rendimiento. En este punto, devuelve un valor y recuerda el contexto. A continuación, puede consultarlo nuevamente y obtener el valor que da.
¿Qué se puede hacer con los generadores? Puede generar un generador, esto le devolverá valores, recuerde el contexto. Puede devolver el generador. En este caso se lanzará la ejecución de StopIteration, cuyo valor dentro del cual contendrá el valor, en este caso Y.
Hecho menos conocido: puede enviar algunos valores al generador. Es decir, llama al método de envío en el generador, y Z, vea el ejemplo, será el valor de la expresión de rendimiento que invocará el generador. Si desea controlar el generador, puede pasar valores allí.
También puede lanzar excepciones allí. Lo mismo: coge un objeto generador, tíralo. Lanzas un error allí. Tendrá un error en lugar del último rendimiento. Y cerca, puedes cerrar el generador. Luego, se inicia la ejecución de GeneratorSalir y se espera que el generador no produzca nada más.

Aquí solo quería hablar sobre cómo funciona en CPython. De hecho, tiene un marco de ejecución en su generador. Y como recordamos, FrameObject contiene todo el contexto. A partir de esto, parece claro cómo se conserva el contexto. Es decir, solo tiene un marco en el generador.

Cuando ejecuta una función de generador, ¿cómo sabe Python que no necesita ejecutarla, sino crear un generador? El CodeObject que miramos tiene banderas. Y cuando llamas a una función, Python comprueba sus banderas. Si la bandera CO_GENERATOR está presente, entiende que la función no necesita ser ejecutada, solo necesita crear un generador. Y lo crea. Función PyGen_NewWithQualName.

¿Cómo va la ejecución? Desde GENERATOR_FUNCTION, el generador primero llama a GENERATOR_Object. Luego puede llamar a GENERATOR_Object usando next para obtener el siguiente valor. ¿Cómo ocurre la próxima llamada? Su marco se toma del generador, se almacena en la variable F. y se envía al bucle principal del intérprete EvalFrameEx. Se ejecuta como en el caso de una función normal. El código de mapa YIELD_VALUE se usa para regresar, pausar la ejecución del generador. Recuerda todo el contexto del marco y deja de ejecutarse. Este fue el penúltimo tema.
(...) Un resumen rápido de qué son las excepciones y cómo se usan en Python.
Excepciones

Las excepciones son una forma de manejar situaciones de error. Tenemos un bloque de prueba. Podemos escribir para probar esas cosas que pueden generar excepciones. Digamos que podemos generar un error usando la palabra subir. Con la ayuda de except podemos detectar ciertos tipos de excepciones, en este caso SomeError. Con excepto, capturamos todas las excepciones sin expresión. El bloque else se usa con menos frecuencia, pero existe y solo se ejecutará si no se lanzaron excepciones. El bloque finalmente se ejecutará de todos modos.
¿Cómo funcionan las excepciones en CPython? Además de la pila de ejecución, cada marco también tiene una pila de bloques. Es mejor usar un ejemplo.


Una pila de bloques es una pila en la que se escriben bloques. Cada bloque tiene un tipo, Handler, un handler. Handler es la dirección de código de bytes a la que se debe saltar para procesar este bloque. ¿Como funciona? Digamos que tenemos un código. Hicimos un bloque try, tenemos un bloque except en el que capturamos las excepciones RuntimeError, y un bloque finalmente, que debería ser en cualquier caso.
Todo esto degenera en este código de bytes. Al principio del bytecode en el bloque try, vemos dos dos opcode SETUP_FINALLY con argumentos a 40 y a 12. Estas son las direcciones de los manejadores. Cuando se ejecuta SETUP_FINALLY, se coloca un bloque en la pila de bloques, que dice: para procesarme, vaya en un caso a la dirección 40, en el otro, a la 12.
12 abajo de la pila es excepto, la línea que contiene el else RuntimeError. Esto significa que cuando tengamos una excepción, miraremos la pila de bloques en busca de un bloque con el tipo SETUP_FINALLY. Busque el bloque en el que hay una transición a la dirección 12, vaya allí. Y ahí tenemos una comparación de la excepción con el tipo: comprobamos si el tipo de excepción es RuntimeError o no. Si es igual, lo ejecutamos, si no, saltamos a otro lado.
FINALMENTE es el siguiente bloque en la pila de bloques. Se ejecutará por nosotros si tenemos alguna otra excepción. Luego, la búsqueda continuará en esta pila de bloques y llegaremos al siguiente bloque SETUP_FINALLY. Habrá un controlador que nos diga, por ejemplo, la dirección 40. Saltamos a la dirección 40; puede ver en el código que este es un bloque final.

Funciona de manera muy simple en CPython. Tenemos todas las funciones que pueden generar excepciones y devuelven un código de valor. Si todo está bien, se devuelve 0. Si es un error, se devuelve -1 o NULL, según el tipo de función.
Tome un recuadro en C. Vemos cómo se produce la división. Y hay una verificación de que si B es igual a cero y no queremos dividir por cero, recordamos la excepción y devolvemos NULL. Entonces ha ocurrido un error. Por lo tanto, todas las demás funciones que están más arriba en la pila de llamadas también deberían arrojar NULL. Veremos esto en el bucle principal del intérprete y saltaremos aquí.

Esto es desenrollar la pila. Todo es como dije: revisamos toda la pila de bloques y comprobamos que su tipo sea SETUP_FINALLY. Si es así, salte sobre Handler, muy simple. Esto, de hecho, es todo.
Enlaces
Intérprete general:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Memory Management:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory- management
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Excepciones:
bugs.python.org/issue17611