
Los costos de almacenamiento de datos a menudo se convierten en el principal elemento de costo al crear un sistema de videovigilancia. Sin embargo, serían incomparablemente más grandes si no existieran algoritmos en el mundo capaces de comprimir una señal de video. En el artículo de hoy, hablaremos sobre cuán efectivos son los códecs modernos y qué principios subyacen en su trabajo.
Comencemos con números para mayor claridad. Deja que el video se grabe de forma continua, en resolución Full HD (ahora este es el mínimo requerido, al menos si quieres aprovechar al máximo las funciones de análisis de video) y en tiempo real (es decir, con una velocidad de fotogramas de 25 fotogramas por segundo). Supongamos también que nuestro hardware elegido admite la codificación de hardware H.265. En este caso, con diferentes configuraciones de calidad de imagen (alta, media y baja), obtendremos aproximadamente los siguientes resultados.
Códec |
Intensidad de movimiento en el encuadre |
Uso de espacio en disco por día, GB |
H.265 (alta calidad) |
Alto |
138 |
H.265 (alta calidad) |
Promedio |
67 |
H.265 (alta calidad) |
Bajo |
41 |
H.265 (calidad media) |
Alto |
86 |
H.265 (calidad media) |
Promedio |
42 |
H.265 (calidad media) |
Bajo |
26 |
H.265 (baja calidad) |
Alto |
81 |
H.265 (baja calidad) |
Promedio |
39 |
H.265 (baja calidad) |
Bajo |
24 |
Pero si la compresión de video no existiera en principio, veríamos números completamente diferentes. Tratemos de averiguar por qué. Una secuencia de video no es más que una secuencia de imágenes estáticas (cuadros) a una determinada resolución. Técnicamente, cada fotograma es una matriz bidimensional que contiene información sobre las unidades elementales (píxeles) que forman la imagen. TrueColor requiere 3 bytes para codificar cada píxel. Por lo tanto, en el ejemplo dado, obtendríamos una tasa de bits:
1920 × 1080 × 25 × 3/1048576 = ~ 148 Mb / s
Considerando que hay 86400 segundos en un día, los números son realmente astronómicos:
148 × 86400/1024 = 12487 GB
Entonces, si grabamos video sin compresión en la máxima calidad bajo las condiciones dadas, entonces necesitaríamos 12 terabytes de espacio en disco para almacenar los datos recibidos de una sola cámara de video durante el día. Pero incluso el sistema de seguridad de un apartamento u oficina pequeña presupone la presencia de al menos dos dispositivos de grabación de video, mientras que el archivo en sí debe conservarse durante varias semanas o incluso meses, si así lo exige la ley. Es decir, para dar servicio a cualquier objeto, incluso de un tamaño muy modesto, se necesitaría un centro de datos completo.
Afortunadamente, los algoritmos modernos de compresión de video pueden ahorrar significativamente espacio en disco: por ejemplo, el uso del códec H.265 puede reducir el tamaño del video en 90 (!) Veces. Fue posible lograr resultados tan impresionantes gracias a una gran cantidad de diversas tecnologías que durante mucho tiempo se han utilizado con éxito no solo en el campo de la videovigilancia, sino también en el sector "civil": en sistemas de televisión analógicos y digitales, en filmaciones de aficionados y profesionales, y muchas otras situaciones.
El ejemplo más simple y obvio es el submuestreo de color. Este es el nombre de un método de codificación de vídeo en el que la resolución de color de los fotogramas se reduce deliberadamente y la frecuencia de muestreo de las señales de diferencia de color es menor que la frecuencia de muestreo de la señal de luminancia. Este método de compresión de datos de vídeo está plenamente justificado tanto desde el punto de vista de la fisiología humana como desde el punto de vista de la aplicación práctica en el campo de la grabación de vídeo. Nuestros ojos son buenos para notar la diferencia de brillo, pero son mucho menos sensibles a los cambios de color, por lo que se puede sacrificar el muestreo de señales de diferencia de color, porque la mayoría de las personas simplemente no lo notarán. Al mismo tiempo, es difícil imaginar cómo se anuncia en la lista de buscados un automóvil del color de una "araña tramando un crimen": la orientación dirá "gris oscuro", y esto es correcto, porque de lo contrario la persona que lea la descripción del automóvil ni siquiera lo entenderá.de qué sombra estamos hablando.
Pero con una disminución en los detalles, todo resulta ser completamente diferente. Técnicamente, la cuantificación (es decir, dividir el rango de la señal en varios niveles y luego llevarlos a los valores especificados) funciona muy bien: con este método, el tamaño del video se puede reducir muchas veces. Pero de esta forma podemos pasar por alto detalles importantes (por ejemplo, el número de un coche que pasa en la distancia o los rasgos faciales de un intruso): se irán difuminando y tal registro nos resultará inútil. ¿Cómo proceder en esta situación? La respuesta es simple, como todo lo ingenioso: una vez que tomas los objetos dinámicos como punto de partida, todo encaja de inmediato. Este principio se ha utilizado con éxito desde la aparición del códec H.264 y ha demostrado que abre una serie de posibilidades adicionales para la compresión de datos.
Era predecible: averiguar cómo H.264 comprime el video
Volvamos a la mesa con la que empezamos. Como ves, además de parámetros como la resolución, la velocidad de fotogramas y la calidad de la imagen, el factor decisivo que determina el tamaño final del vídeo es el nivel de dinamismo de la escena que se está filmando. Esto se debe a las peculiaridades del trabajo de los códecs de video modernos en general, y H.264 en particular: el mecanismo de predicción de cuadros utilizado en él le permite comprimir adicionalmente el video, sin sacrificar prácticamente la calidad de la imagen. Vamos a ver cómo funciona.
El códec H.264 utiliza varios tipos de tramas:
- I-frames (de los marcos intracodificados en inglés, también se denominan clave o clave): contienen información sobre objetos estáticos que no cambian durante mucho tiempo.
- P- (Predicted frames, , ) — , , I-.
- B- (Bi-predicted frames, ) — P-, I-, P- B-, , .
¿Qué significa esto? En el códec H.264, la construcción de una imagen de video es la siguiente: la cámara crea un marco de referencia (I-frame) y sobre su base (por eso se llama marco de referencia) resta las partes fijas de la imagen del marco. Esto crea un marco en P. Luego, el tercero se resta de este segundo fotograma y también se crea un fotograma P modificado. Esto crea una serie de fotogramas diferenciales que solo contienen cambios entre dos fotogramas sucesivos. Como resultado, obtenemos la siguiente cadena:
[INICIO DE CAPTURA] IPPPPPPPPPPPPP- ...
Dado que en el proceso de resta son posibles errores que conducen a la aparición de artefactos gráficos, luego de un cierto número de cuadros se repite el esquema: se forma nuevamente un cuadro clave, seguido de una serie marcos con cambios.
… -PPPPPPPIPPPPPPP ... La
imagen completa se forma "superponiendo" fotogramas P en el marco de referencia. Al mismo tiempo, es posible procesar de forma independiente el fondo y los objetos en movimiento, lo que le permite ahorrar adicionalmente espacio en disco sin el riesgo de perder detalles importantes (rasgos faciales, matrículas, etc.). En el caso de objetos que realizan movimientos monótonos (por ejemplo, ruedas giratorias de automóviles), se pueden utilizar repetidamente los mismos fotogramas de diferencia.
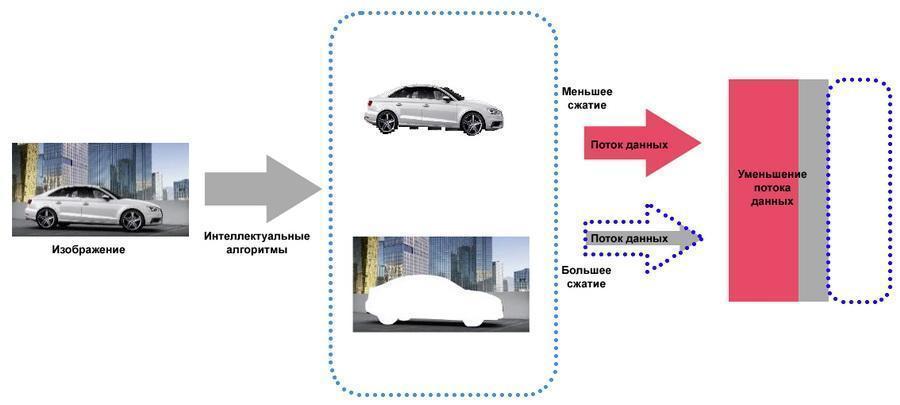
El procesamiento independiente de objetos estáticos y dinámicos ahorra espacio en disco,
este mecanismo se denomina compresión entre cuadros. Los fotogramas predichos se forman a partir del análisis de una amplia muestra de estados de escena fijos: el algoritmo predice dónde se moverá este o aquel objeto en el campo de visión de la cámara, lo que puede reducir significativamente la cantidad de datos registrados al observar, por ejemplo, la calzada.
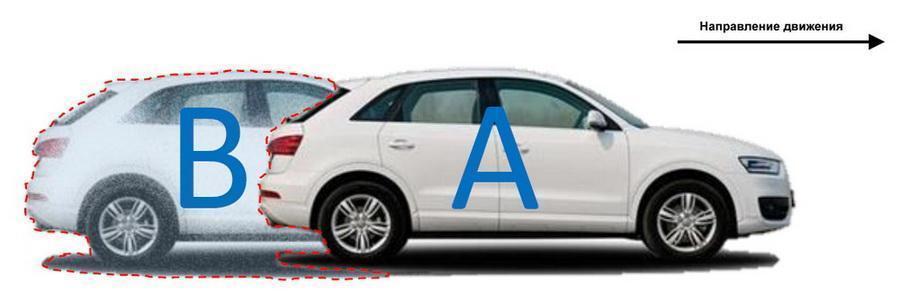
El códec genera cuadros, prediciendo hacia dónde se moverá el objeto; a
su vez, el uso de cuadros predichos bidireccionales permite reducir varias veces el tiempo de acceso a cada cuadro en el flujo, ya que bastará con descomprimir solo tres cuadros para obtenerlo: B que contiene enlaces, y yo y la P a la que se refiere. En este caso, la secuencia de fotogramas se puede representar de la siguiente manera.
[INICIAR CAPTURA] IBPBPBPBPBPBPBPBP-…
Este enfoque puede aumentar significativamente la velocidad de avance rápido y mostrar y simplificar el trabajo con el archivo de video.
¿Cuál es la diferencia entre H.264 y H.265?

H.265 utiliza los mismos principios de compresión que H.264: la imagen de fondo se guarda una vez y luego solo se registran los cambios que se originan en los objetos en movimiento, lo que puede reducir significativamente los requisitos no solo de almacenamiento, sino también de ancho de banda capacidades de red. Sin embargo, en H.265, muchos algoritmos y métodos de predicción de movimiento han sufrido cambios cualitativos significativos.
Entonces, la versión actualizada del códec comenzó a usar macrobloques de un árbol de codificación (Coding Tree Unit, CTU) de tamaño variable con una resolución de hasta 64 × 64 píxeles, mientras que anteriormente el tamaño máximo de dicho bloque era de solo 16 × 16 píxeles. Esto hizo posible mejorar significativamente la precisión de la extracción de bloques dinámicos, así como la eficiencia del procesamiento de cuadros en resolución 4K y superior.
Además, H.265 tiene un filtro de desbloqueo mejorado, un filtro responsable de suavizar los bordes de los bloques, necesario para eliminar artefactos a lo largo de la línea de su unión. Finalmente, el algoritmo mejorado Motion Vector Predictor (MVP) ayudó a reducir significativamente el volumen de video debido a un aumento radical en la precisión de las predicciones al codificar objetos en movimiento, lo cual se logró al aumentar el número de direcciones rastreadas: si antes solo se tenían en cuenta 8 vectores, ahora ... 36.
Además de todo lo anterior, H.265 ha mejorado el soporte para subprocesos múltiples: las áreas cuadradas en las que se divide cada cuadro durante la codificación ahora se pueden procesar de forma independiente entre sí. También es compatible con Wavefront Parallelel Processing (WPP), que también mejora el rendimiento de la compresión. Cuando se activa el modo WPP, el procesamiento de la CTU se realiza línea a línea, de izquierda a derecha, sin embargo, la codificación de cada línea subsiguiente puede comenzar incluso antes de la finalización de la anterior, si los datos recibidos de las CTU procesadas previamente son suficientes para esto. Cambio de codificación retardada en el tiempo de diferentes cadenas de CTU,Junto con el soporte para el conjunto extendido de instrucciones AVX / AVX2, puede aumentar aún más la velocidad de procesamiento de secuencias de video en sistemas de múltiples núcleos y procesadores.
Tarjetas flash de vigilancia: cuando el tamaño no es lo único
Y nuevamente, volvamos a la tableta con la que comenzamos la conversación de hoy. Calculemos cuánto espacio en disco necesitamos si queremos almacenar un archivo de video durante los últimos 30 días con la máxima calidad de video:
138 × 30/1024 = 4
Según los estándares actuales, 4 terabytes para un disco duro de grado industrial es prácticamente nada: los discos duros modernos son para La videovigilancia tiene una capacidad de hasta 14 terabytes y cuenta con un recurso de trabajo de hasta 360 TB por año con MTBF de hasta 1,5 millones de horas. En cuanto a las tarjetas de memoria, todo resulta no tan sencillo.
En las cámaras IP, las tarjetas flash desempeñan la función de almacenamiento de respaldo: los datos que contienen se sobrescriben constantemente para que, en caso de pérdida de conexión con el servidor de video, el fragmento de video faltante se pueda restaurar desde una copia local. Este enfoque puede aumentar significativamente la tolerancia a fallas de todo el sistema de seguridad, pero al mismo tiempo, las tarjetas de memoria están sometidas a un estrés tremendo.
Como puede ver en nuestra tabla, incluso con una calidad de imagen baja y con una actividad mínima en el marco, se grabarán aproximadamente 24 GB de video en solo un día. Esto significa que una tarjeta de 128 GB se sobrescribirá por completo en menos de una semana. Si necesitamos obtener una imagen de la más alta calidad, ¡todos los datos de dicho medio se actualizarán por completo una vez al día! Y esto es solo en resolución Full HD. ¿Y si necesitamos una imagen 4K? En este caso, la carga casi se duplicará (en las condiciones dadas, el video en calidad máxima requerirá 250 GB).
En el uso diario, esto es simplemente imposible, por lo que incluso la tarjeta de memoria más económica puede servirle durante varios años seguidos sin una sola falla. Y todo gracias a los algoritmos de nivelación de desgaste. Su trabajo se puede describir esquemáticamente de la siguiente manera. Tengamos una tarjeta flash nueva, recién sacada de la tienda. Grabamos varios videos en él, usando 7 de 16 gigabytes. Después de un tiempo, eliminamos algunos de los videos innecesarios, liberamos 3 gigabytes y grabamos otros nuevos, cuyo volumen era de 2 GB. Parecería que puede usar el espacio que se acaba de liberar, pero el mecanismo de nivelación de desgaste asignará para nuevos datos esa parte de la memoria que nunca antes se ha usado. Aunque los controladores modernos "mezclan" bits y bytes de una manera mucho más sofisticada, el principio general sigue siendo el mismo.
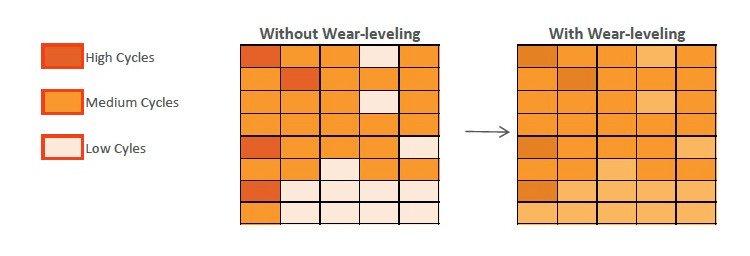
Recordemos que la codificación de bits de información se produce al cambiar la carga en las celdas de memoria debido al túnel cuántico de electrones a través de la capa dieléctrica, lo que provoca un desgaste gradual de las capas dieléctricas con la consiguiente fuga de carga. Y cuanto más a menudo cambie la carga en una celda en particular, antes fallará. La nivelación del desgaste tiene como objetivo precisamente garantizar que cada una de las celdas disponibles se sobrescriba aproximadamente el mismo número de veces y, por lo tanto, ayuda a aumentar la vida útil de la tarjeta de memoria.
No es difícil adivinar que la nivelación del desgaste deja de jugar un papel importante si la tarjeta flash se sobrescribe constantemente por completo: aquí pasa a primer plano la resistencia de los chips mismos. El criterio más objetivo para evaluar este último es el número máximo de ciclos de programa / borrado, o, en definitiva, ciclos P / E, que puede soportar la memoria flash. Además, el coeficiente TBW (Terabytes Written) es bastante preciso y en este caso ilustrativo (ya que podemos calcular los volúmenes de reescritura por adelantado). Si solo uno de los indicadores enumerados se indica en las características técnicas, entonces no será difícil calcular el otro. Es suficiente usar la siguiente fórmula:
TBW = (Capacidad × Número de ciclos P / E) / 1000
Entonces, por ejemplo, TBW de una tarjeta flash con una capacidad de 128 gigabytes, cuyo recurso es 200 P / E, será: (128 × 200) / 1000 = 25.6 TBW.
Vamos a contar. La resistencia de las tarjetas de memoria para consumidores es de 100 a 300 P / E, y 300 es la mejor. Basándonos en estas cifras, podemos estimar su vida útil con una precisión bastante alta. Usemos la fórmula y completemos una nueva tabla para una tarjeta de memoria de 128 GB. Tomemos como guía la máxima calidad de imagen en Full HD, es decir, la cámara grabará 138 GB de video por día, como descubrimos anteriormente.
Recurso de tarjeta de memoria, ciclos P / E |
TBW |
MTBF |
100 |
12,8 |
3 meses |
200 |
25,6 |
6 meses |
300 |
38,4 |
1 año |
¿Quiere usar tarjetas de 64GB o escribir videos 4K? Siéntase libre de dividir el tiempo calculado por dos: en promedio, las tarjetas de memoria del consumidor deberán reemplazarse cada seis meses y en cada cámara. Es decir, cada 6 meses tendrás que adquirir un nuevo lote de tarjetas flash, incurrir en costes de mantenimiento adicionales y, por supuesto, poner en peligro el objeto protegido, ya que las cámaras tendrán que ser puestas fuera de servicio mientras se sustituyen.
Por último, un punto más al que debes prestar mucha atención a la hora de elegir una tarjeta de memoria son sus características de velocidad. En la descripción de casi todas las tarjetas flash modernas, puede encontrar una entrada del formulario: “Rendimiento: hasta 100 MB / s al leer, hasta 90 MB / s al escribir; grabación de video: C10, U1, V10 ". Aquí C10 y U1 no significan más que una clase de velocidad de grabación de video, y si miras los materiales de referencia, las clases C10, U1 y V10 corresponden a 10 MB / s. ¿De dónde viene la diferencia 9 veces y por qué la marcación es triple? De hecho, todo es bastante sencillo.
En el ejemplo considerado, 100 y 90 MB / s son las velocidades nominales, es decir, el rendimiento máximo alcanzable de la tarjeta en operaciones secuenciales de lectura y escritura, siempre que se utilice con hardware compatible, que a su vez tenga un rendimiento suficiente. Y C10, U1 y V1 (10 MB / s) son las tasas de transferencia sostenidas mínimas en las peores condiciones de prueba. Este parámetro debe tenerse en cuenta a la hora de elegir tarjetas para cámaras CCTV por la sencilla razón de que si resulta ser menor que la tasa de bits del flujo de video, está plagado de la aparición de artefactos gráficos en la grabación e incluso la pérdida de cuadros completos. Obviamente, en el caso de los sistemas de seguridad, esto es inaceptable: cualquier defecto en la imagen está plagado de la pérdida de datos críticos, por ejemplo, evidencia que podría ayudar a atrapar a un intruso.
En cuanto a la presencia de tres marcas a la vez, las razones de esto son puramente históricas. C10 pertenece a las primeras clasificaciones creadas por la SD Card Association, que se compiló en 2006, después de haber recibido el nombre simple y sin complicaciones Speed Class. La aparición de la clasificación UHS Speed Class, que se indica con la marca U1, está asociada con la creación de la interfaz Ultra High Speed, que se utiliza hoy en día en la gran mayoría de tarjetas flash. Finalmente, la última clasificación, Video Speed Class (V1), fue desarrollada por la SD Card Association en 2016 en relación con la proliferación de dispositivos que admiten grabación de video de ultra alta definición (4K, 8K y 3D).
Dado que las clasificaciones enumeradas se superponen parcialmente, hemos preparado una tabla comparativa para usted, en la que las características de velocidad de las tarjetas flash se comparan entre sí y se correlacionan con videos de diferentes resoluciones.
Clase de velocidad |
Clase de velocidad UHS |
Clase de velocidad de video |
Velocidad de escritura mínima sostenida |
Resolución de video |
C2 |
- |
- |
2 MB / s |
Grabación de video de definición estándar (SD, 720 por 576 píxeles) |
C4 |
- |
- |
4 MB / s |
Grabación de video de alta definición (HD) que incluye Full HD (720p a 1080p / 1080i) |
C6 |
- |
V6 |
6 MB / s |
|
C10 |
U1 |
V10 |
10 MB / s |
Grabación de video Full HD (1080p) a 60 cuadros por segundo |
- |
U3 |
V30 |
30 MB / s |
Grabación de video con resolución de hasta 4K y 60/120 fps |
- |
- |
V60 |
60 MB / s |
Grabe archivos de video con una resolución de 8K y una velocidad de cuadros de 60/120 cuadros por segundo |
- |
- |
V90 |
90 MB / s |
Debe tenerse en cuenta que las correspondencias dadas en la tabla son relevantes para cámaras de video amateur, semiprofesionales y profesionales. En la industria de la videovigilancia, donde la grabación en tiempo real se realiza a una velocidad máxima de 25 cuadros por segundo, y se utilizan códecs H.264 y H.265 de alto rendimiento para comprimir el flujo de video, utilizando codificación predictiva, en la gran mayoría de los casos, las tarjetas de memoria correspondientes a la clase U1 serán suficientes. / V10, ya que la tasa de bits en tales condiciones casi nunca supera el umbral de 10 MB / s.
Tarjetas microSD WD Purple para sistemas de vigilancia

Teniendo en cuenta todas las características anteriores, Western Digital ha desarrollado una serie especializada de tarjetas de memoria microSD WD Purple, que actualmente incluye dos líneas de productos: WD Purple QD102 y WD Purple SC QD312 Extreme Endurance. El primero incluía cuatro unidades de 32 a 512 GB, el segundo, tres modelos, para 64, 128 y 256 GB. En comparación con las soluciones para el consumidor, WD Purple se ha diseñado específicamente para los sistemas de videovigilancia digital actuales con varias mejoras importantes.
La principal ventaja de la serie violeta es una vida útil significativamente mayor en comparación con los dispositivos domésticos: las tarjetas de la serie QD102 son capaces de soportar 1000 ciclos de programación / borrado, mientras que QD312 - ya 3000 ciclos P / E, lo que les permite extender su vida útil muchas veces incluso en el modo de grabación las 24 horas. y hace que estas tarjetas sean ideales para su uso en instalaciones especialmente protegidas, donde la grabación se realiza 24 horas al día, 7 días a la semana. Por el contrario, el cumplimiento de la clase de velocidad 1 de UHS y la clase de velocidad de vídeo 10 permite que las tarjetas WD Purple se utilicen en cámaras de alta definición, incluso para la grabación en tiempo real.
Además, las tarjetas de memoria WD Purple tienen otras características importantes que vale la pena mencionar:
- ( 1 ) ( -25°C +85°C) WD Purple , ;
- 5000 500 g ;
- , , .
Para mayor claridad, hemos preparado una tabla comparativa para usted, que muestra las principales características de las tarjetas de memoria WD Purple.
Serie |
WD Morado QD102 |
WD Púrpura QD312 |
||||||
Volumen, GB |
32 |
64 |
128 |
256 |
512 |
64 |
128 |
256 |
Formar- factor |
microSDHC |
microSDXC |
||||||
Actuación |
Hasta 100 MB / s en operaciones de lectura secuenciales, hasta 65 MB / s en operaciones de escritura secuencial |
|||||||
Clase de velocidad |
U1 / V10 |
|||||||
Recurso de registro (P / E) |
1000 |
3000 |
||||||
Recurso de escritura (TBW) |
32 |
64 |
128 |
256 |
512 |
192 |
384 |
768 |
Rango de temperatura de funcionamiento |
-25 ° C hasta 85 ° C |
|||||||
Garantía |
3 años |
|||||||