¡Hola! Es difícil encontrar un programador de microcontroladores que nunca haya encontrado una falla grave. Muy a menudo, no se procesa de ninguna manera, sino que simplemente permanece colgando en un bucle sin fin del controlador proporcionado en el archivo de inicio del fabricante. Al mismo tiempo, el programador intenta encontrar intuitivamente el motivo del error. En mi opinión, esta no es la mejor forma de solucionar el problema.
En este artículo, quiero describir una técnica para analizar fallas graves de microcontroladores populares con un núcleo Cortex M3 / M4. Aunque, quizás, "técnica" es una palabra demasiado fuerte. Más bien, solo tomaré un ejemplo de cómo analizo la ocurrencia de fallas graves y mostraré lo que se puede hacer en una situación similar. Usaré el software IAR y la placa de depuración STM32F4DISCOVERY, ya que muchos aspirantes a programadores tienen estas herramientas. Sin embargo, esto es completamente irrelevante, este ejemplo se puede adaptar para cualquier procesador de la familia y cualquier entorno de desarrollo.

Caer en HardFault
Antes de intentar analizar HatdFault, debe entrar en él. Hay muchas maneras de hacer esto. De inmediato se me ocurrió intentar cambiar el procesador del estado Thumb al estado ARM estableciendo la dirección de la instrucción de salto incondicional en un número par.
Una pequeña digresión. Como sabe, los microcontroladores de la familia Cortex M3 / M4 utilizan el conjunto de instrucciones de montaje Thumb-2 y siempre funcionan en modo Thumb. El modo ARM no es compatible. Si intenta establecer el valor de la dirección de salto incondicional (BX reg) con el bit menos significativo borrado, se producirá la excepción UsageFault, ya que el procesador intentará cambiar su estado a ARM. Puede leer más sobre esto en [1] (cláusulas 2.8 EL CONJUNTO DE INSTRUCCIONES; 4.3.4 Lenguaje de ensamblador: llamada y rama incondicional).
Para empezar, propongo simular un salto incondicional a una dirección par en C / C ++. Para hacer esto, crearé la función func_hard_fault, luego intentaré llamarla por puntero, después de disminuir la dirección del puntero en uno. Esto puede hacerse de la siguiente manera:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
Veamos con el depurador lo que hice.

En rojo, resalté la instrucción de salto actual en la dirección en RON R1, que contiene una dirección de salto uniforme. Como resultado:

esta operación se puede realizar de forma aún más sencilla utilizando inserciones de ensamblador:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
¡Hurra, entramos en HardFault, misión completada!
Análisis de HardFault
¿Dónde llegamos a HardFault?
En mi opinión, lo más importante es averiguar de dónde llegamos a HardFault. No es difícil de hacer. Primero, escriba nuestro propio controlador para la situación de HardFault.
extern "C"
{
void HardFault_Handler(void)
{
}
}Ahora hablemos de cómo averiguar cómo llegamos aquí. El núcleo del procesador Cortex M3 / M4 tiene algo tan maravilloso como la preservación del contexto [1] (cláusula 9.1.1 Apilamiento). En términos simples, cuando ocurre alguna excepción, el contenido de los registros R0-R3, R12, LR, PC, PSR se almacenan en la pila.

Aquí, el registro más importante para nosotros será el registro de la PC, que contiene información sobre la instrucción que se está ejecutando actualmente. Dado que el valor del registro se introdujo en la pila en el momento de la excepción, contendrá la dirección de la última instrucción ejecutada. El resto de registros son menos importantes para el análisis, pero se les puede arrebatar algo útil. LR es la dirección de retorno de la última transición, R0-R3, R12 son valores que pueden indicar en qué dirección moverse, PSR es solo un registro general del estado del programa.
Propongo averiguar los valores de los registros en el controlador. Para hacer esto, escribí el siguiente código (vi un código similar en uno de los archivos del fabricante):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
Como resultado, tenemos los valores de todos los registros guardados:
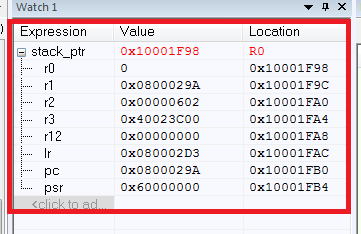
¿Qué pasó aquí? Primero, configuramos el puntero de la pila stack_ptr, todo está claro aquí. Surgen dificultades con la inserción del ensamblador (si es necesario comprender las instrucciones del ensamblador para Cortex, recomiendo [2]).
¿Por qué no guardamos la pila a través de MRS stack_ptr, MSP? El hecho es que los núcleos Cortex M3 / M4 tienen dos punteros de pila [1] (elemento 3.1.3 Stack Pointer R13): el puntero de pila principal de MSP y el puntero de pila de proceso de PSP. Se utilizan para diferentes modos de procesador. No profundizaré en para qué se hace esto y cómo funciona, pero daré una pequeña explicación.
Para averiguar el modo de funcionamiento del procesador (utilizado en este MSP o PSP), debe verificar el tercer bit del registro de comunicación. Este bit determina qué puntero de pila se usa para regresar de una excepción. Si este bit está establecido, entonces es MSP, si no, entonces PSP. En general, la mayoría de las aplicaciones escritas en C / C ++ usan solo MSP, y esta verificación se puede omitir.
Entonces, ¿cuál es el resultado final? Teniendo una lista de registros guardados, podemos determinar fácilmente de dónde proviene el programa en HardFault desde el registro de la PC. La PC apunta a la dirección 0x0800029A, que es la dirección de nuestra instrucción de "ruptura". No olvide la importancia de los valores de los registros restantes.
Causa de HardFault
De hecho, también podemos averiguar la causa del HardFault. Dos registros nos ayudarán con esto. Registro de estado de fallo duro (HFSR) y registro de estado de fallo configurable (CFSR; UFSR + BFSR + MMFSR). El registro CFSR consta de tres registros: registro de estado de falla de uso (UFSR), registro de estado de falla de bus (BFSR), registro de dirección de falla de gestión de memoria (MMFSR). Puede leer sobre ellos, por ejemplo, en [1] y [3].
Propongo ver qué producen estos registros en mi caso:

Primero, se establece el bit HFSR FORCED. Esto significa que se ha producido un error que no se puede procesar. Para más diagnósticos, se deben examinar los registros de estado de falla restantes.
En segundo lugar, se establece el bit CFSR INVSTATE. Esto significa que se ha producido un UsageFault porque el procesador intentó ejecutar una instrucción que utiliza EPSR de forma ilegal.
¿Qué es EPSR? EPSR - Registro de estado del programa de ejecución. Este es un registro interno de PSR, un registro de estado de programa especial (que, como recordamos, se almacena en la pila). El vigésimo cuarto bit de este registro indica el estado actual del procesador (Thumb o ARM). Esto puede determinar nuestra razón del fracaso. Intentemos contarlo:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
Como resultado de la ejecución, obtenemos el valor EPSR = 0. ¿

Resulta que el registro muestra el estado de ARM y encontramos la causa de la falla? Realmente no. De hecho, de acuerdo con [3] (p. 23), leer este registro usando un comando especial de MSR siempre devuelve cero. No tengo muy claro por qué funciona de esta manera, porque este registro ya es de solo lectura, pero aquí no se puede leer completamente (solo se pueden usar algunos bits a través de xPSR). Quizás estas sean algunas limitaciones arquitectónicas.
Como resultado, desafortunadamente, toda esta información no aporta prácticamente nada a un programador MK normal. Es por eso que considero todos estos registros solo como una adición al análisis del contexto almacenado.
Sin embargo, por ejemplo, si la falla fue causada por división por cero (esta falla se permite configurando el bit DIV_0_TRP del registro CCR), entonces el bit DIVBYZERO se configurará en el registro CFSR, lo que nos indicará el motivo de esta misma falla.
¿Que sigue?
¿Qué se puede hacer después de haber analizado la causa del fallo? El siguiente procedimiento parece ser una buena opción:
- Imprima los valores de todos los registros analizados en la consola de depuración (printf). Esto solo se puede hacer si tiene un depurador JTAG.
- Guarde la información de fallas en una memoria flash interna o externa (si está disponible). También es posible mostrar el valor del registro de la PC en la pantalla del dispositivo (si está disponible).
- Vuelva a cargar el procesador NVIC_SystemReset ().

Fuentes
- Joseph Yiu. La guía definitiva del ARM Cortex-M3.
- Guía de usuario genérica de dispositivos Cortex-M3.
- Manual de programación de MCU y MPU STM32 Cortex-M4.