
Desde un punto de vista arquitectónico, la plataforma IoT requiere que se resuelvan las siguientes tareas:
- La cantidad de datos recibidos, recibidos y procesados requiere un gran ancho de banda, almacenamiento y potencia informática.
- Los dispositivos se pueden distribuir en una amplia área geográfica
- Las empresas requieren que su arquitectura esté en constante evolución para poder ofrecer nuevos servicios a los clientes.
Una de las características de la plataforma IoT es la independencia entre objetos y señales, lo que permite cálculos paralelos, aumentando la productividad.
Los datos de los sensores se recopilan de fuentes: PLC, DCS, microcontroladores, etc. y se pueden almacenar en el dominio del tiempo para evitar la pérdida de datos debido a problemas de conexión. Los datos pueden ser series de tiempo (eventos), datos semiestructurados (registros y binarios) o datos no estructurados (imágenes). Los eventos y datos de series de tiempo se recopilan con frecuencia (desde cada segundo hasta varios minutos). Luego se envían a través de la red y se almacenan en un lago de datos centralizado y una base de datos de series de tiempo TSDB. El lago de datos puede estar basado en la nube, un centro de datos local o un almacenamiento de terceros.
Los datos se pueden procesar de inmediato mediante un análisis de flujo de datos llamado "ruta caliente" con un mecanismo de verificación de reglas basado en un punto de ajuste simple o inteligente. Los análisis avanzados pueden incluir gemelos digitales, aprendizaje automático, aprendizaje profundo o análisis basados en la física. Tal sistema puede procesar una gran cantidad de datos (desde diez minutos hasta un mes) de diferentes sensores. Estos datos se almacenan en un almacenamiento intermedio. Esta analítica se denomina "ruta fría" y normalmente la inicia el planificador o cuando los datos están disponibles y requieren una gran cantidad de recursos informáticos. Los análisis avanzados a menudo necesitan información adicional, como el modelo de vehículo monitoreado y los atributos operativos, que se pueden encontrar en el registro de activos.El registro de activos contiene información sobre el tipo de activo, incluido su nombre, número de serie, nombre simbólico, ubicación, capacidades operativas, el historial de las piezas que lo componen y el papel que desempeña en el proceso de fabricación. En el registro de activos, podemos almacenar una lista de las dimensiones de cada activo, nombre lógico, unidad de medida y rango de límites. En el sector industrial, esta información estática es fundamental para un modelo analítico correcto.En el sector industrial, esta información estática es fundamental para un correcto modelo analítico.En el sector industrial, esta información estática es fundamental para un correcto modelo analítico.
Razones para desarrollar una plataforma personalizada:
- Retorno de la inversión: presupuesto reducido;
- Tecnología: uso de tecnología independientemente del proveedor;
- Confidencialidad de los datos;
- Integración: la necesidad de desarrollar un nivel de integración con una plataforma nueva u obsoleta;
- Otras restricciones.
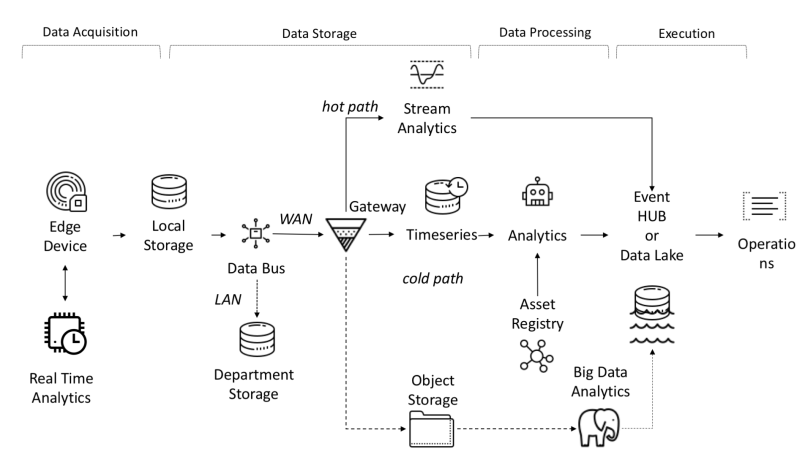
Flujo de datos de un extremo a otro en I-IoT
Ejemplo de implementación personalizada de la plataforma Edge
Esta figura muestra la implementación de los siguientes enlaces de plataforma:
- Fuente de datos: a modo de ejemplo, se selecciona un simulador de controlador Simatic PLCSIM Advanced con un servidor OPC activado, como se describe en el artículo anterior;
- La popular plataforma Node-Red con el complemento node-red-contrib-opcua instalado fue elegida como puerta de enlace fronteriza ;
- El broker Mosquitto de MQTT se utiliza como despachador para la transferencia de datos entre otros enlaces en el flujo;
- Apache Kafka se utiliza como una plataforma de transmisión distribuida que sirve como análisis de rutas activas mediante kafka-streams.
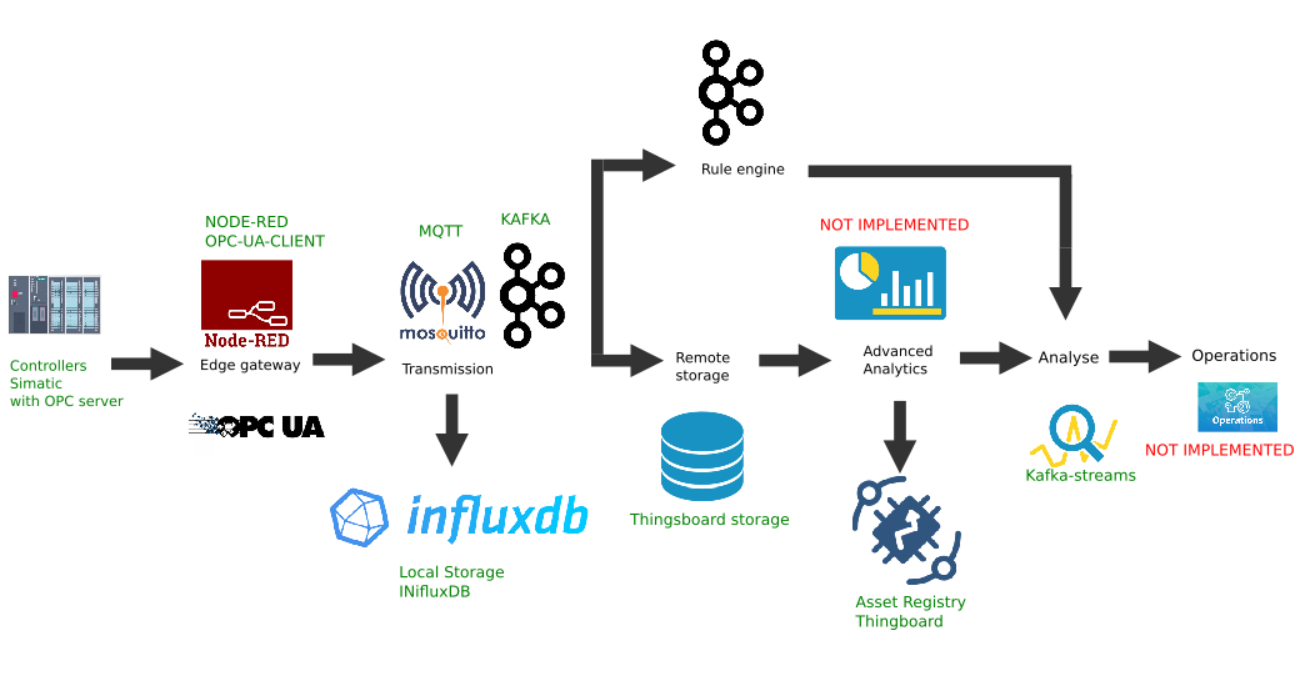
Puerta de enlace Node-red Edge
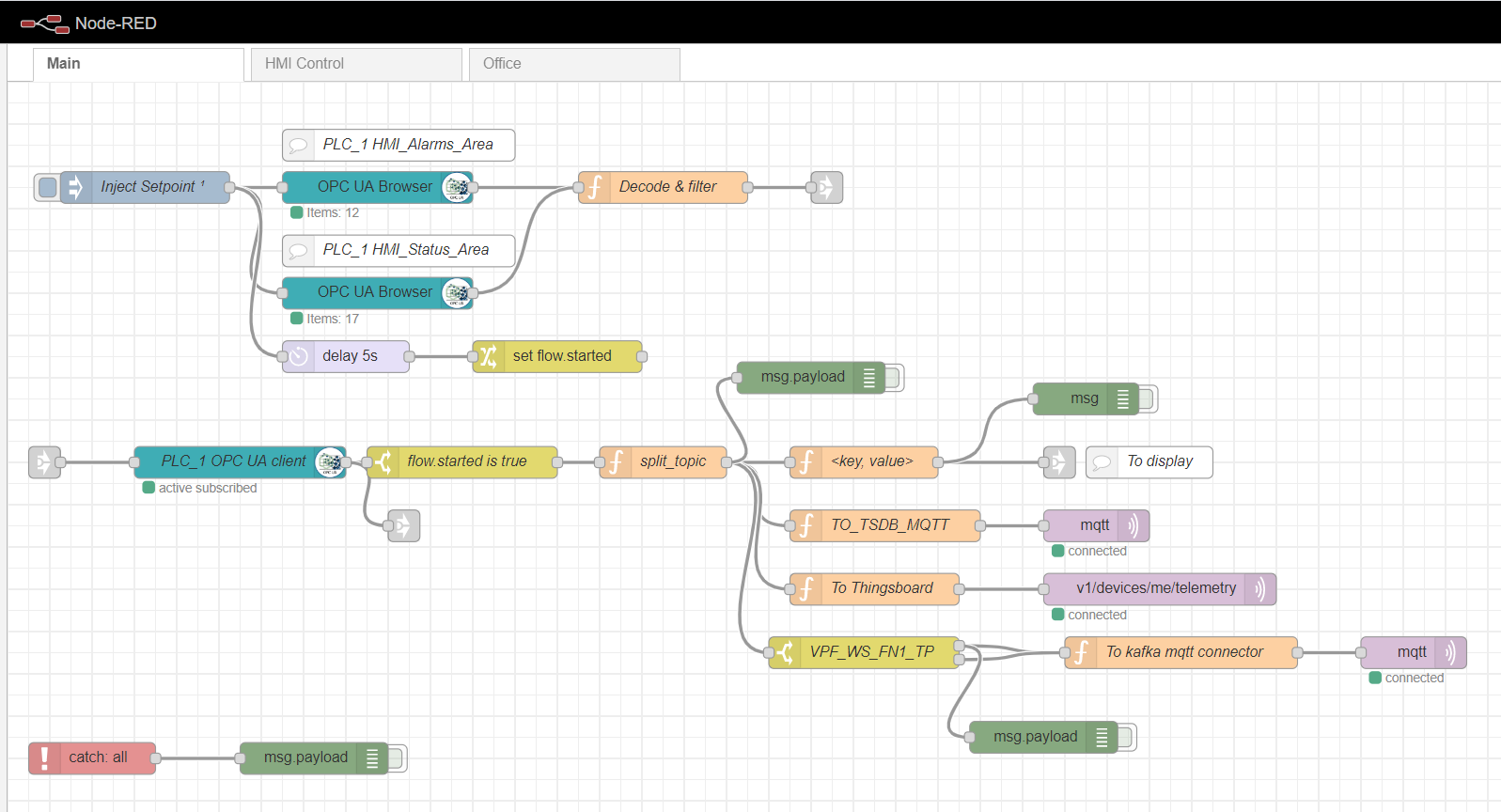
Como puerta de enlace de informática de borde, usaremos Node-red, una plataforma personalizada simple que tiene muchos complementos diferentes. El papel del adaptador industrial lo desempeña el complemento node-red-contrib-opcua. Para la recopilación múltiple de datos del controlador mediante el método de suscripción, se utilizan los nodos: OpcUa-Browser y OpcUa-client. En el nodo del navegador OPC, se configuran la URL del servidor OPC (punto final) y el tema, que especifica el espacio de nombres y el nombre del bloque de datos legibles, por ejemplo: ns = 3; s = "HMI_Alarms_Area". En el nodo de cliente OPC, también se especifica la URL del servidor OPC, el SUBSCRIBE y el intervalo de actualización de datos se establecen como Acción.
Flujo principal de nodo rojo
Configuración del nodo del navegador OPC

OPC-client

Para suscribirse para leer varios datos, es necesario preparar y descargar etiquetas del controlador, de acuerdo con el protocolo OPC. Para hacer esto, primero, se utiliza un nodo de inyección con la casilla de verificación única una vez, que activa una lectura única de los bloques de datos especificados en los nodos del navegador OPC. Luego, los datos son procesados por la función Decodificar y filtrar. Después de eso, el nodo cliente OPC se suscribe y lee los datos cambiantes del controlador. El procesamiento posterior del flujo depende de la implementación y los requisitos específicos. En mi ejemplo, proceso los datos para enviarlos posteriormente al corredor de MQTT a diferentes temas.
Las pestañas de control de HMI y Office son una implementación de HMI simple basada en Scadavis.io y un tablero de nodo rojo como se describe anteriormente en el artículo .
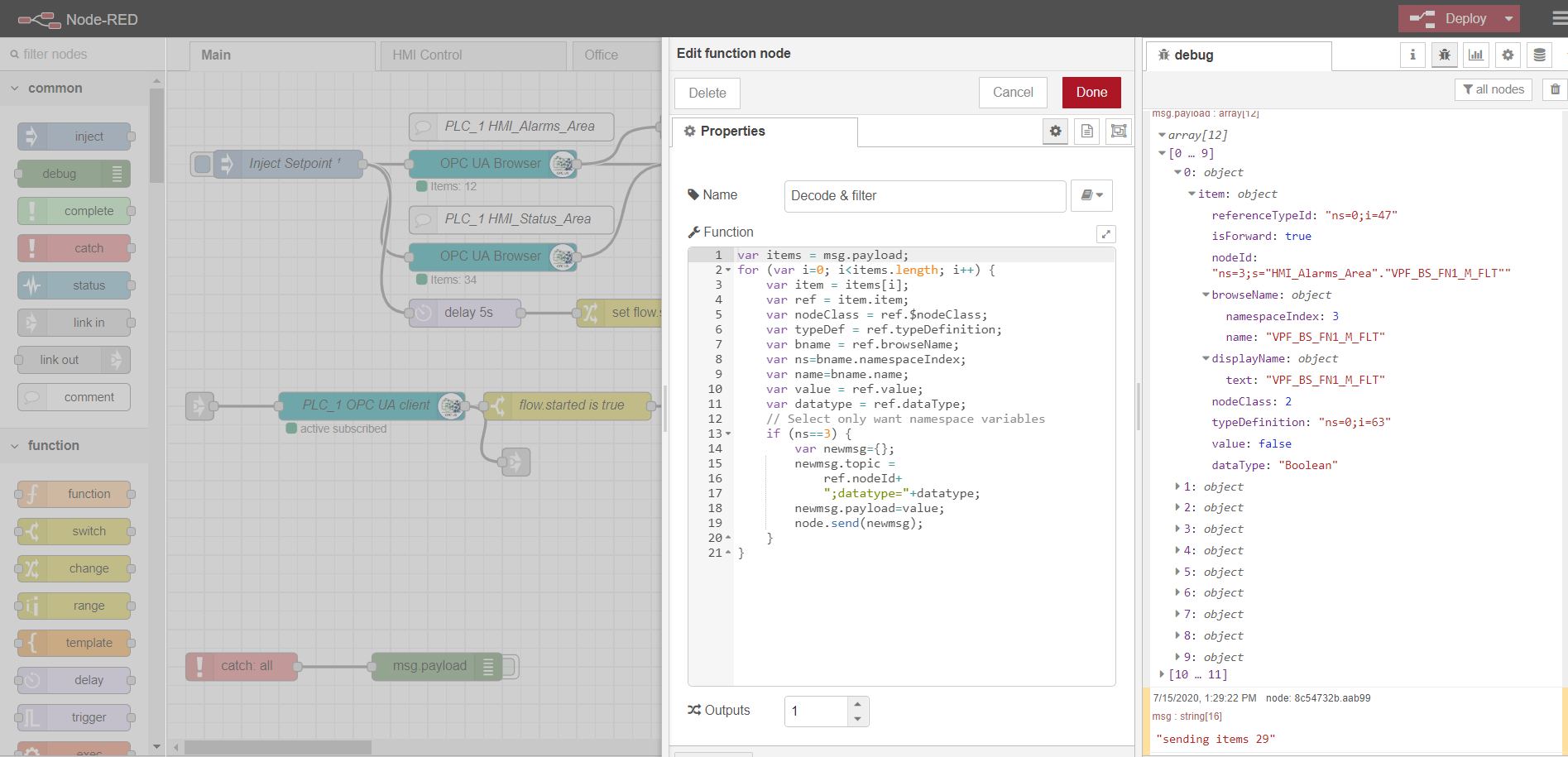
Un ejemplo de análisis de datos de un nodo de navegador OPC:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
Broker MQTT
Cualquier implementación se puede utilizar como intermediario. En mi caso, el broker Mosquitto ya está instalado y configurado . El corredor realiza la función de transportar datos entre la puerta de enlace Edge y otros participantes de la plataforma. Hay ejemplos con equilibrio de carga y arquitectura distribuida ( como aquí ). En este caso, nos limitaremos a un corredor mqtt con transferencia de datos sin cifrado.
Almacenamiento local de datos de series de tiempo
Es conveniente registrar y almacenar datos de series de tiempo en la base de datos de series de tiempo NoSql. La pila InfluxData funciona bien para nuestros propósitos . Necesitamos cuatro servicios de esta pila:
InfluxDB es una base de datos de series de tiempo de código abierto que forma parte de la pila TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Diseñado para el procesamiento de datos de alta carga y proporciona el lenguaje de consulta InfluxQL similar a SQL para interactuar con los datos.
Telegraf es un agente para recopilar y enviar métricas y eventos a InfluxDB desde sistemas externos de IoT, sensores, etc. Está configurado para recopilar datos de temas mqtt.
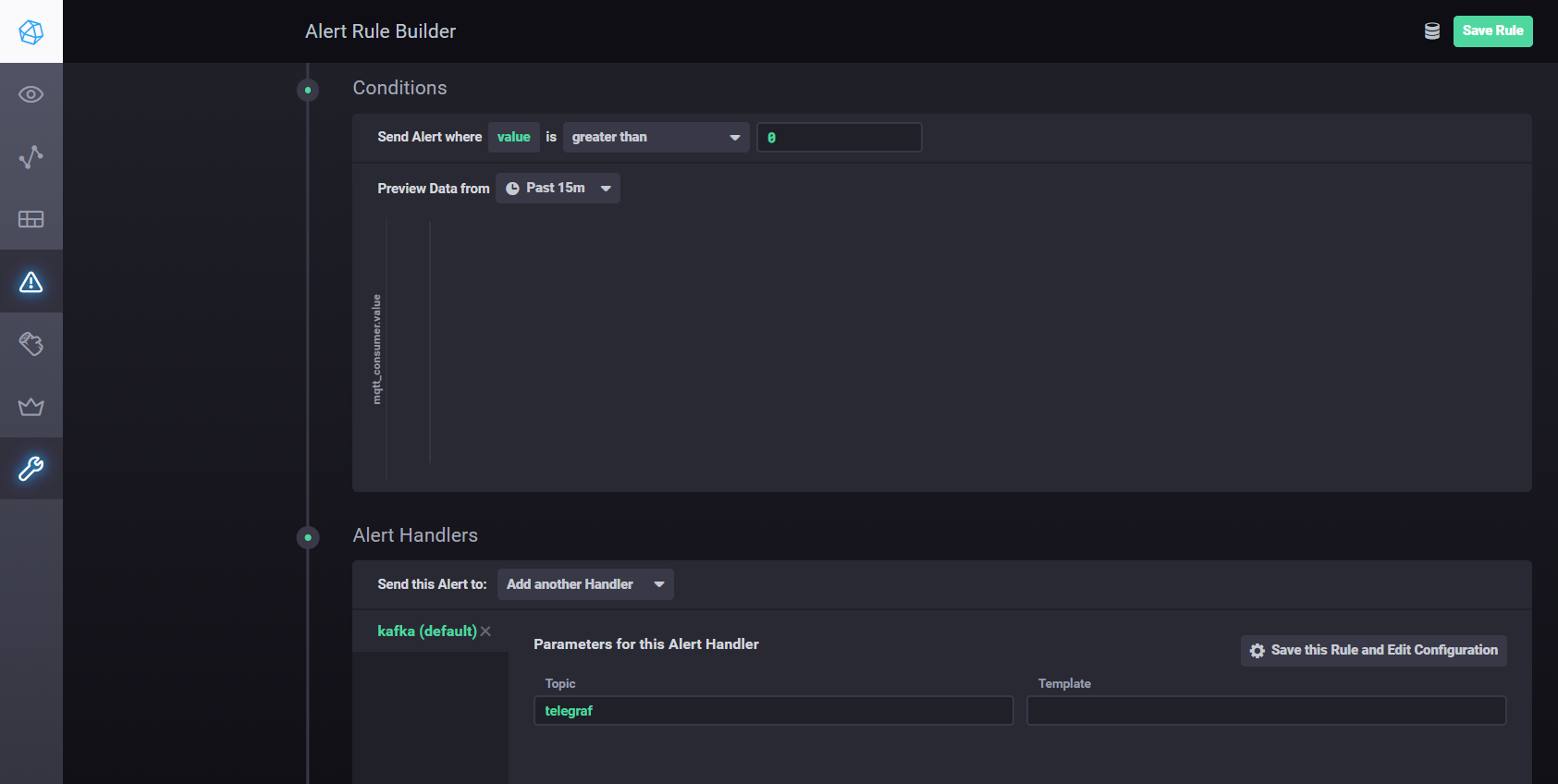
Kapacitor es un motor de datos integrado para InfluxDB 1.xy un componente integrado en la plataforma InfluxDB. Este servicio se puede configurar para monitorear varios puntos de ajuste y alarmas, así como instalar un controlador para enviar eventos a sistemas externos como Kafka, correo electrónico, etc.
Chronograf es la interfaz de usuario y el componente administrativo de la plataforma InfluxDB. Se utiliza para crear cuadros de mando rápidamente con visualización en tiempo real.
Todos los componentes de la pila se pueden ejecutar localmente o configurar un contenedor Docker.
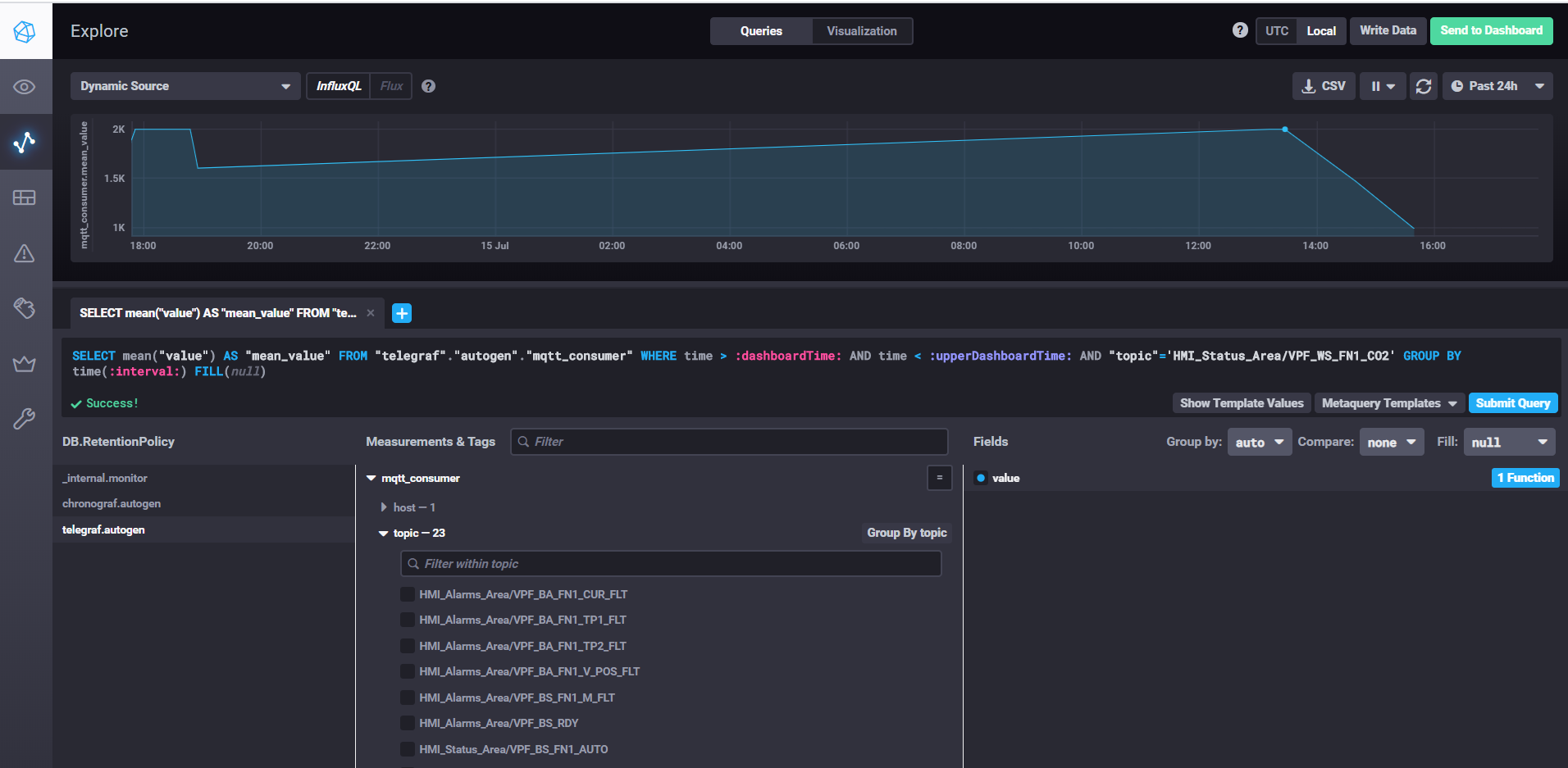
Obtención de datos y personalización de paneles con Chronograf
Para iniciar InfluxDB, simplemente ejecute el comando influxd, en la configuración de influxdb.conf, puede especificar la ubicación de almacenamiento y otras propiedades, por defecto los datos se almacenan en el directorio de usuario en el directorio .influxdb.
Para iniciar telegraf, debe ejecutar el comando telegraf -config telegraf.conf, donde puede especificar las fuentes de métricas y eventos en la configuración, en nuestro ejemplo para mqtt se ve así:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
En la propiedad de los servidores especificamos la url al corredor mqtt, qos puede dejar 0 si es suficiente para escribir datos sin confirmación. En la propiedad de los temas, especifique las máscaras mqtt de los temas de los que leeremos datos. Por ejemplo, HMI_Status_Area / # significa que leemos todos los temas que tienen el prefijo HMI_Status_Area. Por lo tanto, telegraf para cada tema creará su propia métrica en la base de datos, donde escribirá los datos.
Para iniciar kapacitor, debe ejecutar el comando kapacitord -config kapacitor.conf. Las propiedades se pueden dejar por defecto y se pueden realizar más ajustes con chronograf.
Para iniciar el cronógrafo, simplemente ejecute el comando cronógrafo del mismo nombre. La interfaz web estará disponible localhost : 8888 /
Para configurar ajustes y alarmas usando Kapacitor, puede usarmanual . En resumen, debe ir a la pestaña Alertas en Chronograf y crear una nueva regla usando el botón Crear regla de alerta, la interfaz es intuitiva, todo se hace visualmente. Para configurar el envío de resultados de procesamiento a kafka, etc. necesita agregar un controlador en la sección Condiciones
Configuración del controlador de Kapacitor
Streaming distribuido con Apache Kafka
La arquitectura propuesta requiere desvincular la recopilación de datos del procesamiento, mejorando la escalabilidad y la independencia de la capa. Podemos usar una cola para lograr este objetivo. La implementación puede ser Java Message Service (JMS) o Advanced Message Queue Server Protocol (AMQP), pero en este caso usaremos Apache Kafka. Kafka es compatible con la mayoría de las plataformas de análisis, tiene un rendimiento y una escalabilidad muy altos, y tiene una buena biblioteca de flujos de Kafka.
Puede utilizar el complemento Node-red node-red-contrib-kafka-manager para interactuar con Kafka . Pero, teniendo en cuenta la separación de la recopilación del procesamiento de datos, instalaremos el complemento MQTT, que se suscribe a los temas de Mosquitto. El complemento MQTT está disponible aquí .
Para configurar el conector, copie las bibliotecas kafka-connect-mqtt-1.1-SNAPSHOT.jar y org.eclipse.paho.client.mqttv3-1.0.2.jar (u otra versión) en el directorio kafka / libs /. Luego, en el directorio / config, debe crear un archivo de propiedades mqtt.properties con el siguiente contenido:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Habiendo lanzado previamente zookeeper-server y kafka-server, podemos iniciar el conector usando el comando:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
Desde el tema mqtt (mqtt.topic = mqtt), los datos se escribirán en el tema de Kafka streams-Measures (kafka.topic = streams-Measures).
Como ejemplo simple, puede crear un proyecto de maven usando la biblioteca kafka-streams.
Con kafka-streams, puede implementar varios servicios y escenarios para análisis en caliente y procesamiento de datos de transmisión.
Un ejemplo de comparación de la temperatura actual con el punto de ajuste del período.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Registro de activos
El registro de activos, de hecho, no es un componente estructural de la plataforma Edge y es parte del entorno de IoT en la nube. Pero este ejemplo muestra cómo interactúan Edge y Cloud.
Como registro de activos, utilizaremos la popular plataforma ThingsBoard IoT, cuya interfaz también es bastante intuitiva. La instalación es posible con datos de demostración. La plataforma se puede instalar localmente, en la ventana acoplable o utilizando un entorno de nube listo para usar .
El conjunto de datos de demostración incluye dispositivos de prueba (puede crear fácilmente uno nuevo) a los que puede enviar valores. De forma predeterminada, ThingsBoard comienza con su propio agente mqtt, al que debe conectarse y enviar datosen formato json. Digamos que queremos enviar datos a ThingsBoard desde TEST DEVICE A1. Para hacer esto, necesitamos conectarnos al corredor ThingBoard en localhost: 1883 usando A1_TEST_TOKEN como inicio de sesión, que se puede copiar desde la configuración del dispositivo. Luego, podemos publicar los datos en el tema v1 / devices / me / telemetry: {"temperature": 26}
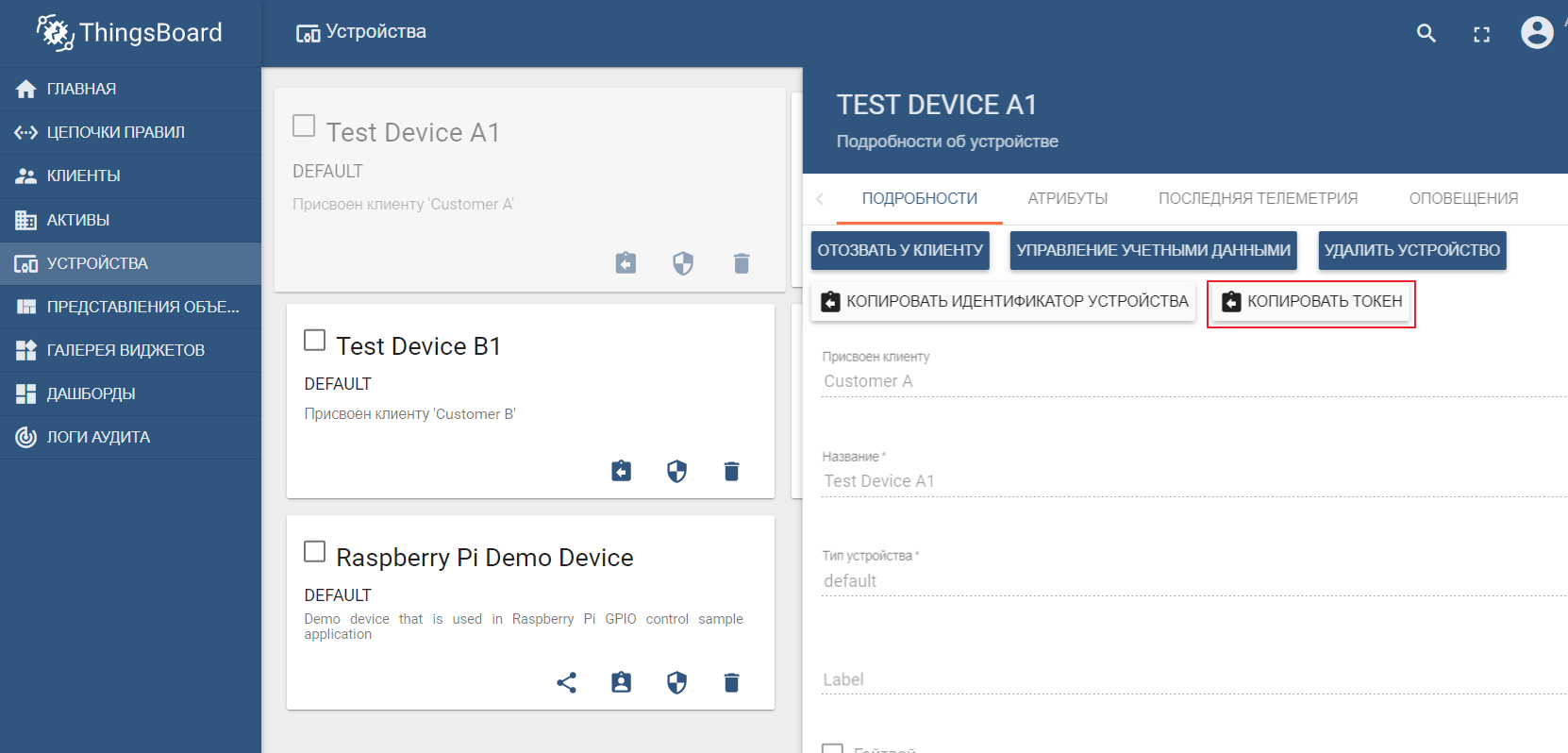
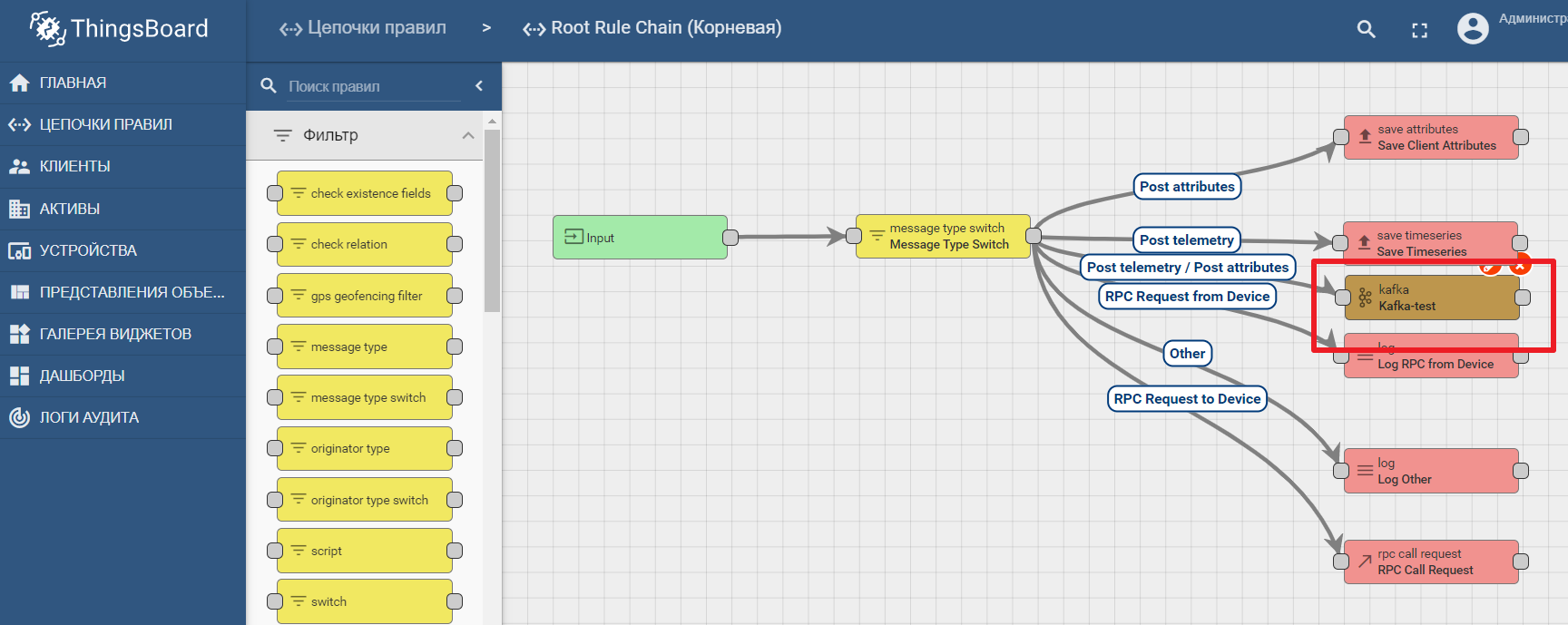
La documentación de la plataforma contiene un manual para configurar la transferencia de datos y el análisis de procesamiento en Kafka: análisis de datos de IoT usando Kafka, Kafka Streams y ThingsBoard
Un ejemplo del uso de un nodo kafka en Thingsboard
Conclusión
Las tecnologías de TI modernas y los protocolos abiertos permiten diseñar sistemas de cualquier complejidad. La plataforma perimetral es el punto de conexión entre el entorno industrial y la plataforma IoT basada en la nube. Se puede descomponer en macrocomponentes, entre los que juega un papel clave la puerta de enlace de borde, responsable de reenviar datos desde los dispositivos al centro de datos de IoT. Las herramientas de transmisión de datos abiertas permiten análisis eficientes y computación de borde.