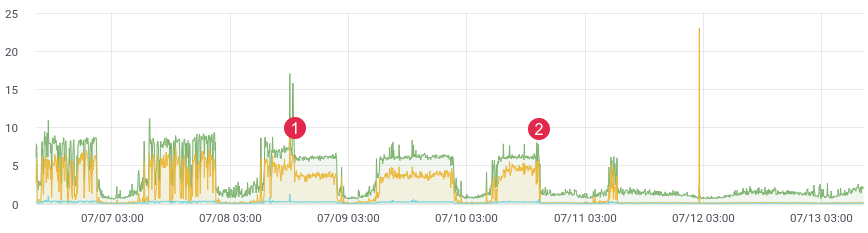
aprox. tiempo de latencia.
Probablemente todo el mundo se enfrenta a la tarea de perfilar el código en producción. El xhprof de Facebook lo hace bien. Perfila, por ejemplo, 1/1000 solicitudes y ve la imagen en este momento. Después de cada lanzamiento, el producto se ejecuta y dice "era mejor y más rápido antes del lanzamiento". No tienes datos históricos y no puedes probar nada. ¿Y si pudieras?
No hace mucho tiempo, reescribimos una parte problemática del código y esperábamos una gran ganancia de rendimiento. Escribimos pruebas unitarias, hicimos pruebas de carga, pero ¿cómo se comportará el código bajo carga en vivo? Después de todo, sabemos que las pruebas de carga no siempre muestran datos reales y, después de la implementación, necesita obtener rápidamente comentarios de su código. Si está recopilando datos, después del lanzamiento, solo necesita de 10 a 15 minutos para comprender la situación en el entorno de combate.
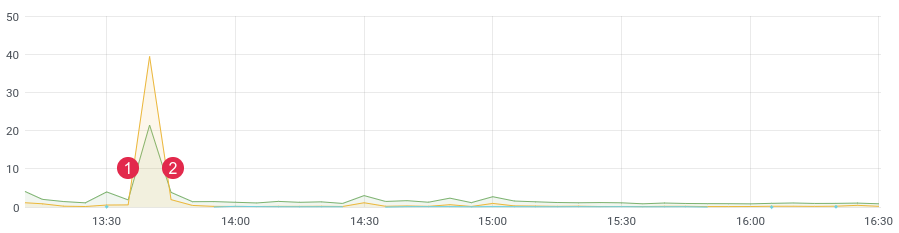
aprox. tiempo de latencia. (1) implementar, (2) deshacer
Apilar
Para nuestra tarea, tomamos una base de datos de ClickHouse en columnas (abreviado kx). La velocidad, la escalabilidad lineal, la compresión de datos y la ausencia de interbloqueo fueron las principales razones de esta elección. Ahora es una de las principales bases del proyecto.
En la primera versión, escribimos mensajes en la cola, y ya los consumidores los escribimos a ClickHouse. El retraso alcanzó las 3-4 horas (sí, ClickHouse es lento para insertar uno por unoregistros). Pasó el tiempo y era necesario cambiar algo. No tenía sentido responder a las notificaciones con tanta demora. Luego escribimos un comando de corona que seleccionó la cantidad requerida de mensajes de la cola y envió un lote a la base de datos, luego los marcó como procesados en la cola. Los primeros meses todo estuvo bien, hasta que empezaron los problemas aquí. Hubo demasiados eventos, comenzaron a aparecer datos duplicados en la base de datos, las colas no se utilizaron para el propósito previsto (se convirtieron en una base de datos) y el comando crown dejó de hacer frente a la grabación en ClickHouse. Durante este tiempo, se agregaron otras dos docenas de tablas al proyecto, que debían escribirse en lotes en kx. La velocidad de procesamiento ha disminuido. La solución fue lo más simple y rápida posible. Esto nos llevó a escribir código con listas en redis. La idea es esta: escribimos mensajes al final de la lista,Con el comando corona formamos un paquete y lo enviamos a la cola. Luego, los consumidores analizan la cola y escriben un montón de mensajes en kx.
Tenemos : ClickHouse, Redis y una cola (cualquiera - rabbitmq, kafka, beanstalkd ...)
Redis y listas
Hasta cierto tiempo, Redis se usaba como caché, pero eso está cambiando. La base tiene una gran funcionalidad, y para nuestra tarea solo se necesitan 3 comandos: rpush , lrange y ltrim .
Usaremos el comando rpush para escribir datos al final de la lista. En el comando crown, lea los datos usando lrange y envíelos a la cola, si logramos enviarlos a la cola, entonces necesitamos eliminar los datos seleccionados usando ltrim.
De la teoría a la práctica. Creemos una lista simple.

Tenemos una lista de tres mensajes, agreguemos un poco más ...
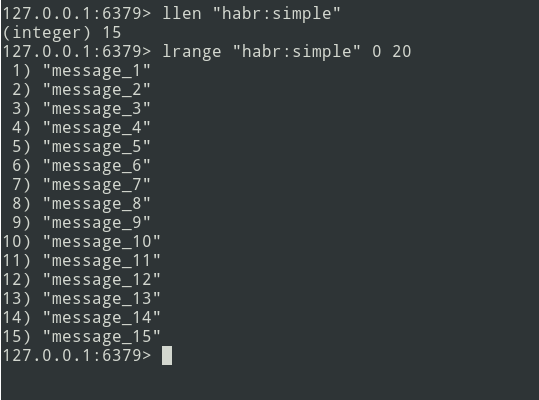
Los mensajes nuevos se agregan al final de la lista. Usando el comando lrange, seleccione el lote (sea = 5 mensajes).
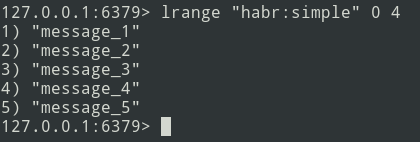
A continuación, enviamos el paquete a la cola. Ahora debe eliminar este paquete de Redis para no volver a enviarlo.
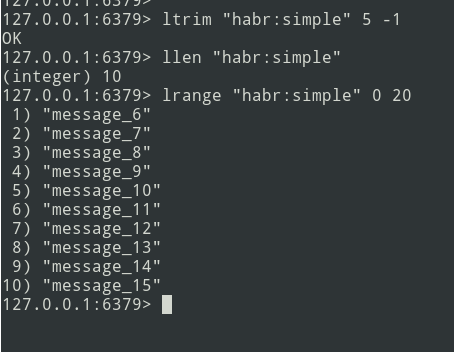
Hay un algoritmo, vayamos a la implementación.
Implementación
Comencemos con la tabla ClickHouse. No me molesté demasiado y definí todo en el tipo String .
create table profile_logs
(
hostname String, // ,
project String, //
version String, //
userId Nullable(String),
sessionId Nullable(String),
requestId String, //
requestIp String, // ip
eventName String, //
target String, // URL
latency Float32, // (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);El evento será así:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}La estructura está definida. Para calcular la latencia necesitamos un período de tiempo. Identificamos usando la función microtime :
$beginTime = microtime(true);
//
$latency = microtime(true) - $beginTime;Para simplificar la implementación, usaremos el marco laravel y la biblioteca laravel-entry . Agregar un modelo (tabla profile_logs):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}Escribamos un método tick (hice un servicio ProfileLogService ) que escribirá mensajes en Redis. Obtenemos la hora actual (nuestra beginTime) y la escribimos en la variable $ currentTime:
$currentTime = \microtime(true);Si el tick de un evento se llama por primera vez, escríbalo en la matriz tick y finalice el método:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}Si se vuelve a llamar al tick, escribimos el mensaje en Redis usando el método rpush:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));La variable $ this-> ticks no es estática. Necesita registrar el servicio como singleton.
$this->app->singleton(ProfileLogService::class);El tamaño del lote ( $ batchSize ) es configurable, se recomienda especificar un valor pequeño (por ejemplo, 10,000 artículos). Si surgen problemas (por ejemplo, ClickHouse no está disponible), la cola comenzará a fallar y deberá depurar los datos.
Escribamos un comando de corona:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// json, decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// ch
\dispatch(new BulkWriter($bulkData));
// redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);Puede escribir datos inmediatamente en ClickHouse, pero el problema radica en el hecho de que kronor funciona en modo de un solo subproceso. Por lo tanto, iremos al revés: con el comando formaremos paquetes y los enviaremos a la cola para su posterior grabación multiproceso en ClickHouse. Se puede regular el número de consumidores, lo que acelerará el envío de mensajes.
Pasemos a escribir a un consumidor:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}Entonces, se desarrolla la formación de paquetes, el envío a la cola y el consumidor; puede comenzar a perfilar:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;Si todo se hace correctamente, los datos deberían estar en Redis. Confundiremos el comando crown y enviaremos los paquetes a la cola, y el consumidor los insertará en la base de datos.
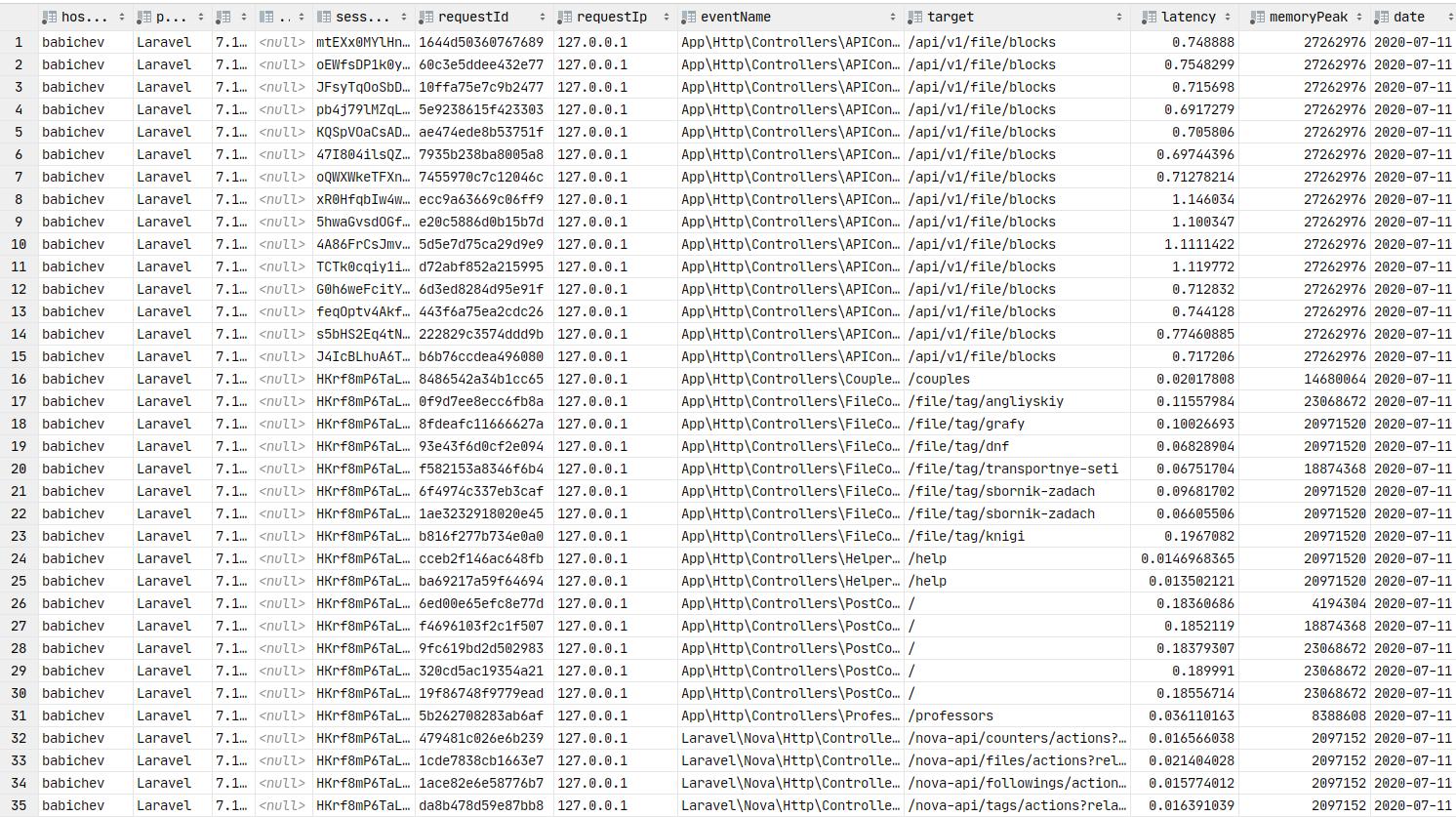
Datos en la base de datos. Puede crear gráficos.
Grafana
Ahora pasemos a la presentación gráfica de datos, que es un elemento clave de este artículo. Necesitas instalar grafana . Saltemos el proceso de instalación para ensamblajes de tipo debain, puede usar el enlace a la documentación . Por lo general, el paso de instalación se reduce a apt install grafana .
En ArchLinux, la instalación se ve así:
yaourt -S grafana
sudo systemctl start grafanaEl servicio ha comenzado. URL: http: // localhost: 3000
Ahora necesita instalar el complemento de origen de datos de ClickHouse :
sudo grafana-cli plugins install vertamedia-clickhouse-datasourceSi ha instalado grafana 7+, ClickHouse no funcionará. Debe realizar cambios en la configuración:
sudo vi /etc/grafana.iniBusquemos la línea:
;allow_loading_unsigned_plugins =Reemplazémoslo con este:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasourceGuardemos y reiniciemos el servicio:
sudo systemctl restart grafanaHecho. Ahora podemos ir a grafana .
Inicio de sesión: admin / contraseña: admin por defecto.

Después de la autorización exitosa, haga clic en el engranaje. En la ventana emergente que se abre, seleccione Fuentes de datos, agregue una conexión a ClickHouse.
Rellenamos la configuración kx. Haga clic en el botón "Guardar y probar", recibimos un mensaje sobre una conexión exitosa.
Ahora agreguemos un nuevo tablero:
Agregue un panel:

Seleccione la base y las columnas correspondientes para trabajar con fechas:
Pasemos a la consulta:
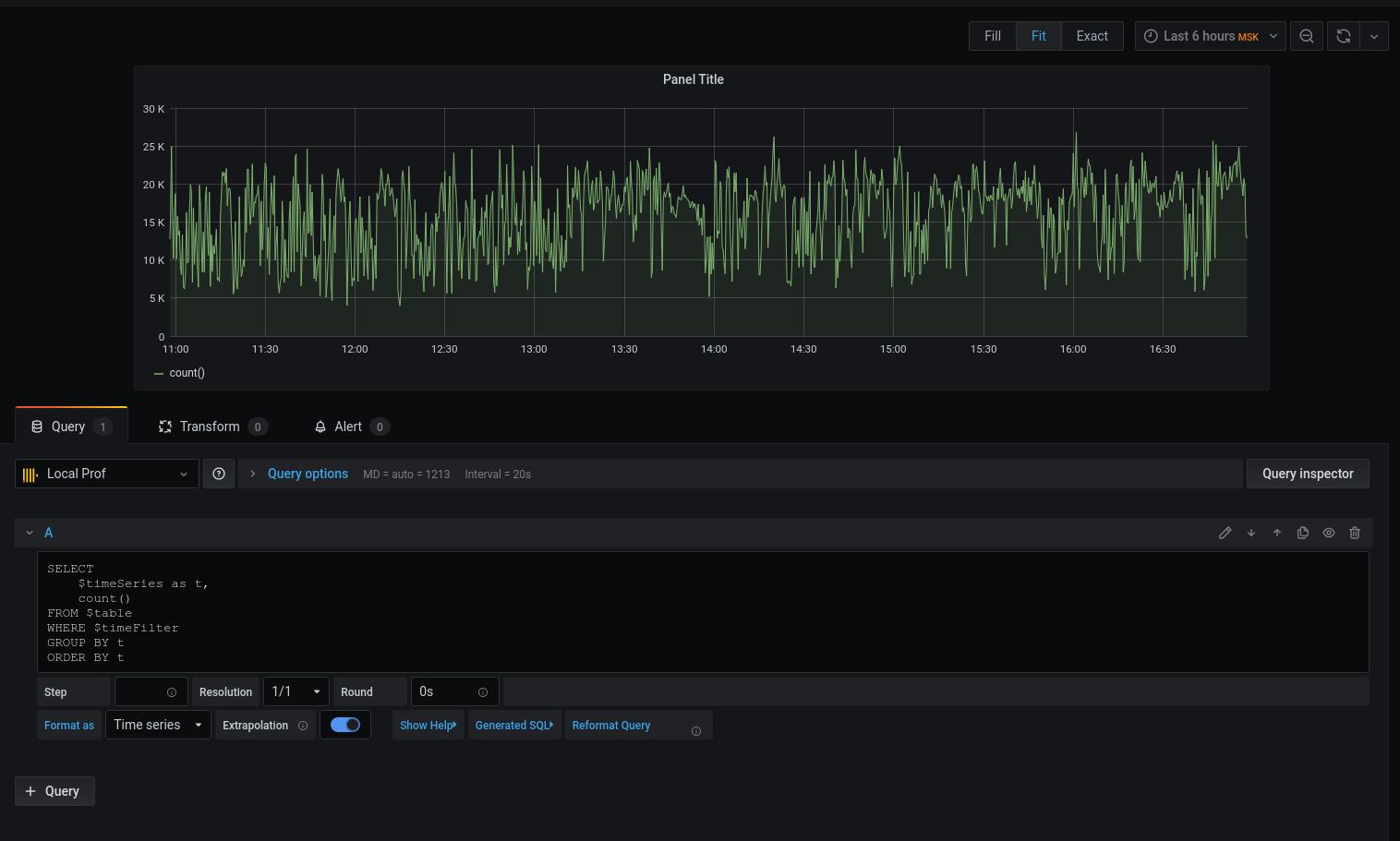
Tenemos un gráfico, pero quiero detalles. Imprimamos la latencia promedio redondeando la fecha con la hora hasta el comienzo del intervalo de cinco minutos :
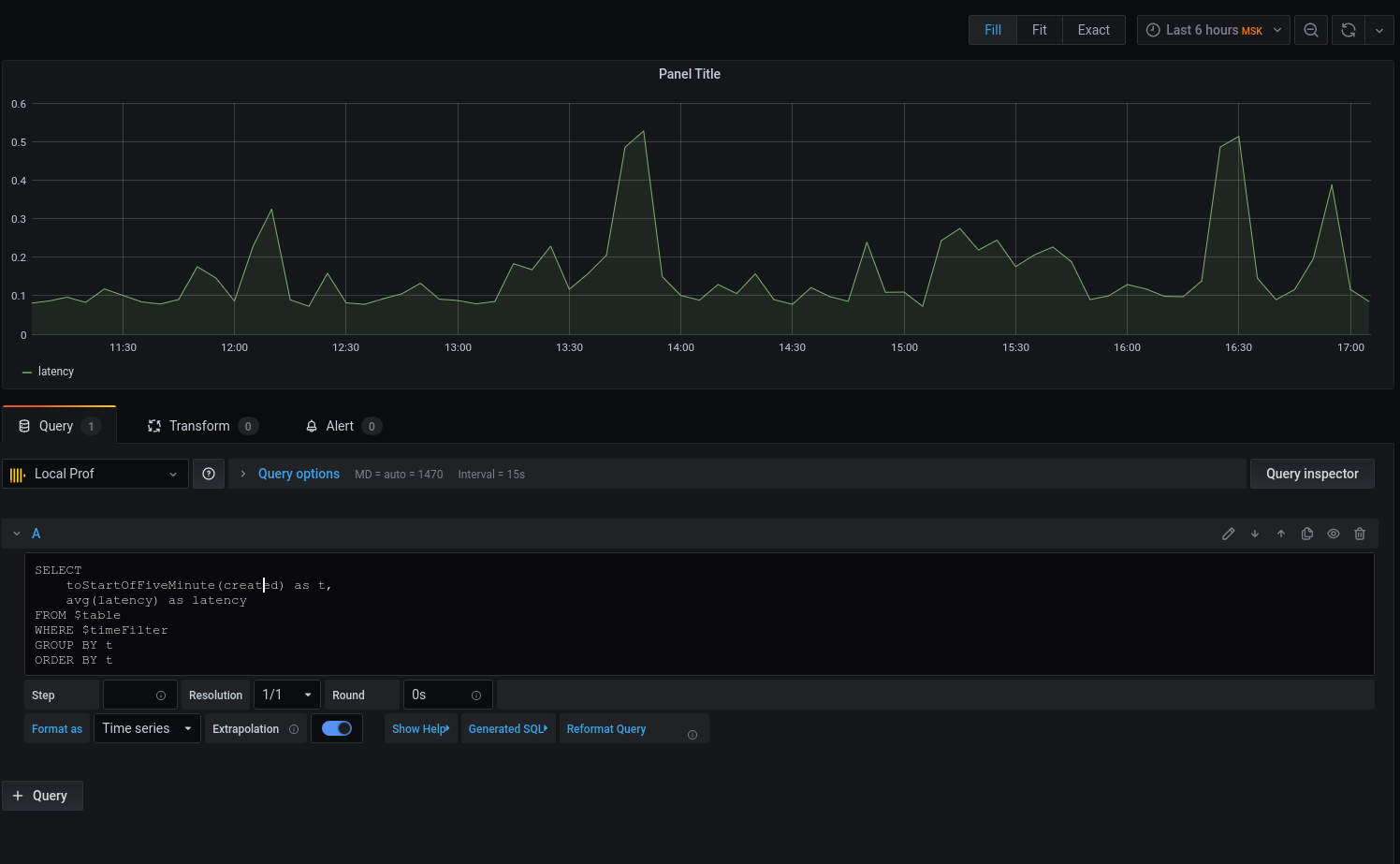
Ahora que los datos seleccionados se muestran en el gráfico, podemos centrarnos en ellos. Para alertas, configure disparadores, agrupe por eventos y mucho más.
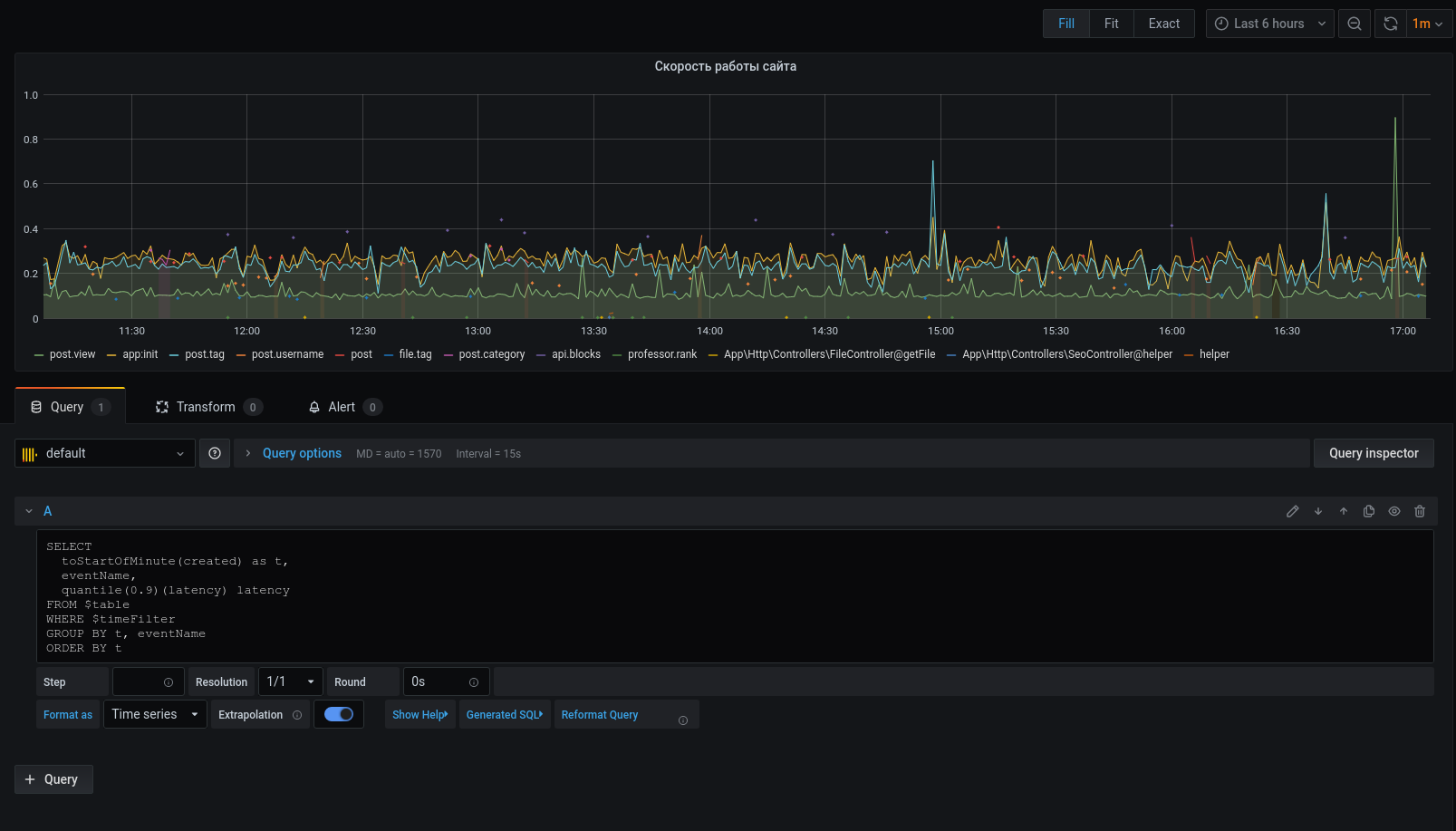
El generador de perfiles no reemplaza de ninguna manera las herramientas: xhprof (facebook) , xhprof (tideways) , liveprof de (Badoo) . Y solo los complementa.
Todo el código fuente está en github : modelo de perfil , servicio , BulkWriteCommand , BulkWriterJob y middleware ( 1 , 2 ).
Instalando el paquete:
composer req bavix/laravel-profConfigurando conexiones (config / database.php), agregue clickhouse:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
Inicio de obra:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
//
app(ProfileLogService::class)->tick('event-name');Para enviar un lote a la cola, debe agregar un comando a cron:
* * * * * php /var/www/site.com/artisan entry:bulkTambién necesita ejecutar un consumidor:
php artisan queue:work --sleep=3 --tries=3Se recomienda configurar supervisor . Config (5 consumidores):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse puede extraer datos de forma nativa de la cola de kafka . Gracias,sdm