Arquitectura de hardware de memoria
La arquitectura de hardware de memoria moderna es algo diferente del modelo de memoria interna de Java. Es importante comprender la arquitectura del hardware para comprender cómo funciona el modelo Java con ella. Esta sección describe la arquitectura de hardware de memoria general y la siguiente sección describe cómo funciona Java con ella.
A continuación se muestra un diagrama simplificado de la arquitectura de hardware de una computadora moderna:
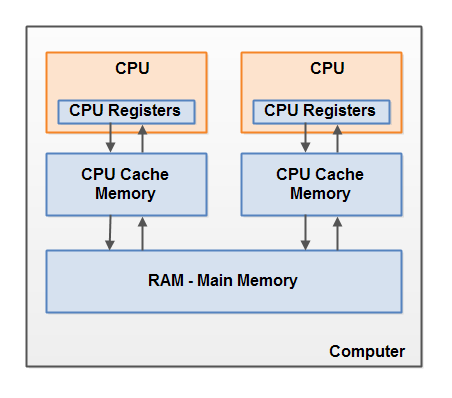
Una computadora moderna a menudo tiene 2 o más procesadores. Algunos de estos procesadores también pueden tener varios núcleos. En dichos equipos, se pueden ejecutar varios subprocesos simultáneamente. Cada procesador (nota del traductor; en adelante, el autor probablemente se refiera a un núcleo de procesador o un procesador de un solo núcleo por un procesador)capaz de ejecutar un hilo en cualquier momento. Esto significa que si su aplicación Java es multiproceso, entonces dentro de su programa se puede ejecutar un subproceso simultáneamente por procesador.
Cada procesador contiene un conjunto de registros que se encuentran esencialmente en su memoria. Puede realizar operaciones con datos en registros mucho más rápido que con datos que se encuentran en la memoria principal (RAM) de la computadora. Esto se debe a que el procesador puede acceder a estos registros mucho más rápido.
Cada CPU también puede tener una capa de caché. De hecho, la mayoría de los procesadores modernos lo tienen. Un procesador puede acceder a su memoria caché mucho más rápido que la memoria principal, pero generalmente no tan rápido como sus registros internos. Por tanto, la velocidad de acceso a la memoria caché se encuentra entre la velocidad de acceso a los registros internos y la memoria principal. Algunos procesadores pueden tener cachés escalonados, pero no es importante comprender esto para comprender cómo interactúa el modelo de memoria Java con la memoria del hardware. Es importante saber que los procesadores pueden tener cierto nivel de memoria caché.
La computadora también contiene un área de memoria principal (RAM). Todos los procesadores pueden acceder a la memoria principal. El área de memoria principal suele ser mucho más grande que la caché del procesador.
Normalmente, cuando un procesador necesita acceder a la memoria principal, lee una parte de ella en su memoria caché. También puede leer parte de los datos de la caché en sus registros internos y luego realizar operaciones en ellos. Cuando la CPU necesita volver a escribir un resultado en la memoria principal, descarga los datos de su registro interno en la memoria caché y, en algún momento, en la memoria principal.
Los datos almacenados en la caché generalmente se descargan de nuevo a la memoria principal cuando el procesador necesita almacenar algo más en la caché. La caché puede borrar su memoria y escribir nuevos datos al mismo tiempo. El procesador no tiene que leer / escribir el caché completo cada vez que se actualiza. Por lo general, la caché se actualiza en pequeños bloques de memoria llamados "líneas de caché". Una o más líneas de caché se pueden leer en la memoria caché y una o más líneas de caché se pueden vaciar de nuevo a la memoria principal.
Combinando el modelo de memoria de Java y la arquitectura de memoria de hardware
Como se mencionó, el modelo de memoria de Java y la arquitectura de hardware de memoria son diferentes. La arquitectura de hardware no distingue entre pila de subprocesos y montón. En el hardware, la pila de subprocesos y el montón están en la memoria principal. Algunas veces, partes de pilas y montones de subprocesos pueden estar presentes en cachés y registros internos de la CPU. Esto se muestra en el diagrama:

Cuando los objetos y las variables se pueden almacenar en diferentes áreas de la memoria de la computadora, pueden surgir ciertos problemas. Hay dos principales:
• Visibilidad de los cambios realizados por el hilo en las variables compartidas.
• Condiciones de carrera al leer, verificar y escribir variables compartidas.
Ambos problemas se explicarán en las siguientes secciones.
Visibilidad de objetos compartidos
Si dos o más subprocesos comparten un objeto entre sí sin una declaración o sincronización volátil adecuada, es posible que los cambios en el objeto compartido realizados por un subproceso no sean visibles para otros subprocesos.
Imagine que un objeto compartido se almacena inicialmente en la memoria principal. Un hilo que se ejecuta en una CPU lee un objeto compartido en el caché de esa misma CPU. Allí realiza cambios en el objeto. Hasta que la memoria caché de la CPU se vacíe en la memoria principal, la versión modificada del objeto compartido no es visible para los subprocesos que se ejecutan en otras CPU. Por lo tanto, cada hilo puede obtener su propia copia del objeto compartido, cada copia estará en un caché de CPU separado.
El siguiente diagrama ilustra un esquema de esta situación. Un hilo, que se ejecuta en la CPU izquierda, copia el objeto compartido en su caché y cambia el valor de la variable
countpor 2. Este cambio es invisible para otros subprocesos que se ejecutan en la CPU correcta porque la actualización para aún countno se ha vaciado de nuevo a la memoria principal.

Para resolver este problema, puede usar
volatileal declarar una variable. Puede garantizar que una variable determinada se lea directamente desde la memoria principal y siempre se vuelva a escribir en la memoria principal cuando se actualice.
Condición de carrera
Si dos o más subprocesos comparten el mismo objeto y más de un subproceso actualiza las variables en ese objeto compartido, puede ocurrir una condición de anticipación .
Imagine que el hilo A está leyendo una variable de
countobjeto compartido en la memoria caché de su procesador. Imagine también que el subproceso B está haciendo lo mismo, pero en la memoria caché de un procesador diferente. Ahora el hilo A agrega 1 al valor de la variable count, y el hilo B hace lo mismo. Ahora se ha var1aumentado dos veces, por separado, +1 en la caché de cada procesador.
Si estos incrementos se realizaran secuencialmente, la variable
countse duplicaría y se volvería a escribir en la memoria principal + 2.
Sin embargo, los dos incrementos se realizaron simultáneamente sin una sincronización adecuada. Independientemente de qué hilo (A o B) escriba su versión actualizada
counten la memoria principal, el nuevo valor solo será 1 más que el valor original, a pesar de dos incrementos.
Este diagrama ilustra la aparición del problema de condición de carrera descrito anteriormente:

Para resolver este problema, puede utilizar un bloque Java sincronizado... Un bloque sincronizado asegura que solo un subproceso pueda ingresar a una determinada sección crítica de código en un momento dado. Los bloques sincronizados también garantizan que todas las variables a las que se accede dentro de un bloque sincronizado se lean desde la memoria principal, y cuando un subproceso sale de un bloque sincronizado, todas las variables actualizadas se volcarán a la memoria principal, independientemente de si la variable se declara como
volatileo no. ...