Las cascadas son impresionantes por su propia naturaleza, por lo que no sorprende que los ingenieros estén un poco obsesionados con ellas. El viejo estándar DOD-STD-2167A recomendó usar el modelo en cascada, y mi experiencia en ingeniería heredada se basó en el modelo Phase-Gate , que en mi opinión es bastante similar al modelo en cascada. Por otro lado, aquellos de nosotros que estudiamos informática en la universidad probablemente sabemos que el modelo de cascada es de alguna manera un antipatrón . Nuestros amigos en la torre de marfil académica nos dicen que no, no, AgileEs el camino hacia el éxito y parece que la industria ha demostrado que esa afirmación es cierta.
Entonces, ¿qué debería elegir un desarrollador entre el modelo de cascada antiguo y el nuevo Agile? ¿Cambia la ecuación cuando se trata de desarrollar algoritmos? ¿O algún software crítico de seguridad?
Como es habitual en la vida, la respuesta se encuentra en algún punto intermedio.
Híbrido, espiral y patrón en V
El desarrollo híbrido es la respuesta que se encuentra en el medio. Cuando el modelo en cascada no permite regresar y cambiar los requisitos, el modelo híbrido sí. Y donde Agile tiene problemas con el diseño inicial, el desarrollo híbrido deja espacio para ello. Además, el desarrollo híbrido tiene como objetivo reducir la cantidad de defectos en el producto final, que es lo que probablemente queremos al diseñar algoritmos para aplicaciones críticas para la seguridad.
Suena bien, pero ¿qué tan efectivo es?
Para responder a esta pregunta, apostamos por el desarrollo híbrido mientras trabajamos en el algoritmo de localización de END.... La localización es una parte esencial de cualquier pila autónoma que va más allá del control reactivo puro. Si no me cree o no está familiarizado con la localización, le recomiendo que eche un vistazo a algunos de los documentos de diseño que se han desarrollado a través de este proceso.
Entonces, ¿qué es el desarrollo híbrido en pocas palabras? Desde mi punto de vista aficionado, diría que este es un modelo idealizado en forma de V o espiral . Planifica, diseña, implementa y prueba, y luego repite todo el proceso en función de las lecciones aprendidas y los nuevos conocimientos que ha adquirido durante ese tiempo.
Uso práctico
Más específicamente, nosotros, con el grupo de trabajo NDT en Autoware, hemos completado nuestro primer descenso por la cascada izquierda del modelo V (es decir, hicimos la primera iteración a través de la fase de diseño) en preparación para el Autoware Hackathon en Londres (dirigido por Parkopedia ). Nuestro primer paso en la fase de diseño consistió en los siguientes pasos:
- Revisión de literatura
- Resumen de implementaciones existentes
- Diseño de componentes de alto nivel, casos de uso y requisitos.
- Análisis de fallas
- Definición de métricas
- Arquitectura y diseño de API
Puede echar un vistazo a cada uno de los documentos resultantes si está interesado en algo similar, pero durante el resto de esta publicación intentaré desglosar algunos de ellos y también explicar qué y por qué surgió en cada una de estas etapas.
Revisión de literatura e implementaciones existentes
El primer paso en cualquier esfuerzo decente (que es cómo clasificaría una implementación de END) es ver lo que otras personas han hecho. Los seres humanos son, después de todo, seres sociales, y todos nuestros logros están sobre los hombros de los gigantes.
Dejando de lado las alusiones, hay dos áreas importantes a considerar al considerar el "arte del pasado": literatura académica y realizaciones funcionales.
Siempre es útil ver en qué estaban trabajando los estudiantes graduados pobres en medio de la hambruna. En el mejor de los casos, encontrará que existe un algoritmo perfectamente excelente que puede implementar en lugar del suyo. En el peor de los casos, obtendrá una comprensión del espacio y la variación de las soluciones (que pueden ayudar a la arquitectura de la información), y también podrá aprender sobre algunos de los fundamentos teóricos del algoritmo (y, por lo tanto, qué invariantes debe tener en cuenta ).
Por otro lado, es igual de útil observar lo que otras personas están haciendo; después de todo, siempre es más fácil comenzar a hacer algo con un mensaje de inicio. No solo puede tomar prestadas buenas ideas arquitectónicas de forma gratuita, sino que también puede descubrir algunas de las suposiciones y trucos sucios que puede necesitar para que el algoritmo funcione en la práctica (e incluso puede integrarlos completamente en su arquitectura).
De nuestra revisión de la literatura sobre END , hemos reunido la siguiente información útil:
- La familia de algoritmos NDT tiene varias variaciones:
- P2D
- D2D
- Limitada
- Semántica - Hay toneladas de trucos sucios que se pueden usar para hacer que el algoritmo funcione mejor.
- NDT generalmente se compara con ICP
- NDT es un poco más rápido y un poco más confiable.
- NDT funciona de manera confiable (tiene una alta tasa de éxito) dentro de un área definida
Nada increíble, pero esta información se puede guardar para su uso posterior, tanto en diseño como en implementación.
Del mismo modo, desde nuestra visión general de las implementaciones existentes, vimos no solo pasos concretos sino también algunas estrategias de inicialización interesantes.
Casos de uso, requisitos y mecanismos.
Una parte integral de cualquier proceso de desarrollo de diseño o plan primero es abordar el problema que está tratando de resolver a un alto nivel. En un sentido amplio, desde el punto de vista de la seguridad funcional (que, confieso, estoy lejos de ser un experto), la "visión de alto nivel del problema" se organiza aproximadamente de la siguiente manera:
- ¿Qué casos de uso estás tratando de resolver?
- ¿Cuáles son los requisitos (o limitaciones) para que una solución satisfaga los casos de uso anteriores?
- ¿Qué mecanismos cumplen los requisitos anteriores?
El proceso descrito anteriormente proporciona una visión disciplinada de alto nivel del problema y gradualmente se vuelve más detallado.
Para tener una idea de cómo se vería esto, puede echar un vistazo al documento de proyecto de localización de alto nivel que preparamos para el desarrollo del END. Si no estás de humor para leer antes de acostarte, sigue leyendo.
Casos de uso
Me gustan tres enfoques de pensamiento para usar casos (atención, no soy un experto en seguridad funcional):
- ¿Qué se supone que debe hacer el componente? (¡recuerda SOTIF !)
- ¿Cuáles son las formas en que puedo ingresar información en un componente? (ingrese casos de uso, me gusta llamarlos en sentido ascendente)
- ¿Cuáles son las formas en que puedo obtener la salida? (casos de uso de fin de semana o de arriba hacia abajo)
- Pregunta adicional: ¿En qué arquitecturas de sistema completo puede residir este componente?
Al poner todo junto, se nos ocurrió lo siguiente:
- La mayoría de los algoritmos pueden usar la localización, pero en última instancia se pueden dividir en sabores que funcionan tanto a nivel local como global.
- Los algoritmos locales necesitan continuidad en su historial de transformación.
- Casi cualquier sensor se puede utilizar como fuente de datos de localización.
- Necesitamos una forma de inicializar y solucionar problemas de nuestros métodos de localización.
Además de los diversos casos de uso en los que puede pensar, también me gusta pensar en algunos casos de uso comunes que son muy estrictos. Para hacer esto, tengo la opción (o tarea) de un viaje fuera de carretera completamente no tripulado, pasando por varios túneles con tráfico en una caravana. Hay un par de molestias con este caso de uso, como la acumulación de errores de odometría, errores de coma flotante, correcciones de localización e interrupciones.
Requisitos
El propósito de desarrollar casos de uso, además de generalizar cualquier problema que esté tratando de resolver, es definir requisitos. Para que un caso de uso tenga lugar (o se satisfaga), probablemente hay algunos factores que deben tenerse en cuenta o ser posibles. En otras palabras, cada caso de uso tiene un conjunto específico de requisitos.
Al final, los requisitos generales para un sistema de localización no dan tanto miedo:
- Proporcionar transformaciones para algoritmos locales.
- Proporcionar transformaciones para algoritmos globales.
- Proporcionar el mecanismo para la inicialización de algoritmos de localización relativa.
- Asegúrese de que las conversiones no se desborden
- Garantizar el cumplimiento de REP105
Es probable que especialistas calificados en seguridad funcional formulen muchos más requisitos. El valor de este trabajo radica en el hecho de que formulamos claramente ciertos requisitos (o restricciones) para nuestro diseño, que, al igual que los mecanismos, satisfarán nuestros requisitos para el funcionamiento del algoritmo.
Los mecanismos
El resultado final de cualquier tipo de análisis debe ser un conjunto práctico de lecciones o materiales. Si como resultado del análisis no podemos usar el resultado (¡incluso uno negativo!), Entonces el análisis se desperdició.
En el caso de un documento de ingeniería de alto nivel, estamos hablando de un conjunto de mecanismos o una construcción que encapsula esos mecanismos que pueden adaptarse adecuadamente a nuestros casos de uso.
Este diseño específico de localización de alto nivel permitió el conjunto de componentes de software, interfaces y comportamientos que componen la arquitectura del sistema de localización. A continuación se muestra un diagrama de bloques simple de la arquitectura propuesta.
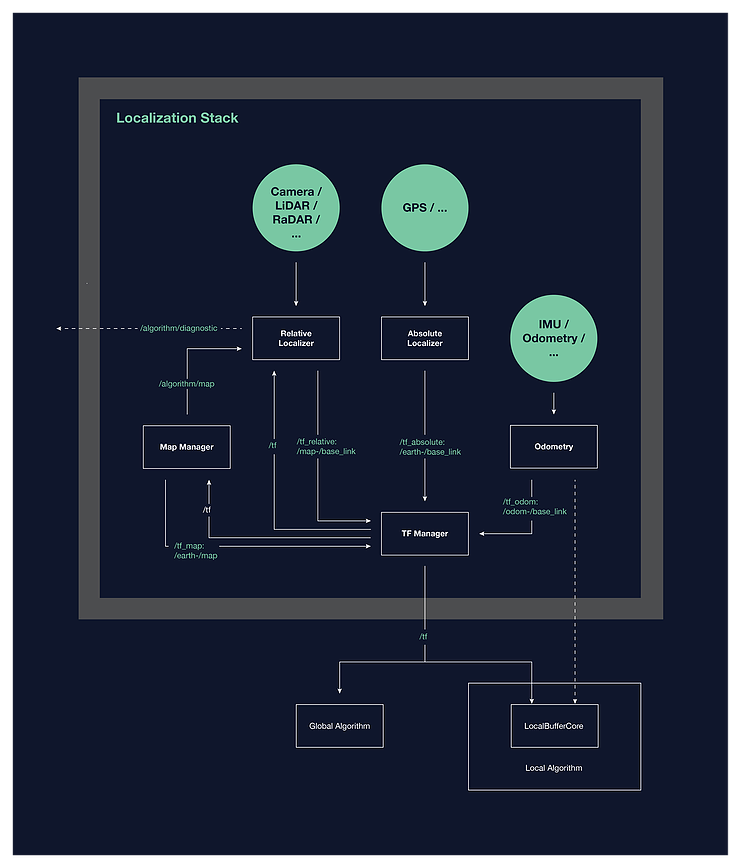
Si está interesado en obtener más información sobre arquitectura o diseño, le recomiendo que leaEl texto completo del documento .
Análisis de fallas
Debido a que estamos creando componentes en sistemas críticos para la seguridad, las fallas son algo que debemos tratar de evitar, o al menos mitigar. Por lo tanto, antes de que intentemos diseñar o construir algo, al menos deberíamos ser conscientes de cómo se pueden romper las cosas.
Al analizar fallas, como en la mayoría de los casos, es útil mirar un componente desde múltiples ángulos. Para analizar las fallas del algoritmo NDT, lo consideramos de dos maneras diferentes: como un mecanismo de localización general (relativo), y específicamente como una instancia del algoritmo NDT.
Cuando se ve desde el punto de vista del mecanismo de localización, el modo de falla principal se formula de la siguiente manera: "¿qué hacer si la entrada es información incorrecta?" De hecho, desde el punto de vista de un componente individual, poco se puede hacer excepto realizar una verificación básica de la adecuación del sistema. En el nivel del sistema, tiene opciones adicionales (por ejemplo, habilitar funciones de seguridad).
Considerando NDT como un algoritmo aislado, es útil abstraer del algoritmo resaltando el número apropiado de aspectos. Será útil prestar atención a la versión de pseudocódigo del algoritmo (esto le ayudará a usted, el desarrollador, a comprender mejor el algoritmo). En este caso, analizamos el algoritmo en detalle y estudiamos todas las situaciones en las que puede romperse.
Un error de implementación es una falla perfectamente razonable, aunque se puede solucionar con las pruebas adecuadas. Algunos matices con respecto a los algoritmos numéricos comenzaron a aparecer un poco más a menudo y de manera más insidiosa. En particular, estamos hablando de encontrar matrices inversas o, de manera más general, resolver sistemas de ecuaciones lineales, que pueden conducir a errores numéricos. Este es un escenario de falla muy sensible y debe abordarse.
Otros dos fallos importantes que también identificamos son verificar que ciertas expresiones no tienen una magnitud ilimitada (control de precisión de coma flotante) y verificar que la magnitud o el tamaño de las entradas se controlan constantemente.
En total, hemos desarrollado 15 recomendaciones.... Le recomendaría que se familiarice con ellos.
También agregaré que aunque no utilizamos este método, el análisis del árbol de fallas es una excelente herramienta para estructurar y cuantificar el problema del análisis de fallas.
Definición de métricas
"Lo que se mide es manejable"Desafortunadamente, en el desarrollo profesional, no es suficiente encogerse de hombros y decir "hecho" cuando estás cansado de trabajar en algo. Básicamente, cualquier paquete de trabajo (que nuevamente es un desarrollo de END) requiere criterios de aceptación, que deben ser acordados tanto por el cliente como por el proveedor (si usted es tanto el cliente como el vendedor, omita este paso). Toda la jurisprudencia existe para respaldar estos aspectos, pero como ingenieros podemos simplemente eliminar a los intermediarios creando métricas para determinar la disponibilidad de nuestros componentes. Después de todo, los números son (en su mayoría) inequívocos e irrefutables.
- Frase popular de gerentes
Incluso si los criterios de aceptación son innecesarios o irrelevantes, es bueno tener un conjunto bien definido de métricas que caractericen y mejoren la calidad y el rendimiento de un proyecto. Al final, lo que se está midiendo es controlable.
Para nuestra implementación de END, dividimos las métricas en cuatro grandes grupos:
- Métricas generales de calidad del software
- Métricas comunes de calidad de firmware
- Métrica general del algoritmo.
- Métricas específicas de localización
No entraré en detalles porque todas estas métricas son relativamente estándar. Lo importante es que las métricas se han definido e identificado para nuestro problema específico, que es aproximadamente lo que podemos lograr como desarrolladores de un proyecto de código abierto. En última instancia, la barra de aceptación debe determinarse en función de los detalles del proyecto por parte de quienes implementan el sistema.
Lo último que repetiré aquí es que si bien las métricas son fantásticas para probar, no son un sustituto para verificar la comprensión de la implementación y los requisitos de uso.
Arquitectura y API
Después de definir minuciosamente el problema que estamos tratando de resolver y comprender el espacio de la solución, finalmente podemos sumergirnos en el área que limita con la implementación.
He sido fanático del desarrollo basado en pruebas últimamente . Como la mayoría de los ingenieros, me encanta el proceso de desarrollo, y la idea de escribir pruebas me pareció engorrosa en primer lugar. Cuando comencé a programar profesionalmente, seguí adelante e hice pruebas después del desarrollo (a pesar de que mis profesores universitarios me dijeron que hiciera lo contrario). Investigacióndemuestre que escribir pruebas antes de la implementación tiende a generar menos errores, una mayor cobertura de pruebas y, en general, un mejor código. Quizás lo más importante, creo que el desarrollo basado en pruebas ayuda a abordar el gran problema de la implementación de algoritmos.
Cómo se ve?
En lugar de introducir un ticket monolítico llamado "Implementar NDT" (incluidas las pruebas), que dará como resultado varios miles de líneas de código (que no se pueden ver y estudiar de manera efectiva), puede dividir el problema en fragmentos más significativos:
- Escribir clases y métodos públicos para un algoritmo (crear una arquitectura)
- Escriba pruebas para el algoritmo utilizando la API pública (¡deberían fallar!).
- Implemente la lógica del algoritmo.
Entonces, el primer paso es escribir la arquitectura y la API para el algoritmo. Cubriré los otros pasos en otra publicación.
Si bien hay muchos trabajos que hablan sobre cómo "crear arquitectura", me parece que diseñar arquitectura de software tiene algo que ver con la magia negra. Personalmente, me gusta pensar en pensar en la arquitectura de software como establecer límites entre los conceptos y tratar de caracterizar los grados de libertad para plantear un problema y cómo resolverlo en términos de conceptos.
¿Cuáles son, entonces, los grados de libertad en END?
Una revisión de la literatura nos dice que hay diferentes formas de presentar exploraciones y observaciones (por ejemplo, P2D-NDT y D2D-NDT). Del mismo modo, nuestro trabajo de ingeniería de alto nivel dice que tenemos varias formas de representar el mapa (estático y dinámico), por lo que también es un grado de libertad. La literatura más reciente también sugiere que el problema de optimización puede revisarse. Sin embargo, al comparar la implementación práctica y la literatura, vemos que incluso los detalles de la solución de optimización pueden diferir.
Y la lista sigue y sigue ...
Con base en los resultados del diseño inicial, nos decidimos por los siguientes conceptos:
- Problemas de optimización
- Soluciones de optimización
- Vista de escaneo
- Vista del mapa
- Sistemas de generación de hipótesis iniciales.
- Algoritmo e interfaces de nodo
Con alguna subdivisión dentro de estos artículos.
La expectativa final de una arquitectura es que debe ser extensible y mantenible. Si nuestra arquitectura propuesta está a la altura de esta esperanza, solo el tiempo lo dirá.
Más lejos
Después del diseño, por supuesto, es hora de implementarlo. Trabajo oficial sobre la implementación de NDT en Autoware. Auto se llevó a cabo en el hackathon Autoware organizado por Parkopedia .
Debe reiterarse que lo que se ha presentado en este texto es solo el primer paso a través de la fase de diseño. Conocidoque ningún plan de batalla aguanta enfrentar al enemigo, y lo mismo puede decirse del diseño de software. El fallo final del modelo de cascada se realizó bajo el supuesto de que la especificación y el diseño eran perfectos. No es necesario decir que ni la especificación ni el diseño son perfectos, y a medida que avanza la implementación y las pruebas, se descubrirán fallas y se deberán realizar cambios en los diseños y documentos descritos aquí.
Y eso esta bien. Nosotros, como ingenieros, no somos nuestro trabajo ni nos identificamos con él, y todo lo que podemos intentar hacer es iterar y luchar por sistemas perfectos. Después de todo lo que se ha dicho sobre el desarrollo del END, creo que hemos dado un buen primer paso.
Suscríbase a los canales:
@TeslaHackers — Tesla-, Tesla
@AutomotiveRu — ,

: