Si bien los lenguajes como Python y R se están volviendo cada vez más populares para la ciencia de datos, C y C ++ pueden ser buenas opciones para resolver problemas de manera eficiente en Data Science. En este artículo, usaremos C99 y C ++ 11 para escribir un programa que funcione con el cuarteto Anscombe, que discutiremos a continuación.
Escribí sobre mi motivación para aprender idiomas constantemente en un artículo sobre Python y GNU Octave que vale la pena leer. Todos los programas son para la línea de comandos, no para una interfaz gráfica de usuario (GUI). Los ejemplos completos están disponibles en el repositorio polyglot_fit.
Desafío de programación
El programa que escribirás en esta serie:
- Lee datos de un archivo CSV
- Interpola datos con una línea recta (es decir, f (x) = m ⋅ x + q).
- Escribe el resultado en un archivo de imagen
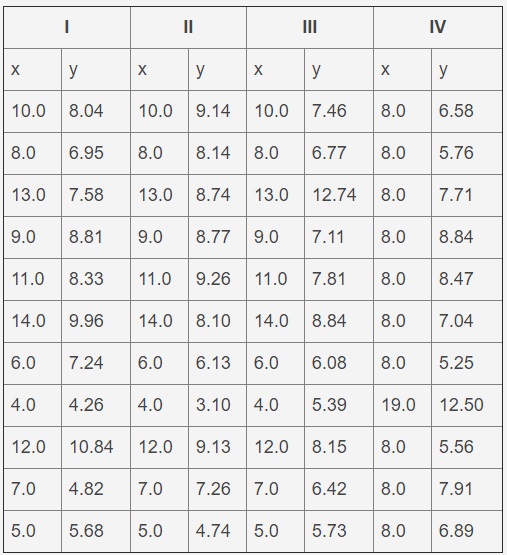
Este es un desafío común que enfrentan muchos científicos de datos. Un ejemplo de datos es el primer conjunto del cuarteto Anscombe, presentado en la tabla a continuación. Este es un conjunto de datos construidos artificialmente que da los mismos resultados cuando se ajusta a una línea recta, pero sus gráficos son muy diferentes. Un archivo de datos es un archivo de texto con pestañas para separar columnas y varias líneas que forman un encabezado. Este problema solo usará el primer conjunto (es decir, las dos primeras columnas).
Cuarteto Anscombe
Solución en C
C es un lenguaje de programación de uso general que es uno de los idiomas más populares en uso en la actualidad (según el Índice TIOBE , las Clasificaciones del lenguaje de programación RedMonk , el Índice de popularidad del lenguaje de programación y la investigación de GitHub ). Es un lenguaje antiguo (fue creado alrededor de 1973) y se han escrito muchos programas exitosos en él (por ejemplo, el kernel de Linux y Git). Este lenguaje también es lo más cercano posible al funcionamiento interno de una computadora, ya que se usa para la administración directa de la memoria. Es un lenguaje compilado , por lo que el código fuente debe traducirse en código de máquina por el compilador . Sula biblioteca estándar es pequeña y de tamaño ligero, por lo que se han desarrollado otras bibliotecas para proporcionar la funcionalidad que falta.
Este es el lenguaje que más uso para descifrar números , principalmente debido a su rendimiento. Me resulta bastante tedioso de usar, ya que requiere una gran cantidad de código repetitivo , pero está bien soportado en una variedad de entornos. El estándar C99 es una revisión reciente que agrega algunas características ingeniosas y es bien compatible con los compiladores.
Cubriré los requisitos previos necesarios para programar en C y C ++ para que tanto los principiantes como los usuarios experimentados puedan usar estos lenguajes.
Instalación
El desarrollo de C99 requiere un compilador. Usualmente uso Clang , pero GCC , otro compilador de código abierto completo , funcionará . Para ajustar los datos, decidí usar la biblioteca científica GNU . Para trazar, no pude encontrar ninguna biblioteca razonable y, por lo tanto, este programa se basa en un programa externo: Gnuplot . El ejemplo también utiliza una estructura de datos dinámica para almacenar datos, que se define en Berkeley Software Distribution (BSD ).
La instalación en Fedora es muy simple:
sudo dnf install clang gnuplot gsl gsl-develComentarios de código
En C99, los comentarios se formatean agregando // al comienzo de la línea, y el intérprete descartará el resto de la línea. Cualquier cosa entre / * y * / también se descarta.
// .
/* */Bibliotecas requeridas
Las bibliotecas constan de dos partes:
- Archivo de encabezado que contiene la descripción de las funciones
- Archivo fuente que contiene definiciones de funciones
Los archivos de encabezado se incluyen en el código fuente, y el código fuente de las bibliotecas está vinculado al ejecutable. Por lo tanto, los archivos de encabezado son necesarios para este ejemplo:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Función principal
En C, el programa debe estar dentro de una función especial llamada main () :
int main(void) {
...
}Aquí puede notar una diferencia con Python, que se discutió en el último tutorial, porque en el caso de Python, se ejecutará cualquier código que encuentre en los archivos fuente.
Definiendo Variables
En C, las variables deben declararse antes de usarse y deben asociarse con un tipo. Siempre que desee utilizar una variable, debe decidir qué datos almacenar en ella. También puede indicar si va a utilizar la variable como un valor constante, lo cual no es obligatorio, pero el compilador puede beneficiarse de esta información. Ejemplo del programa apropiado_C99.c en el repositorio:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;Las matrices en C no son dinámicas en el sentido de que su longitud debe determinarse de antemano (es decir, antes de la compilación):
int data_array[1024];Como generalmente no sabe cuántos puntos de datos hay en el archivo, use una lista vinculada individualmente . Es una estructura de datos dinámica que puede crecer indefinidamente. Afortunadamente, BSD proporciona listas enlazadas individualmente . Aquí hay una definición de ejemplo:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);Este ejemplo define una lista data_point , que consta de valores estructurados que contienen valores x e y . La sintaxis es bastante compleja, pero intuitiva, y una descripción detallada sería demasiado detallada.
Imprimir
Para imprimir en el terminal, puede usar la función printf () , que funciona como la función printf () en Octave (descrita en el primer artículo):
printf("#### C99 ####\n");La función printf () no agrega automáticamente una nueva línea al final de la línea impresa, por lo que debe agregarla usted mismo. El primer argumento es una cadena, que puede contener información sobre el formato de otros argumentos que se pueden pasar a la función, por ejemplo:
printf("Slope: %f\n", slope);Lectura de datos
Ahora viene la parte difícil ... Hay varias bibliotecas para analizar archivos CSV en C, pero ninguna es lo suficientemente estable o popular como para estar en el repositorio de paquetes de Fedora. En lugar de agregar una dependencia para este tutorial, decidí escribir esta parte yo mismo. Nuevamente, sería demasiado prolijo entrar en detalles, por lo que solo explicaré la idea general. Algunas líneas en el código fuente serán ignoradas por brevedad, pero puede encontrar un ejemplo completo en el repositorio.
Primero abra el archivo de entrada:
FILE* input_file = fopen(input_file_name, "r");Luego lea el archivo línea por línea hasta que ocurra un error o hasta que el archivo termine:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}La función getline () es una buena adición reciente al estándar POSIX.1-2008 . Puede leer una línea completa en un archivo y ocuparse de asignar la memoria necesaria. Cada línea se divide en tokens usando la función strtok () . Mirando el token, seleccione las columnas que necesita:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Finalmente, con los valores xey seleccionados, agregue un nuevo punto a la lista:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);La función malloc () asigna (reserva) dinámicamente cierta cantidad de memoria permanente para un nuevo punto.
Datos de ajuste
La función de interpolación lineal de GSL gsl_fit_linear () acepta matrices regulares como entrada. Por lo tanto, dado que no puede conocer el tamaño de las matrices creadas de antemano, debe asignarles memoria manualmente:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Luego, revise la lista para almacenar los datos relevantes en las matrices:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Ahora que ha terminado con la lista, limpie el pedido. Siempre libere memoria asignada manualmente para evitar pérdidas de memoria . Las pérdidas de memoria son malas, malas y nuevamente malas. Cada vez que no se libera el recuerdo, el gnomo del jardín pierde la cabeza:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Finalmente, finalmente (!), Puede ajustar sus datos:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Trazar un gráfico
Para construir un gráfico, debe usar un programa externo. Así que mantenga la función de ajuste en un archivo externo:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}El comando de trazado Gnuplot se ve así:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'resultados
Antes de ejecutar el programa, debe compilarlo:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Este comando le dice al compilador que use el estándar C99, lea el archivo apropiado_C99.c, cargue las bibliotecas gsl y gslcblas y guarde el resultado en ajuste_C99. El resultado resultante en la línea de comando:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421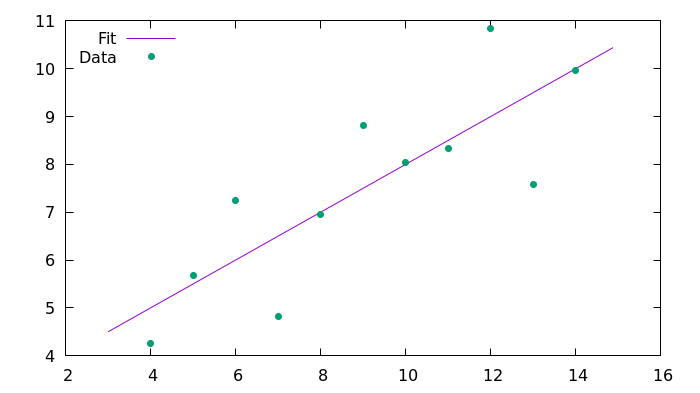
Aquí está la imagen resultante generada usando Gnuplot.
Solución C ++ 11
C ++ es un lenguaje de programación de propósito general que también es uno de los lenguajes más populares en uso hoy en día. Fue creado como el sucesor del lenguaje C (en 1983) con énfasis en la programación orientada a objetos (OOP). C ++ generalmente se considera un superconjunto de C, por lo que un programa en C debe compilarse con un compilador de C ++. Este no es siempre el caso, ya que hay algunos casos extremos donde se comportan de manera diferente. En mi experiencia, C ++ requiere menos código repetitivo que C, pero su sintaxis es más compleja si desea diseñar objetos. El estándar C ++ 11 es una revisión reciente que agrega algunas características ingeniosas que son más o menos compatibles con los compiladores.
Como C ++ es bastante compatible con C, me centraré en las diferencias entre los dos. Si no describo una sección en esta parte, significa que es lo mismo que en C.
Instalación
Las dependencias para C ++ son las mismas que, por ejemplo, C. En Fedora, ejecute el siguiente comando:
sudo dnf install clang gnuplot gsl gsl-develBibliotecas requeridas
Las bibliotecas funcionan igual que en C, pero las directivas de inclusión son ligeramente diferentes:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Dado que las bibliotecas GSL están escritas en C, el compilador debe estar informado sobre esta característica.
Definiendo Variables
C ++ admite más tipos de datos (clases) que C, por ejemplo, el tipo de cadena, que tiene muchas más características que su contraparte en C. Actualice sus definiciones de variables en consecuencia:
const std::string input_file_name("anscombe.csv");Para objetos estructurados como cadenas, puede definir una variable sin usar el signo = .
Imprimir
Puede usar la función printf () , pero es más común usar cout . Use el operador << para especificar la cadena (u objetos) que desea imprimir con cout :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Lectura de datos
El circuito es el mismo que antes. El archivo se abre y se lee línea por línea, pero con una sintaxis diferente:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}Los tokens de cadena se recuperan con la misma función que en el ejemplo C99. Use dos vectores en lugar de matrices C estándar . Los vectores son una extensión de las matrices de C en la biblioteca estándar de C ++ para administrar dinámicamente la memoria sin llamar a malloc () :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);Datos de ajuste
Para ajustar los datos en C ++, no tiene que preocuparse por las listas, ya que se garantiza que los vectores tengan memoria secuencial. Puede pasar directamente punteros a buffers vectoriales a las funciones de ajuste:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Trazar un gráfico
El trazado se realiza de la misma manera que antes. Escribe en el archivo:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();Luego usa Gnuplot para trazar el gráfico.
resultados
Antes de ejecutar el programa, debe compilarse con un comando similar:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Resultado resultante en la línea de comando:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421Y aquí está la imagen resultante, generada con Gnuplot.
Conclusión
Este artículo proporciona ejemplos de ajuste y trazado de datos en C99 y C ++ 11. Como C ++ es ampliamente compatible con C, este artículo usa las similitudes para escribir un segundo ejemplo. En algunos aspectos, C ++ es más fácil de usar, ya que alivia parcialmente la carga de la administración de memoria explícita, pero su sintaxis es más compleja, ya que introduce la capacidad de escribir clases para OOP. Sin embargo, también puede escribir en C usando técnicas OOP, ya que OOP es un estilo de programación, puede usarse en cualquier lenguaje. Hay algunos buenos ejemplos de OOP en C, como las bibliotecas GObject y Jansson .
Prefiero usar C99 para trabajar con números debido a su sintaxis más simple y soporte más amplio. Hasta hace poco, C ++ 11 no era ampliamente compatible y traté de evitar los bordes ásperos en versiones anteriores. Para un software más complejo, C ++ podría ser una buena opción.
¿Estás usando C o C ++ para Data Science? Comparte tu experiencia en los comentarios.

Aprenda los detalles de cómo obtener una profesión solicitada desde cero o subir de nivel en habilidades y salario completando los cursos en línea pagos de SkillFactory:
- Curso de aprendizaje automático (12 semanas)
- Aprendizaje de ciencia de datos desde cero (12 meses)
- Profesión analítica con cualquier nivel inicial (9 meses)
- Curso de Python para desarrollo web (9 meses)