En mi charla, recordé la evolución de Python en la empresa: desde los primeros servicios empaquetados en paquetes deb y desplegados en metal desnudo, hasta un complejo mono-repositorio con su propio sistema de compilación y nube. Más en la historia serán Django, Flask, Tornado, Docker, PyCharm, IPv6 y otras cosas que hemos encontrado a lo largo de los años.
- Déjame hablarte sobre mi. Vine a Yandex en 2008. Al principio hice servicios de contenido, en particular Yandex.Afisha. Escribí allí en Python, reescribimos el servicio con Perl y otras tecnologías divertidas.
Luego me cambié a los servicios internos. El departamento de servicios internos se transformó gradualmente en la gestión de interfaces de búsqueda y servicios para organizaciones. Ha pasado mucho tiempo, desde un desarrollador simple que he crecido hasta el jefe del desarrollo de Python de nuestra división, unas 30 personas.
Un punto importante: la compañía es muy grande y no puedo hablar por todos los Yandex. Me comunico, por supuesto, con colegas de otros departamentos, sé cómo viven. Pero básicamente solo puedo hablar sobre nuestro departamento, sobre nuestros productos. Mi charla se centrará en esto. A veces te diré que en otro lugar de Yandex hacen esto y aquello. Pero eso no sucederá a menudo.
Python se usa mucho en la empresa: cualquier tecnología, cualquier pila de tecnología, cualquier idioma. Todo lo que viene a la mente está en algún lugar de la empresa, ya sea como experimento u otra cosa. Y en cualquier servicio Yandex definitivamente habrá Python en un componente u otro.
Todo lo que te diré es mi interpretación de los acontecimientos. No pretendo ser absolutamente objetivo. Todo esto también pasó por mis manos, estaba coloreado emocionalmente. Toda mi experiencia es tan personal.

¿Cómo se estructurará el informe? Para facilitarle la percepción de la información, y para que yo la diga, decidí romper toda la evolución desde 2007 hasta el momento actual en varias épocas. El informe estará estrictamente estructurado por estas eras. La era significa algún tipo de cambio radical en la infraestructura o el enfoque del desarrollo. Si nuestra infraestructura de hierro cambia y al mismo tiempo cambiamos la forma en que desarrollamos los servicios, qué herramientas usamos, esta es una era. Está claro que tuve que ajustar un poco. Está claro que todo no sucedió sincrónicamente, y hubo diferencias entre estos cambios, pero intenté encajar todo en una línea de tiempo, solo para hacerlo más compacto.
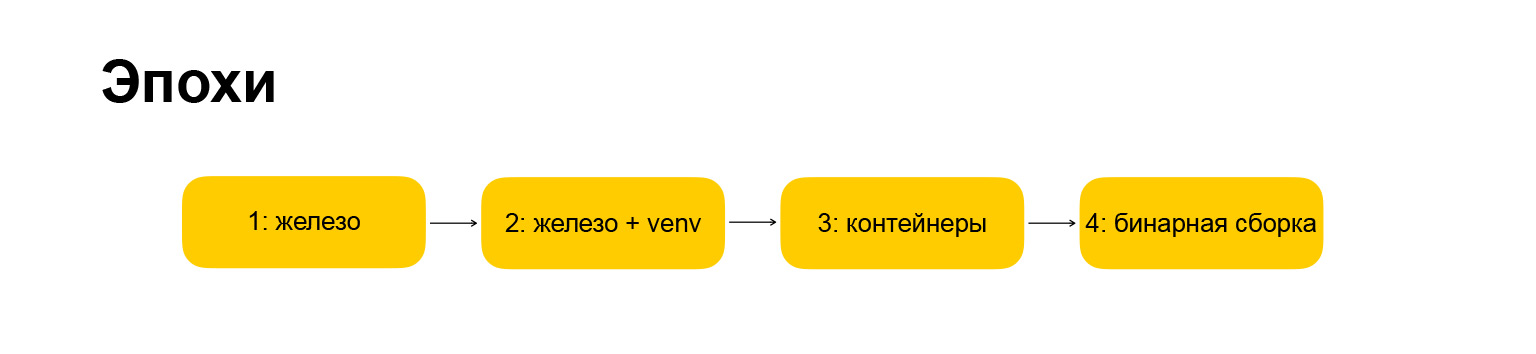
¿Qué época tuvimos? Aquí, también, todo es copyright, todos los nombres son míos. La primera era se llama "hardware", esto es con lo que comenzamos cuando vine a la compañía. Porque todo ha cambiado un poco. La era se convirtió en "hierro + venv". Además, revelaré lo que se esconde detrás de estos nombres. Primero, quiero darle una guía sobre lo que le diré.
La próxima era es "contenedores", todo está más o menos claro aquí. La era en la que nos estamos moviendo en este momento es el "ensamblaje binario", también les contaré al respecto.

¿Cómo se estructurará cada era? Esto también es importante, porque quería hacer una narración rítmica, para que cada sección estuviera estrictamente estructurada y fuera más fácil de entender. La era se describe por la infraestructura, los marcos que utilizamos, la forma en que trabajamos con las dependencias, cuál es nuestro entorno de desarrollo y las ventajas o desventajas de este o aquel enfoque.
(Pausa técnica). Les conté la introducción, les dije cómo se estructurará el informe, pasemos a la historia misma.
Edad 1: hierro
El primer servicio que comencé a hacer cuando me uní a la compañía se llamó "Where Everybody Goes". Era el satélite de Afisha, el primer gran servicio de Django.
Grisha Bakunovbobukpuedo decir por qué una vez decidió transferir Django a Yandex; en general, sucedió. Comenzamos a hacer servicios en Django.
Vine, y me dijeron: hagamos donde va todo el mundo. Entonces ya había algún tipo de base. Me conecté y lo consideramos una especie de experimento: funcionará o no. El experimento resultó ser exitoso. Todos estuvieron de acuerdo en que es posible crear servicios web en Yandex en Python y Django. ¡Multa! Nuestra infraestructura está lista para esto, la gente está lista, el mundo también está listo. Vamos, distribuyamos aún más Python y Django en toda la empresa. Empezamos a hacerlo Reescribió Yandex.Afisha, Weather. Entonces, el programa de televisión. Luego todo fue como en una niebla, comenzaron a reescribir todo.
En ese momento, la infraestructura de Yandex parecía que todo el backend estaba escrito principalmente en los profesionales. Obviamente, el movimiento hacia Python ha acelerado mucho el desarrollo en muchos lugares, y esto ha sido bien recibido por la compañía y la gerencia. Hablemos ahora de la infraestructura: dónde funcionaban estos servicios, en qué estaban girando y todo eso.

Estos eran autos de hierro, de ahí el nombre de esta era. ¿Qué son las máquinas de hierro? Son solo servidores en el centro de datos. Hay muchos servidores, todos se combinan en un grupo de, digamos, 15 máquinas. Luego fueron 30, luego 50, 100. Y todo esto en Debian o Ubuntu. Para entonces, habíamos migrado de Debian a Ubuntu. Lanzamos todas las aplicaciones a través de un proceso de inicio estándar. Todo era estándar, como lo hicieron en ese momento. Para que nuestras aplicaciones se comuniquen en el servidor web, utilizamos el protocolo FastCGI y la biblioteca flup. Si ha estado trabajando con Python durante mucho tiempo, probablemente haya oído hablar de ello. Pero ahora, estoy seguro de que no lo usas, porque está moralmente desactualizado y era algo muy extraño, funcionó muy lentamente.
En ese momento, obviamente, no había un tercer Python, escribimos en Python 2.3. Luego migraron a 2.4. Tiempos salvajes. Ni siquiera quiero pensar en ellos, porque el idioma, las comunidades y el ecosistema se veían completamente diferentes, aunque también era genial, y muchos se sintieron atraídos por esto. Personalmente, me sumergió en el mundo de Python: incluso a pesar de las peculiaridades y rarezas, estaba claro que Python es una tecnología prometedora, puede invertir su tiempo allí.
Un punto importante: entonces todavía no usamos nginx, ya no usamos Apache, sino un servidor web llamado Lighttpd. Si ha estado prestando servicios web durante mucho tiempo, probablemente también haya oído hablar de él. En un momento fue muy popular.

De los marcos, en realidad utilizamos Django. Comenzamos a hacer grandes servicios en Django. En algún lugar de la compañía estaba CherryPy, en algún lugar: Web.py. Es posible que haya escuchado sobre estos marcos también. Ahora que no están en los primeros roles, los marcos más jóvenes y audaces los han dejado de lado. Luego tuvieron su propio nicho, pero al final tarde o temprano se extinguieron, dejamos de hacerles nada. Comenzaron a hacer todo en Django.
En este punto, Python se extendió tanto en la compañía que estalló en nuestro departamento: los servicios web en Python y Django comenzaron a hacerse en todas partes de la compañía.

Pasemos a trabajar con dependencias. Y aquí hay algo que probablemente también haya encontrado si viniera a trabajar para una gran empresa: la corporación ya tiene una infraestructura establecida, debe adaptarse a ella. Yandex tenía una infraestructura de deb, repositorios internos de paquetes de deb. Se creía que el desarrollador de Yandex sabía cómo compilar este paquete de deb. Nos vimos obligados a integrarnos en este flujo, reunimos nuestros proyectos en forma de paquetes deb completos y luego, como paquete deb, pusimos todo esto en los servidores de los que hablaba, y luego los pusimos en grupos en forma de paquetes deb.
Como resultado, todas las dependencias y bibliotecas, el mismo Django, también tuvimos que empacar en paquetes deb. Para esto, creamos nuestra propia infraestructura, creamos un repositorio interno y aprendimos cómo hacerlo. Esta no es una actividad muy original: si intentaste construir un RPM o un paquete deb, entonces lo sabes. RPM es un poco más simple, deb es más complicado. Pero de todos modos, no podrá venir de la calle y comenzar a hacer clic. Necesitas cavar un poco.
Durante muchos años después de eso, recolectamos paquetes deb. Y me parece que no todos los que hicieron esto por trabajo necesitaban entender lo que estaba sucediendo bajo el capó. Simplemente tomaron el uno del otro, copiaron espacios en blanco, plantillas, pero no cavaron profundamente. Pero aquellos que desenterraron lo que estaba sucediendo en el interior se volvieron muy útiles y exigieron colegas: si de repente algo no sucedía, todos acudían a ellos en busca de consejo y les pedían matices y ayuda para la depuración. Fue un momento divertido, porque estaba interesado en descubrir lo que había dentro. Por lo tanto, ganó una popularidad barata entre sus colegas.

Además del ecosistema de dependencias, también se trabaja con código común. Ya al principio hubo un crecimiento explosivo en el número de proyectos, y se requería trabajar con un código común, crear bibliotecas comunes, etc. Comenzamos a hacer una fuente abierta interna. Hicimos la funcionalidad general de autorización, trabajando con registros, con otras cosas comunes, API internas, almacenamientos internos. Hicimos todo esto en forma de bibliotecas, lo pusimos en el repositorio interno. Inicialmente, estos eran repositorios SVN, luego el GitHub interno.
Y al final empacaron todas estas dependencias, todas estas bibliotecas también están en deb, cargadas en un único repositorio. A partir de esto, se formó un entorno de paquete de este tipo. Si comenzó un nuevo proyecto, podría colocar varias bibliotecas allí, obtener una base de funcionalidad e iniciar inmediatamente el proyecto en la infraestructura de Yandex. Fue muy comodo.

¿Cómo era nuestro servidor típico? Clásicamente Hay dependencias del sistema, hay dependencias y aplicaciones de Python. Varias cosas se derivan de esto. En primer lugar, todas las aplicaciones que se ejecutan en el mismo servidor y, por lo tanto, en el mismo clúster deben tener las mismas dependencias. Porque si instala un sistema de paquetes, siempre es una versión, no puede haber varios, debe sincronizar.
Cuando hay pocos proyectos, todavía se puede hacer de alguna manera. Cuando hay mucho, todo se vuelve muy complicado. Están hechas por diferentes equipos, es difícil para ellos estar de acuerdo. Cada equipo desea actualizar antes a alguna biblioteca o desea actualizar el marco. Y todos los demás deberían seguir esto. Con el tiempo, esto crea muchos problemas. Esto nos llevó a abandonar ese esquema, para pasar a la próxima era. Pero hablaré de eso un poco más tarde.
Hablemos del entorno de desarrollo. Pero existe una comprensión tan amplia del entorno de desarrollo. Así es como llegas al trabajo, cómo escribes el código, cómo lo depuras, cómo trabajas con él, dónde lo verificas, cómo lo ejecutas, dónde ejecutas las pruebas y todo eso.

Cuando me uní a la compañía, todos estábamos trabajando en servidores de desarrollo remotos. Es decir, tiene algún tipo de escritorio, en Windows o Linux, no importa. Usted va a un servidor remoto con el Debian correcto y el repositorio de paquetes correcto. Y corres, corres vim, Emacs, escribes código, depuras.
No es muy conveniente, pero en realidad no conocíamos otra vida. Aquellos que tienen la suerte de tener una computadora de escritorio o portátil con Linux podrían intentar hacer esto localmente. Pero tampoco había instrucciones especiales, nada. Un poco de tiempo salvaje. Las personas especiales que en ese momento vivían en Windows y en Mac y querían desarrollarse localmente crearon una máquina virtual dentro de la cual Linux. Escribieron código dentro de esta máquina virtual y lo lanzaron. Más precisamente, escribieron el código en el sistema host, ejecutaron el código dentro de la máquina virtual y de alguna manera enviaron el sistema de archivos allí para que todo estuviera sincronizado. Todo funcionó bastante mal, pero de alguna manera sobrevivió.
¿Cuáles son los pros y los contras de esta era, este enfoque para el desarrollo? De hecho, desventajas sólidas:
- Como dije, los grupos compartidos estaban abarrotados.
- Todos los proyectos en el clúster tenían que tener las mismas dependencias.
- . , , Django . , . 15-20 . . , , — . X, . , . - , - , . . , , . .
- Yandex dependía de la infraestructura de Debian. Lo apoyamos, recopilamos paquetes, admitimos el repositorio interno. Y esto, por supuesto, tampoco es muy bueno, ni muy conveniente, ni muy flexible. Dependes de cosas extrañas que no se hicieron para la empresa. Sin embargo, Debian como una solución de código abierto, como una distribución de Linux, se creó para otras tareas.
Hablemos un poco más sobre Django. ¿Por qué empezamos a usarlo? Solo pensé antes del informe, mientras estaba sentado en una silla, que resulta que hace 11 años hablé en una conferencia en Kiev con el mismo tema "¿Por qué debería usar Django?" Entonces me gustó a mí mismo. Fui un desarrollador admirado que leyó la documentación, hice mi primer proyecto, y le parece que todo, ahora esta herramienta es universal para todo y puedes, no sé, incluso clavar clavos.
Pero tomó mucho tiempo. Todavía amo a Django, todavía se usa bastante en nuestro departamento y en la empresa en general. Por ejemplo, incluso antes del otoño de 2018, Alice tenía a Django en su backend. Ahora ya no está allí, pero para comenzar rápidamente, sus colegas la eligieron. Debido a que algunas de las ventajas siguen siendo válidas: un gran ecosistema, todavía hay muchos especialistas. Hay todas las baterías necesarias.
Y hay una amplia flexibilidad. Cuando comienzas a trabajar con Django, te parece que te limita mucho, ata las manos, requiere un cierto flujo de trabajo con él. Pero si profundiza un poco más, muchas cosas se pueden deshabilitar, cambiar y configurar. Y si puede usar esto hábilmente, puede obtener todos los bollos asociados con el marco de Python más probablemente más popular. Puedes omitir todas las desventajas. También hay muchos de ellos, pero de alguna manera se detienen.
Edad 2: hierro + venv
Hemos terminado de hablar sobre esta era. A finales de 2011, pasamos a la siguiente era, "Iron + venv". Ya sabe sobre hardware, ahora necesita decir qué sucedió, de dónde viene el nombre venv. Digresión de letras: no surgió venv porque aparecieron máquinas virtuales. ¿Por qué entre comillas? Porque comenzamos a probar todo tipo de cosas como contenedores como OpenVZ o LXC. Entonces estaban muy poco desarrollados, no como ahora. No volaron muy bien con nosotros. De todos modos, vivíamos en grupos compartidos, todavía teníamos que existir junto con otros proyectos hombro con hombro en las mismas máquinas. Estábamos buscando una solución.

Por ejemplo, cambiamos de init a upstart systemd, y un poco más tarde obtuvimos flexibilidad para iniciar nuestras aplicaciones. Abandonamos FastCGI y comenzamos a usar la interfaz WSGI para comunicarnos con el servidor web o HTTP. En este punto, ya estábamos usando Python más o menos moderno, el ecosistema ya estaba muy bien desarrollado. Cambiamos a nginx como servidor web, en general todo estuvo bien.

También comenzamos a adaptar nuevos marcos para nosotros mismos. Por ejemplo, comenzaron a usar Tornado. Por supuesto, en ese momento Flask ya había aparecido, después de 2012 Flask ya estaba muy de moda, popular y Django amenazó con arrojar el pedestal de los marcos populares en Python. Y, por supuesto, comenzaron a usar el apio. Porque cuando los proyectos crecen, su número crece, se vuelven más cargados, resuelven más problemas, procesan más datos, entonces necesita un marco para la ejecución fuera de línea de tareas en un gran clúster informático. Por supuesto, comenzamos a usar Celery para esto. Pero más sobre eso más tarde.

Lo que ha cambiado dramáticamente es cómo funciona con las dependencias. Comenzamos a recopilar un entorno virtual. Alrededor de ese tiempo, la comunidad de Python llegó al punto de que es posible no poner bibliotecas de Python en el sistema, sino crear un entorno virtual, poner todas las dependencias de Python que necesita allí, y este entorno será completamente independiente. Puede haber tantos entornos virtuales de este tipo en una máquina. Esto es aislamiento, una adicción muy conveniente. Aún lo usas. Y también lo adaptamos todo. Como resultado, ¿qué hicimos? Creamos un entorno virtual y colocamos todas las dependencias de Python allí, lo empaquetamos en un paquete de deb y ya lo enrollamos al servidor.
Como resultado, todos los proyectos dejaron de interferir entre sí, dependiendo de la dependencia general en el sistema, podían elegir fácilmente qué versión del marco o biblioteca usar. Es muy conveniente. También se produjeron cambios en el código compartido. Dado que abandonamos parcialmente la infraestructura de Debian y, en particular, dejamos de instalar dependencias de depuración, necesitábamos algo donde pudiéramos descargar todo nuestro código común y bibliotecas compartidas y de dónde sacarlas.

Enlace desde la diapositiva
En ese momento, ya había varias implementaciones de PyPI, es decir, un repositorio de paquetes de Python, implementaciones escritas, en particular, en Django. Y elegimos uno de ellos. Se llama Localshop, aquí hay un enlace... Este repositorio todavía está vivo, ya hay alrededor de mil paquetes internos en él. Es decir, desde aproximadamente 2011-2012, una compañía del tamaño de Yandex generó alrededor de mil bibliotecas diferentes, utilidades escritas en Python, que se cree que se reutilizarán en otros proyectos. Puedes apreciar la escala.
Todas las bibliotecas se publican en este repositorio interno. Y a partir de ahí, se instalan en Python o hay una infraestructura automática especial que los convierte en Debian. Todo es más o menos automatizado y conveniente. Dejamos de desperdiciar tantos recursos para mantener la infraestructura de Debian. Todo más o menos funcionó por sí solo.
Y este es un paso cualitativo. Aquí hay un diagrama con lo que estaba hablando.
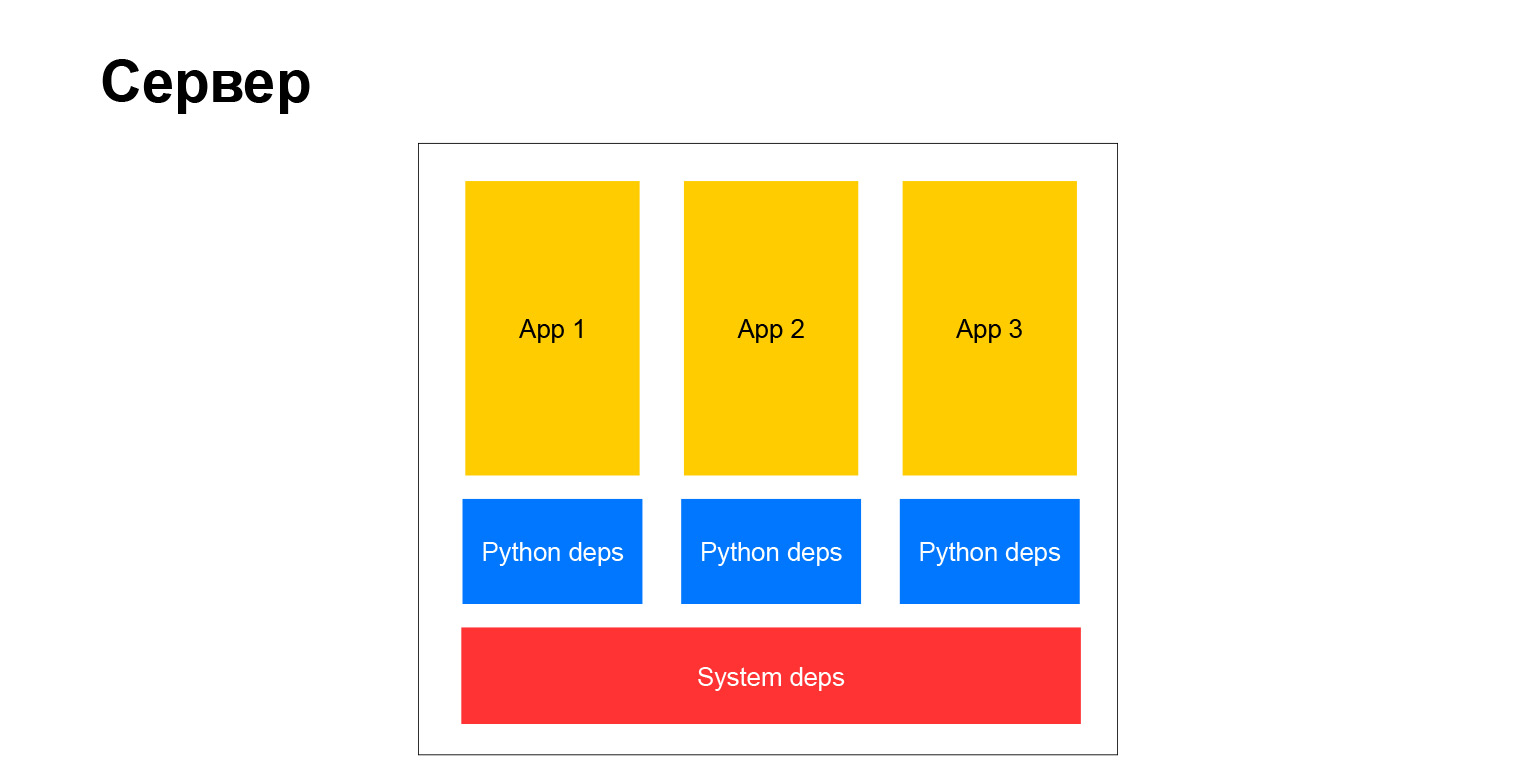
Es decir, la dependencia de las mascotas finalmente dejó de ser la misma para todos. Los del sistema aún permanecen, pero no hay muchos de ellos. Por ejemplo, un controlador de base de datos, un analizador XML requiere bibliotecas binarias del sistema. En general, en ese momento no podíamos deshacernos de estas dependencias.

El entorno de desarrollo también ha cambiado. Desde venv, el entorno virtual estuvo disponible y funcionó en todas partes en ese momento, pudimos construir nuestro proyecto en general en cualquier plataforma local. Esto hizo la vida mucho más fácil. Ya no había necesidad de meterse con Debian, no se necesitaban máquinas virtuales. Podrías tomar cualquier sistema operativo, decir virtual venv, y luego instalar algo. Y funcionó.
¿Cuáles son las ventajas de este esquema? Dado que hemos vivido durante bastante tiempo, tal vez un poco más de tres años, con esta configuración de parámetros, se ha vuelto más fácil vivir en grupos de albergues. Esto es realmente conveniente. Es decir, ya no dependemos de estas actualizaciones globales para ningún Django en toda la empresa. Podríamos seleccionar con mayor precisión las versiones que más nos convengan, actualizar las dependencias críticas con mayor frecuencia si corrigen vulnerabilidades o alguna otra cosa. Y fue una forma muy correcta, nos gustó y nos ahorró mucho de todo.
Pero también hubo desventajas. Las dependencias del sistema seguían siendo comunes. A veces disparó, a veces se interpuso. Una vez más, iré un poco más allá del alcance de nuestro departamento y hablaré sobre la compañía. Dado que la empresa es grande, no todos nos mantuvieron al día con estas épocas. En ese momento, la compañía seguía usando paquetes deb para trabajar con dependencias de python. Hablemos un poco más en detalle por qué comenzamos a usar estos u otros marcos. En particular, Tornado.

Necesitábamos un marco asincrónico, ahora tenemos tareas para ello. El tercer Python y su asincio aún no existían, o estaban en un estado inicial, no era muy confiable usarlos todavía. Por lo tanto, tratamos de elegir qué marco asincrónico deberíamos usar. Había varias opciones: Gevent y Twisted. Lo más probable es que haya más, pero elegimos entre ellos. Twisted ya se usaba en la empresa, por ejemplo, el backend Yandex.Taxi se escribió en Twisted. Pero los miramos y decidimos que Twisted no se ve pitónico, incluso PEP-8 no cumple. Y Gevent: hay algún tipo de pirateo con una pila de python dentro. Usemos Tornado.
No nos arrepentimos. Todavía usamos Tornado en algunos servicios, en aquellos que aún no hemos reescrito en el tercer Python. El marco ha demostrado a lo largo de los años que es compacto, confiable y confiable.
Y por supuesto apio. Ya he contado parcialmente sobre esto. Necesitábamos un marco para la ejecución distribuida de tareas diferidas. Lo conseguimos.

Fue muy conveniente que Celery tenga soporte para diferentes corredores. Utilizamos activamente este b para varias tareas, tratando de encontrar uno u otro corredor correcto. En algún lugar era Mongo, en algún lugar SQS, en algún lugar Redis. Pero tratamos de elegir según las necesidades, y lo logramos.
A pesar del hecho de que hay muchas quejas sobre el apio, cómo está escrito en su interior, cómo depurarlo, qué tipo de registro es, más bien funciona. El apio todavía se usa activamente en casi todos los proyectos en nuestro departamento y, hasta donde yo sé, fuera de nuestro proyecto. El apio es imprescindible. Si necesita ejecución diferida de tareas, entonces todos toman apio. O al principio no lo toman, intentan tomar otra cosa, pero luego siguen acudiendo a Apio.
Vamos a la próxima era. Ya nos estamos acercando a la actualidad, más moderna. Aquí el nombre de la era habla por sí mismo.
3 años: contenedores

Tenemos una nube compatible con Docker internamente. Por dentro, no el tiempo de ejecución de Docker, sino el desarrollo interno. Pero al mismo tiempo, las imágenes de la ventana acoplable se pueden implementar allí. Esto nos ayudó mucho porque pudimos usar todo el ecosistema de acopladores para el desarrollo y las pruebas. Podríamos usar todo tipo de cosas, y luego, simplemente habiendo recibido la imagen probada, subirla a esta nube. Comenzó allí y funcionó como debería.
En ese momento, ya éramos independientes de qué sistema operativo estaba dentro del contenedor. Puedes elegir cualquiera. Por supuesto, no usamos demonios comunes, sino, por ejemplo, un supervisor. Posteriormente, todos cambiaron a uWSGI: resultó que uWSGI no solo sabe cómo ejecutar sus aplicaciones web y proporcionar una interfaz para el servidor web en ellas. También es solo una buena cosa genérica para iniciar procesos.
Sin embargo, hay una configuración un poco extraña, pero, en general, es conveniente. Nos deshicimos de la esencia innecesaria y comenzamos a hacer todo a través de uWSGI. Lo usamos para comunicarnos con el servidor web. Las peculiaridades de nuestra nube son tales que nos comunicamos a través de HTTP con el equilibrador, que está representado globalmente en la nube, como un componente, y no puede usar el protocolo uWSGI. Pero eso está bien. Dentro del uWSGI, el servidor HTTP está bastante bien implementado, funciona de manera rápida y confiable.

¿Qué pasa con los marcos? Apareció el marco Falcon, y reescribimos la misma Alice con Django en Falcon, porque había una serie de cookies; era necesario que se ganaran rápidamente, pero no eran muy complicadas.
Django en algún momento se volvió un poco redundante, y para aumentar la velocidad y deshacernos de una dependencia tan grande, una gran biblioteca, decidimos reescribirla en Falcon.
Y por supuesto asyncio. Comenzamos a escribir nuevos servicios en el tercer Python, y los antiguos, para reescribir en el tercer Python. Solo en nuestro departamento ahora hay unos 30 servicios escritos en Python. Estos son 30 productos completos, con un backend, frontend y su propia infraestructura. Lo que procesa los datos proporciona servicios a los consumidores internos y externos.
Pero la empresa, como saben, tiene miles de servicios de Python, y son diferentes. Están en diferentes marcos, diferentes Python, más antiguos y más nuevos. Ahora la compañía usa casi todos los marcos modernos que conoces. Django, Flask, Falcon, algo más, asincrónico: Tornado, Twisted, asyncio. Todo es usado y beneficioso.
Volvamos a la estructura de la era: cómo comenzamos a trabajar con dependencias.

Todo es simple aquí. Ahora no podemos usar el entorno virtual. No necesitamos paquetes deb. Justo a la hora de construir la imagen ponemos con pip todo lo que necesitamos. Está completamente aislado. No molestamos a nadie. Y muy conveniente. Cualquier dependencia del sistema, puede elegir cualquier imagen base de Debian, Ubuntu, lo que sea. Nos gusta. Libertad total.
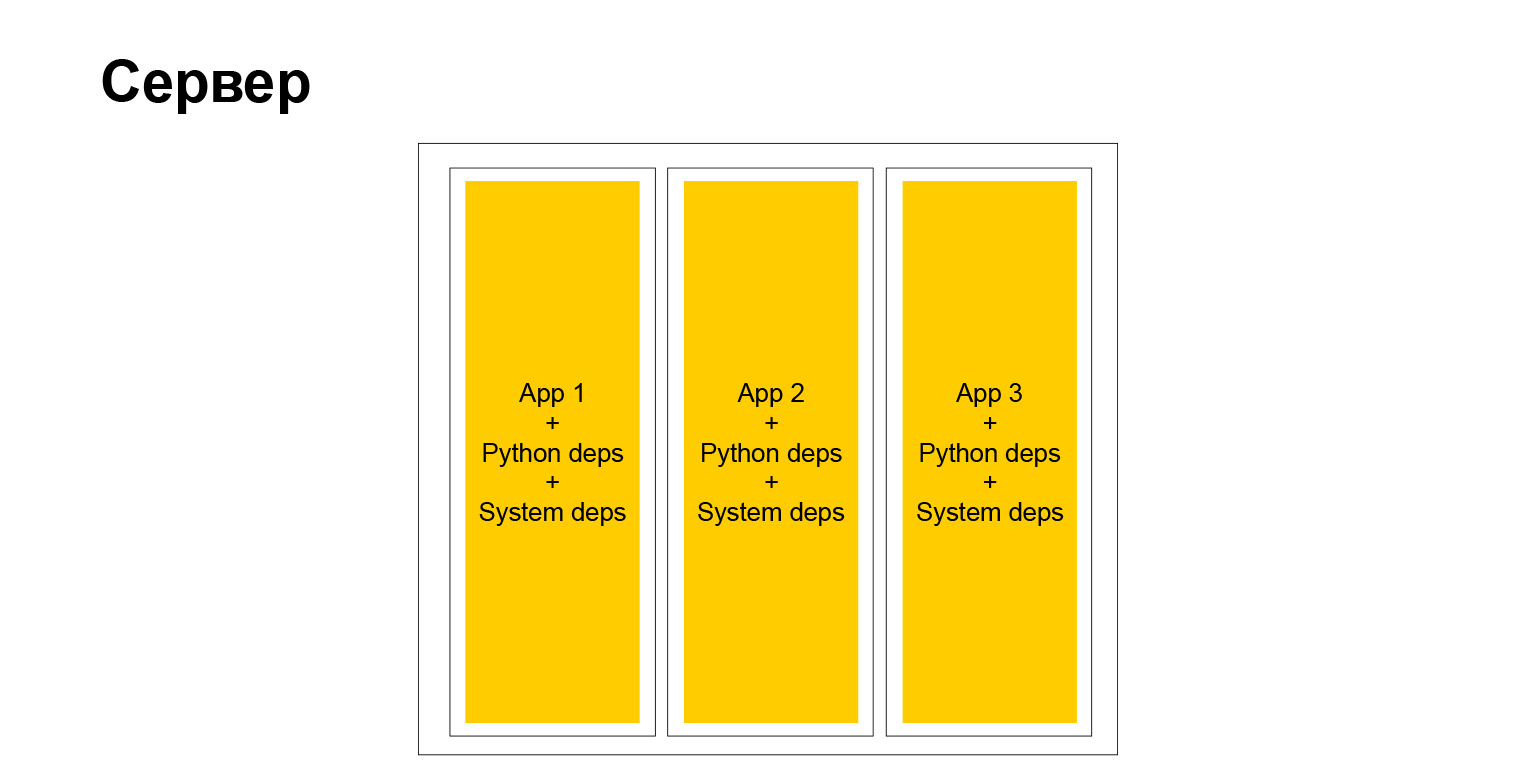
Pero, de hecho, la libertad completa, como saben, tiene un segundo lado. Cuando tienes una gran empresa, y más aún cuando quieres promover métodos y métodos de desarrollo uniformes, métodos de prueba, enfoques de documentación, en este momento te enfrentas al hecho de que este zoológico, por un lado, ayuda en alguna parte. Por otro lado, por el contrario, se complica. No puede fácilmente, por ejemplo, inyectar alguna biblioteca en todos los servicios, porque los servicios son diferentes. Tienen diferentes versiones de Python, Django o algún otro marco. Esto complica las cosas. Pero al final, un servidor típico comenzó a verse así.
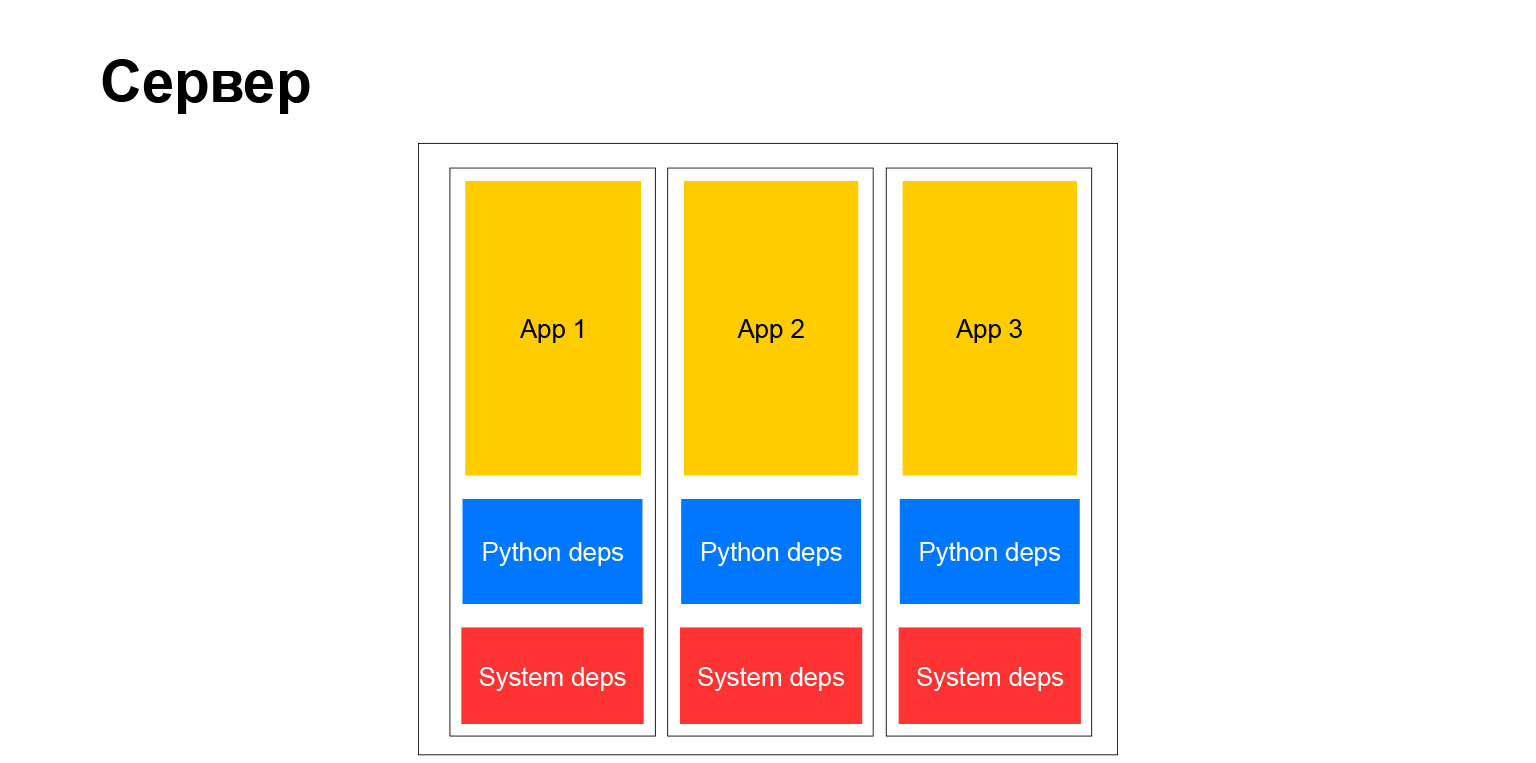
Si, es un servidor. Contamos con contenedores completamente independientes. Cada uno de ellos tiene su propio entorno de sistema, y nuestras aplicaciones están girando. Muy confortablemente. Pero como dije, hay inconvenientes.
Volvamos a Docker por un momento. Comenzamos a usar Docker para el desarrollo, nos ayudó mucho.

Docker es para todas las plataformas. Puede probar, usar docker-compose, hacer un enjambre de docker e intentar emular su entorno de producción en pequeños grupos para probar algo. Tal vez pruebas de carga. Comenzamos a usarlo activamente.
Docker también está muy bien integrado con todo tipo de entornos de desarrollo. Por ejemplo, estoy desarrollando en PyCharm, y también la mayoría de mis colegas. Hay soporte incorporado para Docker, con sus pros y sus contras, pero en general todo funciona.
Se ha vuelto muy conveniente, hemos dado un paso cualitativo, y es en esta etapa que estamos ahora. Es conveniente desarrollar usando Docker, aunque nuestra nube objetivo, donde implementamos nuestras aplicaciones, no es un Docker Runtime completo, tiene algunas limitaciones. Pero esto no nos impide usar Docker Engine localmente y en tareas relacionadas.
Resumamos esta era. Pros: aislamiento completo, cadena de herramientas conveniente para el desarrollo y, como dije, soporte IDE.
También hay desventajas. Docker está en todas partes, pero si no es Linux, funciona un poco extraño. Los desarrolladores de Yandex que tienen un Docker de instalación de MacBook para Mac. Y hay características, por ejemplo, IPv6 funciona de manera extraña, o necesita ajustarlo de alguna manera. Y en nuestra empresa IPv6 es muy común. Hace tiempo que carecemos de direcciones IPv4, por lo que toda la infraestructura interna está en gran medida vinculada a IPv6. Y cuando IPv6 no funciona en su computadora portátil o dentro de la ventana acoplable, que está en la computadora portátil, sufre y no puede hacer nada, entonces tenemos que evitarlo.

A pesar de esto, amamos mucho a Docker. Es eficiente y tiene un buen ecosistema. La gente viene a nosotros desde la calle, decimos: ¿puedes atracar? Ellos sí puedo. Todo perfectamente Llega una persona y, literalmente, comienza a ser útil de inmediato, porque no necesita profundizar en cómo comenzar y cómo construir un proyecto, cómo ejecutar pruebas, cómo mirar componer, cualquier salida de depuración. El hombre ya lo sabe todo. Este es un estándar de facto en el mundo exterior, aumenta nuestra eficiencia, podemos ofrecer rápidamente funciones a los usuarios y no gastar dinero en infraestructura.
4 años: ensamblaje binario
Pero ya nos estamos acercando a la última era en la que recién estamos entrando. Y aquí volveré al comienzo de mi informe, cuando dije: vienes a una gran corporación con tus propios enfoques de infraestructura. Es lo mismo con Yandex. Si antes era una infraestructura de Debian, ahora es diferente. La compañía ha tenido un único repositorio monolítico durante bastante tiempo, donde todo el código se recopila gradualmente. Se ha creado un mecanismo de construcción, un mecanismo de prueba distribuido, un montón de herramientas y todo lo que aún no usamos, pero que estamos comenzando a usar. Es decir, nuestros proyectos de Python también visitan este repositorio. Intentamos recolectar con las mismas herramientas. Pero dado que estas herramientas de un único repositorio, afiladas principalmente en C ++, Java y Go, hay una peculiaridad allí.
La peculiaridad es esta. Si ahora el resultado de construir nuestro proyecto es el motor Docker, donde nuestro código fuente con todas las dependencias simplemente se encuentra, entonces llegamos a la conclusión de que el resultado de construir nuestro proyecto será solo un binario. Es solo un binario, en el que hay un intérprete de python, código y nuestra python y todas las demás dependencias necesarias, están vinculados estáticamente.
Se cree que puede venir, lanzar este binario en cualquier servicio de Linux con una arquitectura compatible y funcionará. Y es verdad
Parece un poco no nativo. La mayoría de las personas en la comunidad nutricional no lo hacen, y estoy seguro de que no. Esto tiene sus pros y sus contras. Pros:
- . , , , , , . , . , , . .
- , , , . , , . , . , checkout , , . .
- , .
Y, por supuesto, hay un inconveniente: un ecosistema cerrado. Un extraño necesita estar inmerso en cómo funciona todo, para saber cómo funciona. Debe intentarlo y solo entonces se hace efectivo. Solo estamos al comienzo de este camino. Quizás, si vengo a esta conferencia en un año o dos, puedo decirles cómo pasamos por esta transformación. Pero ahora somos optimistas sobre el futuro y estamos sujetos a ciertas reglas corporativas internas, y preferimos que no, porque obtendremos muchos bollos internos.
conclusiones
Son más filosóficos. El informe en sí no es tanto técnico como filosófico.
- La evolución es inevitable. Si realiza un servicio y dura mucho tiempo, lo evolucionará, evolucionará su infraestructura, la forma en que lo desarrolla.
- . , , , .
- . , Django, . , . , , , Django - , . , .
- Python-. , , -. , , . , , , , , : , . , .
El tema es muy grande. Muy brevemente les conté cómo y qué hacemos, cómo Python ha evolucionado en nuestro país. Puede tomar cada era, tomar cada punto en la diapositiva y analizarlo más profundamente. Y esto también es suficiente durante 40 minutos: puede hablar durante mucho tiempo sobre las dependencias, el código abierto interno y la infraestructura. Le di una imagen general. Si algún tema es muy popular, puedo cubrirlo en las próximas reuniones o conferencias. Gracias.