
¿Cómo ahorrar en costos en la nube al trabajar con Kubernetes? No existe una solución única y correcta, pero este artículo proporciona varias herramientas para ayudarlo a administrar los recursos de manera más eficiente y reducir los costos de computación en la nube.
Escribí este artículo con la vista puesta en Kubernetes para AWS, pero se aplicará (casi) de la misma manera a otros proveedores de la nube. Supongo que su (s) clúster (es) ya tienen configurado el autoescalado ( cluster-autoscaler ). Eliminar recursos y reducir su implementación solo le ahorrará si también reduce su flota de nodos de trabajo (instancias EC2).
Este artículo cubrirá:
- limpieza de recursos no utilizados ( conserje de kube )
- reducción de escala durante las horas libres ( kube-downscaler )
- usando la escala automática horizontal (HPA),
- Reducción del exceso de reservas de recursos ( kube-resource-report , VPA)
- Usar instancias puntuales
Limpiar recursos no utilizados
Trabajar en un entorno acelerado es genial. Queremos que las organizaciones técnicas se aceleren . La entrega más rápida de software también significa más implementaciones de relaciones públicas, entornos de vista previa, prototipos y soluciones analíticas. Todo desplegado en Kubernetes. ¿Quién tiene tiempo para limpiar manualmente las implementaciones de prueba? Es fácil olvidarse de eliminar un experimento de una semana. La factura de la nube eventualmente crecerá debido al hecho de que olvidamos cerrar:

(Henning Jacobs:
Zhiza:
(citado) Corey Quinn:
Mito: Su cuenta de AWS es una función del número de sus usuarios.
Hecho: Su cuenta de AWS es una función del número de sus ingenieros.
Ivan Kurnosov (en respuesta): Realidad
: Su cuenta de AWS es una función que depende de la cantidad de cosas que olvidó desactivar / eliminar).
Kubernetes Janitor (kube-conserje) ayuda a limpiar su clúster. La configuración del conserje es flexible tanto para uso global como local:
- Las reglas generales para todo el clúster pueden determinar el tiempo máximo de vida (TTL) para implementaciones de PR / prueba.
- Los recursos individuales se pueden anotar con conserje / ttl, por ejemplo, para eliminar automáticamente el pico / prototipo después de 7 días.
Las reglas generales se definen en el archivo YAML. Su ruta se pasa a través del parámetro
--rules-filea kube-conserje. Aquí hay un ejemplo de una regla para eliminar todos los espacios de nombres -pr-en un nombre después de dos días:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dEl siguiente ejemplo regula el uso de la etiqueta de la aplicación en los pods Deployment y StatefulSet para todas las nuevas implementaciones / StatefulSet en 2020, pero al mismo tiempo permite la ejecución de pruebas sin esta etiqueta durante una semana:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dEjecución de una demostración de tiempo limitado durante 30 minutos en el clúster donde se ejecuta kube-conserje:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mOtra fuente de costos crecientes son los volúmenes persistentes (AWS EBS). Al eliminar un StatefulSet de Kubernetes no se eliminan sus volúmenes persistentes (PVC - PersistentVolumeClaim). Los volúmenes no utilizados de EBS pueden conducir fácilmente a costos de cientos de dólares por mes. Kubernetes Janitor tiene una función para limpiar PVC no utilizado. Por ejemplo, esta regla eliminará todos los PVC que no estén montados por el pod y que no estén referenciados por un StatefulSet o CronJob:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor puede ayudarlo a mantener su clúster limpio y evitar los costos de crecimiento lento de la computación en la nube. Para obtener instrucciones de implementación y configuración, siga el archivo README de kube-janitor .
Fuera de la oficina alejar
Por lo general, se requiere que los sistemas de prueba e intermedios trabajen solo durante las horas de trabajo. Algunas aplicaciones de producción, como las herramientas administrativas / administrativas, también requieren disponibilidad limitada y pueden desactivarse por la noche.
Kubernetes Downscaler (kube-downscaler) permite a los usuarios y operadores reducir el sistema durante las horas de descanso. Las implementaciones y StatefulSets pueden escalar a cero réplicas. CronJobs puede ser suspendido. Kubernetes Downscaler es configurable para todo el clúster, uno o más espacios de nombres o recursos individuales. Puede establecer "tiempo de inactividad" o viceversa "tiempo de ejecución". Por ejemplo, para reducir la escala lo más posible durante la noche y los fines de semana:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeAquí hay un gráfico para escalar los nodos de trabajo del clúster durante el fin de semana:

reducir de ~ 13 a 4 nodos de trabajo sin duda hace una gran diferencia en la factura de AWS.
Pero, ¿qué sucede si necesito trabajar mientras el clúster está "inactivo"? Ciertas implementaciones se pueden excluir permanentemente del escalado agregando la anotación downscaler / exclude: true. Las implementaciones se pueden excluir temporalmente utilizando la anotación descendente / excluir-hasta con una marca de tiempo absoluta en el formato AAAA-MM-DD HH: MM (UTC). Si es necesario, todo el clúster puede reducirse mediante la implementación de un pod anotado
downscaler/force-uptime, por ejemplo ejecutando nginx dummy:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueConsulte el README kube-downscaler para obtener instrucciones de implementación y opciones adicionales.
Usar escala automática horizontal
Muchas aplicaciones / servicios tratan con un esquema de carga dinámica: a veces sus módulos están inactivos, y otras funcionan a plena capacidad. Trabajar con una flota permanente de cápsulas para hacer frente a la carga máxima máxima no es económico. Kubernetes admite el escalado automático horizontal a través del recurso HorizontalPodAutoscaler (HPA). El uso de la CPU suele ser un buen indicador de escala:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando ha creado un componente para conectar fácilmente las métricas personalizadas para el escalado: El adaptador de métricas de Kube (kube-metrics-adapter) es un adaptador de métricas universal para Kubernetes que puede recopilar y mantener métricas personalizadas y externas para el autoescalado horizontal. Admite escalado basado en métricas de Prometheus, colas SQS y otras personalizaciones. Por ejemplo, para ampliar su implementación para una métrica personalizada representada por la propia aplicación como JSON en / metrics, use:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueLa configuración de la escala automática horizontal con HPA debería ser una de las acciones predeterminadas para mejorar la eficiencia de los servicios sin estado. Spotify tiene una presentación con sus experiencias y mejores prácticas para HPA: escale sus implementaciones, no su billetera .
Reducción de la redundancia de recursos.
Las cargas de trabajo de Kubernetes determinan sus necesidades de CPU / memoria a través de "solicitudes de recursos". Los recursos de la CPU se miden en núcleos virtuales o más a menudo en "milicores", por ejemplo, 500m implica 50% vCPU. Los recursos de memoria se miden en bytes y se pueden usar sufijos comunes, por ejemplo 500Mi, que significa 500 megabytes. Las solicitudes de recursos "bloquean" la capacidad en los nodos de trabajo, es decir, un módulo con una solicitud de CPU de 1000 m en un nodo con 4 vCPU dejará solo 3 vCPU disponibles para otros módulos. [1]
Slack (exceso de reserva)Es la diferencia entre los recursos solicitados y el uso real. Por ejemplo, bajo, que solicita 2 GiB de memoria, pero usa solo 200 MiB, tiene ~ 1.8 GiB de memoria "en exceso". El exceso cuesta dinero. Se puede estimar aproximadamente que 1 GiB de memoria en exceso cuesta ~ $ 10 por mes. [2]
El Informe de recursos de Kubernetes (kube-resource-report) muestra el exceso de reservas y puede ayudarlo a determinar posibles ahorros:

Informe de recursos de Kubernetesmuestra el exceso agregado por aplicación y equipo. Esto le permite encontrar lugares donde se pueden reducir las demandas de recursos. El informe HTML generado solo proporciona una instantánea del uso de los recursos. Debe observar el uso de la CPU / memoria a lo largo del tiempo para determinar las solicitudes de recursos adecuadas. Aquí hay un diagrama de Grafana para un servicio "típico" de alto uso de CPU: todos los pods están utilizando significativamente menos de 3 núcleos de CPU solicitados: la
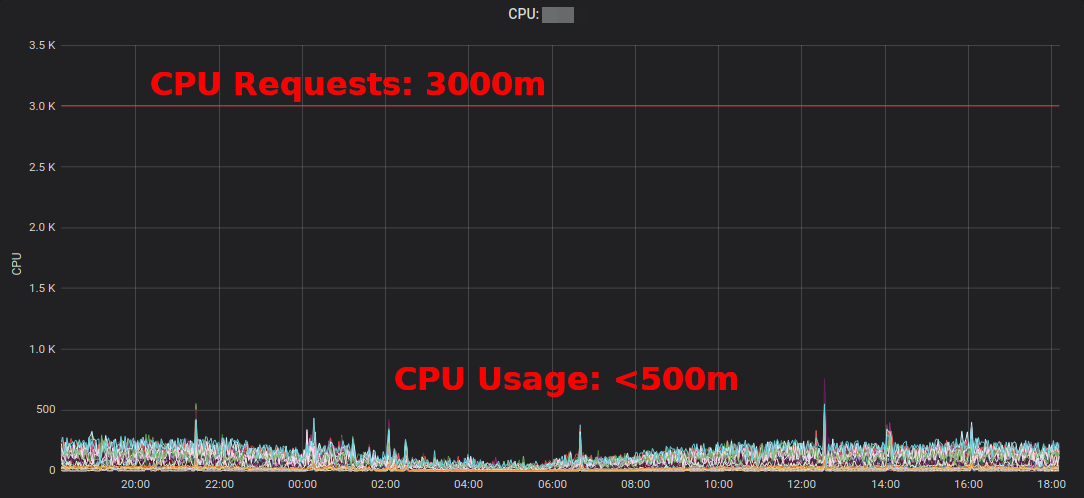
reducción de la solicitud de CPU de 3000 ma ~ 400 m libera recursos para otras cargas de trabajo y permite que el clúster se reduzca.
"El uso promedio de CPU de las instancias de EC2 a menudo varía en el rango de un porcentaje", escribe Corey Quinn . Mientras que para EC2, estimar el tamaño correcto puede ser una mala decisión.Cambiar algunas solicitudes de recursos de Kubernetes en un archivo YAML es fácil y puede generar grandes ahorros.
¿Pero realmente queremos que la gente cambie los valores en los archivos YAML? ¡No, las máquinas pueden hacerlo mucho mejor! Kubernetes Vertical Pod Autoscaler (VPA) hace exactamente eso: adapta las solicitudes de recursos y las restricciones para adaptarse a la carga de trabajo. Aquí hay un ejemplo de un gráfico de solicitudes de CPU Prometheus (línea azul delgada) adaptadas por VPA a lo largo del tiempo:

Zalando usa VPA en todos sus clústeres para componentes de infraestructura. Las aplicaciones no críticas también pueden usar VPA.
Encerrada doradaby Fairwind es una herramienta que crea un VPA para cada implementación en un espacio de nombres y luego muestra la recomendación de VPA en su panel de control. Puede ayudar a los desarrolladores a establecer las solicitudes correctas de procesador / memoria para sus aplicaciones:

escribí una pequeña publicación de blog sobre VPA en 2019, y VPA se discutió recientemente en la Comunidad de usuarios finales de CNCF .
Uso de instancias de spot EC2
Por último, pero no menos importante, los costos de AWS EC2 se pueden reducir mediante el uso de instancias Spot como nodos de trabajo de Kubernetes [3] . Las instancias puntuales están disponibles con hasta un 90% de descuento en los precios bajo demanda. Ejecutar Kubernetes en EC2 Spot es una buena combinación: debe especificar varios tipos de instancias diferentes para una mayor disponibilidad, lo que significa que puede obtener un nodo más grande por el mismo precio o menor, y la mayor capacidad puede ser utilizada por las cargas de trabajo de Kubernetes en contenedores.
¿Cómo ejecuto Kubernetes en EC2 Spot? Hay varias opciones: utilizar un servicio de terceros como SpotInst (ahora llamado "Spot", no me pregunte por qué), o simplemente agregar el grupo de escalado automático (ASG) a su clúster. Por ejemplo, aquí hay un fragmento de CloudFormation para un Spot ASG "con capacidad optimizada" con múltiples tipos de instancia:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Algunas notas sobre el uso de Spot con Kubernetes:
- Debe manejar las terminaciones de Spot, por ejemplo drenando un nodo en una parada de instancia
- Zalando bifurcó la escala automática de clúster oficial con prioridades de grupo de nodos
- Los nodos de spot pueden verse obligados a aceptar "registros" de cargas de trabajo para ejecutarse en Spot
Resumen
Espero que encuentre algunas de las herramientas presentadas útiles para reducir su factura de computación en la nube. Puede encontrar la mayoría de los contenidos del artículo también en mi charla en DevOps Gathering 2019 en YouTube y en diapositivas .
¿Cuáles son sus mejores prácticas para ahorrar costos en la nube en Kubernetes? Avísame en Twitter (@try_except_) .
[1] De hecho, menos de 3 vCPU seguirán siendo utilizables ya que el ancho de banda del host se reduce por los recursos reservados del sistema. Kubernetes distingue entre la capacidad del nodo físico y los recursos "asignados" ( nodo asignable ).
[2] Ejemplo de cálculo: una copia de m5.large con 8 GiB de memoria es ~ 84 USD por mes (eu-central-1, On-Demand), es decir El bloqueo de 1/8 nudos es de aproximadamente ~ $ 10 por mes.
[3] Hay muchas más formas de reducir su puntaje EC2, por ejemplo, instancias reservadas, plan de ahorro, etc. - No voy a cubrir estos temas aquí, ¡pero definitivamente debe averiguarlos!
Aprende más sobre el curso.