
Cuando hablamos de CI&CD, a menudo profundizamos en las herramientas básicas para automatizar la construcción, las pruebas y la entrega de aplicaciones, centrándonos en las herramientas, pero olvidándonos de cubrir los procesos que ocurren durante el corte y la estabilización de las versiones. Sin embargo, no todas las herramientas listas para usar son igualmente útiles y algunos procesos personalizados no encajan en su cobertura. Tienes que investigar los procesos y encontrar formas de automatizarlos para optimizarlos.
En nuestra empresa, los ingenieros de control de calidad utilizan Zephyr para realizar un seguimiento del progreso de la regresión, ya que no podemos reemplazar las pruebas manuales y exploratorias con autotests. Pero a pesar de esto, las pruebas automáticas a menudo se persiguen aquí y en grandes cantidades, por lo que quiero poder omitir algunas verificaciones banales que se han automatizado y permitir que los probadores hagan un trabajo más productivo y útil.
Tenemos carreras nocturnas en las que se persiguen suites de prueba completas. Pero en los albores del dominio de Zephyr, durante la regresión, nuestros probadores tuvieron que descargar xcresult, o incluso antes, plist, o junit xml, y luego escribir las correspondencias de las pruebas verde y roja en malvaviscos con sus manos. Esta es una operación bastante rutinaria, y lleva mucho tiempo pasar 500-600 pruebas a mano. Quieres dejar esas cosas a merced de una máquina sin alma. Así nació ZERG.
Nace zerg
Zephyr Enterprise Report Generator es una pequeña utilidad que inicialmente solo sabía cómo buscar coincidencias en el informe de prueba y enviar sus estados actuales a Zephyr. Posteriormente, la utilidad recibió nuevas funciones, pero hoy nos centraremos en buscar y enviar informes.
En Zephyr, se nos pide que operemos con versiones, bucles y ejecuciones de casos de prueba. Cada versión contiene un número arbitrario de ciclos y cada ciclo contiene pases de casos. Dichos pases contienen información sobre la tarea (zephyr se integra perfectamente con jira y el caso de prueba es, de hecho, una tarea en jira), el autor, el estado del caso, así como quién está involucrado en este caso y otros detalles necesarios. .
Para automatizar el problema que describimos anteriormente, es importante que comprendamos cómo establecer el estado del caso.
Trabajando con código
Pero, ¿cómo se correlaciona la prueba de código y la prueba de malvavisco? Aquí hemos adoptado un enfoque bastante simple y directo: para cada prueba, agregamos enlaces a tareas en jira en la sección de comentarios.
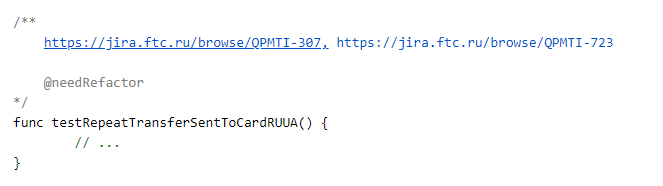
También se pueden colocar parámetros adicionales en los comentarios, pero más sobre eso más adelante.
Entonces, una prueba en el código puede cubrir varias tareas. Pero la lógica inversa también funciona. Se pueden escribir varias pruebas en código para una tarea. Sus estados se tendrán en cuenta al elaborar el informe.
Necesitamos revisar el código fuente, extraer todas las clases y pruebas de prueba, vincular tareas con métodos y correlacionar esto con el informe de aprobación de la prueba (xcresult o junit).
Puede trabajar con el código en sí de diferentes formas:
- simplemente lea archivos y recupere información a través de expresiones regulares
- use SourceKit
Sea como sea, incluso cuando use SourceKit, no podemos prescindir de expresiones regulares para extraer ID de tareas de enlaces en comentarios.
En esta etapa, no estamos interesados en los detalles, por lo que nos aislaremos de ellos con un protocolo:

necesitamos hacernos pruebas. Para hacer esto, describimos las estructuras:
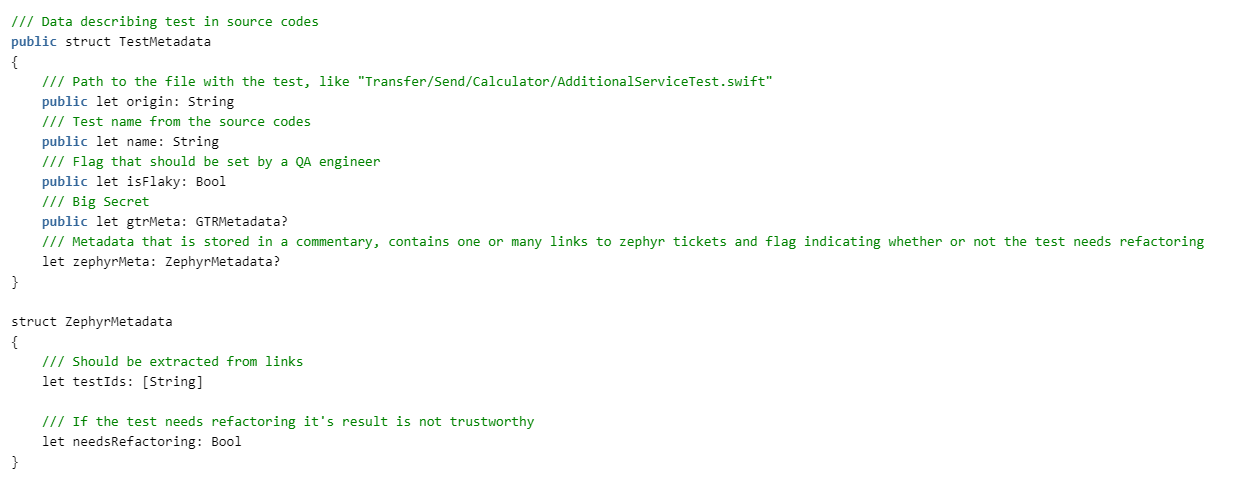
Luego necesitamos leer el informe sobre la aprobación de las pruebas. ZERG nació antes de pasar a xcresult y, por lo tanto, puede analizar plist y junit. Todavía no estamos interesados en los detalles de este artículo, se adjuntarán en el código. Por lo tanto, cerraremos los protocolos.

Todo lo que queda es vincular las pruebas en el código con los resultados de las pruebas de los informes.
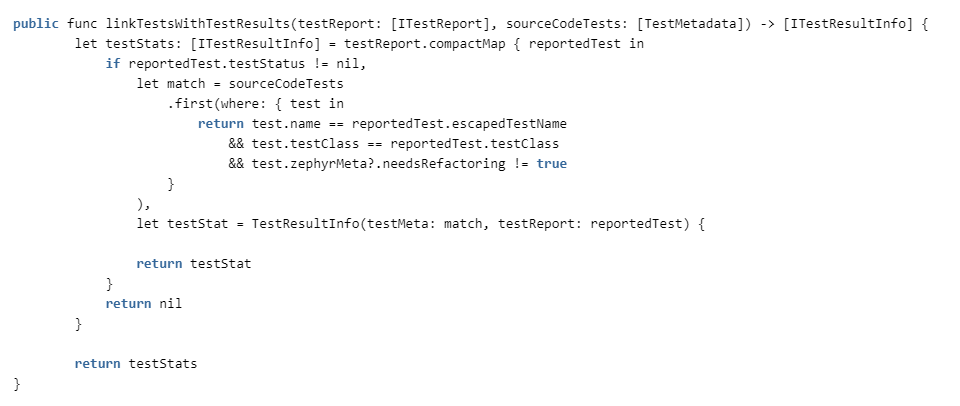
Verificamos la correspondencia por nombre de clase y nombre de prueba (diferentes clases pueden tener métodos con el mismo nombre) y si se necesita refactorización para la prueba. Si lo necesita, consideramos que no es confiable y lo descartamos de las estadísticas.
Trabajamos con malvaviscos
Ahora que hemos leído los informes de prueba, tenemos que traducirlos al contexto céfiro. Para hacer esto, necesita obtener una lista de versiones del proyecto, correlacionar con la versión de la aplicación (para que esto funcione así, es necesario que la versión en el malvavisco coincida con la versión en el Info.plist de su aplicación , por ejemplo, 2.56), descarga bucles y pases. Y luego correlacione los pases con nuestros informes existentes.
Para hacer esto, necesitamos implementar los siguientes métodos en ZephyrAPI: La
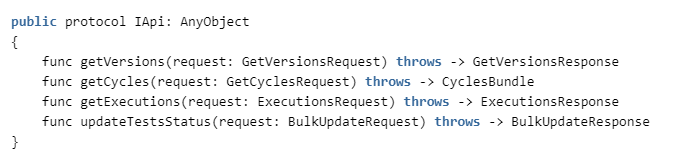
especificación se puede ver aquí: getzephyr.docs.apiary.io , y la implementación del cliente está en nuestro repositorio.
El algoritmo general es bastante simple:
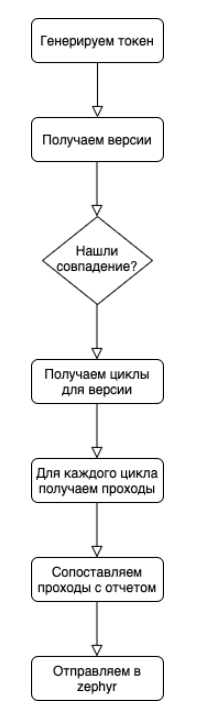
En la etapa de emparejar pases con informes, hay un punto sutil que debe tenerse en cuenta: en la api de zephyr, lo más conveniente es enviar la actualización de ejecución por lotes, donde se transmite el estado general y una lista de ID de pases . Necesitamos ampliar nuestros informes de tickets y tener en cuenta la relación nm. Para un caso de marshmallow, puede haber varias pruebas en el código. Una prueba en el código puede cubrir varios casos. Si para un caso hay n pruebas en el código y una de ellas es roja, entonces para tal caso el estado general es rojo, pero si una de tales pruebas cubre m casos y es verde, entonces el resto de los casos debería no se pone rojo.
Por lo tanto, operamos con conjuntos y buscamos la intersección de rojo y verde. Cualquier cosa que caiga en la intersección, restamos de los resultados verdes y enviamos la información editada a zephyr.

También se debe tener en cuenta aquí que dentro del equipo hemos acordado que los zerg no cambiarán el estado del pase si:
1. El estado actual está bloqueado o fallido (solíamos cambiar el estado de fallido, pero ahora nos hemos rendido práctica, porque queremos que los evaluadores presten atención a los autotests rojos durante la regresión).
2. Si el estado actual es aprobado y fue establecido por una persona, no zerg.
3. Si la prueba está marcada como intermitente.
Intereses de la API de Zephyr
Al solicitar bucles, recibimos json, que a primera vista no se puede sistematizar para la deserialización. El caso es que una solicitud para obtener bucles para una versión, aunque debería devolver una matriz de bucles, de hecho, devuelve un objeto, donde cada campo es único y se llama identificador de bucle, que se encuentra en el valor. Para manejar esto, usamos trucos simples:

los estados de aprobación de la prueba vienen en una de las solicitudes junto al objeto de solicitud. Pero se pueden mover de antemano a la enumeración:

al solicitar bucles, debe pasar la versión y el identificador entero del proyecto a los parámetros de solicitud. Pero en la solicitud de pases para el bucle, se debe pasar el mismo identificador de proyecto en un formato de cadena.

En lugar de una conclusión
Si hay mucho trabajo de rutina, lo más probable es que algo pueda automatizarse. Sincronizar el paso de las pruebas automáticas con el sistema de gestión de pruebas es uno de esos casos.
Por lo tanto, todas las noches realizamos una prueba completa y, durante la regresión, el informe se envía a los ingenieros de control de calidad. Esto reduce el tiempo de regresión y da tiempo para pruebas exploratorias.
Si implementa correctamente el analizador de código fuente de Android, entonces se puede aplicar con el mismo éxito para la segunda plataforma.
Nuestro Zerg, además de comparar pruebas, también es capaz de analizar el impacto inicial, pero más sobre eso, quizás la próxima vez.